
- Financial Performance – A Complete Tutorial
- How Six Sigma Principles Can Progress Your Productivity – Tutorial
- Google Analytics Pro Tutorial | Fast Track your Career
- Activity-Based Costing Tutorial | Know about Definition, Process, & Example
- Create a workbook in Excel Tutorial | Learn in 1 Day
- Excel ROUNDUP Formula Tutorial | Learn with Functions & Examples
- Business Analytics with Excel Tutorial | Learn In 1 Day
- SAP Tutorial – Free Guide Tutorial & REAL-TIME Examples
- IBM SPSS Statistics Tutorial: Getting Started with SPSS
- SAP Security Tutorial | Basics & Definition for Beginners
- SAP Simple Finance Tutorial | Ultimate Guide to Learn [Updated]
- SAP FIORI Tutorial | Learn in 1 Day FREE
- Introduction to Business Analytics with R Tutorial | Ultimate Guide to Learn
- Tableau Desktop Tutorial | Step by Step resource guide to learn Tableau
- Implementing SAP BW on SAP HANA | A Complete Guide
- SAP HANA Administration | Free Guide Tutorial & REAL-TIME Examples
- Tableau API Tutorial | Get Started with Tools, REST Basics
- SAP FICO ( Financial Accounting and Controlling ) Tutorial | Complete Guide
- Alteryx Tutorial | Step by Step Guide for Beginners
- Getting started with Amazon Athena Tutorial – Serverless Interactive | The Ultimate Guide
- Introduction to Looker Tutorial – A Complete Guide for Beginners
- Sitecore Tutorials | For Beginners Learn in 1 Day FREE |Ultimate Guide to Learn [UPDATED]
- Adobe Analytics Tutorial – The Ultimate Student Guide
- Splunk For Beginners – Learn Everything About Splunk with Free Online Tutorial
- An Overview of SAP HANA Tutorial: Learn in 1 Day FREE
- Statistical Package for the Social Sciences – SPSS Tutorial: The Ultimate Guide
- Splunk For Beginners – Learn Everything About Splunk with Free Online Tutorial
- Pentaho Tutorial – Best Resources To Learn in 1 Day | CHECK OUT
- Statistical Package for the Social Sciences – SPSS Tutorial: The Ultimate Guide
- An Overview of SAP HANA Tutorial: Learn in 1 Day FREE
- Spotfire Tutorial for Beginners | Quickstart – MUST- READ
- JasperReports Tutorial: Ultimate Guide to Learn [BEST & NEW]
- Charts and Tables – Qlikview Tutorial – Complete Guide
- TIBCO Business Works | Tutorial for Beginners – Learn From Home
- Cognos TM1 Tutorial : Learn Cognos from Experts
- Kibana
- Power BI Desktop Tutorial
- Tableau Tutorial
- SSAS Tutorial
- Creating Tableau Dashboards
- MDX Tutorial
- Tableau Cheat Sheet
- Analytics Tutorial
- Lean Maturity Matrix Tutorial
- MS Excel Tutorial
- Business Analysis Certification Levels & Their Requirements Tutorial
- Solution Assessment and Validation Tutorial
- Lean Six Sigma Tutorial
- Enterprise Analysis Tutorial
- Create Charts and Objects in Excel 2013 Tutorial
- Msbi Tutorial
- MicroStrategy Tutorial
- Advanced SAS Tutorial
- OBIEE Tutorial
- Tableau Server Tutorial
- OBIA Tutorial
- Business Analyst Tutorial
- Cognos Tutorial
- Qlik Sense Tutorial
- SAP-Bussiness Objects Tutorial
- SAS Tutorial
- PowerApps Tutorial
- Financial Performance – A Complete Tutorial
- How Six Sigma Principles Can Progress Your Productivity – Tutorial
- Google Analytics Pro Tutorial | Fast Track your Career
- Activity-Based Costing Tutorial | Know about Definition, Process, & Example
- Create a workbook in Excel Tutorial | Learn in 1 Day
- Excel ROUNDUP Formula Tutorial | Learn with Functions & Examples
- Business Analytics with Excel Tutorial | Learn In 1 Day
