
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords

What is Data ? All you need to know [ OverView ]
Last updated on 27th Oct 2022, Artciles, Blog, Data Science
- In this article you will get
- 1.What is data?
- 2.What is meant by the term “data”?
- 3.What does it mean to have information?
- 4.What kind of storage mechanisms are in place?
- 5.What is meant by the term “Data Processing Cycle”?
- 6. What is Data, What Are the Different Types of Data, and How Should Data Be Analyzed?
- 7.What exactly does “Data” mean?
- 8.What exactly is the information?
- 9.How do we analyze data?
- 10. Top 5 Jobs in the Data Industry
- 11.Advantages of data
- 12.Conclusion
What is data?
The price or quality of something can be the data. Because it is managed and analysed in a variety of ways, understanding the differences between quantity and quality data is very important. For instance, you cannot calculate the statistics of quality data, and you cannot utilise native language preparation techniques for quantitative data. Both of these are examples of situations in which you cannot use either of these approaches.
What is meant by the term “data”?
The meaning of “is data” comes from the fact that data consists of various kinds of information that are often arranged in a specific way. Programs and data are the two primary components that make up any piece of software. We are already familiar with the concept of data, and we can define programmes as collections of instructions that are used to modify data.Let’s look at some fascinating information after we’ve gained a basic comprehension of what data and data science are.But first things first: when we talk about “information,” what do we mean exactly? Let’s take a step back and examine the basics of the situation, shall we?
What does it mean to have information?
Data that has been categorized or arranged and possesses some meaningful value for the user is what is referred to as information. The processed data that is used to make decisions and take action is also considered to be information. In order for processed data to be of any major use in decision-making, it is necessary for the data to satisfy the following criteria:
- Accuracy It is essential that the information be correct.
- The information needs to be comprehensive in every respect.
- The information must be accessible at the precise moment that it is required to be so.
The Many Forms and Functions of Data:
The expansion of the technological sector, particularly in the realm of smartphones, has resulted in the inclusion of text, video, and audio under the category of data, in addition to online browsing history and activity logs. The majority of this data does not follow any particular structure.
The data that is in the petabyte range or higher is what is meant when the phrase “Big Data” is used to describe it in the definition of data. The terms “variety,” “volume,” “value,” “veracity,” and “velocity” are also used to refer to “big data.” In today’s world, business models that are based on Big Data have arisen, and these models handle data as if it were an asset in and of itself. Additionally, web-based eCommerce has experienced massive expansion. In addition to this, there are a plethora of advantages to utilising big data, such as decreased expenses, increased productivity, increased sales, and many more.
The meaning of data has expanded well beyond the mere processing of data that is performed inside the realm of computer applications. For instance, briefly describing what data science is has already been done here. Accordingly, the fields of finance, demographics, health, and marketing all have their own unique definitions of data, which ultimately leads to a variety of responses to the age-old question, “What is data?”
What kind of storage mechanisms are in place?
The representation of information in computers, such as text, images, sounds, and videos, is done using binary values, which consist of just two numbers: 1 and 0. A single value is represented by the “bit,” the most fundamental unit of data storage, which is also the smallest unit of data. In addition, there are eight individual bits that make up a byte. Memory and storage space can be measured using a variety of different unit sizes, including megabytes, gigabytes, terabytes, petabytes, and exabytes. As the amount of data that our society creates continues to increase, data scientists are always developing new data measurements that are more precise and comprehensive.
There are numerous file formats for the conversion, processing, and storing of data, such as comma-separated values. Data can be stored in file formats utilising mainframe systems like as ISAM and VSAM. Other file formats, such as tab-delimited values, are also available. In spite of the fact that more structured-data-oriented approaches are getting a better foothold in the modern world of information technology, these data formats are nevertheless used across a wide variety of machine kinds.
Since the introduction of the database, the database management system, and most recently, relational database technology, the field of data storage has become increasingly specialised. This is due to the fact that each of these innovations introduced new ways of arranging information and contributed to the field’s growth.
