
- Difference between Data Lake vs Data Warehouse: A Complete Guide For Beginners with Best Practices
- What is Data Mining?| All you need to know [ OverView ]
- What is Data Mining and Data Warehousing?
- Clustering in SSIS | A Definitive Guide with Best Practices [ OverView ]
- What is Data Mart in Data Warehouse? :A Definitive Guide with Best Practices & REAL-TIME Examples
- Accessing Heterogeneous Data In SSIS | Step-By-Step Process with REAL-TIME Examples
- How to Use Java Classes In Talend ? : Step-By-Step Process with REAL-TIME Examples
- What is ODI? ( Oracle Data Integrator ) – A Complete Beginners Guide
- What is Logging in SSIS ( SQL Server Integration Services ) | A Complete Guide with Best Practices
- Applications of Data Mining Free Guide Tutorial & REAL-TIME Examples
- Informatica ETL Tools | Free Guide Tutorial & REAL-TIME Examples
- What Is Data Mining ? – Everything You Need to Know
- What is Amazon Redshift?
- What is Informatica PowerCenter?
- Difference between Data Lake vs Data Warehouse: A Complete Guide For Beginners with Best Practices
- What is Data Mining?| All you need to know [ OverView ]
- What is Data Mining and Data Warehousing?
- Clustering in SSIS | A Definitive Guide with Best Practices [ OverView ]
- What is Data Mart in Data Warehouse? :A Definitive Guide with Best Practices & REAL-TIME Examples
- Accessing Heterogeneous Data In SSIS | Step-By-Step Process with REAL-TIME Examples
- How to Use Java Classes In Talend ? : Step-By-Step Process with REAL-TIME Examples
- What is ODI? ( Oracle Data Integrator ) – A Complete Beginners Guide
- What is Logging in SSIS ( SQL Server Integration Services ) | A Complete Guide with Best Practices
- Applications of Data Mining Free Guide Tutorial & REAL-TIME Examples
- Informatica ETL Tools | Free Guide Tutorial & REAL-TIME Examples
- What Is Data Mining ? – Everything You Need to Know
- What is Amazon Redshift?
- What is Informatica PowerCenter?

What Is Data Mining ? – Everything You Need to Know
Last updated on 28th Oct 2022, Artciles, Blog, Datawarehouse
- In this article you will get
- 1.Introduction to data mining
- 2.Tools for data processing
- 3.Why Orange?
- 4.Scientific libraries
- 5.Characteristics
- 6.Types of data which will be mined
- 7.Data mining process
- 8.Why is it important?
- 9.Data mining applications
- 10.Benefits of data mining
- 11.Conclusion
Introduction to data mining
Data mining is the method of extracting and getting patterns from massive knowledge sets that incorporate ways at the intersections of machine learning, arithmetic, and web site systems. data processing is an element of the subfields of engineering and statistics with the final goal of extracting data (in clever ways) from {a data|a knowledge|and data} set and remodeling information into a comprehensive framework for continuous use. {data mining|data methoding} could be a stepwise analysis of the “on-site knowledge acquisition” process, or KDD. , background analysis of non inheritable properties, display, and renewals on-line.
The term “data mining” could be a name, as a result of the goal is to extract patterns and data, not the extraction (of mines) of the info itself. [6] it’s additionally a bunk [7] and is commonly utilized in any type of huge knowledge or processing (collection, extraction, storage, analysis, and statistics) similarly as any use of pc decision-making systems, together with technical intelligence (e.g., machine learning) and intelligence. of business. the info Mining Handbook: sensible machine learning tools and techniques in Java [8] (which primarily includes machine learning materials) would originally be known as Active Machine Learning, and also the term data processing was solely side-stepped for selling reasons. [9] Common words (large scale) area unit typically knowledge analysis and analysis — or, once concerning real-world, machine-wise and machine learning — area unit terribly acceptable.
