
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords

The Importance of Machine Learning for Data Scientists
Last updated on 26th Sep 2020, Artciles, Blog, Data Science
The Importance of Machine Learning for Data Scientists
The concept of Machine Learning, Artificial Intelligence (AI), Big Data has been around for a while. But the ability to apply algorithms and mathematical calculations to big data is gathering momentum only recently.
In this article we will discuss the importance of Machine Learning and why every Data Scientist must master it.
What is Machine Learning?
Simply put, we’re contributing to Machine Learning through our day to day interactions on the internet. Whether you search your coffee maker on Amazon, “top tips to lose weight” In Google, or “friends” in Facebook you see Machine Learning in action, but you don’t realize it.
It is the Machine Learning technology that lets Google, Amazon, and Facebook search engine offer relevant recommendations to the user.
These companies are able to keep tabs on your day to day activity, search behavior and shopping preference with the help of ML technology.
Machine Learning is also one of the main components of Artificial Intelligence.
Subscribe For Free Demo
Error: Contact form not found.
Who is a Data Scientist?
Before assessing the importance of Machine Learning for Data Scientists, here’s a brief note on who Data Scientists are. We’ll also discuss how one can become a Data Scientist.
Data Scientists draw meaningful information from a huge volume of data. They identify patterns and help build tools like AI-powered chatbots, CRMs, etc. to automate certain processes in a company.
With a sound knowledge of different Machine Learning techniques and contemporary technologies like Python, SAS, R, and SQL/NoSQL databases, Data Scientists perform in-depth statistical analysis.
The role of Data Scientist might sound like that of Data Analyst, but, in fact, they are different.
Difference between a Data Scientist and a Data Analyst
- Data scientists predict the future based on past patterns. Whereas, a Data Analyst curates meaningful insights from data.
- Data scientist’s work involves “estimation” (or prediction) unknown facts; while an analyst investigates the known facts.
- Data Analyst’s job is more geared towards businesses. Data Scientists’ work is integral to innovations and technological advances.
Why Machine Learning is So Important for a Data Scientist?
In the near future, process automation will superimpose most of the human-work in manufacturing. To match human capabilities, devices need to be intelligent and Machine Learning is at the core of AI.
Data Scientists must understand Machine Learning for quality predictions and estimations. This can help machines to take right decisions and smarter actions in real time with zero human intervention.
Machine Learning is transforming how data mining and interpretation work. It has replaced traditional statistical techniques with the more accurate automatic sets of generic methods.
Hence it is imperative for Data Scientists to acquire skills at Machine Learning.
4 Must Have Skills Required to Become a Machine Learning Expert
To become an expert at Machine Learning every Data Scientists must have the following 4 skills.
- Thorough knowledge and expertise in computer fundamentals. For example, computer organization, system architecture and layers, and application software.
- Knowledge of probability is very important because Data Scientists’ work involves a lot of estimation. Analyzing statistics is another area that they need to focus on.
- Data modeling for analyzing various data objects and how they interact with each other.
- Programming skills and a sound knowledge of programming languages like python and R. A quest for learning new database languages like NoSQL apart from traditional SQL and Oracle.
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
How radically does machine learning transform the data analysis avenue?
Data analysis has usually been considered by the experimental and error method – one that becomes impossible to use when there are important and varied data sets in question. It is for this very reason that big data was assessed for being promoted. The obtainability of more data is directly proportional to the difficulty of bringing in new analytical models that work precisely. Traditional statistical solutions are more attentive to static analysis that is limited to the analysis of samples that are solid in time. Enough, this could result in undependable and imprecise conclusions.
Machine learning has the capacity to give accurate results and analysis by developing efficient and fast algorithms and data-driven models for real-time processing of this data.
How data sciences get popularity in the machine learning industry?
Machine learning and data science both are like hand in hand. The definition of machine learning is the aptitude of a machine to simplify knowledge from data. Without any data, there is little that machines can learn. If anything, the increase in the practice of machine learning in many industries will act as a substance to push data science to increase significantly. Machine learning is one of the good as the data it is given and the skill of algorithms to consume it. Basic levels of machine learning will become a typical requirement for data scientists.
