
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Apache Spark Streaming Tutorial | Best Guide For Beginners
Last updated on 10th Aug 2022, Big Data, Blog, Tutorials
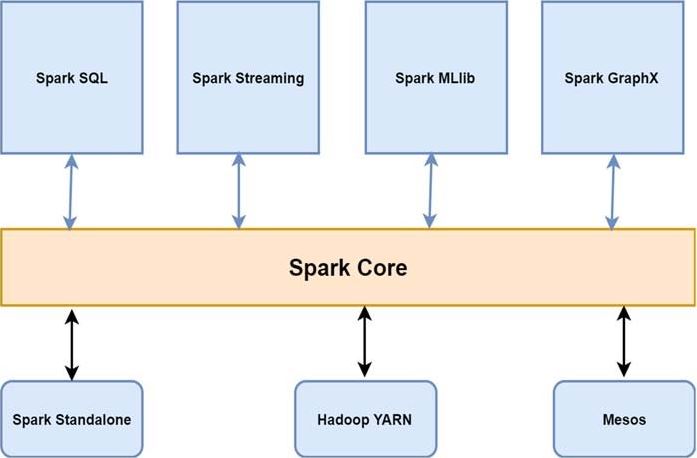
What is Apache Spark Streaming?
Spark streaming is simply an extension of the core Spark API that handles fault-tolerant, high-throughput, scalable live stream processing. Spark streaming takes live data streams as input and divides them into batches as output. The Spark engine then processes these streams, resulting in batches of final stream results.
Example of Spark Streaming:
Here are some real-time Apache Spark Streaming examples:
- Monitoring of websites and networks
- Detection of Fraud
- Sensors for the Internet of Things
- Web advertising clicks
Spark Streaming Architecture:
Instead of processing streaming data in steps of records per unit time, Spark streaming discretizes it into micro-batches. Data is accepted in parallel by the Spark streaming receivers, and this data is held as a buffer in the Spark worker nodes.To process batches, the Spark engine, which is typically optimized for latency, executes short tasks and returns the results to other systems. Spark tasks are dynamically assigned to workers based on available resources and data location. Its obvious advantages are improved load balancing and faster fault recovery.Each batch of data is composed of a resilient distributed dataset (RDD), and this is the fundamental abstraction in Spark for fault-tolerant datasets. Because of this feature, streaming data can be processed using any Spark code snippet or library.
Spark Streaming Advantages:
- Usability – Spark streaming uses Apache Spark’s language-integrated API for stream processing. Streaming jobs can be written in the same way that batch jobs are. Spark streaming supports Java, Scala, and Python.
- Spark Integration – Because Spark streaming runs on Spark, similar code can be reused for running ad-hoc queries on stream state, batch processing, and joining streams against historical data. In addition to analytics, powerful interactive applications can be created.
- Fault tolerance – Spark streaming can recover lost work and operator state without requiring additional code from the developer.
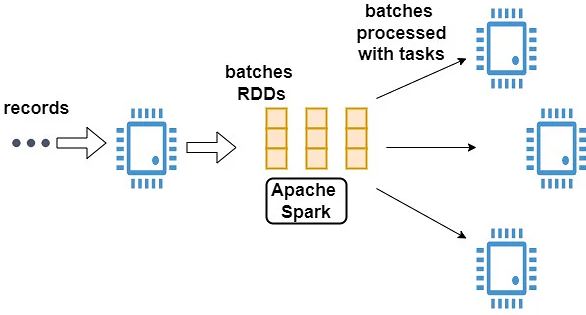
Features of Spark Streaming:
- Ease of use – Spark streaming employs Apache Spark’s language-integrated API for stream processing. Streaming jobs can be written in the same manner as batch jobs. Spark streaming is compatible with Java, Scala, and Python.
- Spark Integration – Because Spark streaming runs on Spark, similar code can be reused. This is useful for running ad-hoc queries on stream state, batch processing, and joining streams against historical data. Aside from analytics, powerful interactive applications can be created.
- Fault tolerance – Lost work and operator state can both be recovered by Spark streaming without the need for additional developer code.
Applications for Spark Streaming:
Spark Streaming is currently implemented in four different ways:
- Streaming ETL – Data is cleaned and aggregated before being stockpiled in data stores.
- Triggers – Abnormal activity is detected in real time, and subsequent actions are triggered.
- Sophisticated Sessions and Continuous Learning – Events from a live session can be grouped and analyzed together. Machine learning models are constantly updated using session data.
- Data Enrichment – By combining live data with a static dataset, real-time analysis is possible when the live data is enriched with additional information.
Spark Streaming Performance:
The Spark streaming component’s ability to batch data and use the Spark engine provides higher throughput than other streaming systems. Spark streaming can achieve latencies as low as a few hundred milliseconds.Spark processes all data in batches because it processes it all at once. Micro batching appears to significantly increase overall latency. In practise, however, batching latency is just one component of overall pipeline latency.
As an example, many applications typically compute over a sliding window, and this window is updated on a regular basis, such as a 15-second window that slides every 1.5 seconds. Pipelines collect records from multiple sources and typically wait for out-of-order data to be processed.An automatic triggering algorithm waits for a time period before firing a trigger. When compared to end-to-end latency, batching rarely adds overhead. As a result of the throughput gains from DStreams, fewer machines would be required to handle the same workload.
Spark Streaming Use Cases:
- Every day, Uber collects terabytes of event data from its mobile users for real-time telemetry analysis. By constructing a continuous ETL pipeline using Kafka, Spark Streaming, and HDFS, Uber converts unstructured event data into structured data as it is collected and sends it for complex analytics.