- SAP Tutorial – Free Guide Tutorial & REAL-TIME Examples
- IBM SPSS Statistics Tutorial: Getting Started with SPSS
- SAP Security Tutorial | Basics & Definition for Beginners
- SAP Simple Finance Tutorial | Ultimate Guide to Learn [Updated]
- SAP FIORI Tutorial | Learn in 1 Day FREE
- Introduction to Business Analytics with R Tutorial | Ultimate Guide to Learn
- Tableau Desktop Tutorial | Step by Step resource guide to learn Tableau
- Implementing SAP BW on SAP HANA | A Complete Guide
- SAP HANA Administration | Free Guide Tutorial & REAL-TIME Examples
- Tableau API Tutorial | Get Started with Tools, REST Basics
- SAP FICO ( Financial Accounting and Controlling ) Tutorial | Complete Guide
- Alteryx Tutorial | Step by Step Guide for Beginners
- Getting started with Amazon Athena Tutorial – Serverless Interactive | The Ultimate Guide
- Introduction to Looker Tutorial – A Complete Guide for Beginners
- Sitecore Tutorials | For Beginners Learn in 1 Day FREE |Ultimate Guide to Learn [UPDATED]
- Adobe Analytics Tutorial – The Ultimate Student Guide
- Splunk For Beginners – Learn Everything About Splunk with Free Online Tutorial
- An Overview of SAP HANA Tutorial: Learn in 1 Day FREE
- Statistical Package for the Social Sciences – SPSS Tutorial: The Ultimate Guide
- Splunk For Beginners – Learn Everything About Splunk with Free Online Tutorial
- Pentaho Tutorial – Best Resources To Learn in 1 Day | CHECK OUT
- Statistical Package for the Social Sciences – SPSS Tutorial: The Ultimate Guide
- An Overview of SAP HANA Tutorial: Learn in 1 Day FREE
- Spotfire Tutorial for Beginners | Quickstart – MUST- READ
- JasperReports Tutorial: Ultimate Guide to Learn [BEST & NEW]
- Charts and Tables – Qlikview Tutorial – Complete Guide
- TIBCO Business Works | Tutorial for Beginners – Learn From Home
- Cognos TM1 Tutorial : Learn Cognos from Experts
- Kibana
- Power BI Desktop Tutorial
- Tableau Tutorial
- SSAS Tutorial
- Creating Tableau Dashboards
- MDX Tutorial
- Tableau Cheat Sheet
- Analytics Tutorial
- Lean Maturity Matrix Tutorial
- MS Excel Tutorial
- Business Analysis Certification Levels & Their Requirements Tutorial
- Solution Assessment and Validation Tutorial
- Lean Six Sigma Tutorial
- Enterprise Analysis Tutorial
- Create Charts and Objects in Excel 2013 Tutorial
- Msbi Tutorial
- MicroStrategy Tutorial
- Advanced SAS Tutorial
- OBIEE Tutorial
- Tableau Server Tutorial
- OBIA Tutorial
- Business Analyst Tutorial
- Cognos Tutorial
- Qlik Sense Tutorial
- SAP-Bussiness Objects Tutorial
- SAS Tutorial
- PowerApps Tutorial

Getting started with Amazon Athena Tutorial – Serverless Interactive | The Ultimate Guide
Last updated on 10th Aug 2022, Blog, Business Analytics, Tutorials
Data analysis is a very difficult process, and efforts have always been made to make it simple.
There are more tools for analytics, and even the famous tech giant Amazon offers an AWS service called Amazon Athena
Amazon Athena is an interactive data analysis tool used to process difficult queries in a relatively short amount of time.
It is a serverless.
Hence, there is no hassle to set up, and no infrastructure management is needed.
It is not a database service.
Therefore, pay for the queries that run.
Just point a data into S3, explain the necessary schema, and are good to go with a standard SQL.
Introduction to Amazon Athena
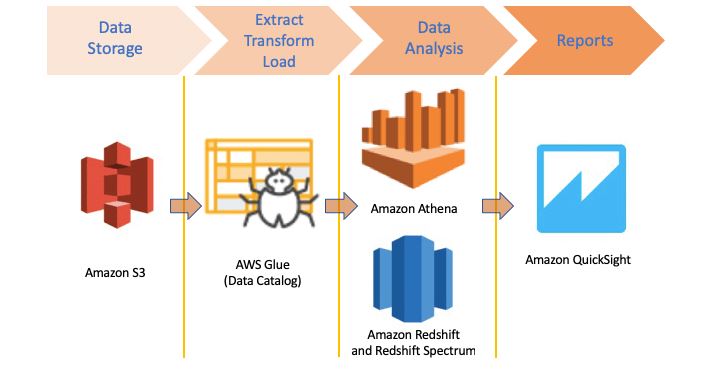
On 20 November 2016, Amazon launched an Athena as one of its services.
