
- Prometheus Tutorial: A Detailed Guide to Getting Started
- Getting Started with TeamCity Tutorial | Learn in 1 Day with Ease
- Getting Started with TeamCity Tutorial | Learn in 1 Day with Ease
- Azure DevOps Tutorial
- Jenkins Cheat Sheet
- Chef Cheat Sheet Tutorial
- Docker Container Tutorial
- Jenkins Tutorial
- Puppet Tutorial
- DevOps Tutorial
- Prometheus Tutorial: A Detailed Guide to Getting Started
- Getting Started with TeamCity Tutorial | Learn in 1 Day with Ease
- Getting Started with TeamCity Tutorial | Learn in 1 Day with Ease
- Azure DevOps Tutorial
- Jenkins Cheat Sheet
- Chef Cheat Sheet Tutorial
- Docker Container Tutorial
- Jenkins Tutorial
- Puppet Tutorial
- DevOps Tutorial

Puppet Tutorial
Last updated on 19th Sep 2020, Blog, DevOps, Tutorials
Puppet is a configuration management technology to manage the infrastructure on physical or virtual machines. It is an open-source software configuration management tool developed using Ruby which helps in managing complex infrastructure on the fly. This tutorial will help in understanding the building blocks of Puppet and how it works in an infrastructure environment.
Puppet
Puppet is a configuration management tool developed by Puppet Labs in order to automate infrastructure management and configuration. Puppet is a very powerful tool which helps in the concept of Infrastructure as code. This tool is written in Ruby DSL language that helps in converting a complete infrastructure in code format, which can be easily managed and configured.
Puppet follows the client-server model, where one machine in any cluster acts as the server, known as puppet master and the other acts as a client known as a slave on nodes. Puppet has the capability to manage any system from scratch, starting from initial configuration till the end-of-life of any particular machine.
Puppet Overview
- A puppet is an open source software, and it is a configuration management tool.
- Puppet runs on Unix-like, Linux and Windows operating systems.
- Puppet software produced by Puppet (Privately held IT automation software-company located in Portland, Oregon).
- Puppet founded by Luke kanies, in 2005.
- Puppet is written in C++ and Clojure.
- Puppet released as free software under GNU GPL (General public License) until version 2.7.0
- The user describes the system state of the resources and resources, either using puppet’s declarative language or Ruby DSL (domain specific language).
Features of Puppet
There are many Puppet features as follow:
1.Large Installed Base
The puppet used by more than 30,000 companies worldwide including Google, semen’s, and Red Hat, etc. the universities like Harvard law school, Stanford are using Puppet software. Almost 22 new organizations per day use Puppet for the first time.
2. Large Developer Base
Puppet has many contributors to its core source code.
3. Long Commercial Track Record
Puppet has been used commercially, since 2005. Puppet keeps on improving and refining. Puppet has deployed in an extensive infrastructure (machines 5000+), scalability and performance lessons learned from such projects and applied to puppet by the Puppet developers.
4. Documentation
Puppet has a website with hundreds of pages of documentation maintained by the community of users, adding content and modifying it is allowed to the user who is part of that community. (Website) It also contains comprehensive references for both languages and resource types. Besides, it is easy to find out the solution for your puppet problem because multiple mailing lists are discussed here actively. It has a popular IRC (Internet Relay Chat) channel. IRC is an application layer protocol that provides ‘communication in the form of text.’ Client-server network model used to work the chat process.
5. Platform Support
Puppet runs on that operating system, which supports Ruby. Examples are windows, Linus, CentOS, etc. It runs on new as well as outdated operating systems and runs on Ruby versions too.
To go into the details of Puppet, first understand the concept of configuration management, need of configuration management.
Subscribe For Free Demo
Error: Contact form not found.
Puppet Installation
Puppet works on the client server architecture, wherein we call the server as the Puppet master and the client as the Puppet node. This setup is achieved by installing Puppet on both the client and well as on all the server machines.
For most of the platforms, Puppet can be installed via the package manager of choice. However, for a few platforms it can be done by installing the tarball or RubyGems.
