
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Apache Mahout Tutorial
Last updated on 29th Sep 2020, Big Data, Blog, Tutorials
We are living in a day and age where information is available in abundance. The information overload has scaled to such heights that sometimes it becomes difficult to manage our little mailboxes! Imagine the volume of data and records some of the popular websites (the likes of Facebook, Twitter, and Youtube) have to collect and manage on a daily basis. It is not uncommon even for lesser known websites to receive huge amounts of information in bulk.
Normally we fall back on data mining algorithms to analyze bulk data to identify trends and draw conclusions. However, no data mining algorithm can be efficient enough to process very large datasets and provide outcomes in quick time, unless the computational tasks are run on multiple machines distributed over the cloud.
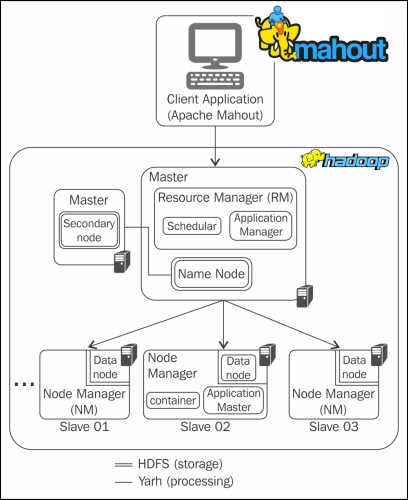
We now have new frameworks that allow us to break down a computation task into multiple segments and run each segment on a different machine. Mahout is such a data mining framework that normally runs coupled with the Hadoop infrastructure at its background to manage huge volumes of data.
What is Apache Mahout?
- A mahout is one who drives an elephant as its master. The name comes from its close association with Apache Hadoop which uses an elephant as its logo.
- Hadoop is an open-source framework from Apache that allows to store and process big data in a distributed environment across clusters of computers using simple programming models.
- Apache Mahout started as a sub-project of Apache’s Lucene in 2008. In 2010, Mahout became a top level project of Apache.
- Apache Mahout is an open source project that is primarily used for creating scalable machine learning algorithms.
Subscribe For Free Demo
Error: Contact form not found.
It implements popular machine learning techniques such as:
- Recommendation
- Classification
- Clustering
Features of Mahout
- The algorithms of Mahout are written on top of Hadoop, so it works well in a distributed environment. Mahout uses the Apache Hadoop library to scale effectively in the cloud.
- Mahout offers the coder a ready-to-use framework for doing data mining tasks on large volumes of data.
- Mahout lets applications analyze large sets of data effectively and in quick time.
- Includes several MapReduce enabled clustering implementations such as k-means, fuzzy k-means, Canopy, Dirichlet, and Mean-Shift.
- Supports Distributed Naive Bayes and Complementary Naive Bayes classification implementations.
- Comes with distributed fitness function capabilities for evolutionary programming.
- Includes matrix and vector libraries.
Mahout – Machine Learning
Apache Mahout is a highly scalable machine learning library that enables developers to use optimized algorithms. Mahout implements popular machine learning techniques such as recommendation, classification, and clustering. Therefore, it is prudent to have a brief section on machine learning before we move further.
Machine Learning
Machine learning is a branch of science that deals with programming the systems in such a way that they automatically learn and improve with experience. Here, learning means recognizing and understanding the input data and making wise decisions based on the supplied data.
It is very difficult to cater to all the decisions based on all possible inputs. To tackle this problem, algorithms are developed. These algorithms build knowledge from specific data and past experience with the principles of statistics, probability theory, logic, combinatorial optimization, search, reinforcement learning, and control theory.
The developed algorithms form the basis of various applications such as:
- Vision processing
- Language processing
- Forecasting (e.g., stock market trends)
- Pattern recognition
- Games
- Data mining
- Expert systems
- Robotics
Machine learning is a vast area and it is quite beyond the scope of this tutorial to cover all its features. There are several ways to implement machine learning techniques, however the most commonly used ones are supervised and unsupervised learning.
