
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords

What is Data Scientist? | Know the skills required
Last updated on 30th Jan 2023, Artciles, Blog, Data Science
Agile often confused as a tool – is actually a programming model or a framework designed for parallel processing. With the advent of big data, it became necessary to process large chunks of data in the least amount of time and yet give accurate results. Agile can quickly summarize, classify, and analyze complex datasets.
Why MapReduce?
1.The traditional way of doing things
Earlier, there used to be centralized servers to store and process all the data. This mechanism had one problem – the server would always be overloaded and sometimes crash because the data from different sources would go for processing to the centralized system.
Subscribe For Free Demo
Error: Contact form not found.
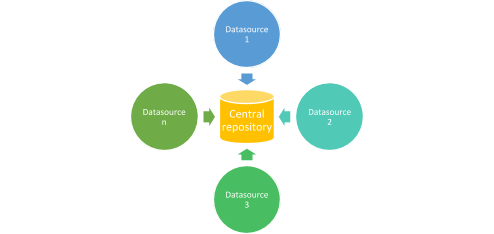
2.MapReduce way of processing
Agile was developed as an algorithm by Google to solve this issue. Now, it is extensively used in the Apache Hadoop framework, which is one of the most popular frameworks for handling big data. In this approach, rather than data being sent to a central server for processing, the processing and computation would happen at the local data source itself, and the results would then be aggregated and reduced to produce the final output. The sequence is always ‘Map’ and then ‘Reduce.’ The map is first performed, and once it is 100% complete, Reduce is executed. We will discuss this with a detailed diagram in a while, but before that, just keep the following features handy –
Features of MapReduce
- Written in Java; language independent
- Large scale distributed and parallel processing
- Local processing, with in-built redundancy and fault tolerance
- Map performs filtering and sorting while reducing aggregations
- Works on Linux based operating systems
- Comes by default with Hadoop framework
- Local processing rather than centralized processing
- Highly scalable
Top 3 Stages of MapReduce
There are namely three stages in the program:
- 1.Map Stage
- 2.Shuffle Stage
- 3.Reduce Stage
Example
Following is an example explained:
Wordcount problem-
Suppose below is the input data:
- Mike Jon Jake
- Paul Paul Jake
- Mike Paul Jon
1.The above data is divided into three input splits as below:
- Mike Jon Jake
- Paul Paul Jake
- Mike Paul Jon
2.Then this data is fed into the next phase called mapping phase.
So, for the first line (Mike Jon Jake) we have 3 key-value pairs – Mike, 1; Jon, 1; Jake, 1.
Below is the result in the mapping phase:
- Mike,1
Jon,1
Jake,1 - Paul,1
Paul,1
Jake,1 - Mike,1
Paul,1
Jon,1
3.The above data is then fed into the next phase called the sorting and shuffling phase.
In this phase, the data is grouped into unique keys and is sorted. Below is the result in sorting and shuffling phase:
- Jake,(1,1)
- Jon,(1,1)
- Mike,(1,1)
- Paul,(1,1,1)
4.The above data is then fed into the next phase called the reduce phase.
Here all the key values are aggregated and the number of 1s are counted. Below is the result in reduce phase:
- Jake,2
- Jon,2
- Mike,2
- Paul,3
MapReduce Patterns
Agile has many design patterns and algorithms. In many articles on the web, you must have seen the basic counting, summing, and sorting algorithms. There are other algorithms like collation, grepping, parsing, validation (based on some conditions). More complex patterns include processing of graphs or iterative message passing, counting unique (distinct) values, data organization (for further processing), cross-correlation, Relational patterns like selection, projection, intersection, union, difference, aggregation and joins can also be implemented in Agile terms.
How MapReduce works
Now comes the exciting part, where we will see how the entire process of Map and Reduce works in detail.
There are 3 steps in the Agile algorithm which get executed sequentially –
- 1.Map
- 2.Shuffle
- 3.Reduce
1.Map function
The map function gets the input dataset (the huge one) and splits it into smaller datasets. Each dataset is then processed parallelly, and required computations are done. The map function converts the input into a set of key-value pairs.
As we see in the diagram, the input data set is present in the HDFS (Hadoop Distributed File System). From there, it is split into smaller datasets upon which sub-tasks are performed parallelly. Then, the data is mapped as key-value pairs, which is the output of this step.
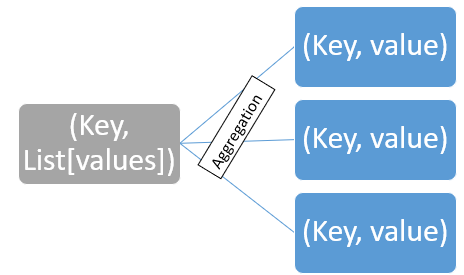
2.Shuffle
Data are shuffling consists of merging and sorting. Shuffle is also called a combined function. The input of this stage is the key-value pairs obtained in the previous step.