Installing Puppet from the Source
First, install the Puppet tarball from the Puppet site using wget. Then, extract the tarball to a target location. Move inside the created directory using the CD command. Using install.rb file, install Puppet on the underlying server.
- # get the latest tarball
- $ wget http://puppetlabs.com/downloads/puppet/puppet-latest.tgz —–: 1
- # untar and install it
- $ gzip -d -c puppet-latest.tgz | tar xf – —-: 2
- $ cd puppet-* ——: 3
- $ sudo ruby install.rb # or become root and run install.rb ——-: 4
Puppet − Workflow
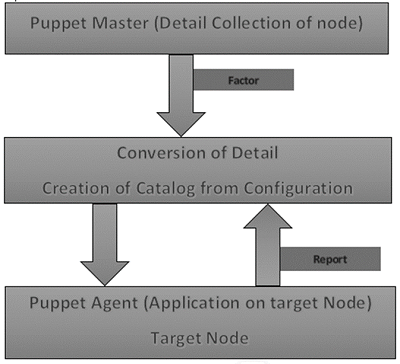
puppet uses the following workflow to apply configuration on the system
- In Puppet, the first thing the Puppet master does is to collect the details of the target machine. Using the factor which is present on all Puppet nodes (similar to Ohai in Chef) it gets all the machine level configuration details. These details are collected and sent back to the Puppet master.
- Then the puppet master compares the retrieved configuration with defined configuration details, and with the defined configuration it creates a catalog and sends it to the targeted Puppet agents.
- The Puppet agent then applies those configurations to get the system into a desired state.
- Finally, once one has the target node in a desired state, it sends a report back to the Puppet master, which helps the Puppet master in understanding where the current state of the system is, as defined in the catalog.
Components of Puppet
Following is the list of puppet components:
- 1.Manifests
- 2.Module
- 3.Resource
- 4.Factor
- 5.M-collective
- 6.Catalogs
Let us understand each component in
1.Manifests
Puppet Master distributes configuration details to every Puppet slave and that configuration details written in Puppet native language. Manifest is nothing but the file describing the configuration details for puppet slave. The extension of the manifest file is .pp (Puppet policy). These files contain puppet programs depicting the configuration for the slave.
Example: Users can write a manifest at puppet master. Master creates a file and installs apache server on every slave, those that are connected to the puppet master.2.Module

Collection of manifests and data forms puppet module. Data can be facts, file or Templates. The module has a specific directory structure. Modules help in organizing puppet code. Modules allow puppet code to split into multiple manifests. Modules are nothing but self-contained bundles of data or code.
3. Resource
Resources are the basic unit of system configuration modeling. Each resource defines some aspect of the system such as a specific service or package.
4. Factor
Factor gathers facts or necessary information about puppet agents such as operating system, IP address, Mac address, hardware details, network settings, SSH keys and many more. These facts present in the manifests of the puppet master, available as a variable.
5. M-collective
M-collective is a framework. This framework allows multiple jobs to run/ execute on various puppet agents in parallel. This framework performs numerous functions as follows
- This framework interacts with a cluster of puppet agents, whether in large groups or small groups.This framework attaches filters with the request.
- This framework uses the broadcast paradigm to send requests to puppet agents. When all agents receive offers at the same time, only those agents start responding to the request whose filters matched with the filters attached to the request.
6. Catalogs
Catalog defines the desired state of each resource on a slave managed by the puppet master. It describes the relationship between resources. It defines compilation for all slaves, which is controlled by the master. The puppet master compiles the catalogs through modules (Manifests + data). Master serves the compiled catalog to the puppet agent on its request.
Puppet architecture
The architecture of Puppet consists of following components
- Puppet Master
- Puppet Agent
- Config Repository
- Facts
- Catalog

Get Advanced Puppet Training from Top-Rated Instructors
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Following is the diagrammatic representation of Puppet architecture.
