
- Using Firebase to Persist Data Tutorial | Complete Guide [STEP-IN]
- MongoDB and Node.js Tutorial | Create Database
- What Are the Benefits of Using MongoDB Tutorial | A Concise Tutorial Just An Hour
- PL/SQL Tutorial : Learn PL/SQL in 7 Days
- PostgreSQL Tutorial
- How to Download and Install SQL Server?
- Date Functions In SQL Server And MySQL Tutorial
- SQL Server Tutorial
- SQL Applications Tutorial
- Full Join in SQL
- SQL Command Cheat Sheet
- Data Modelling
- Order By and Group By in SQL Tutorial
- Apache Cassandra Interfaces Tutorial
- mysql workbench tutorial
- Apache Cassandra Architecture Tutorial
- NoSQL Database Tutorial
- Data Manipulation in SQL Tutorial
- SQL Server Reporting Services (SSRS) Tutorial
- Using Firebase to Persist Data Tutorial | Complete Guide [STEP-IN]
- MongoDB and Node.js Tutorial | Create Database
- What Are the Benefits of Using MongoDB Tutorial | A Concise Tutorial Just An Hour
- PL/SQL Tutorial : Learn PL/SQL in 7 Days
- PostgreSQL Tutorial
- How to Download and Install SQL Server?
- Date Functions In SQL Server And MySQL Tutorial
- SQL Server Tutorial
- SQL Applications Tutorial
- Full Join in SQL
- SQL Command Cheat Sheet
- Data Modelling
- Order By and Group By in SQL Tutorial
- Apache Cassandra Interfaces Tutorial
- mysql workbench tutorial
- Apache Cassandra Architecture Tutorial
- NoSQL Database Tutorial
- Data Manipulation in SQL Tutorial
- SQL Server Reporting Services (SSRS) Tutorial

Apache Cassandra Interfaces Tutorial
Last updated on 29th Sep 2020, Blog, Database, Tutorials
Introduction
In this Apache Cassandra tutorial, you will learn Cassandra from the basics to get a fair idea of why Cassandra is such a robust NoSQL database system. Cassandra is basically a high performance, high availability and highly scalable distributed database that works well with structured, semi-structured and unstructured data. For structured data we have the RDBMS, so a database like Cassandra is essentially used for collecting and handling unstructured data.
Apache Cassandra is a very scalable, high-performance distributed database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It is a type of NoSQL database. Let us first understand what a NoSQL database does.
Recommended audience
This Cassandra tutorial can be beneficial to anybody who wants to learn NoSQL databases. Software developers, database administrators, architects, managers can take this Cassandra tutorial as a first step to learn Cassandra and excel in their careers.
Prerequisites
There are no prerequisites to learn Cassandra from this Cassandra tutorial. If you have a basic knowledge of databases, then it is good.
Subscribe For Free Demo
Error: Contact form not found.
What is Apache Cassandra?
Before we learn Cassandra, let us first understand the difference between a NoSQL database and a relational database through this table:
| Comparison criteria | NoSQL database | Relational database |
|---|---|---|
| Type of data handled | Mainly unstructured data | Only structured data |
| Volume of data | High Volume | Low Volume |
| Type of transactions handled | Simple | Complex |
| Single point of failure | No | Yes |
| Data arriving from | Many locations | A few locations |
Apache Cassandra is an open source powerful, distributed NoSQL database that does not have a single point of failure and is extremely scalable and highly available. Cassandra was originally developed at Facebook and later open sourced and is currently part of the Apache Software Foundation.
What is a NoSQL database?
A NoSQL or Not Only SQL is a set of databases that provide a way to store and retrieve data that is not in the standard tabular format followed by relational databases. The NoSQL databases of which Cassandra is a very popular database share some common features and attributes. The NoSQL databases do not have any schema, they support easy replication of data, they have a simple API, they do not exhibit the ACID properties but are eventually consistent and finally last but not the least, they can handle huge volumes of data.
Some of the properties of a NoSQL database include:
- It has a simple design
- It is scalable horizontally
- It has finer control over availability.
Why is Apache Cassandra so widely used?
In this section of the Cassandra tutorial we list some of the major points why Cassandra is such a widely used NoSQL database.
- It is a high-performance, high availability database
- It is extremely fault-tolerant, scalable and consistent
- It is high-speed thanks to it being a column-oriented database
- Its architecture is based on Google’s Bigtable & Amazon’s Dynamo.
