
- An Overview of AWS Machine Learning Tutorial
- Mapplet In Informatica | Purpose and Implementation of Mapplets | Expert’s Top Picks | Free Guide Tutorial
- Spring Cloud Tutorial
- Azure IoT Hub Integration Tutorial | For Beginners Learn in 1 Day FREE
- Cloud Native Microservices Tutorial | A Comprehensive Guide
- Azure Stream Analytics | Learn in 1 Day FREE Tutorial
- Azure Data Warehouse | Learn in 1 Day FREE Tutorial
- AWS Lambda Tutorial | A Guide to Creating Your First Function
- Azure Logic Apps Tutorial – A beginners Guide & its Complete Overview
- Azure Service Bus Tutorial | Complete Overview – Just An Hour for FREE
- Introduction to Azure Service Fabric Tutorial | Learn from Scratch
- Amazon CloudWatch Tutorial | Ultimate Guide to Learn [BEST & NEW]
- AWS Data Pipeline Documentation Tutorial | For Beginners Learn in 1 Day FREE
- What is Azure App Service? | A Complete Guide for Beginners
- AWS Key Management Service | All You Need to Know
- Apigee Tutorial | A Comprehensive Guide for Beginners
- Kubernetes Tutorial | Step by Step Guide to Basic
- AWS SQS – Simple Queue Service Tutorial | Quickstart – MUST READ
- AWS Glue Tutorial
- MuleSoft
- Cloud Computing Tutorial
- AWS CloudFormation tutorial
- AWS Amazon S3 Bucket Tutorial
- Kubernetes Cheat Sheet Tutorial
- AWS IAM Tutorial
- Cloud Concepts And Models Tutorial
- Cloud Network Security Tutorial
- Azure Active Directory Tutorial
- NetApp Tutorial
- OpenStack tutorial
- AWS Cheat Sheet Tutorial
- Informatica Transformations Tutorial
- AWS vs AZURE Who is The Right Cloud Platform?
- How to Host your Static Website with AWS Tutorial
- VMware Tutorial
- Edge Computing Tutorial
- Cognitive Cloud Computing Tutorial
- Serverless Computing Tutorial
- Sharepoint Tutorial
- AWS Tutorial
- Microsoft Azure Tutorial
- IOT Tutorial
- An Overview of AWS Machine Learning Tutorial
- Mapplet In Informatica | Purpose and Implementation of Mapplets | Expert’s Top Picks | Free Guide Tutorial
- Spring Cloud Tutorial
- Azure IoT Hub Integration Tutorial | For Beginners Learn in 1 Day FREE
- Cloud Native Microservices Tutorial | A Comprehensive Guide
- Azure Stream Analytics | Learn in 1 Day FREE Tutorial
- Azure Data Warehouse | Learn in 1 Day FREE Tutorial
- AWS Lambda Tutorial | A Guide to Creating Your First Function
- Azure Logic Apps Tutorial – A beginners Guide & its Complete Overview
- Azure Service Bus Tutorial | Complete Overview – Just An Hour for FREE
- Introduction to Azure Service Fabric Tutorial | Learn from Scratch
- Amazon CloudWatch Tutorial | Ultimate Guide to Learn [BEST & NEW]
- AWS Data Pipeline Documentation Tutorial | For Beginners Learn in 1 Day FREE
- What is Azure App Service? | A Complete Guide for Beginners
- AWS Key Management Service | All You Need to Know
- Apigee Tutorial | A Comprehensive Guide for Beginners
- Kubernetes Tutorial | Step by Step Guide to Basic
- AWS SQS – Simple Queue Service Tutorial | Quickstart – MUST READ
- AWS Glue Tutorial
- MuleSoft
- Cloud Computing Tutorial
- AWS CloudFormation tutorial
- AWS Amazon S3 Bucket Tutorial
- Kubernetes Cheat Sheet Tutorial
- AWS IAM Tutorial
- Cloud Concepts And Models Tutorial
- Cloud Network Security Tutorial
- Azure Active Directory Tutorial
- NetApp Tutorial
- OpenStack tutorial
- AWS Cheat Sheet Tutorial
- Informatica Transformations Tutorial
- AWS vs AZURE Who is The Right Cloud Platform?
