
- Multilayer Perceptron Tutorial – An Complete Overview
- AWS Machine Learning Tutorial | Ultimate Step-by-Step Guide
- Keras Tutorial : What is Keras? | Learn from Scratch
- Machine Learning Algorithms for Data Science Tutorial
- Machine Learning-Random Forest Algorithm Tutorial
- Naive Bayes
- Classification – Machine Learning Tutorial
- Tensorflow Tutorial
- Deep Learning Tutorial
- Perceptron Tutorial
- Machine Learning Tutorial
- Multilayer Perceptron Tutorial – An Complete Overview
- AWS Machine Learning Tutorial | Ultimate Step-by-Step Guide
- Keras Tutorial : What is Keras? | Learn from Scratch
- Machine Learning Algorithms for Data Science Tutorial
- Machine Learning-Random Forest Algorithm Tutorial
- Naive Bayes
- Classification – Machine Learning Tutorial
- Tensorflow Tutorial
- Deep Learning Tutorial
- Perceptron Tutorial
- Machine Learning Tutorial

Machine Learning Tutorial
Last updated on 21st Sep 2020, Blog, Machine Learning, Tutorials
We are living in the ‘age of data’ that is enriched with better computational power and more storage resources. This data or information is increasing day by day, but the real challenge is to make sense of all the data. Businesses & organizations are trying to deal with it by building intelligent systems using the concepts and methodologies from Data science, Data Mining and Machine learning. Among them, machine learning is the most exciting field of computer science. It would not be wrong if we call machine learning the application and science of algorithms that provides sense to the data.
Machine Learning
Machine Learning (ML) is that field of computer science with the help of which computer systems can provide sense to data in much the same way as human beings do.
In simple words, ML is a type of artificial intelligence that extracts patterns out of raw data by using an algorithm or method. The main focus of ML is to allow computer systems to learn from experience without being explicitly programmed or human intervention.
Need for Machine Learning
Human beings, at this moment, are the most intelligent and advanced species on earth because they can think, evaluate and solve complex problems. On the other side, AI is still in its initial stage and hasn’t surpassed human intelligence in many aspects. Then the question is, what is the need to make machines learn? The most suitable reason for doing this is, “to make decisions, based on data, with efficiency and scale”.
Lately, organizations are investing heavily in newer technologies like Artificial Intelligence, Machine Learning and Deep Learning to get the key information from data to perform several real-world tasks and solve problems. We can call it data-driven decisions taken by machines, particularly to automate the process. These data-driven decisions can be used, instead of using programming logic, in problems that cannot be programmed inherently. The fact is that we can’t do without human intelligence, but another aspect is that we all need to solve real-world problems with efficiency at a huge scale. That is why the need for machine learning arises.
Why & When to Make Machines Learn?
We have already discussed the need for machine learning, but another question arises in what scenarios we must make the machine learn? There can be several circumstances where we need machines to take data-driven decisions with efficiency and at a huge scale.
The followings are some of such circumstances where making machines learn would be more effective
Lack of human expertise
The very first scenario in which we want a machine to learn and take data-driven decisions, can be the domain where there is a lack of human expertise. The examples can be navigations in unknown territories or spatial planets.
Dynamic scenarios
There are some scenarios which are dynamic in nature i.e. they keep changing over time. In case of these scenarios and behaviors, we want a machine to learn and take data-driven decisions. Some of the examples can be network connectivity and availability of infrastructure in an organization.
Difficulty in translating expertise into computational tasks
There can be various domains in which humans have their expertise; however, they are unable to translate this expertise into computational tasks. In such circumstances we want machine learning. The examples can be the domains of speech recognition, cognitive tasks etc.
Machine Learning vs. Traditional Programming
Traditional programming differs significantly from machine learning. In traditional programming, a programmer codes all the rules in consultation with an expert in the industry for which software is being developed. Each rule is based on a logical foundation; the machine will execute an output following the logical statement. When the system grows complex, more rules need to be written. It can quickly become unsustainable to maintain.
Machine learning is supposed to overcome this issue. The machine learns how the input and output data are correlated and it writes a rule. The programmers do not need to write new rules each time there is new data. The algorithms adapt in response to new
data and experiences to improve efficacy over time.
Machine Learning Model
Before discussing the machine learning model, we must need to understand the following formal definition of ML given by professor Mitchell
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
The above definition is basically focusing on three parameters, also the main components of any learning algorithm, namely Task(T), Performance(P) and experience (E).
