
- Multilayer Perceptron Tutorial – An Complete Overview
- AWS Machine Learning Tutorial | Ultimate Step-by-Step Guide
- Keras Tutorial : What is Keras? | Learn from Scratch
- Machine Learning Algorithms for Data Science Tutorial
- Machine Learning-Random Forest Algorithm Tutorial
- Naive Bayes
- Classification – Machine Learning Tutorial
- Tensorflow Tutorial
- Deep Learning Tutorial
- Perceptron Tutorial
- Machine Learning Tutorial
- Multilayer Perceptron Tutorial – An Complete Overview
- AWS Machine Learning Tutorial | Ultimate Step-by-Step Guide
- Keras Tutorial : What is Keras? | Learn from Scratch
- Machine Learning Algorithms for Data Science Tutorial
- Machine Learning-Random Forest Algorithm Tutorial
- Naive Bayes
- Classification – Machine Learning Tutorial
- Tensorflow Tutorial
- Deep Learning Tutorial
- Perceptron Tutorial
- Machine Learning Tutorial

Machine Learning Algorithms for Data Science Tutorial
Last updated on 29th Sep 2020, Blog, Machine Learning, Tutorials
What is Machine Learning?
Arthur Samuel coined the term Machine Learning in the year 1959. He was a pioneer in Artificial Intelligence and computer gaming, and defined Machine Learning as “Field of study that gives computers the capability to learn without being explicitly programmed”.
In simple terms, Machine Learning is an application of Artificial Intelligence (AI) which enables a program(software) to learn from the experiences and improve their self at a task without being explicitly programmed. For example, how would you write a program that can identify fruits based on their various properties, such as colour, shape, size or any other property?
One approach is to hardcode everything, make some rules and use them to identify the fruits. This may seem the only way and work but one can never make perfect rules that apply on all cases. This problem can be easily solved using machine learning without any rules which makes it more robust and practical. You will see how we will use machine learning to do this task in the coming sections.
Thus, we can say that Machine Learning is the study of making machines more human-like in their behaviour and decision making by giving them the ability to learn with minimum human intervention, i.e., no explicit programming. Now the question arises, how can a program attain any experience and from where does it learn? The answer is data. Data is also called the fuel for Machine Learning and we can safely say that there is no machine learning without data.
You may be wondering that the term Machine Learning has been introduced in 1959 which is a long way back, then why haven’t there been any mention of it till recent years? You may want to note that Machine Learning needs a huge computational power, a lot of data and devices which are capable of storing such vast data. We have only recently reached a point where we now have all these requirements and can practice Machine Learning.
Subscribe For Free Demo
Error: Contact form not found.
Why do we need Machine Learning?
Machine Learning today has all the attention it needs. Machine Learning can automate many tasks, especially the ones that only humans can perform with their innate intelligence. Replicating this intelligence to machines can be achieved only with the help of machine learning.
With the help of Machine Learning, businesses can automate routine tasks. It also helps in automating and quickly create models for data analysis. Various industries depend on vast quantities of data to optimize their operations and make intelligent decisions. Machine Learning helps in creating models that can process and analyze large amounts of complex data to deliver accurate results. These models are precise and scalable and function with less turnaround time. By building such precise Machine Learning models, businesses can leverage profitable opportunities and avoid unknown risks.
Image recognition, text generation, and many other use-cases are finding applications in the real world. This is increasing the scope for machine learning experts to shine as a sought after professionals.
Types of Machine Learning
Machine learning has been broadly categorized into three categories
- 1.Supervised Learning
- 2.Unsupervised Learning
- 3.Reinforcement Learning
What is Supervised Learning?
Let us start with an easy example, say you are teaching a kid to differentiate dogs from cats. How would you do it?
You may show him/her a dog and say “here is a dog” and when you encounter a cat you would point it out as a cat. When you show the kid enough dogs and cats, he may learn to differentiate between them. If he is trained well, he may be able to recognise different breeds of dogs which he hasn’t even seen.
Similarly, in Supervised Learning, we have two sets of variables. One is called the target variable, or labels (the variable we want to predict) and features(variables that help us to predict target variables). We show the program(model) the features and the label associated with these features and then the program is able to find the underlying pattern in the data. Take this example of the dataset where we want to predict the price of the house given its size. The price which is a target variable depends upon the size which is a feature.
| Number of rooms | Price |
| 1 | $100 |
| 3 | $300 |
| 5 | $500 |
In a real dataset, we will have a lot more rows and more than one features like size, location, number of floors and many more.
Thus, we can say that the supervised learning model has a set of input variables (x), and an output variable (y). An algorithm identifies the mapping function between the input and output variables. The relationship is y = f(x).
