
- Using Firebase to Persist Data Tutorial | Complete Guide [STEP-IN]
- MongoDB and Node.js Tutorial | Create Database
- What Are the Benefits of Using MongoDB Tutorial | A Concise Tutorial Just An Hour
- PL/SQL Tutorial : Learn PL/SQL in 7 Days
- PostgreSQL Tutorial
- How to Download and Install SQL Server?
- Date Functions In SQL Server And MySQL Tutorial
- SQL Server Tutorial
- SQL Applications Tutorial
- Full Join in SQL
- SQL Command Cheat Sheet
- Data Modelling
- Order By and Group By in SQL Tutorial
- Apache Cassandra Interfaces Tutorial
- mysql workbench tutorial
- Apache Cassandra Architecture Tutorial
- NoSQL Database Tutorial
- Data Manipulation in SQL Tutorial
- SQL Server Reporting Services (SSRS) Tutorial
- Using Firebase to Persist Data Tutorial | Complete Guide [STEP-IN]
- MongoDB and Node.js Tutorial | Create Database
- What Are the Benefits of Using MongoDB Tutorial | A Concise Tutorial Just An Hour
- PL/SQL Tutorial : Learn PL/SQL in 7 Days
- PostgreSQL Tutorial
- How to Download and Install SQL Server?
- Date Functions In SQL Server And MySQL Tutorial
- SQL Server Tutorial
- SQL Applications Tutorial
- Full Join in SQL
- SQL Command Cheat Sheet
- Data Modelling
- Order By and Group By in SQL Tutorial
- Apache Cassandra Interfaces Tutorial
- mysql workbench tutorial
- Apache Cassandra Architecture Tutorial
- NoSQL Database Tutorial
- Data Manipulation in SQL Tutorial
- SQL Server Reporting Services (SSRS) Tutorial

Apache Cassandra Architecture Tutorial
Last updated on 26th Sep 2020, Blog, Database, Tutorials
Cassandra is a distributed database from Apache that is highly scalable and designed to manage very large amounts of structured data. It provides high availability with no single point of failure.
The tutorial starts off with a basic introduction of Cassandra followed by its architecture, installation, and important classes and interfaces. Thereafter, it proceeds to cover how to perform operations such as create, alter, update, and delete on keyspaces, tables, and indexes using CQLSH as well as Java API. The tutorial also has dedicated chapters to explain the data types and collections available in CQL and how to make use of user-defined data types.
Components of Cassandra
The key components of Cassandra are as follows −
- Node − It is the place where data is stored.
- Data center − It is a collection of related nodes.
- Cluster − A cluster is a component that contains one or more data centers.
- Commit log − The commit log is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log.
- Mem-table − A mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.
- SSTable − It is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value.
- Bloom filter − These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
Cassandra Architecture
Some of the features of Cassandra architecture are as follows:
- Cassandra is designed such that it has no master or slave nodes.
- It has a ring-type architecture, that is, its nodes are logically distributed like a ring.
- Data is automatically distributed across all the nodes.
- Similar to HDFS, data is replicated across the nodes for redundancy.
- Data is kept in memory and lazily written to the disk.
- Hash values of the keys are used to distribute the data among nodes in the cluster.
A hash value is a number that maps any given key to a numeric value.