What is meant by the term “Data Processing Cycle”?
Processing data is described as the act of reorganising or restructuring data for the aim of increasing its usability and adding value for a certain purpose or function. This can be done by humans or by machines. Input, processing, and output are the three primary stages that make up the standard data processing procedure. The cycle of processing data is comprised of these three stages taken together.
The data that is provided as input is formatted in a manner that is user-friendly for the processing machine and relies on the machine itself to perform the processing.
Processing: After that, the format of the input data is altered to be something that is more usable. For instance, information from timecards is utilized in the computation of wages for employees.
The results of the processing are gathered as the output data in the very last phase of the procedure. The form that the output data takes depends on what it is going to be utilized for. Continuing with the previous illustration, the data that is generated becomes the actual paychecks for the employees.
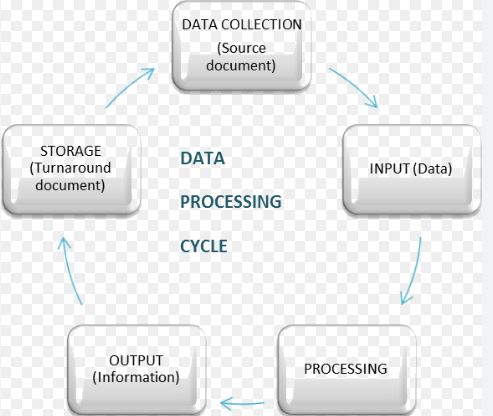
What is Data, What are the different types of data, and How should data be analyzed?
The Following Are Some of the Top Reasons to Become a Data Scientist: Jobs in Data Top 5 Jobs in the Data Industry People have been using the term “data” to refer to computer information ever since the development of computers. This information could be transferred or stored depending on the user’s preference. On the other hand, this is not the only definition of data; there are other additional categories of data.
What exactly does “Data” mean?
Programs and data are the two primary components that make up any and all software. We are already familiar with the concept of data, and we know that programmes are collections of instructions that are used to modify data.
We make the process of working with data simpler by utilising data science. Data science is a field that combines knowledge of mathematics, programming skills, domain expertise, scientific methods, algorithms, processes, and systems to extract actionable knowledge and insights from both structured and unstructured data, then applies the knowledge that was gleaned from that data to a wide range of uses and domains. The term “data science” was coined by computer scientist Ken Thompson in the 1980s.
Let’s investigate some fascinating information after we’ve gained a fundamental comprehension of what data and data science are. But first things first: what exactly do we mean when we say “information”? Let’s take a step back and examine the basics of the situation, shall we?
What exactly is the information?
The term “information” refers to data that has been categorised or structured and possesses some significant value for the user. Data that has been processed and is used to make decisions and take action is also considered information. For processed data to be of any major utility in decision-making, it is necessary for the data to satisfy the following criteria:
Accuracy: It is essential that the information be correct.
- Completeness is required, and all of the information must be provided.
- The information must be accessible at the appropriate time when it is required.
The various forms and functions of data:
The expansion of the technological sector, particularly in the realm of smartphones, has resulted in the categorization of text, video, and audio as data, in addition to web browsing history and activity logs. The vast majority of this data is in an unstructured format.
The data that is defined as being in the petabyte range or higher is referred to as “Big Data,” and the term “Big Data” is used to characterise this type of data. Big Data is sometimes referred to using the acronym 5Vs, which stands for variety, volume, value, veracity, and velocity. In today’s world, web-based eCommerce has experienced enormous growth, and business models built on big data have developed to the point where they view data as an asset in and of itself. In addition to this, there are other advantages to utilising big data, such as decreased expenses, increased productivity, increased sales, and many more.
How are the files saved?
The representation of information in computers, such as text, graphics, music, and video, is done using binary values, which consist of just two numbers: 1 and 0. A “bit” is the smallest unit of data that can store a single value, and its name comes from the word “bit.” In addition, there are eight bits in the length of a byte. Memory and storage space can be expressed using a variety of different unit sizes, including megabytes, gigabytes, terabytes, petabytes, and exabytes. As the amount of data that our society creates continues to increase, data scientists are always developing new data measurements that are more comprehensive.