As mentioned earlier, Amazon Athena is a serverless query service that analyse a data using standard SQL stored in Amazon S3. With a few clicks in the AWS Management Console, customers can point Amazon Athena at the data saved in Amazon S3 and run queries using standard SQL to retrieve results in a seconds.With an Amazon Athena, there is no infrastructure to set up or maintain, and the customer only pays for the queries they run Amazon Athena scales automatically, executing queries in the parallel, giving fast results even with high datasets and difficult queries.
Difference Between Microsoft SQL Server And Amazon Athena
| Features | Microsoft SQL Server | Amazon Athena |
|---|---|---|
| DEFINITION | Microsoft SQL Server is a database management and also an analysis system. | Amazon Athena is an interactive query service that made a data analysis easy. |
| USAGE | Used for DML, DCL, DDL, and TCL operations on the Database. | Used for a DML operations on the Database. |
| BENEFITS | 1.Reliable and simple to use. 2.More performance. 3.Simple to maintain. 4.Simple server installation. 5.Multiple tools an integration possible. | 1.Simple to use 2.High performance. 3.No maintenance are required. 4.No server configuration are required. 5.Multiple tools an integration possible. |
| INTEGRATION | 1.Sequlize 2.SQLDep 3.Presto | 1.Amazon S3 2.AWS Glue 3.Presto |
| LIMITATIONS | 1.Limited RDS can be storage. 2.Limited instances. 3.Can not be handle recursion. | 1.No DDLs are supported. 2.Works with an external table only. 3.Defined User Functions are not supported. |
Creating Table in Athena
Use live resources, so only charged for the queriesfrom run, but not for the datasets y use, and if need to upload the data files to Amazon S3, then charges apply.
To query S3 file data, must have an external table associated with a file structure.
Create an external tables in two ways:
- Manually.
- Using AWS Glue Crawler.
To create an external table manually, follow the correct structure CREATE DETAILS CREATE EXTERNAL TABLE and denote the correct format and exact location.
An example is given below:
Creating an external table manually
The created external tables are saved in the AWS Glue Catalog.
Glu Clover parses the input file structure and made a metadata table explained in the Glu Data Catalog.
The Crawler usedthe AWS IAM (Identity and Access Management) role to permit to archived data and data catalogs.
Must have permission to pass the roles to the Crawler to access crawled Amazon S3 paths.
Go to AWS Glue, select “Add Table,” and select an option “Add Table Using Crawler”.
Add tables by using a glue crawler.
Given the Crawler a name. for example, a car-crawler
Choose the path in an Amazon S3, where the file is saved.
If plan to query only one file, can choose either the S3 file path or the S3 folder path to query all files in the folder with the same structure.
Enter a crawler name
Choose the path in the Amazon S3, where the file are saved.
Create an IAM role with the permissions to the S3 object whose target that want to query or select an existing IAM role (that has sufficient privileges to access the S3 object).
Choose a database that include an external tables and optionally choose a prefix to be an added to the external table name.
Select Database and also prefix for external tables
Run crawler
The external table has been generated under the specified Database.
Now can query the S3 object by using this.
Select data from external table
Since put a file, the query “select * from json_files” returns a one record in the file.
Let’s try to put another file with the same structure in the same S3 folder and query and an external table again.
If want query the same EXTERNAL table, that will see two rows returned instead of a one.
When the same external table is queried, that will get two records.
It is because there are 2 files in the S3 folder with a desired structure.
Can perform more operations on the data.
For example, the following Query will UNNEST the array into result set.
Accessing Amazon Athena
Athena is very simple to reach, and one can either:
These are few of the ways to access Amazon Athena.
By now, know everything important about Amazon Athena, and let about the various features of Athena.
Features of Athena
Among the more services provided by Amazon, Athena is one of the services.
It has some features that make it suitable for data analysis.
Let’s take a look at the various features one by one.
Easy Implementation:
Athena does not need installation, and it can also be accessed by a AWS CLI directly from a AWS console.
Serverless:
It is serverless, so the end-user does not require to worry about infrastructure, configuration, scaling, or failure. Athena takes care of an everything .