For example, the string ‘ABC’ may be mapped to 101, and decimal number 25.34 may be mapped to 257. A hash value is generated using an algorithm so that the same value of the key always gives the same hash value. In a ring architecture, each node is assigned a token value, as shown in the image below:
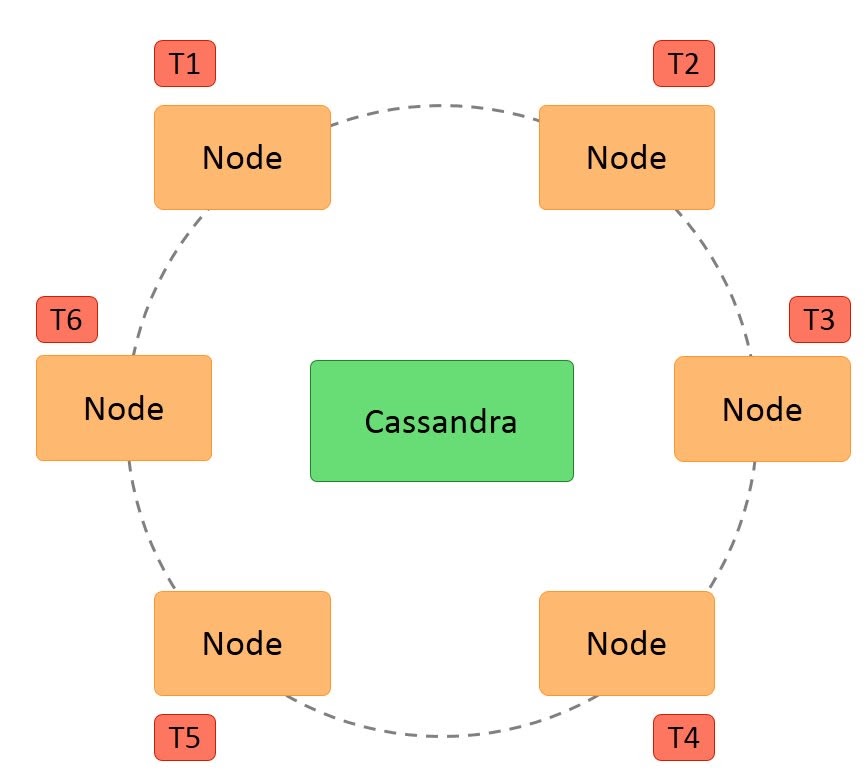
Additional features of Cassandra architecture are:
- Cassandra architecture supports multiple data centers.
- Data can be replicated across data centers.
You can keep three copies of data in one data center and the fourth copy in a remote data center for remote backup. Data reads prefer a local data center to a remote data center.
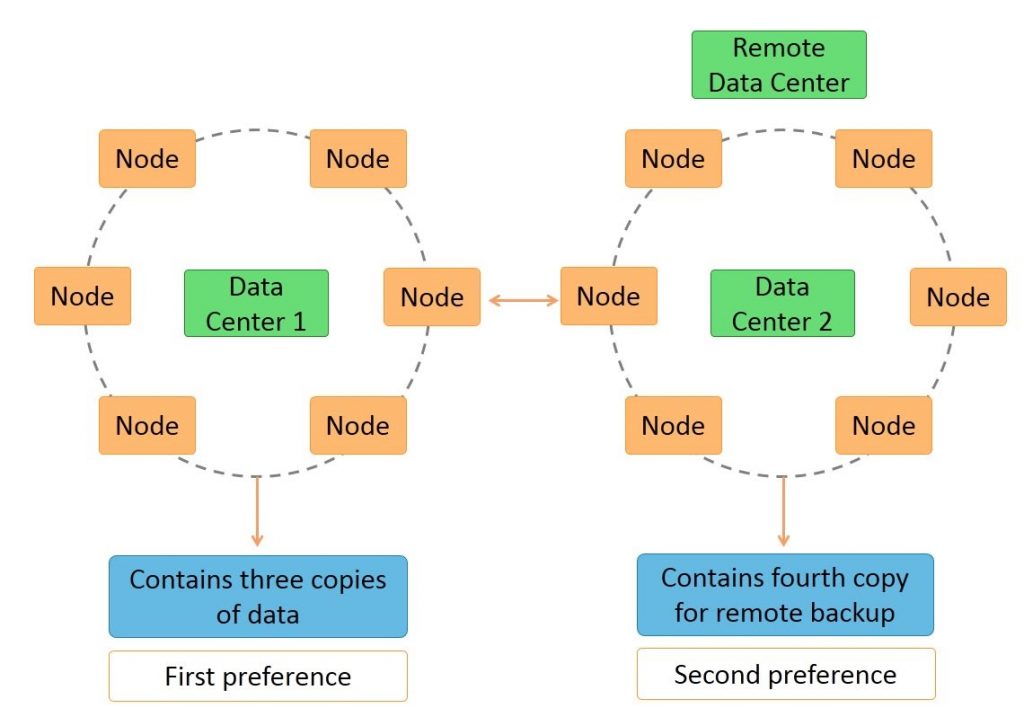
Let us discuss the effects of the architecture in the next section.
