
- Prometheus Tutorial: A Detailed Guide to Getting Started
- Getting Started with TeamCity Tutorial | Learn in 1 Day with Ease
- Getting Started with TeamCity Tutorial | Learn in 1 Day with Ease
- Azure DevOps Tutorial
- Jenkins Cheat Sheet
- Chef Cheat Sheet Tutorial
- Docker Container Tutorial
- Jenkins Tutorial
- Puppet Tutorial
- DevOps Tutorial
- Prometheus Tutorial: A Detailed Guide to Getting Started
- Getting Started with TeamCity Tutorial | Learn in 1 Day with Ease
- Getting Started with TeamCity Tutorial | Learn in 1 Day with Ease
- Azure DevOps Tutorial
- Jenkins Cheat Sheet
- Chef Cheat Sheet Tutorial
- Docker Container Tutorial
- Jenkins Tutorial
- Puppet Tutorial
- DevOps Tutorial

Prometheus Tutorial: A Detailed Guide to Getting Started
Last updated on 11th Aug 2022, Blog, DevOps, Tutorials
What Is Prometheus?
Prometheus is that the hottest observance answer for Kubernetes. It’s the second project to be launched by the Cloud Native Computing Foundation, that is that the same organization answerable for Kubernetes. Prometheus takes full advantage of the strengths offered from a cloud-native setup. It monitors many metrics on Kubernetes and stores them as a time/date series. So, information are often simply searched, scanned, and retrieved.Prometheus collects information at pre-set intervals. It can even send alerts once sure thresholds area unit crossed.
It has libraries for a large berth of various programming languages.These include:
- Go
- Ruby
- Java
- Python
Architecture
While knowing however Prometheus works might not be essential to victimisation it effectively, it are often useful, particularly if you are considering victimisation it for production. The Prometheus documentation provides this graphic and details regarding the essential parts of Prometheus and the way the items connect along.
For most use cases, you ought to perceive 3 major parts of Prometheus:
1.The Prometheus server scrapes and stores metrics. Note that it uses a persistence layer, that is a component of the server and not expressly mentioned within the documentation. every node of the server is autonomous and doesn’t trust distributed storage. i will come back this later once wanting to use an ardent time-series info to store Prometheus information, instead of looking forward to the server itself.
2.The online UI permits you to access, visualize, and chart the hold on information. Prometheus provides its own UI, however you’ll additionally set up different mental image tools, like Grafana, to access the Prometheus server victimisation PromQL (the Prometheus question Language).
3.Alertmanager sends alerts from shopper applications, particularly the Prometheus server. it’s advanced options for deduplicating, grouping, and routing alerts and might route through different services like PagerDuty and OpsGenie.
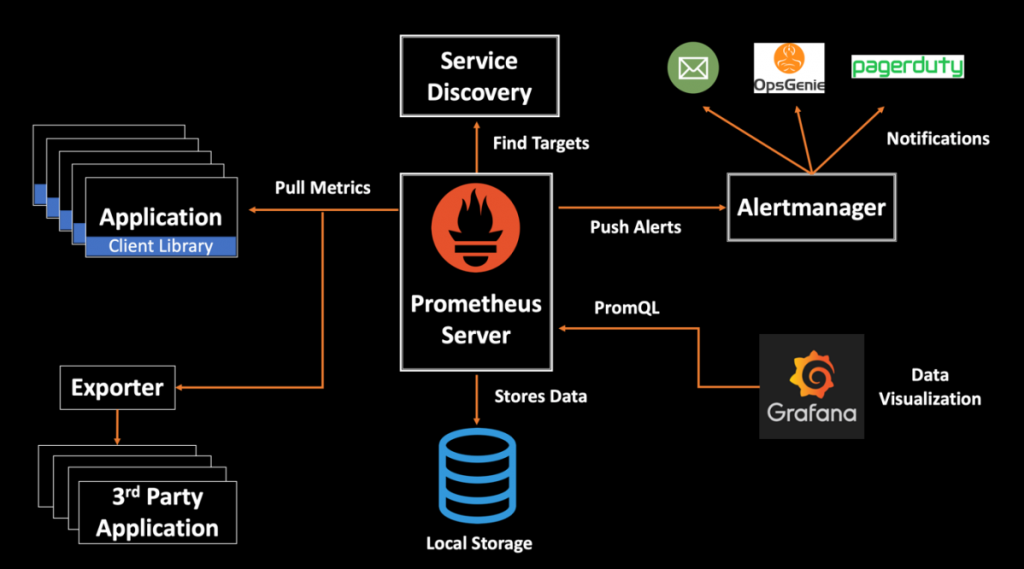
Working of Prometheus
Prometheus will run in Go and dockhand applications. The observance code are often outlined because the time-series info at the side of the UI (User Interface) and versatile, refined command language referred to as PromQL.Prometheus assembles metrics through instrumented jobs. The samples are often hold on domestically. Also, it are often scanned via rules to either record or collect any new time-series through existing information and build style alerts. These metrics square measure shown via method of histograms, gauges, and counters. information are often transmitted via hypertext transfer protocol with plaintext.