In data science, there is no lack of cool junk to do the glossy new algorithms to throw at data. However, what it does miss is why things work and how to solve non-standard problems, which is where machine learning will come into play.

Learn Machine Learning Training & Advance Your Career to Next Level
What every data scientist must know
Understandably, it is easy to get overwhelmed with how much there is to learn with ML. This article discusses the two important topics in ML that every data scientist should know.
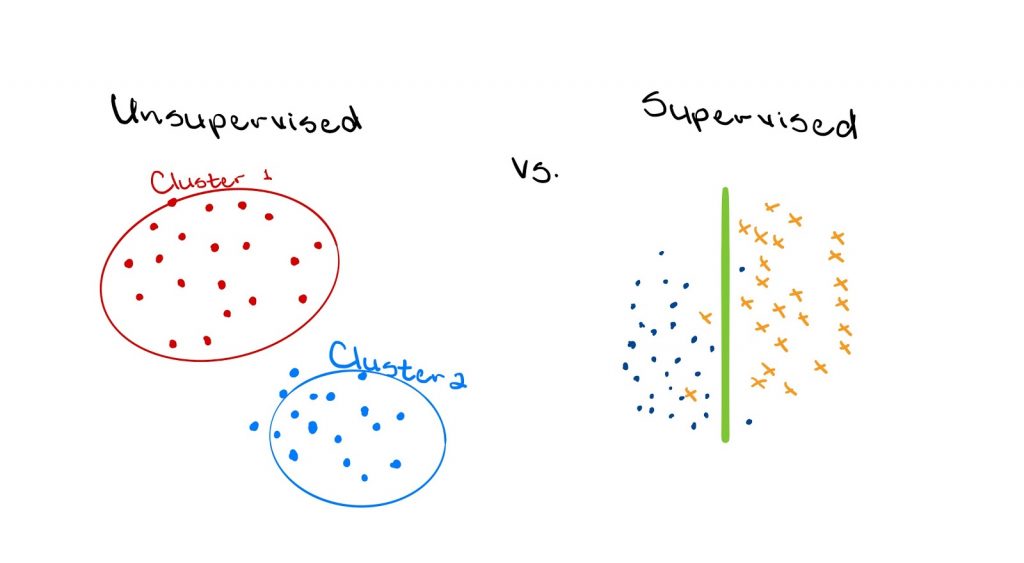
1.The Type of Learning
ML algorithms are often categorized as either supervised or unsupervised, and this broadly refers to whether the dataset being used is labelled or not. Supervised ML algorithms apply what has been learned in the past to new data by using labelled examples to predict future outcomes. Essentially, the correct answer is known for these types of problems and the estimated model’s performance is judged based on whether or not the predicted output is correct. In contrast, unsupervised ML algorithms refer to those developed when the information used to train the model is neither classified nor labelled. These algorithms work by attempting to make sense out of data by extracting features and patterns that can be found within the sample.
Now semi-supervised learning does exist, and it takes the middle ground between supervised and unsupervised learning. That is, a small portion of the data might be labelled, and the remainder is not.