Effects of the Architecture
Cassandra architecture enables transparent distribution of data to nodes. This means you can determine the location of your data in the cluster based on the data.
Any node can accept any request as there are no masters or slaves. If a node has the data, it will return the data. Else, it will send the request to the node that has the data.
You can specify the number of replicas of the data to achieve the required level of redundancy. For example, if the data is very critical, you may want to specify a replication factor of 4 or 5.
If the data is not critical, you may specify just two.
It also provides tunable consistency, that is, the level of consistency can be specified as a trade-off with performance. Transactions are always written to a commitlog on disk so that they are durable.
Let us discuss Cassandra’s writing process in the next section.
Subscribe For Free Demo
Error: Contact form not found.
Cassandra Write Process
The Cassandra write process ensures fast writes.
Steps in the Cassandra write process are:
- Data is written to a commitlog on disk.
- The data is sent to a responsible node based on the hash value.
- Nodes write data to an in-memory table called memtable.
- From the memtable, data is written to an sstable in memory. Sstable stands for Sorted String table. This has a consolidated data of all the updates to the table.
- From the sstable, data is updated to the actual table.
- If the responsible node is down, data will be written to another node identified as tempnode. The tempnode will hold the data temporarily till the responsible node comes alive.
The diagram below depicts the write process when data is written to table A.
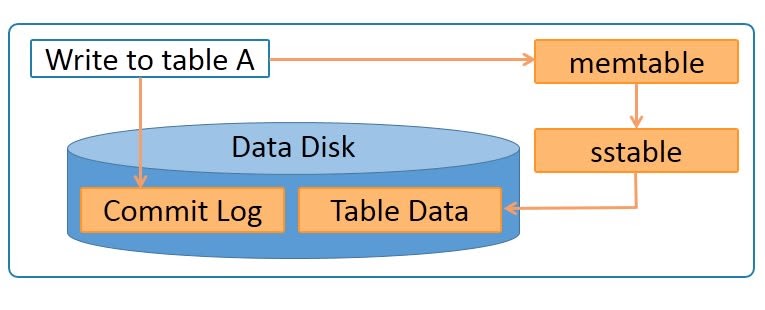
Data is written to a commitlog on disk for persistence. It is also written to an in-memory memtable. Memtable data is written to sstable which is used to update the actual table.
Let us understand what rack is, in the next section.
Rack
The term ‘rack’ is usually used when explaining network topology. A rack is a group of machines housed in the same physical box. Each machine in the rack has its own CPU, memory, and hard disk. However, the rack has no CPU, memory, or hard disk of its own.
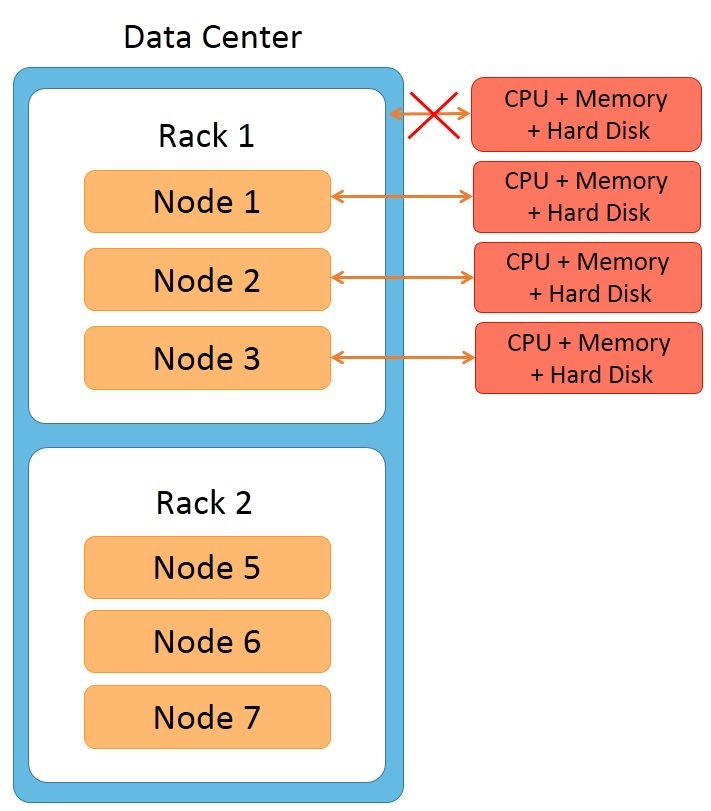
Features of racks are:
- All machines in the rack are connected to the network switch of the rack
- The rack’s network switch is connected to the cluster.
