
- Difference between Data Lake vs Data Warehouse: A Complete Guide For Beginners with Best Practices
- What is Data Mining?| All you need to know [ OverView ]
- What is Data Mining and Data Warehousing?
- Clustering in SSIS | A Definitive Guide with Best Practices [ OverView ]
- What is Data Mart in Data Warehouse? :A Definitive Guide with Best Practices & REAL-TIME Examples
- Accessing Heterogeneous Data In SSIS | Step-By-Step Process with REAL-TIME Examples
- How to Use Java Classes In Talend ? : Step-By-Step Process with REAL-TIME Examples
- What is ODI? ( Oracle Data Integrator ) – A Complete Beginners Guide
- What is Logging in SSIS ( SQL Server Integration Services ) | A Complete Guide with Best Practices
- Applications of Data Mining Free Guide Tutorial & REAL-TIME Examples
- Informatica ETL Tools | Free Guide Tutorial & REAL-TIME Examples
- What Is Data Mining ? – Everything You Need to Know
- What is Amazon Redshift?
- What is Informatica PowerCenter?
- Difference between Data Lake vs Data Warehouse: A Complete Guide For Beginners with Best Practices
- What is Data Mining?| All you need to know [ OverView ]
- What is Data Mining and Data Warehousing?
- Clustering in SSIS | A Definitive Guide with Best Practices [ OverView ]
- What is Data Mart in Data Warehouse? :A Definitive Guide with Best Practices & REAL-TIME Examples
- Accessing Heterogeneous Data In SSIS | Step-By-Step Process with REAL-TIME Examples
- How to Use Java Classes In Talend ? : Step-By-Step Process with REAL-TIME Examples
- What is ODI? ( Oracle Data Integrator ) – A Complete Beginners Guide
- What is Logging in SSIS ( SQL Server Integration Services ) | A Complete Guide with Best Practices
- Applications of Data Mining Free Guide Tutorial & REAL-TIME Examples
- Informatica ETL Tools | Free Guide Tutorial & REAL-TIME Examples
- What Is Data Mining ? – Everything You Need to Know
- What is Amazon Redshift?
- What is Informatica PowerCenter?

Difference between Data Lake vs Data Warehouse: A Complete Guide For Beginners with Best Practices
Last updated on 01st Feb 2023, Artciles, Blog, Datawarehouse
- In this article you will learn:
- 1.What is Data Lake?
- 2.What is Data Warehouse?
- 3.A Difference between the Data Lake and Data Warehouse.
- 4.Data Lake Tools.
- 5.Data Warehouse Tools.
- 6.Conclusion.
What is Data Lake?
A Data Lake is a large storage repository that can hold structured semi-structured and unstructured data. It is the place to store any type of data in its native format with no restrictions on account size or file size. It offers a large quantity of data for improved analytical performance as well as native integration.Data Lake is a large container similar to a natural lake or riverLike a lake a data lake has many streams that flow into it. Structured data, unstructured data, machine-to-machine communication and logs all flow into a data lake in real time.
What is Data Warehouse?
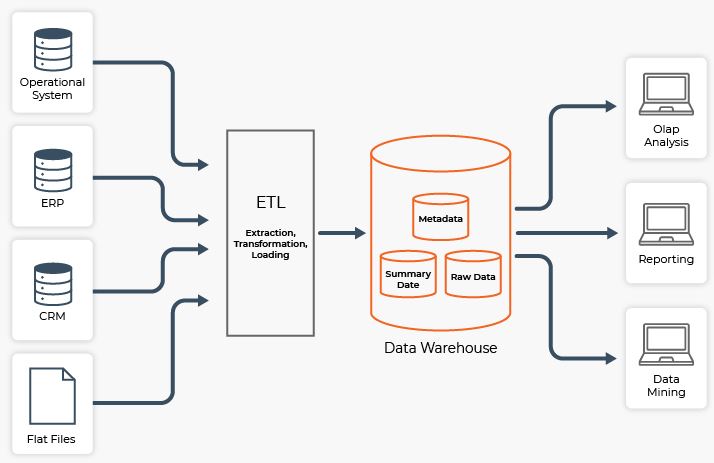
A data warehouse is a collection of technologies and components used to make strategic use of data. It collects and manages data from various sources in order to provide useful business insights. It is a large amount of information stored electronically for query and analysis rather than transaction processing. It is the transformation of data into information.