The learning is monitored or supervised in the sense that we already know the output and the algorithm are corrected each time to optimise its results. The algorithm is trained over the data set and amended until it achieves an acceptable level of performance.
We can group the supervised learning problems as:
Regression problems – Used to predict future values and the model is trained with the historical data. E.g., Predicting the future price of a house.
Classification problems – Various labels train the algorithm to identify items within a specific category. E.g., Dog or cat( as mentioned in the above example), Apple or an orange, Beer or wine or water.
What is Unsupervised Learning?
This approach is the one where we have no target variables, and we have only the input variable(features) at hand. The algorithm learns by itself and discovers an impressive structure in the data.
The goal is to decipher the underlying distribution in the data to gain more knowledge about the data.
We can group the unsupervised learning problems as:
Clustering: This means bundling the input variables with the same characteristics together. E.g., grouping users based on search history
Association: Here, we discover the rules that govern meaningful associations among the data set. E.g., People who watch ‘X’ will also watch ‘Y’.
What is Reinforcement Learning?
In this approach, machine learning models are trained to make a series of decisions based on the rewards and feedback they receive for their actions. The machine learns to achieve a goal in complex and uncertain situations and is rewarded each time it achieves it during the learning period.
Reinforcement learning is different from supervised learning in the sense that there is no answer available, so the reinforcement agent decides the steps to perform a task. The machine learns from its own experiences when there is no training data set present.
In this tutorial, we are going to mainly focus on Supervised Learning and Unsupervised learning as these are quite easy to understand and implement.
What machine learning algorithms can you use?
Choosing the right machine learning algorithm depends on several factors, including, but not limited to: data size, quality and diversity, as well as what answers businesses want to derive from that data. Additional considerations include accuracy, training time, parameters, data points and much more. Therefore, choosing the right algorithm is both a combination of business need, specification, experimentation and time available. Even the most experienced data scientists cannot tell you which algorithm will perform the best before experimenting with others. We have, however, compiled a machine learning algorithm ‘cheat sheet’ which will help you find the most appropriate one for your specific challenges.
What are the most common and popular machine learning algorithms?
Naïve Bayes Classifier Algorithm (Supervised Learning – Classification)
The Naïve Bayes classifier is based on Bayes’ theorem and classifies every value as independent of any other value. It allows us to predict a class/category, based on a given set of features, using probability.
Despite its simplicity, the classifier does surprisingly well and is often used due to the fact it outperforms more sophisticated classification methods.
K Means Clustering Algorithm (Unsupervised Learning – Clustering
The K Means Clustering algorithm is a type of unsupervised learning, which is used to categorise unlabelled data, i.e. data without defined categories or groups. The algorithm works by finding groups within the data, with the number of groups represented by the variable K. It then works iteratively to assign each data point to one of K groups based on the features provided.
Support Vector Machine Algorithm (Supervised Learning – Classification)
Support Vector Machine algorithms are supervised learning models that analyse data used for classification and regression analysis. They essentially filter data into categories, which is achieved by providing a set of training examples, each set marked as belonging to one or the other of the two categories. The algorithm then works to build a model that assigns new values to one category or the other.
Linear Regression (Supervised Learning/Regression)
Linear regression is the most basic type of regression. Simple linear regression allows us to understand the relationships between two continuous variables.
Logistic Regression (Supervised learning – Classification)
Logistic regression focuses on estimating the probability of an event occurring based on the previous data provided. It is used to cover a binary dependent variable, that is where only two values, 0 and 1, represent outcomes.
Artificial Neural Networks (Reinforcement Learning)
An artificial neural network (ANN) comprises ‘units’ arranged in a series of layers, each of which connects to layers on either side. ANNs are inspired by biological systems, such as the brain, and how they process information. ANNs are essentially a large number of interconnected processing elements, working in unison to solve specific problems.
ANNs also learn by example and through experience, and they are extremely useful for modelling non-linear relationships in high-dimensional data or where the relationship amongst the input variables is difficult to understand.
Decision Trees (Supervised Learning – Classification/Regression)
A decision tree is a flow-chart-like tree structure that uses a branching method to illustrate every possible outcome of a decision. Each node within the tree represents a test on a specific variable – and each branch is the outcome of that test.
Random Forests (Supervised Learning – Classification/Regression)
Random forests or ‘random decision forests’ is an ensemble learning method, combining multiple algorithms to generate better results for classification, regression and other tasks. Each individual classifier is weak, but when combined with others, can produce excellent results. The algorithm starts with a ‘decision tree’ (a tree-like graph or model of decisions) and an input is entered at the top. It then travels down the tree, with data being segmented into smaller and smaller sets, based on specific variables.