The actual operation of knowledge mining is the automatic or automatic analysis of huge amounts of knowledge to extract antecedently unknown, fascinating patterns like knowledge record teams (cluster analysis), unconventional records (confusing discovery), and dependence (organizational excavation, consecutive excavation). This typically involves victimization website methods as native indicators. These patterns could also be seen as a type of outline computer file, and should be utilized in any analysis or, for instance, in machine learning and statement analysis. for instance, {a knowledge|a knowledge|and the information} mining step could establish multiple teams within the data, which might be accustomed to get additional correct predictor results with a choice web. knowledge assortment, processing, or interpretation of results and reportage isn’t a part of the info mining method, however not the whole KDD method as further steps.
Tools for data processing
Data Mining could be a set of methods that use specific algorithms, mathematical analysis, AI, and web-based systems to analyze knowledge from a spread of sizes and views.
Data mining tools aim to search out patterns / trends / teams between massive knowledge sets and convert knowledge into extremely refined data.
It is a framework, similar to Rstudio or Tableau that allows you to perform different types of data mining analysis.
It will perform varied algorithms like merging or dividing your data set and visualizing the results itself. It’s a framework that offers the us of America higher details of our data and thus the standing of the data delineate. Such a framework is known as AN data mining tool.
Orange may be a whole machine learning computer code package organization and mining data. Supports detection and is computer code package supported Python pc-based parts and developed among the bioinformatics laboratory among the college of pc and information science, national capital University, Slovenia.
As it may be a component-based computer code package, parts of Orange area unit area unit are cited as “widgets.” These widgets vary from pre-processing and data show to experimental algorithms and inevitable modeling.
Widgets deliver necessary functions such as:
- Displaying AN data table and allowing selecting choices.
- Data reading.
- Training predictions and examination learning algorithms.
- Data object views, etc..
- Besides, Orange provides a cohesive and fun atmosphere to form the boring analysis tools. It’s terribly fun to work.
Why Orange?
Data up to orange is instantly formatted to the desired pattern, and moving widgets could also be merely transferred once needed. Orange is implausibly attention-grabbing for users. Orange permits its users to form sensible decisions in AN passing short quantities of it slowly by quickly examining and analyzing data.It is a picture of fine open provide data and experiments poignant beginners and professionals. processing could also be through a lucid system or with Python scripting. Most analyses are done via the visual piece of writing interface (drag and drop links and widgets) and lots of visual tools are typically supported like bar charts, scatterplots, trees, dendrograms, and temperature maps. AN oversized kind of widgets (over 100) area unit generally supported.
DMelt may be a multi-forum tool tagged JAVA. it’ll work on any JVM compatible package (Java Virtual Machine). Contains scientific and mathematical libraries.
Scientific libraries
Science libraries area unit conversion in drawing 2D / 3D episodes.
Statistical libraries:
Mathematical libraries are unit conversions in generating random numbers, algorithms, curves, etc. DMelt could also be conversant in analyzing large amounts of data, processing, and applied math analysis. It’s widely utilized in subject fields, cash markets, and engineering.

Characteristics
Data mining analysis was performed on victimization analytical focus structures. Such structures are the distinctive property of the main target half. generally they will be options of a better level than the extent of the main target half. you’ll be able to use a spread of advanced profile options to capture the analytical focus options you wish to include into your data processing analysis. All options result in one column within the output table. completely different|completely different} feature varieties area unit related to different input modification ways in order that the desired analysis focus parts area unit calculated.
Focus attribute:Properties that trust only on one put attentiveness, as an example, store or date, area unit the only as a result of their values are quite the values already contained within the original web site tables.
Consolidation:In general, several buildings area unit the results of merging. every purchase level is simply too smart to be sure, thus multiple purchase options ought to be combined with an inexpensive level of focus. Typically, integration is performed in the least levels of concentration. Within the example of predicting individual store sales, this suggests the ultimate combination with the date.
Combined division:When analyzing stores, particularly their sales performance, it’s customary to incorporate sales that are a part of the departments that are a unit necessary in analysis. you’ll be able to do that by dividing the daily sales worth into sales costs for every department. This is often a standard method of analyzing knowledge in several areas.
Understanding:Some data processing algorithms need part input rather than numeric input. During this case, the information should be processed earlier in order that the values in a specific numerical vary area unit mapped into totally different values.
Value adjustment:Similarly with the division of numerical components you’ll be able to assign new values to get totally different value values.
Calculation:To calculate the feature in some options, any SQL expression is often tested. The calculations are often as easy as adding or separating 2 components, or they are often as complicated because of the drawback needs.
