
- What is Data Clustering? | A Complete Guide For Beginners [ OverView ]
- What is Regression ? Know about it’s types
- What is Lasso Regression? : Learn With examples
- What is Ridge Regression? Learn with examples
- What is Linear Regression? | A Complete Guide
- What is Linear Regression in Machine Learning?
- Bagging vs Boosting in Machine Learning | Know Their Differences
- What is a Confusion Matrix in Machine Learning? : A Complete Guide For Beginners
- What Is Machine Learning | How It Works and Techniques | All you need to know [ OverView ]
- Support Vector Machine (SVM) Algorithm – Machine Learning | Everything You Need to Know
- Decision Trees in Machine Learning: A Complete Guide with Best Practices
- Pattern Recognition and Machine Learning | A Definitive Guide | Everything You Need to Know [ OverView ]
- An Overview of ML on AWS : Computer Vision, Forecasting
- Keras vs TensorFlow – What to learn and Why? : All you need to know
- Machine Learning Engineer Salary | Required Skills | Everything You Need to Know
- The Best Machine Learning Tools
- Best Deep Learning Books to Read
- Top Machine Learning Projects for Beginners
- Top Machine Learning Algorithms You Need to Know
- What is Data Clustering? | A Complete Guide For Beginners [ OverView ]
- What is Regression ? Know about it’s types
- What is Lasso Regression? : Learn With examples
- What is Ridge Regression? Learn with examples
- What is Linear Regression? | A Complete Guide
- What is Linear Regression in Machine Learning?
- Bagging vs Boosting in Machine Learning | Know Their Differences
- What is a Confusion Matrix in Machine Learning? : A Complete Guide For Beginners
- What Is Machine Learning | How It Works and Techniques | All you need to know [ OverView ]
- Support Vector Machine (SVM) Algorithm – Machine Learning | Everything You Need to Know
- Decision Trees in Machine Learning: A Complete Guide with Best Practices
- Pattern Recognition and Machine Learning | A Definitive Guide | Everything You Need to Know [ OverView ]
- An Overview of ML on AWS : Computer Vision, Forecasting
- Keras vs TensorFlow – What to learn and Why? : All you need to know
- Machine Learning Engineer Salary | Required Skills | Everything You Need to Know
- The Best Machine Learning Tools
- Best Deep Learning Books to Read
- Top Machine Learning Projects for Beginners
- Top Machine Learning Algorithms You Need to Know

What Is Machine Learning | How It Works and Techniques | All you need to know [ OverView ]
Last updated on 04th Nov 2022, Artciles, Blog, Machine Learning
- In this article you will get
- Machine Learning Techniques
- How does machine learning work?
- Supervised learning
- Unsupervised Learning
- Conclusion
Machine Learning Techniques
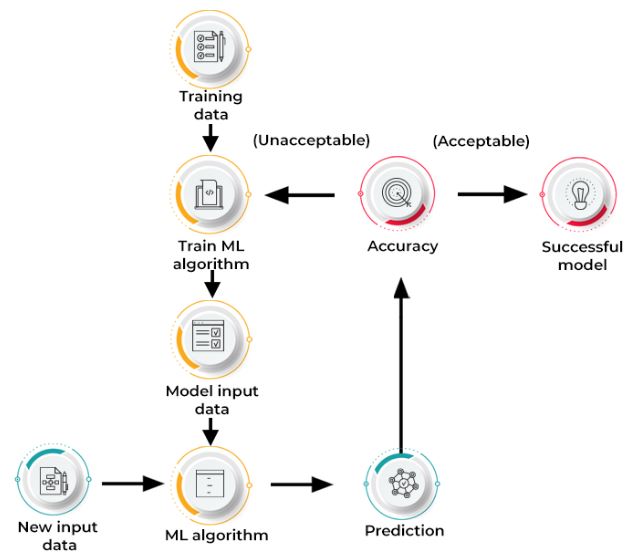
Machine learning is the data analytics technique that teaches a computers to do what comes are naturally to humans and animals: Learn from an experience. Machine learning algorithms use the computational methods to directly “learn” from a data without relying on predetermined equation as model.As number of samples available for a learning increases, the algorithm adapts to an improve performance. Deep learning is the special form of a machine learning.
How does a machine learning work?
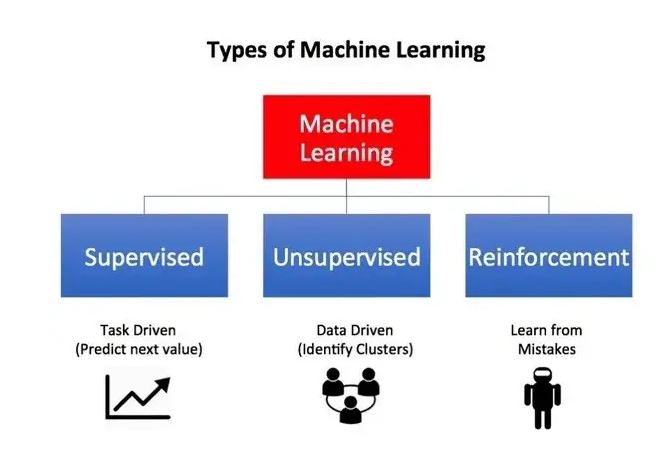
Machine learning uses a two techniques: supervised learning, which trains the model on known input and output data to predict a future outputs, and unsupervised learning, which uses a hidden patterns or internal structures in a input data.