Pay Per Query:
Athena charges only for the Query that run, i.e., the amount of data managed for per Query.
Can save a lot if can compress them and format the dataset accordingly.
Fast:
Athena is a very quick analysis tool.
It can execute difficult queries quickly by breaking them down into easier queries and running them in parallel, then combining the results to give the desired output
Secure:
With the help of IAM rules and AWS identities, Athena gives a complete control over the data set.
Since data saved in S3 buckets, IAM policies can help to manage users’ controls.
Highly Available:
With the assurance of AWS, Athena is more available, and the user can execute a queries round the clock.
As is AWS 99.999% available, so it is Athena.
Integration:
The best feature of Athena is that it can be integrated with a AWS Glue.
AWS Glue will help the user to built a better-integrated data repository.
It helps to create a better versions of data, better tables, views, etc.
What are the limitations of Amazon Athena?
- Optimization is limited to the queries.
- For example, data already saved in S3 cannot be optimized.
- No indexing options.
- Indexing options generally appear in traditional databases.
- Without indexing, an operation load on Athena improves, potentially affecting performance.
- Efficient queries required partitioning.
- To enable an efficient queries, data must first be partitioned, and partitions must then be keep for what best fits performance needs.
- Stored procedures, parameterized queries, and Presto federated connectors are not a supported.
- Amazon Athena Federated Query is required to connect data sources.
- When querying a table with thousands of a partitions, Athena can time out.
- Source files that initiate with an underscore or a dot are treated as hidden.
- The row and column size are cannot be exceed 32 megabytes.
- Athena does not encourage querying data in S3 Glacier and S3 Glacier Deep Archive storage classes.
- Statements like CREATE TABLE LIKE, DESCRIBE INPUT and DESCRIBE OUTPUT, EXECUTE ? USING, MERGE and UPDATE are not supported.
AWS Athena vs. AWS Glue
Since its initial release in an August 2017, AWS Glu has been operating as a entirely -managed Extract, Transform and Load (ETL) service.
It comes with 3 primary components:
- 1. A flexible scheduler to handle a job monitoring
- 2. An ETL engine capable of creating Scalable or Python code
- 3. A data catalog that serves as central metadata repository
AWS Glue helps to find and transform data sets and prepare them for discovery and querying with the tools.
So, should be able to use an AWS Athena with AWS Glue.
Subsequent data catalogs will made, save and retrieve table metadata (or schemas) as queried by Athena.
Advantages and disadvantages of using AWS Athena
AWS Athena, as it turned out, double-edged sword.
The features that made it conveniently cheap and accessible are the ones that may limit a somewhat.
Serverless: Since it is delivered as a fully managed serverless service, AWS Athena stores all the hassle that comes with managing infrastructure.
Cost-effective: AWS Athena is not for only a cost-effective but also quite affordable as compared to its close competitors
Widely Accessible: As a service that runs its queries by using standard SQL, AWS Athena is widely accessible to anyone – not just developers and also engineers.
It can be adopted by a business analysts and other data professionals, as standard SQL queries are very easy and straightforward.
Flexibility: Amazon Athena’s open and versatile architecture doesn’t limit to any particular vendor, technology, or device.For example, can work with a wide range of open-source file formats and freely switch between the query engines without adjusting schemas.
Cons of AWS Athena
No Data Optimization: AWS Athena does noy offer a lot of customization capabilities. The farthest can go here is anoptimize the queries – not the underlying data. Even want try to replace Amazon S3 data using AWS Glu, still need to be careful not to harm to other services that access the same data.
Shared Resources: According to an Amazon’s Service Level Agreement (SLA), all AWS Athena users worldwide share the same resource when a running their queries.
This multi-tenancy approach can triggered a resource stress from time to time, leading to a fluctuating query performance.
Reduction in data manipulation operations: AWS Athena is just a query service, and that will find only one query engine here.It does not come with a build-in Data Manipulation Language (DML) interface for inserting, deleting, and for updating data.
Requires data partitioning: If intend to run the SQL queries efficiently, may want to partition the data set ssaved in Amazon S3. The number of partitions have to made will affect the speed and performance of the queries to a great extent.
For example, every 500 partitions scanned will improve a query time by one second.
Lack of indices: While indexing are always been a built-in provision in traditional databases, do not get this privilege with an AWS Athena.
As such should expect challenges in an operations such as consolidating large tables.