
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- Sorting data in MongoDB ? : A Complete Guide For Beginners [ OverView ]
- What are Data Modelling tools? : The Ultimate Guide
- SQL Server Certification 2016 | A Definitive Guide
- What is Database Administration | Database Management Essentials | A Complete Guide For Beginners
- What is MongoDB and its Queries | All you need to know [ OverView ]
- What is Database Management | Benefits of DBMS | Expert’s Top Picks
- MongoDB Vs MySQL | Know Their Differences and Which Should You Learn?
- MongoDB vs DynamoDB | Know Their Differences and Which Should You Learn?
- MongoDB vs PostgreSQL | Know Their Differences and Which Should You Learn?
- What is a Database? : A Complete Guide with Best Practices
- What is Data Modelling? : All you need to know [ OverView ]
- A Complete Guide on SQL Optimization Techniques
- What is MongoDB Port? : Free Guide Tutorial & REAL-TIME Examples
- What is MongoDB? : A Complete Guide with Best Practices
- What is a Transaction Processing System? REAL-TIME Examples
- MongoDB Commands Cheat Sheet
- How To Become a Data Modeler?
- How To Start a Career in Database Administration?
- Types Of SQL Indexes
- DBMS vs RDBMS vs NoSQL
- Cassandra Vs MongoDB
- Different types of Joins in SQL Server
- What is SSRS?
- Schema in SQL
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- Sorting data in MongoDB ? : A Complete Guide For Beginners [ OverView ]
- What are Data Modelling tools? : The Ultimate Guide
- SQL Server Certification 2016 | A Definitive Guide
- What is Database Administration | Database Management Essentials | A Complete Guide For Beginners
- What is MongoDB and its Queries | All you need to know [ OverView ]
- What is Database Management | Benefits of DBMS | Expert’s Top Picks
- MongoDB Vs MySQL | Know Their Differences and Which Should You Learn?
- MongoDB vs DynamoDB | Know Their Differences and Which Should You Learn?
- MongoDB vs PostgreSQL | Know Their Differences and Which Should You Learn?
- What is a Database? : A Complete Guide with Best Practices
- What is Data Modelling? : All you need to know [ OverView ]
- A Complete Guide on SQL Optimization Techniques
- What is MongoDB Port? : Free Guide Tutorial & REAL-TIME Examples
- What is MongoDB? : A Complete Guide with Best Practices
- What is a Transaction Processing System? REAL-TIME Examples
- MongoDB Commands Cheat Sheet
- How To Become a Data Modeler?
- How To Start a Career in Database Administration?
- Types Of SQL Indexes
- DBMS vs RDBMS vs NoSQL
- Cassandra Vs MongoDB
- Different types of Joins in SQL Server
- What is SSRS?
- Schema in SQL

What does the Yield keyword do and How to use Yield in python ? [ OverView ]
Last updated on 01st Feb 2023, Artciles, Blog, Database
- In this article you will get
- Configure Database Services
- Database service overview
- Process flow example
- Components
- What is OpenStack used for?
- Conclusion
Configure Database Services
The Database service offers a scalable and reliable Cloud Database-as-a-Service functionality for the both relational and non-relational database engines. Users can quickly and easily use a database features without a burden of handling the complex administrative tasks.
OpenStack supports the number of database backends—an internal SQLite database (the default), MySQL, and Postgres. MoreOpenStack services maintain the database to keep track of a critical resources, usage, and other information. By default, individual SQLite databases are specified for this purpose and are useful for a single-node configuration. For a multi-node configurations, a MySQL database is a recommended for storing this information.
Database service overview
The Database service provides a scalable and reliable cloud provisioning functionality for the both relational and non-relational database engines. Users can quickly and easily use a database features without a burden of handling complex administrative tasks. Cloud users and database administrators can provision and manage the multiple database instances as needed.The Database service provides a resource isolation at a high performance levels, and automates complex administrative tasks like deployment, configuration, patching, backups, restores, and monitoring.
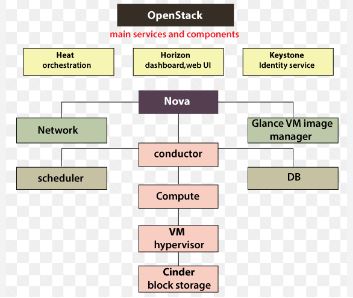
Process flow example
This example is the high-level process flow for using a Database services:
1.The OpenStack Administrator configures a basic infrastructure using a following steps:
- a.Install a Database service.
- b.Create an image for every type of database. For example, one for a MySQL and one for MongoDB.
- c.Use a trove-manage command to import images and provide them to tenants.
2.The OpenStack end user deploys a Database service using a following steps:
- a.Create a Database service instance using as openstack database instance create command.
- b.Use a openstack database instance list command to get an ID of the instance, followed by openstack database instance show command to get a IP address of it.
- c.Access a Database service instance using a typical database access commands.
Components
The Database service includes below components:
Trove-api component:This component is a responsible for providing a RESTful API. It talks to a task manager for complex tasks, but it can also talk to a guest agent directly to perform a simple tasks, like retrieving a databases or users from a trove instance.
Trove-conductor service:The conductor component is responsible for an updating a Trove backend database with an information that are be guest agent sends regarding the instances. It removes the need for a direct database access by all guest agents for updating information.
Trove-taskmanager service:The task manager is an engine responsible for doing majority of a work. It is responsible for a provisioning instances, managing the life cycle, and performing various operations. The task manager normally sends a common commands to trove guest agent, which are of an abstract nature; it is a responsibility of a guest agent to read them and problem database-specific commands in order to be execute them.
Trove-guestagent service:The guest agent runs inside a Nova instances that are used to run a database engines. The agent listens to messaging bus for topic and is responsible for an actually translating and executing a commands that are sent to it by a task manager component for a particular datastore.
What is OpenStack used for?
A OpenStack is the open-source platform that uses a pooled virtual resources to build and manage a private and public clouds. The tools that comprise a OpenStack platform, called “projects,” handle a core cloud-computing services of a computing, networking, storage, identity, and image services.
What is an OpenStack cloud?
OpenStack is the cloud operating system that controls a large pools of computing, storage, and networking resources throughout data center, all managed and provisioned through an APIs with the common authentication mechanisms.
Who is OpenStack for?
Many cloud platforms have an integrated OpenStack in a cloud toolkit by default. The OpenStack backend is ever growing with the more companies joining .
Example Architecture:
Example Architecture requires a 2 nodes (min) to launch the basic virtual machine or an instance.The example architecture considered here has minimum configuration to give idea of proof of a concept of OpenStack, rather than going for a production environment.
Hardware requirements:
Controller:
The controller node mainly runs a following functionalities:
- Image service
- Identity service
Management portions of:
- Compute
- Networking
- Various networking agents
- Dashboard
- Supporting services like a SQL Database, message queue, NTP. etc.
- Controller node requires the minimum of a two network interfaces.

Job opportunities for OpenStack:
The opportunities for OpenStack developers and a technical consultants on a boom. The available roles in a market on OpenStack extend from OpenStack engineer, developer, technical consultant, VMware Engineer with an expertise in OpenStack, OpenStack neutron architect, etc. to Python developer with the automation.
Conclusion
The OpenStack community has had database-as-a-service tool in a development for some time, and will finally see a first integrated release of it in Icehouse. Initially, it will only support for MySQL, with further options available in a Juno onward, but it should be able to deploy a database servers out of the box in the highly available way from this release.