Features of Cassandra
Here in this section of the Cassandra tutorial, we will discuss some of the top features of Cassandra
- Cassandra is highly scalable meaning you can have additional hardware for accommodating more customers and data
- Cassandra does not have a single point of failure and it has an always-on architecture
- It has a fast linear performance which means you can increase the throughput by increasing the number of nodes in the cluster
- It has a highly flexible data storage meaning all formats of data can be stored including structured, semi-structured and unstructured
- It allows for easy data distribution by providing the flexibility to distribute data by replicating it across multiple data centers
- Cassandra supports the ACID compliance which stands for Atomicity, Consistency, Isolation, Durability
- It performs blazing fast writes without sacrificing the read efficiency.
Applications of Apache Cassandra
Apache Cassandra is one of the most widely used NoSQL databases. Here we list some of the top applications of Cassandra.
- It is extensively used for monitoring and tracking of applications
- It is used in web analytics which is heavy write systems
- It is deployed for social media analysis for providing suggestions to customers
It is used in retail applications for product catalog lookups and inputs
- It is extensively used as the database for mobile messaging services
Why should you learn Cassandra?
Cassandra is a top NoSQL database and it is finding more and more users with each passing day. Since we are living in a world of big data, Cassandra is finding huge acceptance since it was built for big data. Also, a lot of the organizations are moving from the traditional relational database systems to NoSQL databases and thus Cassandra is their natural choice. All this means that the job market for Cassandra is just heating up and the salaries for Cassandra professionals are among the best in the big data domain. All these are compelling reasons for you to learn Cassandra and excel in your career.
What is Cassandra architecture
Cassandra architecture is based on the understanding that system and hardware failures occur eventually. Before talking about Cassandra lets first talk about terminologies used in architecture design.
Node: Is computer (server) where you store your data. It is the basic infrastructure component of Cassandra.
Data center :
A collection of related nodes. A data center can be a physical data center or virtual data center. Replication is set by the data center. Depending on the replication factor, data can be written to multiple data centers. However, data centers should never span physical locations.
Cluster:
A cluster contains one or more data centers. It can span physical locations.
Commit log:
Is a crash-recovery mechanism.All data is written first to the commit log (file) for durability. After all its data has been flushed to SSTables, it can be archived, deleted, or recycled.
Table:
A collection of ordered columns fetched by row.
SSTable:
A sorted string table (SSTable) is an immutable data file to which Cassandra writes memtables periodically. SSTables are appended only and stored on disk sequentially and maintained for each Cassandra table.
Gossip:
Gossip is a peer-to-peer communication protocol in which nodes periodically exchange state information about themselves and about other nodes they know about. The gossip process runs every second and exchanges state messages with up to three other nodes in the cluster.
Bloom filter:
These are quick, nondeterministic, algorithms for testing whether an element is a member of a set. Bloom filters are accessed after every query.
A detailed understanding of Apache Cassandra is available in this blog post for your perusal!
Cassandra addresses the problem of failures by using a peer-to-peer distributed system across homogeneous nodes where data is distributed among all nodes in the cluster. Each node exchanges information across the cluster every second. A sequentially written commit log on each node captures write activity to ensure data durability. Data is then indexed and written to an in-memory structure, called a memtable, which resembles a write-back cache. Once the in-memory data structure is full, the data is written to disk in an SSTable data file. All writes are automatically partitioned and replicated throughout the cluster. Using a process called compaction Cassandra periodically consolidates SSTables, discarding obsolete data and tombstones (an indicator that data was deleted). Client’s read or write requests can be sent to any node in the cluster. When a client connects to a node with a request, that node serves as the coordinator for that particular client operation. The coordinator acts as a proxy between the client application and the nodes that own the data being requested. The coordinator determines which nodes in the ring should get the request based on how the cluster is configured

Cassandra Data Model
In relational data models we have outermost containers which are called databases. Each Database will correspond to a real application for example in an online library application database name could be library . Database contains tables which could be mapped to real world entity examples. Books in the library correspond to book tables with multiple fields ( columns ) which talk about books as an entity like name . author, ISBN number etc. Usually each table has a unique identifier (primary key).
The Cassandra logical division that associates similar data is called a column family. Basic Cassandra data structures: the column, which is a name/value pair (and a client-supplied timestamp of when it was last updated), and a column family, which is a container for rows that have similar, but not identical, column sets. We have a unique identifier for each row that could be called a row key. A keyspace is the outermost container for data in Cassandra, corresponding closely to a relational database.