In this context, we can simplify this definition as
ML is a field of AI consisting of learning algorithms that
- Improve their performance (P)
- At executing some task (T)
- Over time with experience (E)
Let us discuss them more in detail now
Task(T)
From the perspective of a problem, we may define task T as the real-world problem to be solved. The problem can be anything like finding the best house price in a specific location or to finding the best marketing strategy etc. On the other hand, if we talk about machine learning, the definition of task is different because it is difficult to solve ML based tasks by conventional programming approach.
A task T is said to be a ML based task when it is based on the process and the system must follow for operating on data points. The examples of ML based tasks are Classification, Regression, Structured annotation, Clustering, Transcription etc.
Subscribe For Free Demo
Error: Contact form not found.
Experience (E)
As the name suggests, it is the knowledge gained from data points provided to the algorithm or model. Once provided with the dataset, the model will run iteratively and will learn some inherent pattern. The learning thus acquired is called experience(E). Making an analogy with human learning, we can think of this situation as in which a human being is learning or gaining some experience from various attributes like situation, relationships etc. Supervised, unsupervised and reinforcement learning are some ways to learn or gain experience. The experience gained by our ML model or algorithm will be used to solve the task T.
Performance (P)
An ML algorithm is supposed to perform tasks and gain experience with the passage of time. The measure which tells whether an ML algorithm is performing as per expectation or not is its performance (P). P is basically a quantitative metric that tells how a model is performing the task, T, using its experience, E. There are many metrics that help to understand the ML performance, such as accuracy score, F1 score, confusion matrix, precision, recall, sensitivity etc.
Challenges in Machines Learning
The challenges that ML is facing currently are
Quality of data
Having good-quality data for ML algorithms is one of the biggest challenges. Use of low-quality data leads to the problems related to data preprocessing and feature extraction.
Time-Consuming task
Another challenge faced by ML models is the consumption of time especially for data acquisition, feature extraction and retrieval.
Lack of specialist persons
As ML technology is still in its infancy stage, availability of expert resources is a tough job.
No clear objective for formulating business problems
Having no clear objective and well-defined goal for business problems is another key challenge for ML because this technology is not that mature yet.
Issue of overfitting & underfitting
If the model is overfitting or underfitting, it cannot be represented well for the problem.
Curse of dimensionality
Another challenge ML models face is too many features of data points. This can be a real hindrance.
Difficulty in deployment
Complexity of the ML model makes it quite difficult to be deployed in real life.
Machine learning Life cycle
Machine learning has given the computer systems the abilities to automatically learn without being explicitly programmed. But how does a machine learning system work? So, it can be described using the life cycle of machine learning. Machine learning life cycle is a cyclic process to build an efficient machine learning project. The main purpose of the life cycle is to find a solution to the problem or project.
Machine learning life cycle involves seven major steps, which are given below:
- 1.Gathering Data
- 2.Data preparation
- 3.Data Wrangling
- 4.Analyse Data
- 5.Train the model
- 6.Test the model
- 7.Deployment
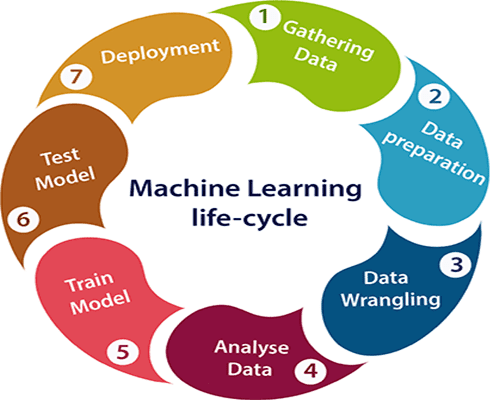
In the complete life cycle process, to solve a problem, we create a machine learning system called “model”, and this model is created by providing “training”. But to train a model, we need data, hence, life cycle starts by collecting data.
Gathering Data
Data Gathering is the first step of the machine learning life cycle. The goal of this step is to identify and obtain all data-related problems.
In this step, we need to identify the different data sources, as data can be collected from various sources such as files, database, internet, or mobile devices. It is one of the most important steps of the life cycle. The quantity and quality of the collected data will determine the efficiency of the output. The more will be the data, the more accurate will be the prediction.
This step includes the below tasks:
- Identify various data sources
- Collect data
- Integrate the data obtained from different sources
By performing the above task, we get a coherent set of data, also called as a dataset. It will be used in further steps.
Data preparation
After collecting the data, we need to prepare it for further steps. Data preparation is a step where we put our data into a suitable place and prepare it to use in our machine learning training.
In this step, first, we put all data together, and then randomize the ordering of data.
This step can be further divided into two processes:
Data exploration:
It is used to understand the nature of data that we have to work with. We need to understand the characteristics, format, and quality of data.