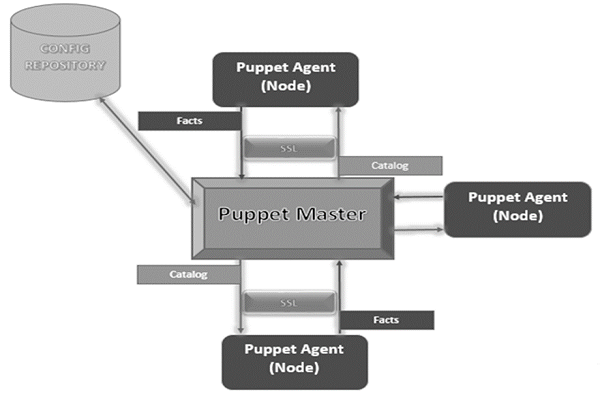
Puppet Master
Puppet Master is the key mechanism which handles all the configuration related stuff. It applies the configuration to nodes using the Puppet agent.
Puppet Agent
Puppet Agents are the actual working machines which are managed by the Puppet master. They have the Puppet agent daemon service running inside them.
Config Repository
This is the repo where all nodes and server-related configurations are saved and pulled when required.
Facts
Facts are the details related to the node or the master machine, which are basically used for analyzing the current status of any node. On the basis of facts, changes are done on any target machine. There are predefined and custom facts in Puppet.
Catalog
All the manifest files or configuration which are written in Puppet are first converted to a compiled format called catalog and later those catalogs are applied on the target machine.
Puppet Configuration Management
So far, we have seen that Puppet is a configuration management tool. Now here we will discuss what is configuration management exactly? Server installation and configuration are a few of the repetitive tasks that have to be performed by the system admin. However, through executable scripts, they can perform these repetitive tasks, but for large infrastructure, it is not possible. Here comes the role of Configuration Management.
Configuration management means to handle the system changes while maintaining its integrity in a timely manner. It is ensured by the configuration management that the current design and build a state of the system are purely tested and good in condition without any intermediary role of developers.
Challenges Handled by Configuration Management
Following challenges are handled by Configuration Management:
- Identification of the component that needs to be changed at the time of requirement changes
- When implementation is changed it is being redone for all nodes
- If required then the previous version is again implemented
- In case of wrong identification of the component that needs to be changed, it is replaced by the right component implementation
Elements of Configuration Management
Configuration Management consists of following elements:
- 1.Configuration Identification
- 2.Change Management
- 3.Configuration Status Accounting
- 4.Configuration Audits
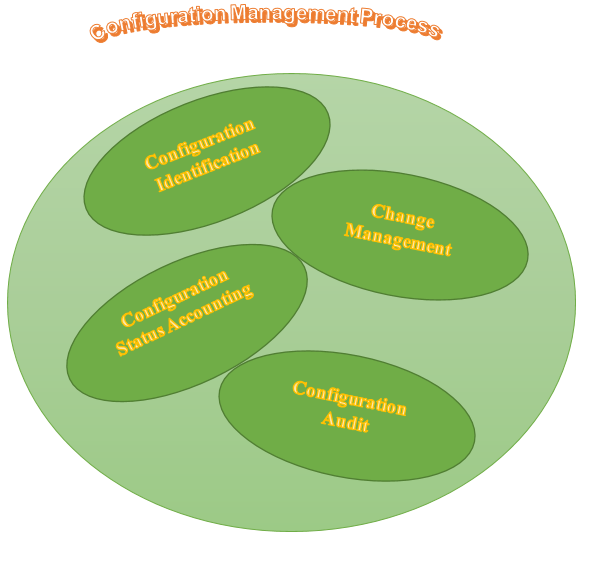
- Configuration Identification: To define product and its configuration documentation. This process involves grouping of related configuration items into a single cluster, labeling of hardware and software configuration items using identifiers and configuration item documentation.
- Change Management: To control product and configuration documentation changes. It is all about dealing with changes either at the individual or organizational level.
- Configuration Audits: To verify the configuration documentation consistency against the product. It helps in determining the current state of the system. It is a process of reviewing the product and its expected behavior as it is supposed that it should behave as promised to the customer. The outcome information of any quality audit and testing is used along with configuration status accounting information and it is done just to ensure that all promised features have been delivered.