There are numerous file formats for the conversion, processing, and storing of data, such as comma-separated values. Data can be stored in file formats utilising mainframe systems like as ISAM and VSAM. Other file formats, such as comma-delimited values, are also available. In spite of the fact that more structured-data-oriented approaches are getting a wider grip in the field of information technology today, these data formats are nevertheless used across a wide variety of machine kinds.
Since the introduction of the database, the database management system, and most recently, relational database technology, the field of data storage has become increasingly specialised. This is due to the fact that each of these innovations introduced novel approaches to the information organisation process.
How do we analyze data?
In an ideal world, there are two different approaches of analysing the data:
- 1. Data Analysis in Qualitative Research
- 2. Data Analysis in Quantitative Research
1. Data Analysis in Qualitative Research:
Due to the fact that the quality of the information consists of words, depictions, photos, objects, and sometimes images, data analysis and research in subjective information function somewhat better than they do with numerical information. Because gaining insight from such convoluted data is a challenging endeavour, exploratory research is typically conducted with it in addition to its usage in data analysis.
Identifying Trends and Patterns in the Qualitative Data:
A word-based technique is the method that is relied on the most and is the most often utilized global method for exploration and analysis of data. This is despite the fact that there are a few other ways to discover patterns in printed data. In qualitative research, the data analysis process is done manually, which is a significant limitation. In this step, the professionals would often read the available information and search for words that are repetitive or that are used frequently.
2.Data Analysis in Quantitative Research:
The process of getting the data ready for analysis:
When conducting research and analysing data, the first step is to do it for the examination with the intention of transforming the insignificant information into something significant. This is the fundamental stage. The following are the components that form the data preparation process.
- 1. Data Validation
- 2. Data Editing
- 3. Data Coding
When conducting quantitative statistical research, the application of descriptive analysis frequently produces superior data. Nevertheless, the analysis is seldom sufficient to establish the justification that lies behind such numbers. In spite of this, it is essential to give some thought to the most appropriate method that can be applied to the study and analysis of data pertinent to your review survey as well as the narrative that experts have to relay.
Therefore, in order for businesses to be successful in today’s hypercompetitive world, they need to have an exceptional capacity to analyse complicated research data, deduce significant pieces of knowledge, and adapt to the ever-changing requirements of the market.

Top Reasons to Become a Data Scientist: Work in Data
The applications of data that are described in the following paragraphs demonstrate why becoming a data scientist is a sensible career path to pursue.
- The field of data science can be utilized to discover risks and frauds. The financial industry was one of the first to make use of data science, and this remains one of the most prominent applications of this field today.
- The next sector is the Healthcare Industry. Data science is utilized in this setting for the purpose of studying medical imaging, genetics, and genomics. It is also applicable to the process of formulating new pharmaceuticals. And finally, becoming a patient’s virtual assistant is a huge benefit that comes from having this capability.
- A search on the internet is an additional application of data science. Data science methods are utilized by each and every search engine in order to display the intended results.
- The planning of airline routes, augmented reality gaming, targeted advertising, advanced recognition of photos, recognition of speed, and so on are only some of the many more applications of data science and artificial intelligence.
Top 5 Jobs in the Data Industry:
Several names of job titles that are now in great demand are provided in the following list.
1. Data Scientist:As was mentioned in the previous paragraph, this is currently one of the occupations that is in the most demand.
2. BIA:Business Intelligence Analysts assist businesses in producing beneficial judgments by making use of available data and providing the necessary advice to the firms they work for.
3. Person Who Develops Databases:The position of “database developer” comes in third on the list of the top five jobs in the field of data. They are concentrating their efforts mostly on enhancing the databases and creating new apps for making more effective use of the data.
4. Database Administrator:The Database Administrator is responsible for the initial setup of the databases, as well as their ongoing maintenance and protection.