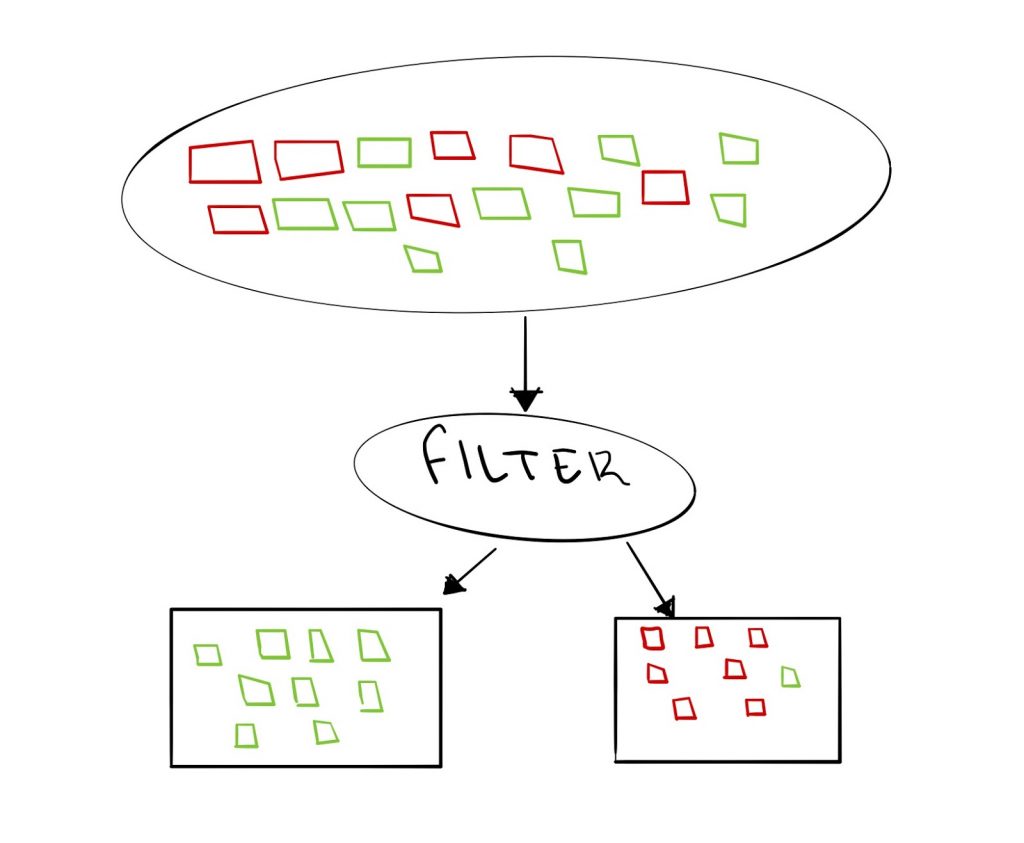
Supervised learning is useful when the task given is a classification or regression problem. Classification problems refer to grouping observations or input data into discrete ‘classes’ based on particular criteria developed by the model. A typical example of this would be predicting whether an email is spam or non-spam. The model would be developed and trained on a dataset containing both spam and non-spam emails, where each observation is appropriately labelled.
Regression problems, on the other hand, refer to the process of accepting a set of input data and determining a continuous quantity as the output. A common example of this is predicting an individual’s income, given their education level, gender, and the total amount of hours worked.
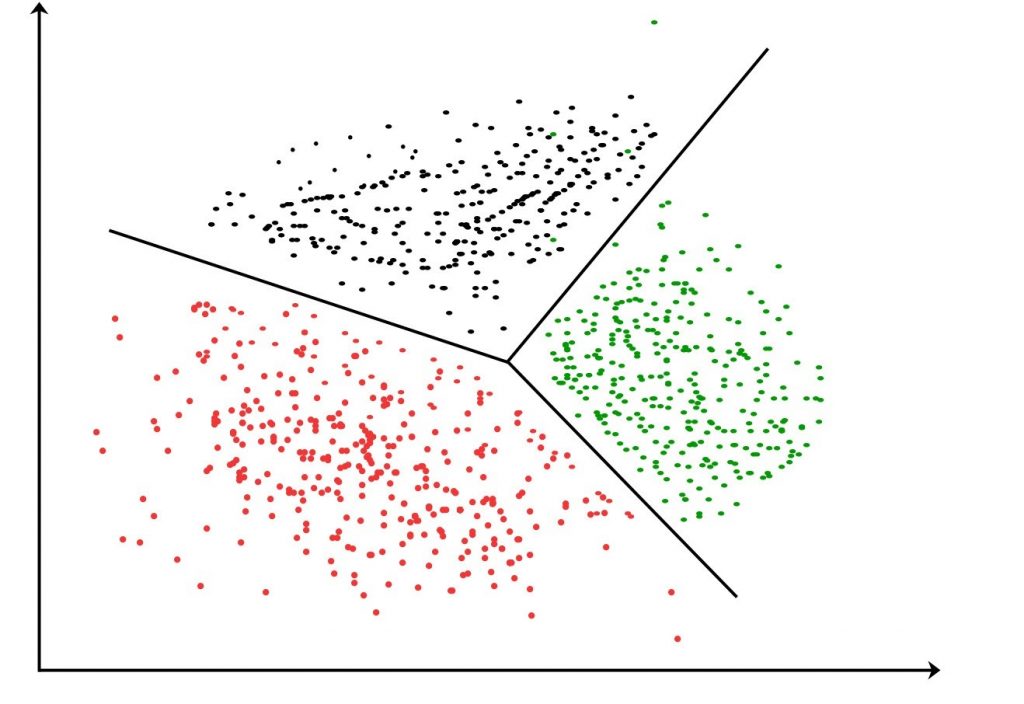
Unsupervised learning is most appropriate when the answer to a particular question is more or less unknown. These algorithms are mainly used for clustering and anomaly detection because it is possible to detect similarities throughout observations without knowing exactly what the observation refers to. For example, one can look at the colour, size, and shape of various flowers and then roughly separate them into groups without truly knowing the species of each flower. Additionally, consider a credit card company monitoring consumer behaviour. It would be possible to detect fraudulent transactions by monitoring where transactions have occurred. For example, consider a credit card is frequently used in New York. If on a particular day, the card is used in New York, Los Angeles and Hongkong, then it could be considered an anomaly and the system should alert the relevant parties.

