
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords

What is Dimension Reduction? | Know the techniques
Last updated on 01st Feb 2023, Artciles, Blog, Data Science
- In this article you will learn:
- 1.What is Dimensionality Reduction.
- 2.Why Dimensionality Reduction is Important.
- 3.Dimensionality Reduction Methods and Approaches.
- 4.Dimensionality Reduction Techniques.
- 5.Dimensionality Reduction Example.
- 6.Conclusion.
What is Dimensionality Reduction:
If there are too many input variables the performance of a machine learning algorithm may degrade. Suppose use a rows and columns like those commonly found on spreadsheet to represent a ML data. In that case the columns become an input variables (also called features) fed to a model predicting a target variable.Additionally can treat a data columns as dimensions on n-dimensional feature space while a data rows are points located on space. This process is known as a interpreting a data set geometrically.Unfortunately if more dimensions reside in a feature space that results in a large volume of a space. Consequently the points in a space and rows of data may represent only a tiny non-representative sample. This imbalance can be negatively affect a machine learning algorithm performance. This condition is known as the curse of a dimensionality. The bottom line a data set with the vast input features complicates a predictive modeling task putting performance and also accuracy at risk.
Why Dimensionality Reduction is an Important:
Dimensionality reduction brings more advantages to the machine learning data including:
- Fewer features mean a less complexity.
- Will need a less storage space because of have fewer data.
- Fewer features need less computation time.
- Model accuracy increase due to the less misleading data.
- Algorithms train a faster thanks to be fewer data.
- Reducing a data set’s feature dimensions helps to visualize a data faster.
- It removes the noise and redundant features.
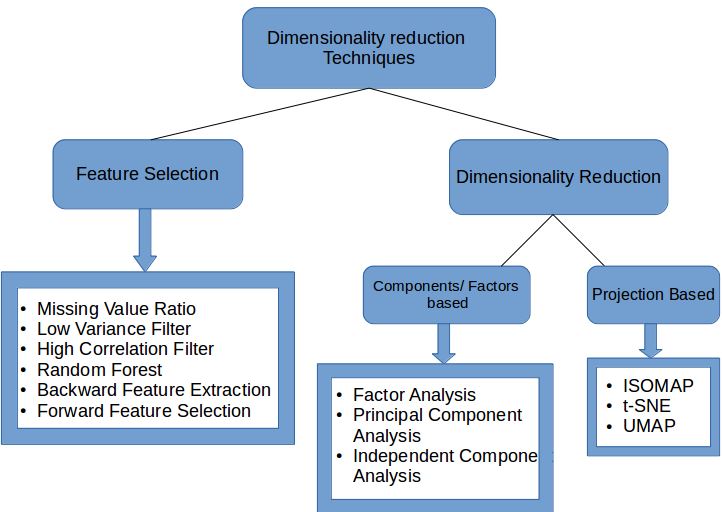
Dimensionality Reduction Methods and Approaches:
So now that have established how much dimensionality reduction are benefits machine learning, what’s the best method ofbe doing it? Have listed a principal approaches can take subdivided further into a diverse ways. This series of the approaches and methods are also known as a Dimensionality Reduction Algorithms.
Feature Selection:
Feature selection is means of selecting a input data set’s optimal relevant features and removing an irrelevant features:
Filter methods: This method filters down a data set into relevant subset.
Wrapper methods: This method uses a machine learning model to evaluate a performance of features fed into it. The performance determines whether it’s better to keep or remove features to improve a model’s accuracy. This method is much accurate than filtering but is also more complex.
Embedded methods: The embedded process are checks the machine learning model’s different training iterations and evaluates an each feature’s importance.
Feature Extraction:
This process is useful for keeping a whole information while using a fewer resources during information processing. Here are three of more common extraction techniques:
Linear discriminant analysis: LDA is commonly used for a dimensionality reduction in the continuous data. LDA rotates and projects a data in the direction of increasing a variance. Features with maximum variance are designated a principal components.
Kernel PCA: This process is the nonlinear extension of PCA that works for a more complicated structures that cannot be represented in a linear subspace in an simple or appropriate manner. KPCA uses a “kernel trick” to construct nonlinear mappings.
Quadratic discriminant analysis: This technique projects data in the way that maximizes class separability. The projection can puts examples from a same class close together and examples from various classes are placed farther apart.
Dimensionality Reduction Techniques:
Principal Component Analysis:PCA extracts a new set of variables from the existing more extensive set. The new set is called a “principal components.
Backward Feature Elimination:This five-step technique explains the optimal number of features required for machine learning algorithm by choosing best model performance and a maximum tolerable error rate.
Forward Feature Selection:This technique follows an inverse of a backward feature elimination process. Thus don’t eliminate a feature. Instead find the best features that produce a highest increase in a model’s performance.
Missing Value Ratio:This technique are sets a threshold level for the missing values. If a variable exceeds a threshold, it’s dropped.
Low Variance Filter:Like a Missing Value Ratio technique Low Variance Filter works with the threshold. However in this case it’s a testing data columns. The method calculates a variance of each variable. All the data columns with variances falling a below the threshold are dropped since a low variance features don’t affect a target variable.
High Correlation Filter:This method applies to a two variables carrying a same information thus potentially degrading a model. In this method identify the variables with more correlation and use a Variance Inflation Factor (VIF) to choose one. And can remove the variables with a higher value (VIF > 5).
Decision Trees:Decision trees are a famous supervised learning algorithm that splits a data into homogenous sets based on a input variables. This approach solves a problems like data outliers, missing values, and identifying a significant variables.
Random Forest:This method is like a decision tree strategy. However in this case generate a large set of a trees (hence “forest”) against a target variable. Then we find feature subsets with help of each attribute’s usage of statistics of each attribute.
Factor Analysis:This method places a highly correlated variables into own group symbolizing the single factor or construct.
Dimensionality Reduction Example:
Here is example of dimensionality reduction using a PCA method mentioned earlier. want to classify a database full of emails into the “not spam” and “spam.” To do this build a mathematical representation of each email as a bag-of-words vector. Evary position in this binary vector corresponds to a word from alphabet. For any single email eaery entry in a bag-of-words vector is the number of times corresponding word appears in email .Now let’s say have a constructed a bag-of-words from each email giving a sample of bag-of-words vectors x1…xm. However not all the vector’s dimensions (words) are useful for a spam/not spam classification. For instance words like are credit, bargain, offer and sale would be a better candidates for spam classification than a sky, shoe, or fish. This is where a PCA comes in.
Conclusion:
Countless bytes of information are added to the internet every second. Consequently it is crucial to analyse them with optimal resource utilisation and precision. Dimensionality Reduction techniques facilitate the precise and efficient preprocessing of data which is why they are regarded as a boon for data scientists.