
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Kafka Tutorial : Learn Kafka Configuration
Last updated on 06th Aug 2022, Big Data, Blog, Tutorials
What is kafka configuration?
It represents how the Kafka tool runs within JAAS configuration.
These are some security rules and regulations used while interchange words with the servers. It denotes the size of the memory buffer which will handle information to be sent to the producer.
Kafka Configuration Types
Kafka creates its configuration. It can be distributed from a file or programmatically.It’s taken from a default file and can be self-programmed. Some configurations have both a default global setting and Topic-level overrides.
- i)Broker configuration.
- ii)Producer configuration.
- iii) Consumer configuration.
- iv)Kafka Connect configuration.
i) Broker configuration
The important configurations are:
| Property | Description |
|---|---|
| broker.id | It is a list of directories arranged properly separated by commas and every partition is placed in a directory having a small number of partitions. |
| log.dirs | It stores the log and is used when it is 0. |
| zookeeper.connect | ZK leader and follower distance |
ii)Producer configuration.
It provides parameters accessible for Confluent Platform.The Apache Kafka® producer configuration parameters are arranged by order of importance, graded from high to low.
It is the source of the information stream and, In Kafka Cluster it writes tokens or messages to one or more topics.There are actually piles of Franz Kafka Producer Configurations within the scheme .It can help to bring Kafka Producer to the next stage. But I started with Kafka Producer Configurations.
Key Features of Kafka:
Fault-Tolerant: clusters maintain the organization info as safe and secure in distributed and durable clusters. Kafka is exceptionally reliable and allows us to generate new custom connections as per our needs.
Scalability: Kafka can readily handle large volumes of data streams and trillions of messages per day. Kafka’s high scalability permits organizations to simply scale production clusters up to a thousand brokers.
High Availability: Kafka is super fast and ensures zero downtime making sure data is available at any time. Kafka replicates information across multiple clusters efficiently without any loss.
Integrations: Kafka comes with a set of connectors that simplify moving data inside and outside of Kafka. Kafka Connect allows Developers to easily connect to hundreds of event sources and sinks .
Ease of Use: Kafka is a user-friendly platform that doesn’t require extensive programming knowledge to get started. Kafka has extensive resources in terms of documentation, By using Kafka CLI, tutorials, videos, projects, etc, to help Developers learn and develop applications.
iii). Consumer configuration
The Important consumer configurations:
| group.id | All the processes belonging to similar consumer processes are connected to a singular group and given an identity. If the id is set, it means all the processes belong to the same group. |
| zookeeper.connect | It is the Zookeeper connector using both hosts and ports of variety Zookeepers. This connection includes a chroot path which keeps the data under another path. The same chroot path is used by both consumer and producer. To use a chroot path, the string will be as hostname1:port1,hostname2:port2 /chroot/path |
The producer configuration takes care of compression, synchronous and asynchronous configuration and also batching sizes. And the Consumer configuration takes care of the winning sizes.
iv)Kafka Connect configuration.
Kafka Connect is a free, open-source component of Apache Kafka® that works as a centralized data hub for simple data integration between key-value stores, databases , file systems and search indexes.
The data page is specific to Kafka Connect for Confluent Platform.
Kafka Connect provides the subsequent benefits:
Data-centric pipeline: Connect uses meaningful data abstractions to pull or push data to Kafka.
Flexibility and scalability: Connect runs with streaming and batch-oriented systems on a one node scaled to an organization-wide service
Reusability and extensibility: Connect leverages existing connectors or extends them need to fit and provides lower time to production. It is targeted on streaming data to and from Kafka,Making it simpler to write high quality, reliable, and high performance connector plugins. It conjointly allows the framework to form guarantees that square measure troublesome to attain victimization alternative frameworks.. It’s AN integral part of AN ETL pipeline, once combined with Kafka and a stream process framework.
How Kafka Connect Works
It can deploy Kafka Connect as a standalone process that runs jobs on a even one machine (for example, log collection), As supplied, scalable, fault-tolerant service supporting an entire organization. Kafka Connect provides a coffee barrier to entry and low operational overhead. It can start small with a standalone environment for creating and testing,
Then scale up to a full production environment to guide the data pipeline of a big organization.
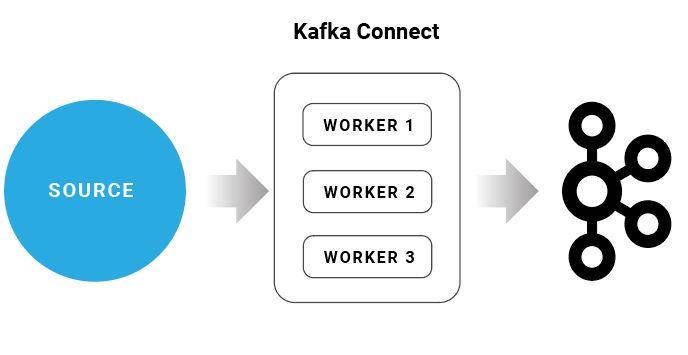
Kafka Connect includes two types of connectors:
- Source connector
- Sink connector
It ingest entire databases and stream table updates to Kafka topics.
Source connectors can also gather metrics from all application servers .
keep the data in Kafka topics–making the data available for stream processing with low latency.
Sink connector:Sink connectors deliver data from Kafka topics to secondary indexes,
such as Elasticsearch, or batch systems like Hadoop for offline analysis.
Conclusion:
It totally depends on correctly occurring data delivery.
The delivery of every message to its consumer correctly, on time without late.
The message delivery has to be done at a correct time and if not received within that particular time, alerts start to raise.