Supervised learning
Supervised machine learning creates the model that makes predictions based on a evidence in presence of uncertainty. A supervised learning algorithm takes known set of an input data and known responses to a data (output) and trains a model to create reasonable predictions for the response to a new data. Use a supervised learning if have known data for output are trying to be estimate.
Supervised learning uses a classification and regression techniques to develop a machine learning models. Classification models classify a input data. Classification techniques predict a discrete responses. For example, an email is genuine, or spam, or tumor is cancerous or benign.
Use taxonomy if data can be tagged, classified, or divided into the specific groups or classes. For example, an applications for handwriting recognition use a classification to recognize a letters and numbers. In image processing and a computer vision, unsupervised pattern recognition techniques are used for an object detection and an image segmentation. Common algorithms for performing the classification include a support vector machines (SVMs), boosted and bagged decision trees, k-nearest neighbors, Naive Bayes, discriminant analysis, logistic regression, and a neural networks.
Regression techniques predict a continuous responses – for example, changes in a temperature or fluctuations in an electricity demand. Typical applications include the power load forecasting and an algorithmic trading.
If working with the data range or if the nature of a response is a real number, such as a temperature or the time until a piece of an equipment fails, use a regression techniques.
Common regression algorithms include a linear, nonlinear models, regularization, stepwise regression, boosted and a bagged decision trees, neural networks, and an adaptive neuro-fuzzy learning.
Physicians need to predict whether someone will have heart attack within a year. They have data on a previous patients, including age, weight, height, and blood pressure. They know if a previous patients had had a heart attack within year. So problem is to combine an existing data into a model that can predict whether new person will have heart attack within a year.
Unsupervised Learning
A Detects hidden patterns or an internal structures in unsupervised learning data. It is used to remove datasets containing an input data without a labeled responses.
Clustering is the common unsupervised learning technique. It is used for an exploratory data analysis to find a hidden patterns and clusters in a data. Applications for the cluster analysis include a gene sequence analysis, market research, and commodity identification.
For example, if cell phone company needs to optimize the locations where they are build towers, they can use a machine learning to predict how many people their towers are based on.
A phone can only talk to the 1 tower at a time, so team uses a clustering algorithms to design a good placement of cell towers to can optimize signal reception for groups or groups of a customers.
Common algorithms for a performing clustering are like k-means and k-medoids, hierarchical clustering, Gaussian mixture models, hidden Markov models, self-organizing maps, fuzzy C-means clustering, and a subtractive clustering.
Ten methods are described and it is a foundation can build on to improve the your machine learning knowledge and skills:
- Regression
- Classification
- Clustering
- Dimensionality Reduction
- Ensemble Methods
- Neural Nets and Deep Learning
- Transfer Learning
- Reinforcement Learning
- Natural Language Processing
- Word Embedding’s
Let’s differentiate between the two general categories of a machine learning: supervised and unsupervised. Apply a supervised ML techniques when have a piece of data that need to predict or interpret. Use a previous and output data to predict a output based on a new input.
For example, can use a supervised ML techniques to help service business that wants to estimate a number of new users that will sign up for the service in a next month. In contrast, untrained ML looks at a ways of connecting and grouping of data points without using a target variables to make predictions.
In other words, it evaluates a data in terms of a traits and uses traits to group objects that are similar to the each other. For example, can use a unsupervised learning techniques to help retailer who need to segment products with the similar characteristics-without specifying in an advance which features to use.
1.Regression:
Regression methods fall under a category of supervised ML. They help to predict or interpret a specific numerical value based on a prior data, such as predicting the asset’s price based on past pricing data for a similar properties. The simplest method is a linear regression, where use a mathematical equation of the line (y = m * x + b) to model a data set. Train a linear regression model with the multiple data pairs (x, y) by computing a position and slope of a line that minimizes a total distance between all data points and the line. In the other words, calculate a slope (M) and the y-intercept (B) for line that best approximates an observations in the data.
2.Classification:
In another class of a supervised ML, classification methods predict or explain the class value. For example, they can help to predict whether an online customer will purchase product. Output can be yes or no: buyer or no buyer. But methods of classification are not limited to the two classes. For example, a classification method can help tp assess whether a given image contains car or a truck. The simplest classification algorithm is a logistic regression, which sounds like the regression method, but it is not. Logistic regression estimates a probability of occurrence of event based on a one or more inputs.
3.Clustering:
Fall into the untrained ML with clustering methods because they aim to group or group observations with a similar characteristics. Clustering methods do not use a output information for training but instead let algorithm explain the output. In a clustering methods, can only use visualization to observe a quality of solution.
4.Dimensionality Reduction:
Use a dimensionality reduction to remove least important information from a data setFor example, and images may consist of a thousands of pixels, which are unimportant to the analysis. Or, when testing microchips within manufacturing process, may have thousands of measurements and tests applied to every chip, many of which offer a redundant information. In these cases, need a dimensionality reduction algorithm to make a data set manageable.
5.Ensemble Methods:
Imagine that y have decided to build the bicycle because are not happy with options available in a stores and online. Once have assembled these great parts, resulting bike will outlast all the other options.Every model uses a same idea of combining the multiple predictive models (supervised ML) to obtain a higher quality predictions than the model.
6.Neural networks and deep learning:
Unlike linear and logistic regression, which is considered a linear models, neural networks aim to capture a nonlinear patterns in a data by adding layers of parameters to model. The simple neural net has a three inputs as in image below, a hidden layer with a five parameters and an output layer.
Conclusion
Machine learning is the branch of artificial intelligence (AI) and computer science which focuses on use of data and an algorithms to imitate the way that humans learn, gradually improving its be accuracy.