Types of data which will be mined
1. Knowledge hold on on the web site:
Database management system or DBMS. Each DBMS stores connected knowledge in a method or another. It conjointly encompasses a set of code programs accustomed to managing knowledge and supplying quick access to that. These code programs have several functions, as well as process an internet site structure, making certain that archives stay secure and consistent, and managing differing types of information access, like sharing, distribution, and compliance. connected websites have tables with totally different names, attributes, and may store lines or records of enormous knowledge sets. All records held in a table have a novel key. The relationship model was created to produce an illustration of a connected web site that integrates businesses and also the relationships that exist between them.
2. Knowledge repository:
A knowledge warehouse could be a single knowledge warehouse that collects data from multiple sources associated with it in an integrated system. Once knowledge is held in a very information, it’s cleansed, compiled, loaded, and updated. The information held within the information is unionized into many components. If you’re searching for info on knowledge held on when vi or twelve months, you’ll notice it within the style of an outline.
3. Activity knowledge:
Activity records keep records that area unit thought-about transactions. These functions embrace flight booking, client purchases, website clicks, and more. All dealings records have a novel ID. It conjointly lists all those things that created it a dealings.
4. Different styles of knowledge:
We have several different styles of knowledge familiar for his or her structure, linguistics definitions, and variability. they’re employed in many types. Here the area units some of these styles of knowledge: streaming data, engineering style knowledge, sequencing knowledge, graph data, location knowledge, transmission knowledge, and more.
Examples of style applications:
The prophetic capability of information mining has modified the structure of business ways. Now, you’ll be able to perceive the current and anticipate the longer term. These areas unit just a few of the samples of data processing within the current trade.
Marketing:
Data mining is employed to check growing databases and to boost market fragmentation. By analyzing the relationships between parameters like client age, gender, preferences, etc., it’s potential to guess their behavior so as to direct personal loyalty campaigns. data processing in advertising conjointly predicts that users might choose from the service list, what interests them supported their searches, or what ought to be enclosed within the list for the next response rate. For sale. Supermarkets, as an example, use collective shopping for patterns to spot product associations and verify however they’re placed in hallways and shelves. data processing conjointly determines that offers are the area unit most vital to customers or increasing sales within the exit line.
Banks:
Banks use data processing to perceive market risk. It’s typically employed in credit ratings and on dishonorable schemes to analyze transactions, card transactions, purchase patterns and client money knowledge. Data processing conjointly permits banks to find out additional information regarding their on-line choices or practices so as to boost returns on their promoting campaigns, learn the way channel sales work or manage compliance obligations.
The tree:
Data mining allows an additional correct diagnosis. Having all patient info, like medical records, physical examinations, and treatment patterns, permits for more practical treatment to be determined. It conjointly empowers them to manage health services additionally expeditiously, effectively and inexpensively by diagnosing risks, predicting unwellness in sure segments of the population or predicting length of hospital stay. detection of fraud and malpractice, and strengthening relationships with patients with advanced data of their desires also are edges of exploitation of medical data processing.
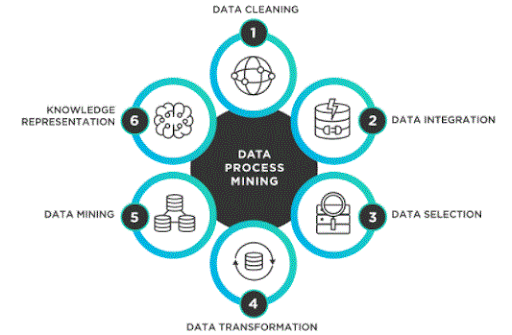
Data mining process
Before actual data processing will present itself, there are many processes concerned in beginning data processing. Here’s how:
Step 1: Business analysis – Before you begin, you would like to completely perceive the aim of your business, the resources obtainable, and therefore the current state of affairs in line with its wants. This may facilitate the formation of an in depth data processing system that effectively achieves the objectives of the organizations.
Step 2: Information Quality Assessment – As information is collected from a spread of sources, it must be monitored and compared to make sure that there aren’t any restrictions on the info assortment method. Quality assurance helps to spot any hidden ambiguities within the information, like the dearth of interpolation of knowledge, to stay the info up to straightforward before aiming to the mine.
