
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords

What is Data Science?
Last updated on 25th Sep 2020, Artciles, Blog, Data Science
“Data Science is about extraction, preparation, analysis, visualization, and maintenance of information. It is a cross-disciplinary field which uses scientific methods and processes to draw insights from data. ” With the emergence of new technologies, there has been an exponential increase in data. This has created an opportunity to analyze and derive meaningful insights from data. It requires special expertise of a ‘Data Scientist’ who can use various statistical & machine learning tools to understand and analyze data. A Data Scientist, specializing in Data Science, not only analyzes the data but also uses machine learning algorithms to predict future occurrences of an event. Therefore, we can understand Data Science as a field that deals with data processing, analysis, and extraction of insights from the data using various statistical methods and computer algorithms. It is a multidisciplinary field that combines mathematics, statistics, and computer science.
Subscribe For Free Demo
Error: Contact form not found.
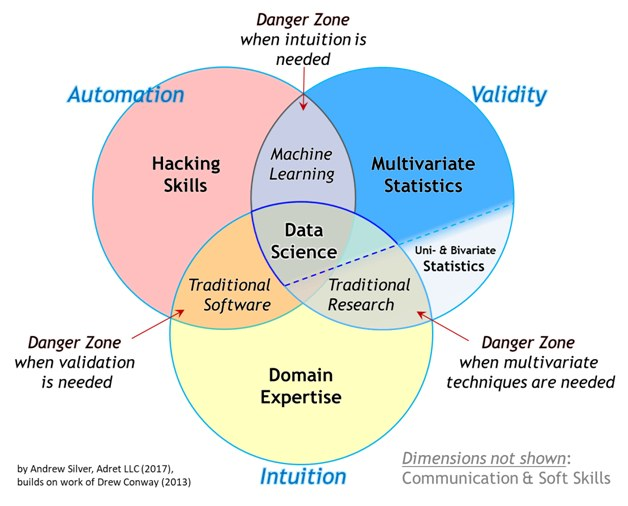
Why Data Science?
Companies require data to function, grow and improve their businesses. Data Scientists deal with the data in order to assist companies in making proper decisions. The data-driven approach undertaken by the companies with the help of Data Scientists who analyze a large amount of data to derive meaningful insights. These insights will be helpful for the companies who wish to analyze themselves and their performance in the market. Other than commercial industries, healthcare industries also use Data Science. where the technology is in huge demand to recognize microscopic tumors and deformities at an early stage of diagnosis.
Solving Problems with Data Science
When solving a real-world problem with Data Science, the first step towards solving it starts with Data Cleaning and Preprocessing. When a Data Scientist is provided with a dataset, it may be in an unstructured format with various inconsistencies. Organizing the data and removing erroneous information makes it easier to analyze and draw insights. This process involves the removal of redundant data, the transformation of data in a prescribed format, handling missing values etc.
A Data Scientist analyzes the data through various statistical procedures. In particular, two types of procedures used are:
- Descriptive Statistics
- Inferential Statistics
Assume that you are a Data Scientist working for a company that manufactures cell phones. You have to analyze customers using the mobile phones of your company. In order to do so, you will first take a thorough look at the data and understand various trends and patterns involved. In the end, you will summarize the data and present it in the form of a graph or a chart. You therefore, apply Descriptive Statistics to solve the problem.
You will then draw ‘inferences’ or conclusions from the data. We will understand inferential statistics through the following example – Assume that you wish to find out a number of defects that occurred during manufacturing. However, individual testing of mobile phones can take time. Therefore, you will consider a sample of the given phones and make a generalization about the number of defective phones in the total sample.
Now, you have to predict the sales of mobile phones over a period of two years. As a result, you will use Regression Algorithms. Based on the given historical sales, you will use regression algorithms to predict the sales over time.
Furthermore, you wish to analyze if customers will purchase the product based on their annual salary, age, gender, and credit score. You will use historical data to find out whether customers will buy (1) or not (0). Since there are two outputs or ‘classes’, you will use a Binary Classification Algorithm. Also, if there are more than two output classes we use the Multivariate Classification Algorithm to solve the problem. Both of the above-stated problems are part of ‘Supervised Learning’.
There are also instances of ‘unlabeled’ data. In this, there is no segregation of output in fixed classes as mentioned above. Suppose that you have to find clusters of potential customers and leads based on their socio-economic background. Since you do not have a fixed set of classes in your historical data, you will use the Clustering Algorithm to identify clusters or sets of potential clients. Clustering is an ‘Unsupervised Learning’ algorithm.
Tools for Data Science
- 1.R
- 2.Python
- 3.SQL
- 4.Hadoop
- 5.Tableau
- 6.Weka
Applications of Data Science
Data science is becoming one of the most demanding fields nowadays and thus used in various areas. There are multiple applications of data science. Let us explore them:
- Healthcare Sectors
- Internet Searching
- Digital advertisements
- Fraud and risk detection
- Airline route planning
- Gaming
- Image Recognition
- Logistics delivery
- Speech recognition
- Price comparison websites
Advantages of Data Science
- Data Science helps organizations know how and when their products sell best and that’s why the products are always delivered to the right place and right time.
- Faster and better decisions are taken by the organization to improve efficiency and earn higher profits.
- It helps the marketing and sales team of organizations in understanding by refining and identifying the target audience.
Disadvantages of Data Science
- Extracted information from the structured as well as unstructured data for further use can also be misused against a group of people of a country or some committee.
- Tools used for data science and analytics are more expensive to use to obtain information. The tools are also more complex, so people have to learn how to use them.
Comparison of Data Science with Data Analytics
A lot of people confuse the role of a Data Scientist with the role of a Data Analyst. So, we will go ahead and understand the similarities and differences between Data Science and Data Analytics in this Data Science tutorial.
| Criteria | Data Science | Data Analytics |
|---|---|---|
| Skills Needed | Data capturing, statistics, and problem-solving | Analytical, mathematical, and statistical skills |
| Type of Data Used | All types of data | Mostly structured and numeric data |
| Standard Life Cycle | Explore, discover, investigate, and visualize | The report, predict, prescribe, and optimize |
The above table gives you a high-level understanding of what the major difference is between a Data Scientist and a Data Analyst. One more key difference between the two domains is that data analysis is a necessary skill for Data Science. Thus, Data Science can be thought of as a big set, where data analysis can be a subset of it.