- Pinterest’s ETL data pipeline feeds data to Spark via Spark streaming to provide a picture of how users are engaging with Pins around the world in real-time. Pinterest’s recommendation engine is thus very good in that it can show related pins as people use the service to plan places to go, products to buy, and recipes to cook.
- Netflix receives billions of events from various sources. They created a real-time engine using Kafka and Spark streaming to provide users with the most relevant movie recommendations.
Spark Streaming Fundamentals:
- Streaming Context
- DStream
- Caching
- Accumulators, Broadcast Variables and Checkpoints
Context of Streaming: In Spark, Streaming Context consumes a stream of data. It creates a Receiver object by registering an Input DStream. It is the primary point of access to Spark functionality. Spark includes several default implementations of sources such as Twitter, Akka Actor, and ZeroMQ that are accessible from the context.A SparkContext object can be used to create a StreamingContext object. A SparkContext represents a Spark cluster’s connection and can be used to create RDDs, accumulators, and broadcast variables on that cluster.
DStream: Spark Streaming’s basic abstraction is the discretized stream (DStream). It is a continuous data stream. It is obtained from a data source or from a processed data stream produced by transforming the input stream. A DStream is internally represented by a continuous series of RDDs, with each RDD containing data from a specific interval.
Input DStreams: Input DStreams are DStreams that represent the stream of data received from streaming sources. Every input DStream has a Receiver object that receives data from a source and stores it in Spark’s memory for processing.
DStream Transformations: Any operation performed on a DStream corresponds to operations performed on the underlying RDDs. Transformations, like RDDs, allow the data from the input DStream to be modified. Many of the transformations available on standard Spark RDDs are supported by DStreams.
DStreams of output: DStream’s data can be pushed out to external systems such as databases or file systems using output operations. Output operations initiate the execution of all DStream transformations.
Caching: DStreams enable developers to cache/persist the data of a stream in memory. If the data in the DStream will be computed multiple times, this is useful. This can be accomplished by calling the persist() method on a DStream.
Accumulators: Accumulators are variables that can only be added using associative and commutative operations. They are employed in the implementation of counters or sums. Understanding the progress of running stages can be aided by tracking accumulators in the UI. Numeric accumulators are natively supported by Spark. We can make both named and unnamed accumulators.
Need for Spark Streaming:
Companies are collecting increasing amounts of data and want to extract value from it in real time. Online transactions, social networks, and sensors generate data that must be continuously monitored and acted upon. As a result, real-time stream processing is more important than ever.
For example: online purchases necessitate the storage of all associated data (e.g., date, time, items, price) in order for organizations to analyze and make timely decisions based on customer behavior. Detecting fraudulent bank transactions (via data streams) is another application that necessitates pre-trained fraud models, and it can significantly reduce the likelihood of fraud occurring.
a) Straggler Recovery and Fast Failure: There is a greater chance of cluster nodes failing or slowing down unexpectedly (also known as stragglers). Traditional systems make it extremely difficult because continuous operators are statically assigned to worker nodes, making it extremely difficult for a system to provide results in real-time.
b) Load Distribution: Another issue with the continuous operator system is the uneven distribution of processing load among the workers. It typically causes system bottlenecks and is more likely to occur in large clusters with dynamically varying workloads. The system necessitates dynamic resource allocation in response to workload.
c) Merging Streaming, Batch, and Interactive Workloads: Streaming data can also be interactively queried or combined with static datasets (Eg. pre-computed models). This is difficult to implement in continuous operator systems that lack operators for ad hoc queries, and a single engine must handle batch, streaming, and interactive queries.
d) SQL Queries and Machine Learning for Advanced Analytics: Complex workloads necessitate continuous learning and updating data models based on new information. In some cases, even querying the streaming data with SQL queries is required, which the traditional model does not allow for.
| Parameters | Apache Kafka | Apache Spark |
|---|---|---|
| Stream Processing Style | Each event is processed as it arrives. As a result, it relies on event-based(continuous) processing. | The model involves micro-batch processing, and incoming streams are divided into small batches for further processing. |
| Infrastructure | As it is a Java client library, it can execute wherever Java is supported. | It runs on top of the Spark stack that can be anyone of Spark standalone, YARN, or container-based. |
| Data Sources | Topics and streams are used to process data from Kafka itself. | Data is ingested from various sources, including files, Kafka, sockets, and other sources. |
| Latency | Due to its low latency, it is faster than Apache Spark | Latency is higher. |
| ETL Transformation | It is not supported. | Spark supports ETL transformation. |
| Fault-tolerance | Implicit support with internal Kafa topics | Implicit checkpoint support with HDFS |
| Language Support | Supports Java and Scala mainly | Support multiple languages such as Python, Scala, R, Java |
| Use Cases | Many companies use Kafka Streams to store and distribute data, including Zalando, Trivago, Pinterest, etc. | Spark streams at Yelp (ad platform), Booking.com handles hundreds of millions of ad requests per day. |
Conclusion:
Spark streaming includes the ability to recover from failures in real time. Depending on the workload, resource allocation is dynamically adjusted. Using SQL queries to stream data has never been simpler. The Apache Foundation has pioneered new technologies such as Spark, Hadoop, and other big data tools.Spark streaming is Spark’s streaming data capability, and it is a very efficient one at that. In comparison to legacy streaming alternatives, Spark streaming is the best option for performing data analytics on real-time data streams.