5. Data Analytics Manager:In today’s world, an increasing number of businesses are beginning to rely on data managers in order to mine huge amounts of data for the information that is the most pertinent to their operations.
Advantages of data:
1. Performance and the Needs That Are Anticipated:
Organizations are coming under an increasing amount of pressure from their competitors to not only locate customers but also to comprehend the requirements of their customers in order to enhance the customer experience and cultivate connections that will last for a long time. Customers have the expectation that businesses will know them, create connections that are relevant to them, and provide a seamless experience across all of their points of contact if they share their data and enable unrestricted privacy in the use of it.
As a result, businesses need to collect and combine several client identifiers, such as a customer’s address, email address, and mobile phone number, into a single customer ID. Because customers are increasingly using various channels in their contacts with businesses, it is necessary to combine both traditional and digital data sources in order to comprehend customer behaviour. In addition, consumers anticipate receiving timely, pertinent information, and businesses are obligated to provide it to them.
2. Fraud Prevention and Risk Management:
The purpose of security and fraud statistics is to protect all of an organization’s material, financial, and intellectual property from being misappropriated by either an internal or an external danger. Effective data and analytical abilities will give high levels of fraud prevention and organisational security as a whole. Prevention involves mechanisms that allow firms to swiftly uncover possible job fraud and forecast future work, as well as identify and track down perpetrators of the fraud.
Using mathematical, network, method, and big data methods for models of predicting fraud trends that lead to warnings will ensure timely responses to real-time threat detection processes as well as automatic alerts and mitigation. This will also ensure that automatic alerts and mitigation are implemented. The creation of fraud control methods will be facilitated by the management of data, together with the accurate reporting of fraud cases and complete transparency of such situations.
In addition, the integration and integration of data across an entire firm can provide an integrated view of fraud across many different business lines, products, and processes. In fraudulent investigations and investigations, multidisciplinary analyses and databases give a more accurate study of fraudulent trends, projections, and prospective future expectations and risk assessments.
3. Transportation of Valuable Items:
Products are an organization’s lifeblood, and the most successful businesses in this regard are typically enormous investment corporations. Identifying trends that are the primary drivers of strategic innovation, innovative services, and new product development are the primary responsibilities of the product management team.
The combination of effective data collection from external company sources where people express their thoughts and ideas publicly with statistics will help companies remain competitive even as demand shifts or as new technologies are developed. It will also make it simpler to anticipate what the market wants to offer a product before it is requested.
4. Customization and Attention to Detail:
Companies are still having trouble with systematic data, and they need to respond more forcefully in order to overcome the instability that is being caused by customers engaged in digital technologies today. Only with advanced statistics will you be able to respond to a consumer in real time while still giving them the impression that they are being personally informed. Big data creates the possibility for interaction based on the personality of the customer. This can be accomplished by gaining an understanding of the customer’s perspectives and taking into account other factors, such as their real-time location, which can assist in the delivery of personalized service across multiple channels.
5. Developing and Improving Information Regarding Customers:
Poor performance can lead to and will lead to costly problems, including a high risk of destroying customer information and, eventually, product integrity. These problems can also be caused by a lack of integrity in the product itself. Utilizing design statistics, process management, and enhancing company performance in the production of goods or services provides efficiency and effectiveness, allowing businesses to satisfy the expectations of their customers and achieve efficiency.
It is possible to plant advanced analytical strategies in order to boost the productivity and efficiency of the field as well as to increase the organization’s workforce in accordance with the requirements of the business and the requirements of the customers. The effective utilization of data and statistics will additionally guarantee that ongoing improvement is continually encouraged owing to the ultimate viewing and monitoring of important performance criteria.
Conclusion
This article provides an introduction to the fundamental concept of data, which incorporates both the quantity and the quality of data. The concentration of attention in volume analysis is on the numbers, whereas quality analysis is on the stages. Both kinds of analysis have received a lot of attention and work, but there is still room for improvement in the research.