Step 3: Information Purification – It’s believed that ninety percent of the time is spent on sorting, cleaning, info and unacquainted with information before mining.
Step 4: Information Transformation – Comprising 5 sub-categories, here, the processes concerned create {the information|the info|the information} appropriate for the ultimate data sets. Includes:
Data Summary: The compilation of knowledge sets is employed during this method.
Data Execution: Here, information is processed in an exceedingly normal method by commuting any low-level information with high-quality concepts.
General information Performance: Here, the info is outlined within the default variable.
Data symbol Development: Information sets ought to be within the attribute set before data processing.
Step 5: creating {a information|a knowledge|and information} Model: For higher data identification, many applied mathematics models are utilized in the info, supported in many cases. Learn information science to know and apply the facility of knowledge mining.
Why is it important?
Data mining is the method of capturing massive information sets to spot the main points and concepts of that information. Today, the demand for {the information|the info|The information} business is growing speedily and has increased the strain of knowledge analysts and data scientists.
Data mining applications
Below are a number of the foremost helpful data processing apps that inform U.S.A. additional concerning them.
1. Health care
Data mining has the potential to fully remodel the health care system. It may be wont to determine advanced empirical and applied mathematics processes, which may facilitate health care facilities cut back prices and improve patient outcomes. data processing, additionally as machine learning, statistics, visualization, and alternative techniques may be wont to create a distinction.
2. Education
The use of academic data processing remains in your initial part. It aims to develop methods which will use information from academic establishments to check data. Expected objectives of those methods embody learning however educational support affects students, supporting students’ future wants, and promoting learning science among alternative things. academic establishments will use these methods to not solely predict however students can perform in tests however additionally to form abreast of selections.
3. Market basket analysis
This is a modeling technique that uses the hypothesis as a basis. The hypothesis states that if you get bound merchandise, you’re additional seemingly get|to shop for} merchandise that doesn’t belong to a similar cluster that you simply buy from. Vendors will use this method to know the shopping habits of their customers. Retailers will use this data {to create|to form|to create} changes to their store structure and make purchases a lot easier and fewer time intense for patrons.
4. Client Relationship Management (CRM)
CRM involves client acquisition and retention, rising trust, and implementing customer-focused methods. Each business wants client information to analyze and apply its findings in an exceedingly method which will build lasting relationships with their customers. data processing will facilitate them to do exactly that.
5. Production engineering
The producing company depends heavily on information or data from it. Data processing will assist these firms in distinguishing patterns in processes that are too complicated for the human mind to grasp. they will determine the relationships that exist between totally different style-level design components, as well as client information necessities, properties, and products portfolio. Data processing can even be helpful in predicting all the time needed for development, the prices concerned during this method, and what firms may expect from the ultimate product.
6. Finance and banking
The banking industry has seen the assembly of enormous amounts of knowledge since its medical care. Banks will use data processing techniques to unravel the banking and monetary issues that companies face by finding connected links to promote prices and business data. This task is incredibly tough while not data processing because the quantity of knowledge they face is incredibly massive. Managers within the banking and finance sectors will use this data to accumulate, store, and look after a client.
Benefits of data mining
As we tend to live and add a data-centered world, it’s vital to induce as several edges as potential. Data processing provides the U.S. with solutions to issues and issues during this difficult modern era. edges of knowledge mining include:
- Helps firms collect reliable data.
- It is a sensible, cheap resolution compared to alternative information applications.
- It helps businesses to form profitable production and performance enhancements.
- Data mining uses each new systems and assets.
- It helps businesses create abreast of selections.
- It helps to spot debt risks and fraud.
- It helps information scientists simply analyze massive amounts of knowledge quickly.
- Data scientists will use the data to discover fraud, produce risk models, and improve product security.
- It helps information scientists quickly begin automatic behavioral predictions and trends and see hidden patterns.
Conclusion
Data mining involves a spread of strategies from totally different fields, as well as information show, machine learning, management, statistics, and more. These approaches may be developed to figure along to contend with complicated issues. Typically, data processing code or programs use one or additional of those strategies to deal with totally different information wants, data types, application locations, and mining operations.