A Difference between the Data Lake and Data Warehouse:
| Parameters | Data Lake | Data Warehouse |
|---|---|---|
| Storage. | In a data lake all data is kept irrespective of a source and its structure. Data is kept in its a raw form. It is only transformed when it is a ready to be used. | A data warehouse will contain data extracted from transactional systems or data containing quantitative metrics and their attributes. The information is being cleaned and transformed. |
| History. | The use of big data technologies in data lakes is relatively recent. | Unlike big data the concept of a data warehouse has been used for decades. |
| Data Capturing. | Captures all the kinds of data and structures semi-structured and unstructured in an original form from source systems. | Captures structured information and organizes them in a schemas as explained for a data warehouse purposes. |
| Data Timeline. | Data lakes can retain all the data. This includes not only a data that is in use but also data that it might use in a future. Also data is kept for all the time, to go back in a time and do an analysis. | Significant time is spent during the data warehouse development process analysing various data sources. |
| Users. | A data lake is ideal for users who perform in-depth analyses. Included among these users are data scientists who require advanced analytical tools with capabilities such as predictive modelling and statistical analysis. | Because it is well structured easy to use and understand the data warehouse is ideal for operational users. |
| Storage Costs. | Data storage in big data technologies is less expensive than data storage in a data warehouse. | The storage of data warehouses is more expensive and time-consuming. |
| Task. | Data lakes can be contain all data and data types it empowers a users to access data prior a process of transformed, cleansed and structured. | Data warehouses can provide the insights into a pre-defined questions for a pre-defined data types. |
| Processing time. | Data lakes empower a users to access data before it has been transformed cleansed and aslo structured. Thus it allows users to get to result more quickly compares to a traditional data warehouse. | Data warehouses provide a insights into pre-defined questions for pre-defined data types. So any changes to a data warehouse needed more time. |
| Position of Schema. | Typically a schema is explained after data is stored. This provides high agility and simple of data capture but requires work at a end of the process. | Typically schema is explained before data is stored. Requires work at a start of a process but offers performance, security and integration. |
| Data processing. | Data Lakes use of an ELT (Extract Load Transform) process. | Data warehouse uses the traditional ETL (Extract Transform Load) process. |
| Complain. | Data is kept in its a raw form. It is only transformed when it is a ready to be used. | The chief complaint against a data warehouses is an inability or the problem faced when are trying to make change in them. |
| Key Benefits. | They integrate various types of data to come up with an entirely new questions as these users not likely to use a data warehouses because they can need to go beyond its capabilities. | Most users in organization are operational. These type of a users only care about the reports and key performance metrics. |
Data Lake Tools:
Azure Data Lake Storage – Creates single unified a data storage space. The tool offers a advanced security facilities, accurate data authentication and limited access to a specific roles. Ideal for a large scale queries .
AWS Lake Formation – Offers a very simple solution to set up data lake. Seamless integration with an AWS-based analytics and machine learning services. The tool creates meticulous searchable data catalog with the audit log in place for identifying a data access history.
Qubole – This data lake solution are stores data in an open format that can be accessed through a open standards. Ad hoc analytics reports and the mixing of data pipelines to provide a unified insight in real-time are key features.
Infor Data Lake – Collects data from various sources and ingests into a structure that can immediately begins to derive value from it. Data stored here will never turn into the swamp due to intelligent cataloging.
Intelligent Data Lake – This tool helps a customers to gain maximum value from a Hadoop-based Data Lake. The underlying a Hadoop system ensures users don’t need much of coding for running a large-scale data queries.
Data Warehouse Tools:
The selection of tools and software is a critical factor in deciding between a Data Lake and a Data Warehouse:
Amazon Redshift – A cloud data warehousing tool that is an excellent for more speed data analytics. This data warehouse example can execute a numerous concurrent queries without the any operational overhead.
Microsoft Azure – It is the node-based platform that allows a massive parallel processing which helps to extract and visualize business insights much quickly.
Google BigQuery – This data warehousing tool can be integrated with the Cloud ML and TensorFlow to build a powerful AI models.
Snowflake – It allows analysis of a data from various structured and unstructured sources. It consists of the shared architecture which separates storage from a processing power. As a result users can scale a CPU resources according to user activities.
Micro Focus Vertica – This SQL data warehouse is aslo available in a cloud on platforms including AWS and Azure. It offers a built-in analytics capability for a machine learning, pattern matching and time series.
Amazon DynamoDB – Scalable DynamoDB can scale a querying capacity up to 10 or 20 trillion requests in the day over petabytes of data.
Conclusion:
A data warehouse is a large repository of organizational data gathered from a variety of operational and external data sources. The data has already been structured, filtered and processed for a specific purpose. Data warehouses pull processed data from various internal applications and external partner systems on a regular basis for advanced querying and analytics.