Supervised Learning
Supervised learning deals with learning a function from available training data. A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. Common examples of supervised learning include:
- classifying emails as spam,
- labeling web pages based on their content, and
- voice recognition.
There are many supervised learning algorithms such as neural networks, Support Vector Machines (SVMs), and Naive Bayes classifiers. Mahout implements Naive Bayes classifier.
Unsupervised Learning
Unsupervised learning makes sense of unlabeled data without having any predefined dataset for its training. Unsupervised learning is an extremely powerful tool for analyzing available data and looking for patterns and trends. It is most commonly used for clustering similar input into logical groups. Common approaches to unsupervised learning include:
- k-means
- self-organizing maps, and
- hierarchical clustering
Recommendation
Recommendation is a popular technique that provides close recommendations based on user information such as previous purchases, clicks, and ratings.
- Amazon uses this technique to display a list of recommended items that you might be interested in, drawing information from your past actions. There are recommender engines that work behind Amazon to capture user behavior and recommend selected items based on your earlier actions.
- Facebook uses the recommender technique to identify and recommend the “people you may know list”.
Classification
Classification, also known as categorization, is a machine learning technique that uses known data to determine how the new data should be classified into a set of existing categories.
Classification is a form of supervised learning.
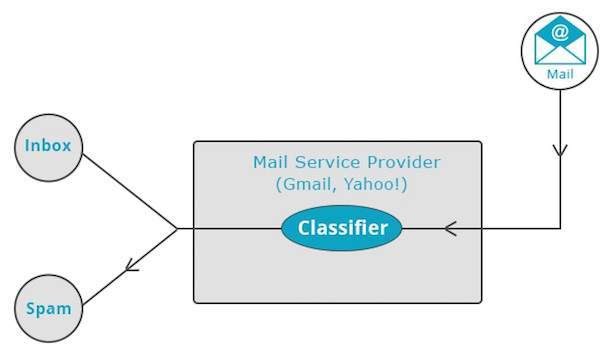
- Mail service providers such as Yahoo! and Gmail use this technique to decide whether a new mail should be classified as spam. The categorization algorithm trains itself by analyzing user habits of marking certain mails as spams. Based on that, the classifier decides whether a future mail should be deposited in your inbox or in the spams folder.
- iTunes application uses classification to prepare playlists.
Clustering
Clustering is used to form groups or clusters of similar data based on common characteristics.
Clustering is a form of unsupervised learning.
- Search engines such as Google and Yahoo! use clustering techniques to group data with similar characteristics.
- Newsgroups use clustering techniques to group various articles based on related topics.
The clustering engine goes through the input data completely and based on the characteristics of the data, it will decide under which cluster it should be grouped. Take a look at the following example.

Get Experts Curated Apache Mahout Training with Industry Trends Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Mahout Uses
- Collaborative filtering: mines user behavior and makes product recommendations (e.g. Amazon recommendations)
- Clustering: takes items in a particular class (such as web pages or newspaper articles) and organizes them into naturally occurring groups, such that items belonging to the same group are similar to each other
- Classification: learns from existing categorizations and then assigns unclassified items to the best category
- Frequent itemset mining: analyzes items in a group (e.g. items in a shopping cart or terms in a query session) and then identifies which items typically appear together.
List of machine learning algorithms exposed by Mahout.
Below is a current list of machine learning algorithms exposed by Mahout.
1.Collaborative Filtering
- Item-based Collaborative Filtering
- Matrix Factorization with Alternating Least Squares
- Matrix Factorization with Alternating Least Squares on Implicit Feedback
2.Classification
- Naive Bayes
- Complementary Naive Bayes
- Random Forest
3.Clustering
- Canopy Clustering
- k-Means Clustering
- Fuzzy k-Means
- Streaming k-Means
- Spectral Clustering
4.Dimensionality Reduction
- Lanczos Algorithm
- Stochastic SVD
- Principal Component Analysis
5.Topic Models
- Latent Dirichlet Allocation
6.Miscellaneous
- Frequent Pattern Matching
- RowSimilarityJob
- ConcatMatrices
- Collocations
Installation
Setting up Mahout in Eclipse
1.Download Mahout source from
- http://apache.techartifact.com/mirror/mahout/0.7/
2.Extract from archive it.