A better understanding of data leads to an effective outcome. In this, we find Correlations, general trends, and outliers.
Data pre-processing:
Now the next step is preprocessing of data for its analysis.
Data Wrangling
Data wrangling is the process of cleaning and converting raw data into a usable format. It is the process of cleaning the data, selecting the variable to use, and transforming the data in a proper format to make it more suitable for analysis in the next step. It is one of the most important steps of the complete process. Cleaning of data is required to address the quality issues.
It is not necessary that data we have collected is always of our use as some of the data may not be useful. In real-world applications, collected data may have various issues, including:
- Missing Values
- Duplicate data
- Invalid data
- Noise
So, we use various filtering techniques to clean the data.
It is mandatory to detect and remove the above issues because it can negatively affect the quality of the outcome.
Data Analysis
Now the cleaned and prepared data is passed on to the analysis step.
This step involves:
- Selection of analytical techniques
- Building models
- Review the result
The aim of this step is to build a machine learning model to analyze the data using various analytical techniques and review the outcome. It starts with the determination of the type of the problems, where we select the machine learning techniques such as Classification, Regression, Cluster analysis, Association, etc. then build the model using prepared data, and evaluate the model.
Hence, in this step, we take the data and use machine learning algorithms to build the model.
Train Model
Now the next step is to train the model, in this step we train our model to improve its performance for better outcome of the problem.
We use datasets to train the model using various machine learning algorithms. Training a model is required so that it can understand the various patterns, rules, and features.
Test Model
Once our machine learning model has been trained on a given dataset, then we test the model. In this step, we check for the accuracy of our model by providing a test dataset to it.
Testing the model determines the percentage accuracy of the model as per the requirement of project or problem.

Advance your Career with Machine Learning Training By World Class Faculty
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Deployment
The last step of the machine learning life cycle is deployment, where we deploy the model in the real-world system.
If the above-prepared model is producing an accurate result as per our requirement with acceptable speed, then we deploy the model in the real system. But before deploying the project, we will check whether it is improving its performance using available data or not. The deployment phase is similar to making the final report for a project.
Classification of Machine Learning
At a broad level, machine learning can be classified into three types:
- 1.Supervised learning
- 2.Unsupervised learning
- 3.Reinforcement learning
Supervised Learning
Supervised learning is a type of machine learning method in which we provide sample labeled data to the machine learning system in order to train it, and on that basis, it predicts the output.
The system creates a model using labeled data to understand the datasets and learn about each data, once the training and processing are done then we test the model by providing a sample data to check whether it is predicting the exact output or not.
The goal of supervised learning is to map input data with the output data. The supervised learning is based on supervision, and it is the same as when a student learns things in the supervision of the teacher. The example of supervised learning is spam filtering.
Supervised learning can be grouped further in two categories of algorithms:
- Classification
- Regression
Unsupervised Learning
Unsupervised learning is a learning method in which a machine learns without any supervision.
The training is provided to the machine with the set of data that has not been labeled, classified, or categorized, and the algorithm needs to act on that data without any supervision. The goal of unsupervised learning is to restructure the input data into new features or a group of objects with similar patterns.
In unsupervised learning, we don’t have a predetermined result. The machine tries to find useful insights from the huge amount of data. It can be further classified into two categories of algorithms:
- Clustering
- Association
Reinforcement Learning
Reinforcement learning is a feedback-based learning method, in which a learning agent gets a reward for each right action and gets a penalty for each wrong action. The agent learns automatically with these feedbacks and improves its performance. In reinforcement learning, the agent interacts with the environment and explores it. The goal of an agent is to get the most reward points, and hence, it improves its performance.
The robotic dog, which automatically learns the movement of his arms, is an example of Reinforcement learning.
Applications of Machines Learning
Machine Learning is the most rapidly growing technology and according to researchers we are in the golden year of AI and ML. It is used to solve many real-world complex problems which cannot be solved with a traditional approach.
Following are some real-world applications of ML
- Emotion analysis
- Sentiment analysis
- Error detection and prevention
- Weather forecasting and prediction
- Stock market analysis and forecasting
- Speech synthesis
- Speech recognition
- Customer segmentation
- Object recognition
- Fraud detection
- Fraud prevention
- Recommendation of products to customers in online shopping.
Features of Machine Learning
- Machine learning uses data to detect various patterns in a given dataset.
- It can learn from past data and improve automatically.
- It is a data-driven technology.
- Machine learning is much similar to data mining as it also deals with the huge amount of the data.
Machine Learning Examples
There are many ways in which machine learning impacts our daily lives, optimize operations and informs business decisions for some of the world’s leading organizations. There is a possibility that you are using it in one way or the other and you are absolutely unaware of it. In this section, we will focus on few amazing practical examples of machine learning.