Features of Prometheus
Some primary aspects of Prometheus square measure mentioned as follows:
- Several dashboards and graphing modes support.
- Representation of your time series assemblage from any pull model on hypertext transfer protocol.
- Multidimensional information model presenting statistic information, i.e., recognized with the name of the metric or with KVP (Key-value pairs).
- Capability to use PromQL for supporting the multidimensionality feature of a knowledge model.
- Zero reliance over distributed storage and autonomous individual server nodes.
- Target discovery from service discovery or static configuration.
- Capability to manage statistic from any mediator entrance.
Prometheus Exporters:
For every major DevOps tool on the market or rising from Open supply, there’s a particular bourgeois to maneuver metrics into promenade. the foremost vital of those is that the Node_Exporter, to export system metrics. the complete list of Titan exporters is long, however some essential examples include:
Available exporters
Databases:Diplomatist, CouchDB, Elasticsearch, MongoDB (and MongoDB question exporter), MySQL, OpenTSDB, PostgreSQL, ProxySQL, Graphite, InfluxDB, and Hadoop.
Message brokers/queues: Redis, Kafka, RabbitMQ (and RabbitMQ Management Plugin exporter), Nagios / Naemon
Workspaces:Confluence and JIRA
Servers: Apache, HAProxy, and Nginx (metric library and VTS exporter)
Cloud suppliers and their APIs: AWS ECS, AWS Health, AWS SQS, AWS CloudWatch, Azure Health, Azure Monitor, Google Stackdriver, DigitalOcean, Alibaba Cloudmonitor, Akamai Cloudmonitor
Logging-relevant exporters: Fluentd, Grok, JSON bourgeois, and Kibana
Alternatively, developers may prefer to instrument code for Titan metric varieties. Titan maintains four official consumer libraries for the subsequent languages: Go, Java / Scala, Python, and Ruby. however additionally, Titan users have created libs for the subsequent languages:
Bash, C, C++, Common Lisp, Dart, Elixir, Erlang, Haskell, Lua for Nginx and Lua for Tarantool, .NET / C#, Node.js, Perl, PHP, R, Rust.
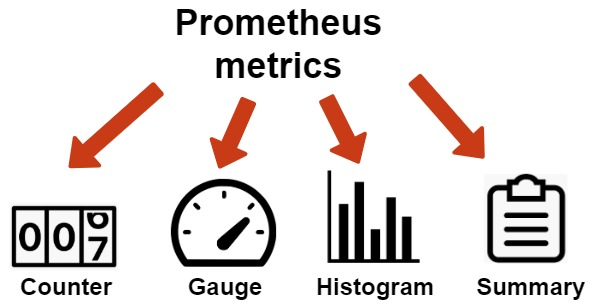
Prometheus Metric varieties
The shopper libraries of Prometheus supply four core kinds of metrics. However, the Prometheus server doesn’t presently save these metrics as completely different information varieties. Instead, it flattens all info into associate degree untyped statistic.
Counter:
This is a accumulative metric. It represents one monotonically-increasing counter, and its worth will either increase or be reset to zero on restart.There square measure many use cases that suit counter metrics. You can, for instance, use it to represent the amount of served requests, errors, or completed tasks. you must ne’er use counters to show values which will decrease, just like the range of running processes.
Gauge:
This metric represents one numerical worth, which may every which way go down and up. A gauge is commonly wont to live values like current memory usage or temperatures.
Histogram:
A bar graph samples observations, like request durations or response sizes. It then counts the observations in a very configurable bucket. A bar graph may offer a complete total of all the ascertained values.
Use of Prometheus
Service Metrics:
Prometheus is usually wont to collect numeric metrics from services that run 24/7 and permit metric information to be accessed via communications protocol endpoints. this will be done manually or with numerous shopper libraries. Prometheus exposes information employing a easy format, with a replacement line for every metric, separated with printing operation characters.The file is revealed on associate degree communications protocol server that Prometheus will question and scrape metrics from supported the required path, port, and hostname.Prometheus may be used for distributed services, that square measure run on multiple hosts. every instance publishes its own metrics and incorporates a name that Prometheus will distinguish.
Host Metrics:
You can monitor the package to spot once a server’s disc is full or if a server operates perpetually at 100% electronic equipment. you’ll be able to install a special bourgeois on the host to gather the package info associate degreed publish it to an HTTP-reachable location.
Website Uptime/Up standing:
Prometheus doesn’t sometimes monitor web site standing, however you’ll be able to use a blackbox bourgeois to modify this. You specify the target URL to question associate degree end, associate degreed perform an period check to receive info like the website’s latency. You outline the hosts to be queried within the Prometheus.yml configuration file, exploitation relabel_configs to confirm Prometheus uses the blackbox bourgeois.