- How to Host your Static Website with AWS Tutorial
- VMware Tutorial
- Edge Computing Tutorial
- Cognitive Cloud Computing Tutorial
- Serverless Computing Tutorial
- Sharepoint Tutorial
- AWS Tutorial
- Microsoft Azure Tutorial
- IOT Tutorial

AWS Data Pipeline Documentation Tutorial | For Beginners Learn in 1 Day FREE
Last updated on 10th Aug 2022, Blog, Cloud Computing, Tutorials
What is the AWS Data Pipeline?
AWS Data Pipeline is a service that can be used to handle, transform, and transfer data, particularly business data. This service can be automated, and data-driven workflows can be established to eliminate errors and extended work hours. You may use AWS Data Pipeline to do the following:
- Ensure that the relevant resources are available.
- Workloads for complex data processing should be created.
- Data can be transferred to any of the AWS services.
- Give each task the necessary pauses/breaks.
- Manage any interconnected jobs efficiently.
- Create a mechanism to alert you of any errors that occur during the procedure.
- Data locked in on-premises data silos must be transferred and transformed.
- After the unstructured data has been examined, it can be moved to Redshift for a few simple queries.
- Even the log files should be moved from AWS Log to Amazon Redshift.
- Data can be protected via AWS’s Disaster Recovery methods, where necessary data can be restored from backups.
- Overall, AWS Data Pipeline is utilized when a specified path of data sources and data exchange is required for processing data, as determined by the users. It is a user-friendly service that is widely used in today’s corporate sector.
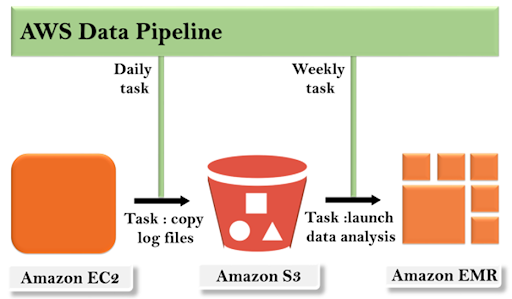
AWS Data Pipeline – Idea
AWS Data Pipeline is a data pipeline that works with three different input spaces: Redshift, Amazon S3, and DynamoDB.The information gathered from these three input valves is routed to the Data Pipeline.When data arrives at the Data Pipeline, it is analyzed and processed.The processed data is then transported to the output valve, which can be Amazon S3 / Redshift / Amazon Redshift.
Data Pipeline Advantages:
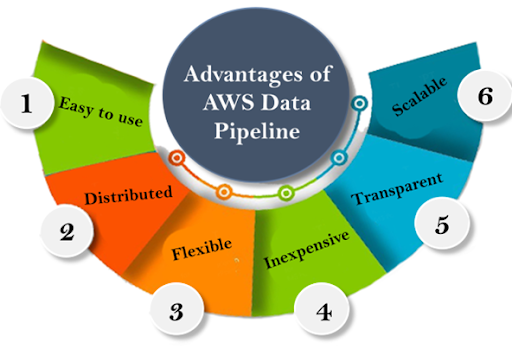
The following are six important advantages of AWS Data Pipeline:
- There are predefined sets of instructions and codes that allow the user to simply type the name of the function and the task will be performed. A pipeline can be easily created using this method.
- AWS Data Pipeline is available for free. Even its ‘Pro edition’ is less expensive, making it accessible to a wide range of users, both large and small.
- If your function fails in the middle or an error occurs, AWS Data Pipeline will automatically retry that action. It is simple to experiment with new tasks thanks to its failure notifications and rapid backup data. This functionality improves the dependability of AWS Data Pipeline.
- AWS Data Pipeline allows users to define their own working conditions rather than relying on the application’s preset set of functions. This feature provides users with flexibility as well as an efficient way to examine and handle data.
- Because of the AWS Data Pipeline’s flexibility, it is scalable to distribute work to multiple servers and analyze many files.
- A precise record of your whole execution logs will be delivered to Amazon S3, improving transparency and consistency. You can also use your business logic’s resources to improve and debug it as needed.
AWS Data Pipeline Components:
- The four primary components comprise numerous concepts that aid in the operation of AWS Data Pipeline.
- Pipeline Definition: This section addresses the rules and processes that must be followed when communicating business logic with the Data Pipeline. This definition includes the following details: The name, storage location, and data source format are all given and are referred to as “Data Nodes.” AWS Data Pipeline supports RedshiftDataNode, DynamoDBDataNode, S3DataNode, and SqlDataNode.
