
- What is Data Clustering? | A Complete Guide For Beginners [ OverView ]
- What is Regression ? Know about it’s types
- What is Lasso Regression? : Learn With examples
- What is Ridge Regression? Learn with examples
- What is Linear Regression? | A Complete Guide
- What is Linear Regression in Machine Learning?
- Bagging vs Boosting in Machine Learning | Know Their Differences
- What is a Confusion Matrix in Machine Learning? : A Complete Guide For Beginners
- What Is Machine Learning | How It Works and Techniques | All you need to know [ OverView ]
- Support Vector Machine (SVM) Algorithm – Machine Learning | Everything You Need to Know
- Decision Trees in Machine Learning: A Complete Guide with Best Practices
- Pattern Recognition and Machine Learning | A Definitive Guide | Everything You Need to Know [ OverView ]
- An Overview of ML on AWS : Computer Vision, Forecasting
- Keras vs TensorFlow – What to learn and Why? : All you need to know
- Machine Learning Engineer Salary | Required Skills | Everything You Need to Know
- The Best Machine Learning Tools
- Best Deep Learning Books to Read
- Top Machine Learning Projects for Beginners
- Top Machine Learning Algorithms You Need to Know
- What is Data Clustering? | A Complete Guide For Beginners [ OverView ]
- What is Regression ? Know about it’s types
- What is Lasso Regression? : Learn With examples
- What is Ridge Regression? Learn with examples
- What is Linear Regression? | A Complete Guide
- What is Linear Regression in Machine Learning?
- Bagging vs Boosting in Machine Learning | Know Their Differences
- What is a Confusion Matrix in Machine Learning? : A Complete Guide For Beginners
- What Is Machine Learning | How It Works and Techniques | All you need to know [ OverView ]
- Support Vector Machine (SVM) Algorithm – Machine Learning | Everything You Need to Know
- Decision Trees in Machine Learning: A Complete Guide with Best Practices
- Pattern Recognition and Machine Learning | A Definitive Guide | Everything You Need to Know [ OverView ]
- An Overview of ML on AWS : Computer Vision, Forecasting
- Keras vs TensorFlow – What to learn and Why? : All you need to know
- Machine Learning Engineer Salary | Required Skills | Everything You Need to Know
- The Best Machine Learning Tools
- Best Deep Learning Books to Read
- Top Machine Learning Projects for Beginners
- Top Machine Learning Algorithms You Need to Know

Bagging vs Boosting in Machine Learning | Know Their Differences
Last updated on 05th Nov 2022, Artciles, Blog, Machine Learning
- In this article you will learn:
- 1.Bagging Vs Boosting.
- 2.Bagging.
- 3.Advantages of using the Random timber fashion.
- 4.Benefits of using grade boosting styles.
- 5.Boosting.
- 6.Boosting working.
- 7.Difference between Bagging and Boosting.
- 8.Boosting Algorithms.
- 9.Conclusion.
Bagging Vs Boosting:
We all use decision tree ways in diurnal life to make opinions. Organizations use these supervised machine literacy ways similar as decision trees to make better opinions and induce further fat and profit.Ensemble styles combine different decision trees to produce better prophetic results the ultimate using a single decision tree. Given below are the two ways that are used to do the Ensemble Decision Tree.
Bagging:
Bagging is used when our ideal is to reduce the friction of a decision tree. The conception then’s to produce some subset of data from the training sample which is aimlessly named with relief. Now each collection of subset data is used to prepare their decision trees therefore we end up with a bunch of different models. The normal of all estimates from multiple branches is used which is more important than a decision tree.
- There’s an extension on Random Forest Bagging.
- A fresh step has to be taken to prognosticate an arbitrary subset of the data. It also does arbitrary selection of features rather than using all the features to grow the tree.
- When we’ve numerous arbitrary trees it’s called arbitrary timber. The tree is the largest developed.
- Several subsets are created from the original dataset opting the compliances with relief.
- A base model( weak model) is erected on each of these subsets.
- Models run in resemblant and are independent of each other.
- The final prognostications are determined by combining the prognostications of all the models.
Advantages of using the Random timber fashion:
- It handles high dimension data sets veritably well.
- It manages missing amounts and maintains delicacy for missing data.
- Disadvantages of using arbitrary timber fashion.
- Since the final validation depends on the mean prognostications from the subset trees it’ll not give accurate values for the retrogression model.
Benefits of using grade boosting styles:
- It supports colorful loss functions.
- It works well with discussion.
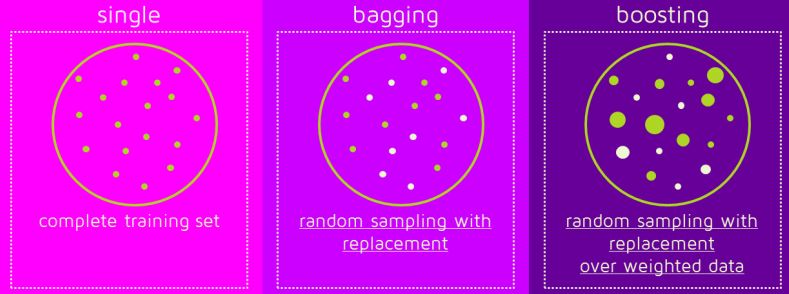
Boosting:
- Boosting is another ensemble process to produce a collection of prognostications. In other words we fit successive trees generally arbitrary samples and at each step the ideal is to resolve the net error from the former trees.