2. Model Fitting
Fitting a model refers to making an algorithm determine the relationship between the predictors and the outcome so that future values can be predicted. Recall that the models are developed using training data, which is ideally a large random sample that accurately reflects a population. This necessary action comes with some very undesirable risks. Fully accurate models are difficult to estimate because sample data are subject to random noise. This random noise, along with the number of assumptions made by the researcher, has the potential to cause ML models to learn fake patterns within the data. If one tries to combat this risk by making too few assumptions, it can cause the model to not learn enough information from the data. These issues are known as overfitting and underfitting, and the goal is to determine an appropriate mix between simplicity and complexity.
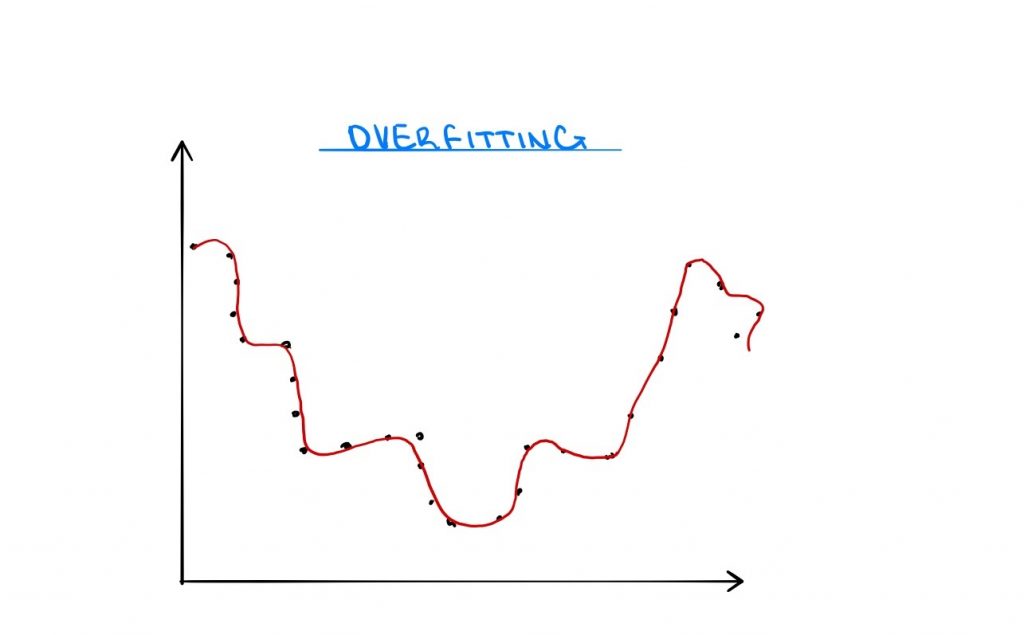
Overfitting occurs when a model learns ‘too much’ from the training data, including random noise. Models are then able to determine very intricate patterns within the data, but this negatively affects the performance on new data. The noise picked up in the training data does not apply to new or unseen data, and the model is unable to generalize the patterns found. Certain ML models are more prone to overfitting than others, and these include both nonlinear and nonparametric models. For these types of models, overfitting can be overcome altering the model itself. Consider a nonlinear equation to the 4th power. It is possible to reduce overfitting by reducing the power of the model to maybe the 3rd power once acceptable results will still be produced. Alternatively, overfitting can be limited by applying cross-validation or regularization to the model parameters.