3.Convert the project into an eclipse project.
- $ cd mahout-distribution-0.7
- $ mvn eclipse:eclipse
Wait for a long time till it builds the eclipse project.
4.Now set the classpath variable M2_REPO of Eclipse to Maven 2 local repository
- mvn -Declipse.workspace= eclipse:add-maven-repo
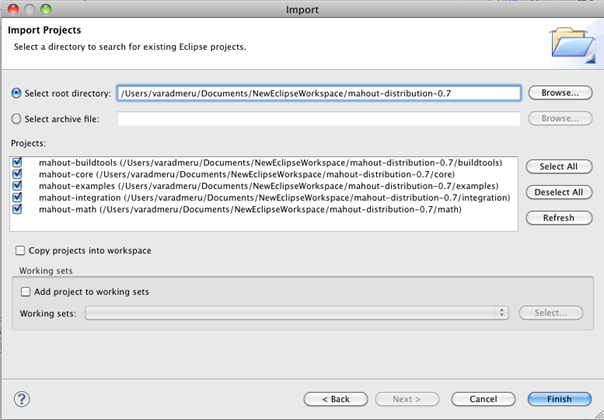
5.Finally import the converted Eclipse project of Mahout. Open File > Import > General > Existing Projects into Workspace from Eclipse menu.
6.At first, generate a Maven project for sample codes on the Eclipse workspace directory.
- $ mvn archetype:create -DgroupId=com.orzota.mahout.recommender -DartifactId=recommender
The name of the project created is “recommender” in the workspace directory
7.Convert the newly created java project into eclipse project
- $ cd recommender
- $ mvn eclipse:eclipse
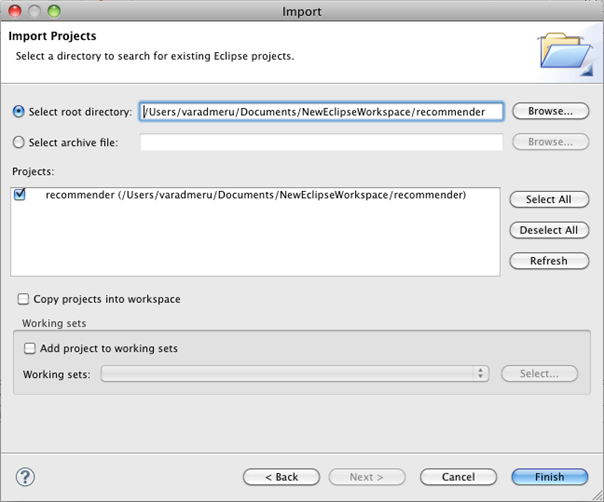
8.Import the project into eclipse
Open File > Import > General > Existing Projects into Workspace from Eclipse menu and select the ‘recommender’ project.
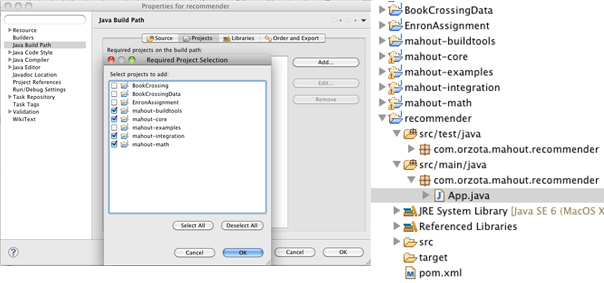
The Folder structure looks like the below. Now we can build apps using the Mahout
9.Right click the ‘recommender’ project, select Properties > Java Build Path > Projects from pop-up menu and click ‘Add’ and select the below Mahout projects.
Applications of Mahout
- Companies such as Adobe, Facebook, LinkedIn, Foursquare, Twitter, and Yahoo use Mahout internally.
- Foursquare helps you in finding out places, food, and entertainment available in a particular area. It uses the recommender engine of Mahout.
- Twitter uses Mahout for user interest modelling.
- Yahoo! uses Mahout for pattern mining.