Nearest Neighbours (Supervised Learning)
The K-Nearest-Neighbour algorithm estimates how likely a data point is to be a member of one group or another. It essentially looks at the data points around a single data point to determine what group it is actually in. For example, if one point is on a grid and the algorithm is trying to determine what group that data point is in (Group A or Group B, for example) it would look at the data points near it to see what group the majority of the points are in.
Clearly, there are a lot of things to consider when it comes to choosing the right machine learning algorithms for your business’ analytics. However, you don’t need to be a data scientist or expert statistician to use these models for your business. At SAS, our products and solutions utilise a comprehensive selection of machine learning algorithms, helping you to develop a process that can continuously deliver value from your data.
Machine learning Algorithms
This may be the most time-consuming and difficult process in your journey of Machine Learning. There are many algorithms in Machine Learning and you don’t need to know them all in order to get started. But I would suggest, once you start practising Machine Learning, start learning about the most popular algorithms out there such as:
- Linear Regression
- Logistic Regression
- Decision Tree
- SVM
- Naive Bayes
- K-nearest neighbour
- K-Means
- Random Forest
- Gradient Boosting algorithms
- GBM
- XGBoost
- LightGBM
- CatBoost

Get On-Demand Machine Learning Training to Enhance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Here, I am going to give a brief overview of one of the simplest algorithms in Machine learning, the K-nearest neighbour Algorithm (which is a Supervised learning algorithm) and show how we can use it for Regression as well as for classification. I would highly recommend checking the Linear Regression and Logistic Regression as we are going to implement them and compare the results with KNN(K-nearest neighbour) algorithm in the implementation part.
You may want to note that there are usually separate algorithms for regression problems and classification problems. But by modifying an algorithm, we can use it for both classifications as well as regression as you will see below
K-Nearest Neighbour Algorithm
KNN belongs to a group of lazy learners. As opposed to eager learners such as logistic regression, SVM, neural nets, lazy learners just store the training data in memory. During the training phase, KNN arranges the data (sort of indexing process) in order to find the closest neighbours efficiently during the inference phase. Otherwise, it would have to compare each new case during inference with the whole dataset making it quite inefficient.
So if you are wondering what is a training phase, eager learners and lazy learners, for now just remember that training phase is when an algorithm learns from the data provided to it. For example, if you have gone through the Linear Regression algorithm linked above, during the training phase the algorithm tries to find the best fit line which is a process that includes a lot of computations and hence takes a lot of time and this type of algorithm is called eager learners. On the other hand, lazy learners are just like KNN which do not involve many computations and hence train faster.
K-NN for Classification Problem
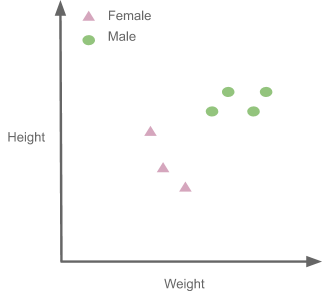
Now let us see how we can use K-NN for classification. Here a hypothetical dataset which tries to predict if a person is male or female(labels) on the base of the height and weight(features).
| Height(cm) -feature | Weight(kg) -feature. | Gender(label) |
| 187 | 80 | Male |
| 165 | 50 | Female |
| 199 | 99 | Male |
| 145 | 70 | Female |
| 180 | 87 | Male |
| 178 | 65 | Female |
| 187 | 60 | Male |
Now let us plot these points:
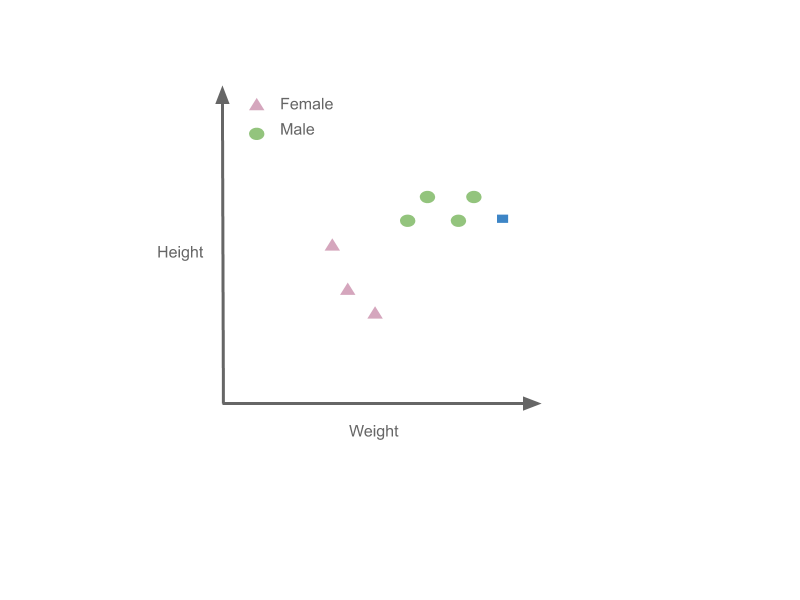
Now we have a new point that we want to classify, given that its height is 190 cm and weight is 100 Kg. Here is how K-NN will classify this point:
- 1.Select the value of K, which the user selects which he thinks will be best after analysing the data.