- When SQL Queries are executed on databases, they tend to change the data source of the data, which is referred to as “Activities.”
- When Activities are scheduled, they are referred to as “Schedules.”
- The user must complete the requirements / ‘Preconditions’ to have an action/activity executed in the AWS Data Pipeline. This must be completed prior to scheduling the Activities.
- The EMR cluster and Amazon EC2 are referred to as “Resources” since they are critical to the operation of the AWS Data Pipeline.
- Any status update regarding your AWS Data Pipeline is provided to you via an alarm or notification, which are referred to as ‘Actions.’
Pipeline:
A pipeline is made up of three major components:
- This category includes the components involved in creating communication between the user’s Data Pipeline and the AWS Services.
- Instances are the compiled pipeline components that contain the instructions for doing a certain task.
- Attempts deal with the retry’ option provided by an AWS Data Pipeline to its users in the event of a failed operation.
How to Create an AWS Data Pipeline:
- You may create an AWS Data Pipeline using a template or by hand in the console.
- Open the AWS Data Pipeline console by going to http://console.aws.amazon.com/.
- Select the necessary region’ from the ‘navigation bar.’ It makes no difference if the region is different from the place.
- The console will display an “introduction” where you should hit “Get started immediately” if the area you choose is brand-new.
- However, the console will look at the list of pipelines you have in that region if the region you choose is old. To create a new pipeline, choose “Create new pipeline.”
- Enter your Pipeline’s name in the ‘Name’ box and a description in the DESCRIPTION column.
- To determine the source, pick “Build using a template,” then “Getting started with ShellCommandActivity.”
- The ‘Parameters’ column will now appear. All you need to do is leave the default values for ‘S3 input folder’ and ‘Shell command to run’ alone. Now, near the ‘S3 output folder,’ tap the icon that looks like a folder, select the buckets and folders you require, and then press SELECT.
- You may schedule the AWS Data Pipeline by leaving the default values, which causes the Pipeline to run every 15 minutes for an hour.
- Alternatively, you may select “Run once on pipeline activation” to have this done automatically.
- You don’t need to modify anything in the ‘Pipeline Configuration’ column, but you can activate or disable logging. Select any of your folders/buckets from the ‘S3 location for logs’ section and press SELECT.
- Make sure the IAM roles are set to ‘Default’ in the ‘Security/Access’ column.
- After you’ve double-checked everything, click ACTIVATE. Select ‘Edit in Architect’ if you need to add new preconditions or alter an existing Pipeline.
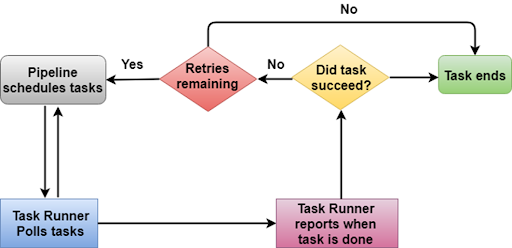
Monitoring instructions for the AWS Data Pipeline:
- You may view/monitor the operation of AWS Data Pipeline on the ‘Execution details’ page, which appears instantly after you start your Pipeline.
- Now, press UPDATE / F5 to refresh the page and see the most recent status updates. If there are no currently running ‘runs,’ check if the scheduled start is covered by ‘Start (in UTC)’ and the end of the Pipeline is covered by ‘End (in UTC),’ then press UPDATE.
- When the state of every object is ‘FINISHED,’ it implies that the Pipeline finished the scheduled tasks.
- If you have any unfinished jobs in your Pipeline, go to the ‘Settings’ tab and try to troubleshoot them.
- How do I access the generated output?
- Navigate to your ‘bucket / folder’ in the Amazon S3 dashboard.
- There will be four subfolders with the name “output.txt” that will only be present when the Pipeline runs every 15 minutes for an hour.
- How do I get rid of a pipeline?
- Navigate to the List Pipelines’ page.
- Select the Pipeline to be deleted.
- Select ACTIONS and then DELETE.
- A confirmation dialogue box will appear. To erase the Pipeline, you must press DELETE.
Conclusion:
AWS Data Pipeline is a web server that collects, monitors, stores, analyses, transforms, and transfers data on cloud platforms. By utilizing this Pipeline, one can save money and time while dealing with large amounts of data. As many businesses evolve and grow at a quick pace each year, the demand for AWS Data Pipeline grows as well. Be an AWS Data Pipeline master and build a successful career in this competitive, digital business world.