- Still its weight is increased so that the preceding thesis is more likely to classify it correctly ultimately outperforming the weaker learners by integrating the whole set If a given input is misclassified by the proposition. be converted into a model.
- grade boosting is an extension of the boosting process.
- grade Boosting = grade Descent Boosting.
- It uses a grade descent algorithm that can optimize any differentiable loss function. A group of trees is erected collectively and the individual trees are added up successionally. The coming three passes to restore the loss( this is the difference between the factual and prognostic values).
Let us understand how Boosting works in the way given below:
- Originally equal weighting is given to all data points.
- A base model is erected on this subset.
- This model is used to make prognostications on the entire dataset.
- crimes are calculated using factual values and estimated values.
- compliances that are incorrectly prognosticate are given further weight.( Then the three misclassified blue-else points will be given further significance).
- Another model is erected and prognostications are made on the dataset.( This model attempts to correct the crimes of the former model).
- Also several models are created each of which corrects the crimes of the former model.
- Therefore the boosting algorithm combines several weak learners to form a strong learner.
- Individual models won’t perform well on the whole dataset but they work well for some part of the dataset.
- Therefore each model actually enhances the performance of the ensemble.
Difference between Bagging and Boosting:
| Bagging | Boosting |
|---|---|
| Different training data subsets are aimlessly generated with reserves from the entire training dataset. | Each new subset contains factors that were misclassified by former models. |
| Bagging attempts to attack the over-fitting issue. | Boosting passes to reduce bias. |
| still we need to apply bagging If the classifier is unstable( high friction). | Still we need to apply boosting If the classifier is stable and straight( high bias). |
| Each model receives an equal weight. | Models are ladened by their performance. |
| Aim to reduce friction not bias. | Aim to reduce bias not variation. |
| This is the easiest way to combine prognostications of the same type. | It’s a way to combine predicates belonging to different types. |
| Each model is manufactured singly. | New models are affected by the performance of preliminarily developed models. |
| Bagging and boosting gain N learners by generating fresh data in the training phase. | N new training data sets are generated by arbitrary slices with relief from the original set. |
| Some compliances can be replicated in each new training data set by slice with relief. | Still compliances are valued for boosting and so some of them will share more constantly in new sets. |
| Bagging It’s a homogeneous weak learners model that learns from each other singly in resemblant and combines them for determining the model normal. | Boosting It’s also a homogeneous weak learners model but works elsewhere from Bagging. In this model learners learn successionally and adaptively to ameliorate model prognostications of a literacy algorithm. |
Boosting Algorithms:
There are several boosting algorithms. The original bones proposed by Robert Schapire and Yoav Freund weren’t adaptive and couldn’t take full advantage of the weak learners. Schapire and Freund also developed AdaBoost an adaptive boosting algorithm that won the prestigious Gödel Prize. AdaBoost was the first really successful boosting algorithm developed for the purpose of double brackets. AdaBoost is short for Adaptive Boosting and is a veritably popular boosting fashion that combines multiple “ weak classifiers ” into a single “ strong classifier ”.
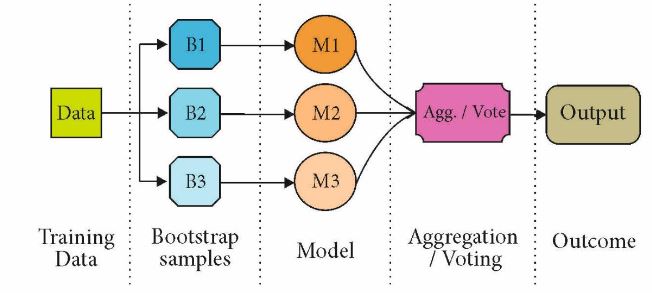
Parallels Between Bagging and Boosting:
Bagging and Boosting, both being the generally used styles have a universal similarity of being classified as ensemble styles. Then we will explain the parallels between them.
- Both are ensemble styles to get N learners from 1 learner.
- Both induce several training data sets by arbitrary slice.
- Both make the final decision by comprising the N learners( or taking the maturity of theme Majority Voting).
- Both are good at reducing friction and give advanced stability.
Difference in processes:
- Some boosting ways include a fresh condition to keep or discard a single learner.
- For illustration the most notorious, AdaBoost, requires lower than 50 error to maintain the model else the replication is repeated until a better learner is obtained from an arbitrary conjecture.
- The former image shows the general process of a boosting system but several options live for determining the weights to be used in the coming training phase and in the bracket phase.
Opting the stylish fashion- Bagging or Boosting:
- Bagging and boosting reduce the friction of your single estimate because they combine multiple estimates from different models.
- Still also bagging will infrequently get better bias, If the problem is that a single model gets veritably little performance. Still boosting can induce a combined model with smaller crimes because it optimizes the advantages and minimizes the disadvantages of a single model.
- Again if the difficulty of a single model is overfitting also bagging is the stylish option. Boosting for its part does n’t help avoid over-fitting.
- Actually this technology is floundering with this problem itself. For this reason bagging is more frequently effective than boosting.
Conclusion:
The bagging( or bootstrap aggregating) fashion uses these subsets( bags) to get a fair idea of the distribution( the complete set). The size of the subset created for bagging may be lower than the original set.Boosting is a gradational process where each posterior model tries to correct the crimes of the former model. Successful models are dependent on former models.When an input is misclassified by one thesis its weight is increased so that the coming thesis is more likely to classify it correctly. Eventually combining the entire set converts the weaker learners into better performing models.