- All machines on the rack have a common power supply. It is important to notice that a rack can fail due to two reasons: a network switch failure or a power supply failure.
- If a rack fails, none of the machines on the rack can be accessed. So it would seem as though all the nodes on the rack are down.
Let us learn about Cassandra read process in the next section.
Cassandra Read Process
The Cassandra read process ensures fast reads. Read happens across all nodes in parallel. If a node is down, data is read from the replica of the data. Priority for the replica is assigned on the basis of distance.
Features of the Cassandra read process are:
- Data on the same node is given first preference and is considered data local.
- Data on the same rack is given second preference and is considered rack local.
- Data on the same data center is given third preference and is considered data center local.
- Data in a different data center is given the least preference.
Data in the memtable and sstable is checked first so that the data can be retrieved faster if it is already in memory.
The diagram below represents a Cassandra cluster.
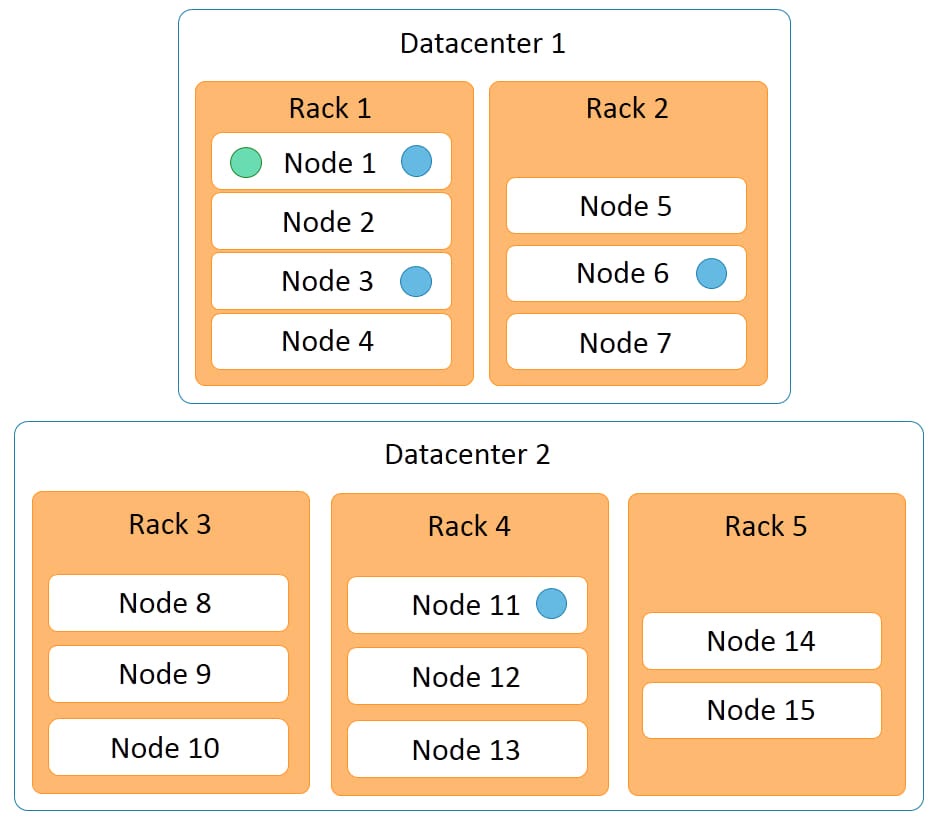
It has two data centers:
- data center 1
- data center 2
Data center 1 has two racks, while data center 2 has three racks. Fifteen nodes are distributed across this cluster with nodes 1 to 4 on rack 1, nodes 5 to 7 on rack 2, and so on.
Example of Cassandra Read Process
The Cassandra read process is illustrated with an example below.