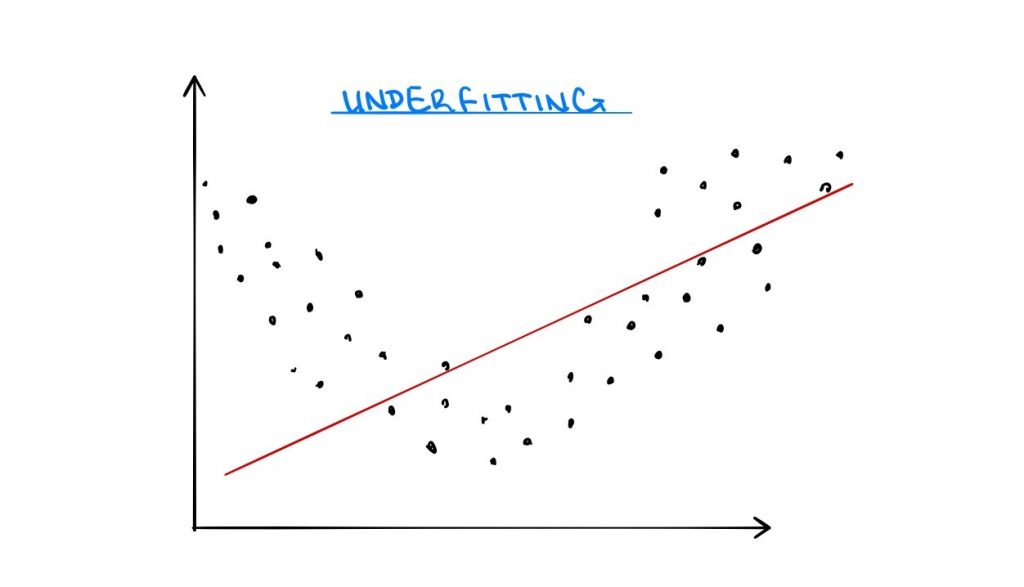
Underfitting, on the other hand, occurs when a model is unable to learn a sufficient amount of information from the training data. Then models are then unable to determine suitable patterns within the data, and this negatively affects the performance on new data. Since very little is learned, the model cannot apply much to unseen data and it is unable to generalize observations for the research problem at hand. Commonly, underfitting is as a result of model misspecification and can be fixed by using a more appropriate ML algorithm. For example, if a linear equation is used to estimate a nonlinear problem, underfitting will occur. Although this is true, underfitting can also be corrected through cross-validation and parameter regularization.
Cross-validation is a technique used to evaluate a model’s fit by training several models on various subsets of the sample dataset and then evaluating them on a complementary subset of the training set.
Regularization refers to the process of adding information to a model parameter in order to combat poor model performance. This can be through specifying that a parameter follows a particular distribution, such as the normal distribution versus a uniform distribution; or by giving a range of values that a parameter must fall within.

Machine learning models are extremely powerful, but with great power comes great responsibility. Developing the most appropriate ML model requires that the researcher adequately understands the problem at hand and what techniques will be suitable given the circumstance. Understanding whether a problem is supervised or unsupervised will provide some insight into what type of ML algorithm will be used; while understanding the model fit can prevent poor model performance when deployed. Happy modelling!
Conclusion
Data is the new oil.
IBM predicts that the global demand for Data Scientists will rise 28% by 2020. Finance, Insurance, Professional services and IT sectors will cover 59% of the Data Science and Analytics job demand.
In the coming future, Machine Learning is going to be one of the best solutions to analyze high volumes of data. Therefore, Data Scientists must acquire an in-depth knowledge of Machine Learning to boost their productivity.