- Voice & Image Recognition Systems
- Smart Email Categorization
- Search Recommendations & Suggestions
- Traffic Analysis & Predictions in Maps
- Determining Arrival Times & Pricing
Voice & Image Recognition Systems
It is quite difficult for computers to identify the difference between two distinct images (a tiger and a cat, for example), read a sign, or recognize a human’s face. With the help of deep convolutional neural networks, machine learning has made a tremendous progress in addressing the problems related to image recognition.
The machine learning models are at the centre stage of speech recognition methodology. The speech recognition have been evolved in the recent years due to advancements in deep learning. The two important machine learning models that are used in the automatic speech recognition systems are SVM and ANN.
Smart Email Categorization
A classifier based on machine learning could help a person or an organization reduce work hours spent on email support. This machine learning based classifier is trained to forward the emails to personnel or groups that manage different type of errands. These machine learning models are less prone to error and are more consistent.
Search Recommendations & Suggestions
Recommendation systems are one of the widespread and most successful applications of machine learning. The recommender systems make use of machine learning algorithms and provide customers with tailored suggestions based on their attributes or recommend items similar to those liked by them in the past. This is known as content based filtering. Today’s modern recommender systems contain collaborative filtering along with content based filtering.
Machine learning is used in almost all the components of a search engine. The examples of search engines using machine learning are Google and Bing. Machine learning is used in places such as search ranking, query understanding (detecting navigational vs transactional queries), document/url understanding, recommending search queries based on users’ previous searches, etc.
Traffic Analysis & Predictions in Maps
Traffic is rapidly growing day-by-day in major cities all over the world, given the slow development of road infrastructure and increase in the densities of cars on roads. To tackle this problem, several organizations are using machine learning methods to develop predictive models for traffic.
These models infer and estimate the traffic flow at different times into the future by analyzing large amounts of data on traffic over several months and years. This work is leveraged in traffic maps that provide information to users on how traffic is increasing over time, and in services that offer traffic-sensitive directions by contemplating the inferred speeds on roads that aren’t sensed directly.
Determining Arrival Times & Pricing
Here, we will deal with an example of determining flight arrival times and pricing for flight tickets. The machine learning models are used to predict prices of flights with high amount of accuracy depending on historical fare data. The machine learning models that can be used here are linear SVM, logistic regression, Partial Least Squares Regression, etc. Based on data related to historical flight departures and arrivals, and weather observations, the Deep Neural Networks accurately determine the arrival times of flights.
How is machine learning is utilized today in our daily life?
The use of machine learning is implemented across the world and it is not limited to the following:
Fraud detection:
Based on your buying pattern if you the system observes any uncertainty it quickly alerts the authorities and at the same time intimates the user.
The best example is your Gmail account login. If you have logged into your Gmail account from a different city or country or logged into your Gmail account from a new device, immediately you will get an email to your account. This means your regular device and the internet connection is been logged somewhere and a system is monitoring for uncertainties.
Web search results:
All your search results are tracked and based on your search history pattern, real-time ads are displayed on the web browsers.
For example: If you have searched for any Televisions on Amazon and closed your browser and then started browsing or reading something over the internet, TV-related ads will be shown in the browser prompting the user to buy.
Text-based sentiment analysis:
The best example for this is your Gmail app on your iPhone or your Android phone. If you have the latest app updated on your phone, whenever a user reads the email, predefined options are displayed for the user to reply back. This way the user doesn’t have to manually type. This is one such example where the email is read by the system already and it has come to certain conclusions and the keywords are displayed for the user.
A lot of software companies have built a product using text-based sentiment analysis concept and minting money on these products. Once the product is utilized by companies they can understand their customer’s reviews and comments. All the comments and reviews put forward by their customers are read and analyzed and categorized into meaningful data for the business. With this, they can classify if their customers are satisfied or if they have a problem the business would understand how many individuals have faced this particular problem.
Thus helping the business in every aspect and helping them to correct themselves and maintain a profitable business for themselves.
Conclusion
Industries working with large varieties and amounts of data that have incorporated machine learning into their business processes, are able to benefit from intelligent, real-time data analysis. Unlike traditional analytics, machine learning is scalable, continuously learning, and automated.
To adopt and integrate machine learning into your business processes, data availability and data governance issues need to be addressed. In order for machine learning algorithms to truly benefit your business, you should refine them continuously based on data and adjust them according to your business objectives. So, it is in the best interest of the organization to provide as much data as possible to machine learning algorithms as their decision making capability depends on the amount of data you provide to them.