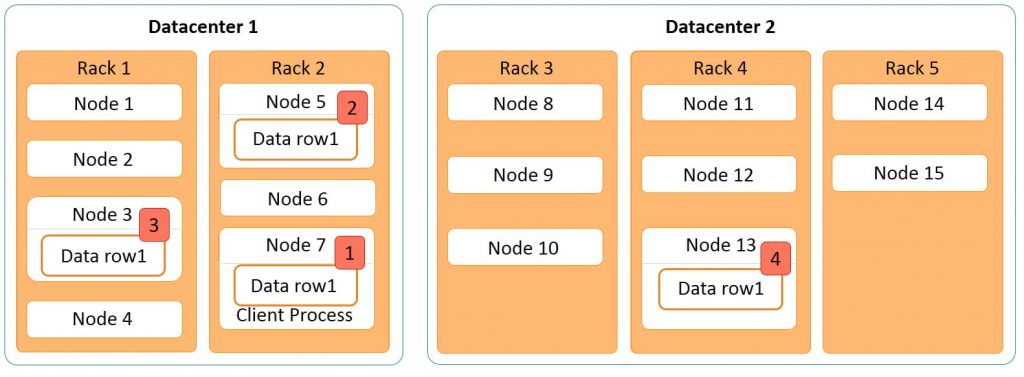
The diagram below explains the Cassandra read process in a cluster with two data centers, five racks, and 15 nodes. In the image, place data row1 in this cluster. Data row1 is a row of data with four replicas.
The first copy is stored on node 3;
The second copy is stored on node 5
The third copy is stored on node 7.
All these nodes are in data center
- 1. The fourth copy is stored on node 13 of data center
- 2. If a client process is running on data node 7 wants to access data row1; node 7 will be given the highest preference as the data is local here. The next preference is for node 5 where the data is rack local.
The next preference is for node
- 3. where the data is on a different rack but within the same data center. The least preference is given to node 13 that is in a different data center. So the read process preference in this example is node 7, node 5, node 3, and node 13 in that order.
Let us focus on Data Partitions in the next section.
Data Partitions
Cassandra performs transparent distribution of data by horizontally partitioning the data in the following manner:
- A hash value is calculated based on the primary key of the data.
- The hash value of the key is mapped to a node in the cluster
- The first copy of the data is stored on that node.
- The distribution is transparent as you can both calculate the hash value and determine where a particular row will be stored.
The following diagram depicts a four node cluster with token values of 0, 25, 50 and 75.
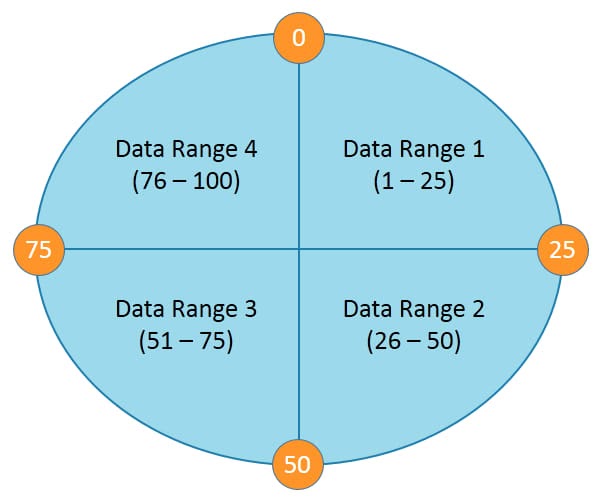
For a given key, a hash value is generated in the range of 1 to 100.
Keys with hash values in the range 1 to 25 are stored on the first node, 26 to 50 are stored on the second node, 51 to 75 are stored on the third node, and 76 to 100 are stored on the fourth node.
Please note that actual tokens and hash values in Cassandra are 127-bit positive integers.
Let us discuss replication in Cassandra in the next section.
Replication in Cassandra
Replication refers to the number of replicas that are maintained for each row. Replication provides redundancy of data for fault tolerance. A replication factor of 3 means that 3 copies of data are maintained in the system.
In this case, even if 2 machines are down, you can access your data from the third copy. The default replication factor is 1. A replication factor of 1 means that a single copy of the data is maintained, so if the node that has the data fails, you will lose the data.
Cassandra allows replication based on nodes, racks, and data centers, unlike HDFS that allows replication based on only nodes and racks. Replication across data centers guarantees data availability even when a data center is down.