- 2.Measure the distance of new points from its nearest K number of points. There are various methods for calculating this distance, of which the most commonly known methods are – Euclidian, Manhattan (for continuous data points i.e regression problems) and Hamming distance (for categorical i.e for classification problems).
- 3.Identify the class of the points that are more closer to the new point and label the new point accordingly. So if the majority of points closer to our new point belong to a certain “a” class than our new point is predicted to be from class “a”.
Now let us apply this algorithm to our own dataset. Let us first plot the new data point.
Now let us take k=3 i.e, we will see the three closest points to the new point:
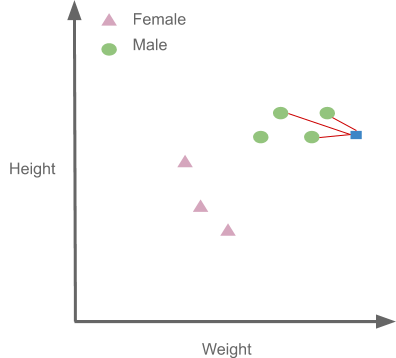
Therefore, it is classified as Male:
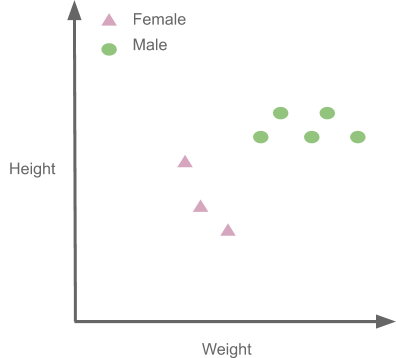
Now let us take the value of k=5 and see what happens:
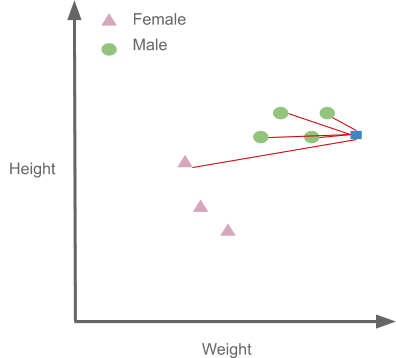
As we can see four of the points closest to our new data point are males and just one point is female, so we go with the majority and classify it as Male again. You must always select the value of K as an odd number when doing classification.
K-NN for a Regression problem
We have seen how we can use K-NN for classification. Now, let us see what changes are made to use it for regression. The algorithm is almost the same there is just one difference. In Classification, we checked for the majority of all nearest points. Here, we are going to take the average of all the nearest points and take that as predicted value. Let us again take the same example but here we have to predict the weight(label) of a person given his height(features).
| Height(cm) -feature | Weight(kg) -label |
| 187 | 80 |
| 165 | 50 |
| 199 | 99 |
| 145 | 70 |
| 180 | 87 |
| 178 | 65 |
| 187 | 60 |
Now we have new data point with a height of 160cm, we will predict its weight by taking the values of K as 1,2 and 4.
When K=1: The closest point to 160cm in our data is 165cm which has a weight of 50, so we conclude that the predicted weight is 50 itself.
When K=2: The two closest points are 165 and 145 which have weights equal to 50 and 70 respectively. Taking average we say that the predicted weight is (50+70)/2=60.
When K=4: Repeating the same process, now we take 4 closest points instead and hence we get 70.6 as predicted weight.
You might be thinking that this is really simple and there is nothing so special about Machine learning, it is just basic Mathematics. But remember this is the simplest algorithm and you will see much more complex algorithms once you move ahead in this journey.
At this stage, you must have a vague idea of how machine learning works, don’t worry if you are still confused. Also if you want to go a bit deep now, here is an excellent article – Gradient Descent in Machine Learning, which discusses how we use an optimization technique called as gradient descent to find a best-fit line in linear regression.
Future of Machine Learning
Machine Learning can be a competitive advantage to any company, be it a top MNC or a startup. As things that are currently being done manually will be done tomorrow by machines. With the introduction of projects such as self-driving cars, Sophia(a humanoid robot developed by Hong Kong-based company Hanson Robotics) we have already started a glimpse of what the future can be. The Machine Learning revolution will stay with us for long and so will be the future of Machine Learning.
This brings us to the end of this tutorial. Check out our PG program in machine learning. Also, here is a free course about Machine Learning that can help you to make your foundations much stronger.