
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

What is Elasticsearch | Tutorial for Beginners
Last updated on 10th Aug 2022, Big Data, Blog, Tutorials
What is Elasticsearch?
First, let us consider why Elasticsearch was created. Consider the following scenario: buyers are looking for product information from a large product volume. However, due to the high amount of data, the system takes too long to retrieve information. This, in turn, leads to a poor user experience, and there is a risk of losing a potential customer as a result. When dealing with big amounts of data, RDBMS (Relational Database Management System) is slow. Elasticsearch was created to address this issue.Elasticsearch is a document-based system for storing, managing, and retrieving structured or unstructured data. Elasticsearch stores data in JSON document format. It also lacks schema. It is a NoSQL database that uses the Lucene search engine.To interact with data, Elasticsearch employs Query Domain Specific Language. Queries are written in JSON format here. We can fit all of the sophisticated logic in a single query by using Query DSL. The purpose of Query DSL is to handle all real-world sophisticated logic in a single query.
Elasticsearch Features:
Elasticsearch provides the following features:
- Elasticsearch works best with structured and unstructured data.
- Elasticsearch is a document store that is similar to MongoDB and RavenDB.
- Elasticsearch has used denormalization to boost search performance.
- Elasticsearch is used as a search engine by several large businesses, including Wikipedia, Github, and StackOverflow.
- It is a free and open technology.
- It is a user-friendly and developer-friendly environment.
- The Elasticsearch community is extremely active and is constantly working to guarantee that Elasticsearch is compatible with everything.
Architecture of Elasticsearch:
Elasticsearch is not primarily a data store. But, technically, we can turn it into data storage. Elasticsearch saves documents and versions of documents. If two processes begin writing to a document at the same time, the more recent version is retained. It lacks database-like ACID (Atomicity, Consistency, Isolation, and Durability) features.
Nodes and Clusters:
Elasticsearch is defined as a single instance of Node. It typically runs one instance for each machine. Clusters are defined as groups of nodes that communicate with one another in order to read and write to an index. To prevent extraneous nodes from joining the cluster, the cluster must have a unique name. The entire cluster is managed by a master node. The master node is in charge of any cluster changes, such as adding or removing nodes, creating or deleting indices, and so on. Each cluster and node is given a distinct name.
Documents and Indices:
The document is the only data item we store in the cluster. In this context, a document is a JSON object that can be compared to rows in database terminology. For example, if you wish to store a student, you will create one object with the values name and standard. We know that data will be distributed among all nodes, but do we know how to organize it? Indexes are used to store these records. The index is described as a collection of documents that share comparable characteristics or are logically related. For example, an index for data on orders, items, and customers.
Shards and replicas:
Elasticsearch makes use of Lucene technology to speed up data retrieval. It makes advantage of the Lucene index in a distributed system to obtain data quickly. Individual instances of the Lucene index are referred to as shards. Index performance slows as data amount rises. Elasticsearch employs shards to partition indexes and numerous parts to overcome this. Shards are significant for the following two reasons.
Advantages of Elasticsearch
Elasticsearch has the following advantages:
- Elasticsearch is based on Lucene, a powerful information retrieval library. As a result, it has the most powerful and efficient full-text search capabilities of any open source application. It will be fantastic because coders are well aware of it.
- Faceted search, customizable stemming, customized breaking text into words, and other functions have been incorporated by Elasticsearch.
- Elasticsearch can perform fuzzy searches. Despite the fact that there are spelling errors in the search text.
- Elasticsearch includes the IntelliSense function, which predicts your search based on your search history or completes your text with existing tags. Consider Google search.
- Because Elasticsearch is API-driven, any operation may be carried out through a RESTful API.
- Elasticsearch records any data changes in transaction loss, lowering the chance of data loss.
- Because Elasticsearch is distributed, it is simple to scale and incorporate into any enterprise.
- Elasticsearch enables faceted search, which is similar to applying many filters to data and then applying a classification system to it. This search is more robust than a standard text search.
- As a huge Elasticsearch index, Elasticsearch implements multi-tenancy better.
- It is relatively simple to build complex queries and precisely tune them using the Elasticsearch query DSL. Furthermore, query DSL allows you to rank and group the results.
Elasticsearch Applications
Here are a few Elasticsearch use-cases:
- An online business that allows customers to browse all of the things it sells. In this situation, Elasticsearch can be used to store the entire product inventory and catalog. Users can also search and use the autocomplete feature.
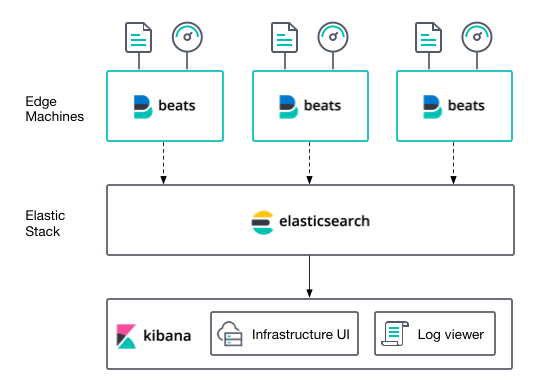
- Consider a case in which you need to retain a log or transactions in order to examine trends, summaries, anomalies, or statistics. In this situation, Logstash, a component of the ELK Stack (Elasticsearch/Logstash/Kibana), can be used to store and parse your data. Logstash makes it possible to feed data into Elasticsearch.
- Have you seen the “Notify me if an item becomes available” or “Notify me if the price of this item reduces” buttons on e-commerce sites? Elasticsearch can be used to implement this feature. You can use Elasticsearch to reverse-search and monitor price or stock changes, sending alerts to customers once conditions are met.
- Consider the situation in which you need to swiftly examine and visualize data. Kibana works best with Elasticsearch in this case. Kibana can see data stored in Elasticsearch in a variety of bespoke dashboards. Kibana is a component of the ELK Stack (Elasticsearch, Logstash, Kibana).
Elasticsearch Vs. RDBMS
Elasticsearch is a database that does not use SQL. It lacks joins, relations, limitations, and transactional behavior. When compared to RDBMS, Elasticsearch is easier to grow. To learn more, consider how Elasticsearch differs from RDBMS.
| Elasticsearch | RDBMS |
|---|---|
| Semi-structured or unorganized data | Structured and organized data |
| Eventual Consistency | Tight Consistency |
| BASE transactions | ACID transactions |
| No Predefined Schema | Data and relationships stored in tables. |
| Index | Database |
| Shard | Partition |
| Type | Table |
| Document | Row |
| Field | Column |
| Mapping | Schema |
| Everything is indexed | Index |
| Query DSL | SQL |
Elasticsearch’s Current and Future Demand:
Elasticsearch is the most widely used search engine that is open source, distributed, cross-platform, and scalable. Since 2010, Elasticsearch has grown at an exponential rate, leaving a lasting influence on the IT sector. Elasticsearch capabilities are in high demand due to the company’s exponential growth. IT experts who are familiar with Elasticsearch are paid more and regarded more. It is popular in the IT industry because of its ability to manage enormous amounts of data and do faster searches.
Conclusion:
Elasticsearch distinguishes itself from its competitors by being highly scalable and widely dispersed. If you have a vast amount of data and want to perform a faster search, there is nothing better than Elasticsearch.