- Configuration Status Accounting: To provide the configuration documentation and product status information. To record and report configuration item description and any baseline departure is included and listed here. Here, in such cases, modifications are also done instantly if required.
Installation of Puppet
Go through the following steps to install the Puppet on Linux (Red Hat Enterprise Linux):
Step 1: Enable the Puppet Package Repository
Run the below-given command to enable the Puppet package repository
Step 2: If you wish you can enable the prereleases
Execute the below command to enable the prereleases
- [Puppetlabs-devel]name=Puppet Labs Devel <%= @dist.capitalize -%><%= @version -%> – $basearchbaseurl=https://yum.Puppetlabs.com/<%= @dist.downcase -%>/<%= @codename -%>/devel/$basearchgpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Puppetlabsenabled=1gpgcheck=1
Otherwise, you can disable the prerelease by setting the value 0
Step 3: Update the Puppet master to the latest version by executing the given command
sudo Puppet resource package Puppet-server ensure=latest
You have to restart the Puppet master server after upgrading it.
Step 4: Install the agent nodes on the server
Should run the following command in all the agent nodes of Puppet
sudo yum install Puppet
Step 5: Upgrade with the Puppet agent with the given command
sudo Puppet resource package Puppet ensure=latest
When you complete these processes in a perfect way, Puppet will get installed successfully. The next process is to configure the Puppet based on the following steps.
Configuration of Puppet
Step 1: Create the Puppet Master’s Certificate
Make sure that you have given the main name for Puppet service in your site as the DNS resolves it to the Puppet master. Navigate to ‘main’ section of the Puppet.conf file of master and create the list of comma separated hostname and set the value of DNS names.
dns-alt-names =Puppet,Puppet.example.com,Puppetmaster,Puppetmaster.example.com
Run the following command to generate the Puppet certificate
sudo Puppet master –verbose –no-daemonize
When it displays the Puppet master version press ctrl+C
Step 2: Starting the Puppet master service
Run the below-mentioned command to start and enable the service
systemctl start Puppet Master Systemctl enable Puppet Master
Step 3: Configuring the Puppet’s agent node
Add the Puppet.conf file of agent node in the agent section
server= Puppet.example.com
Step 4: Start the Puppet agent service with the help of the following command
sudo Puppet resource service ensure=running enable=true
Step 5: Generating a certificate request for the Puppet agent node
During the first attempt of the agent nodes, they will ask for the request certificates which must be approved by the admin
First of all, log into the Puppet master and execute the command as shown below
sudo Puppet cert list
Run the below-given command to sign all requests
sudo Puppet cert sign –all
Step 6: Enter the following command to start and enable the Puppet agent
systemctl start Puppet Systemctl enable Puppet
Step 7: Use the following command to verify the correctness of the sign in the certificates
Puppet agent –fingerprint
With the execution of the last command, your Puppet is installed and configured successfully in your system.
Puppet Applications
Puppet is being used by many organizations. Every type and size of the organization is using Puppet. Here, mainly the organizations adopt Puppet for the following listed reasons:
- Consistency and Scalability: To maintain the phenomenal growth of the organization and to fulfill the infrastructure related needs. Earlier script-based solution and manual approaches were not sufficient for the organizations
- Portable Infrastructure: Organizations can use a consistent configuration management approach for their public cloud infrastructure and their data centers.
- Flexibility: To match the right configuration with the right machine Puppet provides flexibility and by using it organizations can remain quite more flexible.
- Infrastructure Insights: Organizations can visualize all machine properties and infrastructure insights can be accessed to maintain the servers.
Conclusion
Puppet is a popular and most used configuration management tool that can be used to manage servers. Master-slave mode of the Puppet is its strength and users prefer it to add extra benefits to the organizations. Regardless of the platform, users can use Puppet with any of the machines and manage the communication between master and slave machines.
Much functionality is provided by the Puppet to manage such communication. With every release, Puppet is getting well-versed with new functions. So far, this is a popular and foremost chosen tool for DevOps professionals. Apart from other technologies, Puppet is mostly used by the organizations.