Cronjobs:
To check if a cronjob is running at the required intervals, you’ll be able to use the Push entrance to show metrics to Prometheus through associate degree communications protocol end. you’ll be able to push the timestamp of the last productive job (i.e. a backup job) to the entrance, and compare it with the present time in Prometheus. If the time exceeds the required threshold, the monitor times out associate degreed triggers an alert.
Prometheus benefits:
1.Provides service discovery that’s greatly integrated with Kubernetes, finding all services, and actuation metrics from Prometheus endpoints.
2.Prometheus continually works, even though alternative components of the infrastructure square measure broken. No have to be compelled to install agents – your Prometheus installation will already pull metrics.
3.No in depth established required.
4.Permits quick outage discovery. Outages may be terribly quickly discovered once the system fails to urge requests from well-known watching sources.
5.Provides a purposeful source language, PromQL, that enables US to pick and mixture time-series information in time period. It will apply subqueries, functions, and operators. It will filter and cluster by labels, and use regular expressions for improved matching and filtering.
.Ensures easy reconfiguration. Configuration may be modified via the program line. for instance, immutable system parameters, like storage locations or computer’s disk and in memory (a fast example: the quantity of information to stay on your Mac), and configuration files, like jobs, instances, or that rule file to load. dynamical configuration mechanically applies to all or any watching services.
7.The load Prometheus places on monitored services and also the network is low since metrics square measure hold on in memory as they’re generated, and born-again to a decipherable format, and Prometheus receives them by request (every fifteen seconds by default), despite what percentage events square measure being generated.
8.The Prometheus design style system provides operational simplicity.
What makes Prometheus such an important component of this whole infrastructure?
The complexity of modern-day DevOps is only expected to increase over time. DevOps has also made it more difficult to manually handle and monitor operations, which adds another layer of complexity. Because of this, there is a significant demand for automation in today’s market to compete. Multiple servers, each of which operates as a containerized application are contained within the Prometheus system.In addition to that, Prometheus is comprised of hundreds of one-of-a-kind processes that are distributed throughout an infrastructure. Because everything is related to everything else, it is becoming increasingly vital to keep a configuration that ensures smooth operating operations without relying on application downtimes. This is because everything is entirely integrated.
Take for instance the fact that you own a highly intricate and entangled infrastructure that consists of a number of servers dispersed across a number of different places. The infrastructure does not provide complete visibility into what is happening in terms of the hardware or even the applications themselves, such as faults, response slowness, hardware failure, or overcrowded resources caused by the concurrent use of other resources. When dealing with complex infrastructures, there is always the potential that things will go horribly wrong in general.
A significant number of companies have an excessively large number of services and applications. In addition to this, the risk of crashing and failing in other services that are concurrently running is increased. Users are immediately unable to use the application after a sudden change. Trying to correctly identify the wrong items can get extremely tiresome. The process of manually debugging the system and locating the source of the issue can take a significant amount of time.What would happen if one of your servers ran out of memory and a container that synchronises data between two or more databases suddenly ceased running?
What course of action would you take if faced with such complications?In this scenario, the two database pots will invariably stop working since the database, which provides the authentication service at the core of all operations, will eventually become inoperable. The application that authenticates users on a day-to-day basis was unable to execute for some reason as well. These activities take place in the background, which is essentially the reverse of what the users see when they interact with the system. An error message that indicates there is a problem with the user interface will appear to users. Users are kept in the dark regarding the sequence of activities that are going place within the cluster.The mistake is the only thing that appears on their screen.
As soon as they notice a mistake, they immediately begin working their way backward to determine the root cause before applying a cure. When it comes to recognising problems and finding solutions to them, it is far simpler to say than to do. Users will investigate whether the programme is once again functioning, whether the authentication service is adequate, and the reasons behind its crashing. In the end, after thorough inspection, they will get to the source of the problem, which is the failed container. It is possible that you will not have any insight into how to fix the problem if you do not follow these processes. Now, this is where the heroic figure of Prometheus comes into play, clad in his golden armour.
An ongoing monitoring programme known as Prometheus checks to confirm that all of the services are functioning appropriately. Additionally, it notifies the people in charge of maintenance the minute even a single turn in the cluster crashes. People are able to have a deeper understanding of what happened in the cluster thanks to the insightful tool known as Prometheus. At other times, the issues are recognised far in advance of their manifestation. Maintainers won’t need to spend a significant lot of effort identifying, evaluating, and fixing the underlying issues that occur in a container cluster.In this scenario, Prometheus will continue to monitor the amount of memory being used and will send an alert to both the maintainer and the administrator. The real-time tool performs measurements until either fifty or sixty percent of available memory has been utilised.
Prometheus and Grafana Feature Comparison
| Prometheus | Grafana |
|---|---|
| There are a few ways to examine fundamental trends and indicators. | A wide variety of charting and graphing choices for presenting data. |
| It offers a place to keep track of information collected over time. | It lacks its own storage space. |
| Requests that are pulled from HTTP endpoints. | Includes add-ons for connecting to external data stores. |