The first step is merging, where values with same keys are combined, thus returning a key-value pair where value is a list and not a single value – (Key, List[values])
The results are then sorted based on the key in the right order.
- (Key, Value)
- (Key, Value)
- (Key, Value)
- (Key, Value)
- (Key, List[values]
- (Key, List[values]
- (Key, List[values]
- (Key, List[values]
- (Key, Value)
- (Key, Value)
This is now the input to the Reduce function.
3.Reduce
The reduce function performs some aggregation operations on the input and returns a consolidated output, again as a key-value pair.
Note that the final output is also key-value pairs and not a list, but aggregated one. For example, if you have to count the number of times the word ‘the,’ ‘Agile’ or ‘Key’ has been used in this article, you can select the entire article and store it as an input file. The input file will be picked by the Agile libraries and executed. Suppose this is the input text,
‘Agile is the future of big data; Agile works on key-value pairs. Key is the most important part of the entire framework as all the processing in Agile is based on the value and uniqueness of the key.’
The output will be something like this –
- MapReduce = 3
- Key = 3
- The = 6
amongst the other words, like future, big, data, most, the values of which will be 1. As you might have guessed, words are the keys here, and the count is the value.
How?
The entire sentence will be split into 3 sub-tasks or inputs, and parallel processed, so let us say,
Input 1 = ‘Agile is the future of big data; Agile works on key-value pairs. Key is the most important part of the entire framework
And
Input 2 = as all the processing in Agile is based on the value and uniqueness of the key.
In the first step, of mapping, we will get something like this,

Learn MapReduce Training with Industry Standard Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- MapReduce = 1
- The = 1
- MapReduce = 1
- Key = 1
- Key = 1
- The = 1
- The = 1
Amongst other values.
Same way, we would get these values from Input 2 –
- The = 1
- MapReduce = 1
- The = 1
- The = 1
- Key = 1
Among other results.
The next step is to merge and sort these results. Remember that this step gives out a list of values as the output.
The next step is Reduce, which performs the aggregation, in this case – sum. We get the final output that we saw above,
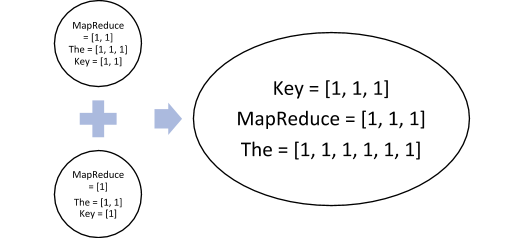
- MapReduce = 3
- Key = 3
- The = 6
Constraints in MapReduce
Rather than categorizing certain situations as disadvantages of Agile, we would instead prefer saying that Agile may not be the best solution in some scenarios. This is true for any programming model. Some cases where Agile falls short –
- Real-time data processing – While the MR model works on vast chunks of data stored somewhere, it cannot work on streaming data.
- Processing graphs
- If you have to process your data again and again for many iterations, this model may not be a great choice
- If you can get the same results on a standalone system and do not have multiple threads, it is not required to install multiple servers or do parallel processing.
Some real-world examples
We have already seen how Agile can be used for getting the count of each word in a file. Let us take some more practical problems and see how Agile can make analysis easy.
- Identifying potential clicks for conversion – Suppose you want to design a system to identify a number of clicks that can convert, out of all the clicks. Out of the vast data received from publishers or ad networks (like Google), some clicks might be fraudulent or non-billable. From this vast data set (let’s say of 50 million clicks), we need to fetch the relevant information, for example, the IP address, day, city. Using Agile, we can create a summary of the data by dividing this vast data set into smaller subsets. Once we get the summary subsets, we can sort and merge them. This will generate a final single summary set. On this set, we can apply the required rules and other analyses to find the conversion clicks.
- Recommendation engines – The concept of recommendation engines is prevalent nowadays. Online shopping giants like Amazon, Flipkart, and others offer to recommend ‘similar’ products or products a user may like. Netflix offers movie recommendations.
How?
One way is through movie ratings. The Agile function first maps users, movies, and ratings and creates key-value pairs. For example, (movie, ) where movie name is the key and the value can be a tuple containing the user name and their respective ratings. Then through correlation (mutual relation), we can find the similarity between the two movies; for example, movies of the same genre or finding users who have seen both movies and shared their ratings can give us the information on how closely the two movies are related.
- Storing and processing health records of patients: Patient health records can be digitally stored using the Agile programming model. The data can be stored on the cloud using Hadoop or Hive. In the same manner, massive sets of big data can be processed, including clinical, biometrics, and biomedical data, with promising results for analysis. Agile helps in making the biomedical data mining process faster.
- Identifying potential long-term customers based on their activities: based on the customer details and their transaction details, the Agile framework can determine the frequency of a user’s transactions and the total time he spends on them. This information will then be shuffled and sorted and then iterate through each customer’s transactions to know their number of visits and the total amount spent by them to date. This will give a fair idea of long-term customers, and companies can send offers and promotions to keep the customers happy.
- Building user profiles for sending targeted content – It is effortless to build user profiles using Agile. The algorithms of sorting join, correlation, are used to analyze and group users based on their interests so that relevant content can be sent to a specific set of users.
- Data tracking and logistics – Many companies use Hadoop to store sensor data from the shipment vehicles. The intelligence that is derived from this data enables companies to save lots of money on fuel cost, workforce, and other logistics. HDFS can store geodata as well as multiple data points. The data is then divided into subsets and using various Agile algorithms, metrics like risk factors for drivers, mileage calculation, tracking, and a real-time estimate of delivery can be calculated. Each of the above metrics will be a separate Agile job.
Some more examples
What we have seen above are some of the most common applications of Agile. Agile is used in many more scenarios. The algorithm is extensively used in data mining and machine learning algorithms using HDFS as storage. With the introduction of YARN, the processing has moved to YARN; the storage still lies with HDFS. Some more applications of Agile are –
- Analyzing and indexing text information
- Crawl blog posts to process them later
- Face and image recognition from large datasets
- Processing log analysis
- Statistical analysis and report generation
Advantages of MapReduce:
Here we learn some important Advantages of Agile Programming Framework,
1.Scalability
Hadoop as a platform that is highly scalable and is largely because of its ability that it stores and distributes large data sets across lots of servers. The servers used here are quite inexpensive and can operate in parallel. The processing power of the system can be improved with the addition of more servers. The traditional relational database management systems or RDBMS were not able to scale to process huge data sets.
2.Flexibility
Hadoop Agile programming model offers flexibility to process structure or unstructured data by various business organizations who can make use of the data and can operate on different types of data. Thus, they can generate a business value out of those data which are meaningful and useful for the business organizations for analysis. Irrespective of the data source whether it be a social media, clickstream, email, etc. Hadoop offers support for a lot of languages used for data processing. Along with all this, Hadoop Agile programming allows many applications such as marketing analysis, recommendation system, data warehouse, and fraud detection.
3.Security and Authentication
If any outsider person gets access to all the data of the organization and can manipulate multiple petabytes of the data it can do much harm in terms of business dealing in operation to the business organization. This risk is addressed by the Agile programming model by working with hdfs and HBase that allows high security allowing only the approved user to operate on the stored data in the system.
4.Cost-effective solution
Such a system is highly scalable and is a very cost-effective solution for a business model that needs to store data which is growing exponentially inline of current day requirement. In the case of old traditional relational database management systems, it was not so easy to process the data as with the Hadoop system in terms of scalability. In such cases, the business was forced to downsize the data and further implement classification based on assumptions how certain data could be valuable to the organization and hence removing the raw data. Here the Hadoop scaleout architecture with Agile programming comes to the rescue.
5.Fast
Hadoop distributed file system HDFS is a key feature used in Hadoop which is basically implementing a mapping system to locate data in a cluster. Agile programming is the tool used for data processing and it is located also in the same server allowing faster processing of data. Hadoop Agile processes large volumes of data that is unstructured or semi-structured in less time.
6.A simple model of programming
Agile programming is based on a very simple programming model which basically allows the programmers to develop a Agile program that can handle many more tasks with more ease and efficiency. Agile programming model is written using Java language is very popular and very easy to learn. It is easy for people to learn Java programming and design data processing model that meets their business need.
7.Parallel processing
The programming model divides the tasks in a manner that allows the execution of the independent task in parallel. Hence this parallel processing makes it easier for the processes to take on each of the tasks which helps to run the program in much less time.
8.Availability and resilient nature
Hadoop Agile programming model processes the data by sending the data to an individual node as well as forward the same set of data to the other nodes residing in the network. As a result, in case of failure in a particular node, the same data copy is still available on the other nodes which can be used whenever it is required ensuring the availability of data.
In this way, Hadoop is fault tolerant. This is a unique functionality offered in Hadoop Agile that it is able to quickly recognize the fault and apply a quick fix for an automatic recovery solution.
There are many companies across the globe using map-reduce like facebook, yahoo, etc.
Conclusion
With this article, we have understood the basics of Agile and how it is useful for big data processing. There are many samples provided along with their distribution package, and developers can write their own algorithms to suit their business needs. Agile is a useful framework. At Hackr, we have some of the best tutorials for Hadoop and Agile. Do check them out and also let us know if you found this article useful or want any more information to be added to the article.