A detailed understanding of Apache Cassandra is available in this blog post for your perusal!
In relational databases, we’re used to storing column names as strings but in Cassandra, both row keys and column names can be strings, like relational column names, but they can also be long integers, UUIDs, or any kind of byte array.
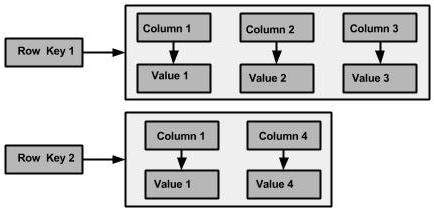
In Cassandra, the basic attributes that can be set per key space are:
Replication factor:
It refers to the number of nodes that will act as copies (replicas) of each row of data. If your replication factor is 3, then three nodes in the ring will have copies of each row, and this replication is transparent to clients.
Replica placement strategy:
refers to how the replicas will be placed in the ring. There are different strategies for determining which nodes will get copies of which keys. These are SimpleStrategy (formerly known as RackUnawareStrategy), Old Network Topology Strategy (formerly known as Rack- AwareStrategy), and NetworkTopologyStrategy (formerly known as Datacenter- ShardStrategy).
Column families:
a keyspace is a container for a list of one or more column families. Can be thought of something like this:
- [Keyspace][ColumnFamily][Key][Column]
Example of Cassandra Book column family
- Book {
- key: 9352130677{ name: “Hadoop The Definitive Guide”, author:” Tom White”, publisher:”Oreilly”, priceInr;650, category: “hadoop”, edition:4},
- key: 8177228137{ name”” Hadoop in Action”, author: “Chuck Lam”, publisher:”manning”, priceInr;590, category: “hadoop”},
- key: 8177228137{ name:” Cassandra: The Definitive Guide”, author: “Eben Hewitt”, publisher:” Oreilly”, priceInr:600, category: “cassandra”},
- }
Why is the Column family not equivalent to tables in relational databases?
1.) schema-free:
Cassandra column family doesn’t follow any schema. You can freely add any column to any column family at any time, depending on your needs.
2.) Comparator:
column family has two attributes: a name and a comparator. The comparator value indicates how columns will be sorted when they are returned to you in a query—according to long, byte, UTF8, or other ordering
3.) Data Storage:
column families are each stored in separate files on disk, it’s important to keep related columns defined together in the same column family. This makes it different from RDBMS tables.
4.) Super Columns:
In relational tables defines only columns, and the user supplies the values, which are the rows but Cassandra column family can hold columns, or it can be defined as a super column family.

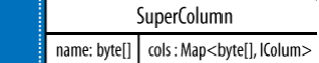
Columns Versus Super column
A column is the most basic unit of data structure in the Cassandra data model. A column is a triplet of a name, a value, and a clock, which you can think of as a timestamp. Whereas a super column is a special kind of column. Both kinds of columns are name/value pairs, but a regular column stores a byte array value, and the value of a super column is a map of sub columns (which store byte array values).
Things to keep in mind while designing Cassandra Column Family
Secondary Indexes:
In Relational Database if you want to find books for hadoop form book table you would write following query:
Select name from book where category=”hadoop”;
When handed a query like this, a relational database will perform a full table scan, inspecting each row’s name column to find the value you’re looking for. But this can become very slow once your table grows very large. So the relational answer to this is to create an index on the name column, which acts as a copy of the data that the relational database can look up very quickly.

Get Apache Cassandra Training with Industry Concepts By Experts Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Cassandra has a different approach for secondary indexes. At a high level, secondary indexes look like normal column families, with the indexed value as the partition key. Cassandra’s secondary indexes are not distributed like normal tables. They are implemented as local indexes.
Each node stores an index of only the data that it stores in Cassandra, you create a second column family that holds the lookup data. Example if Hadoop The Definitive Guide and Hadoop Training in Action records are stored on the same node.
- category {
- key: hadoop {” Hadoop The Definitive Guide”:”” ”Hadoop in Action”:””},
- key: cassandra { ” Cassandra: The Definitive Guide”:”” }
- }
Materialized View:
Materialized” means storing a full copy of the original data so that everything you need to answer a query is right there, without forcing you to look up the original data. This is because you don’t have a SQL WHERE clause, you can recreate this effect by writing your data to a second column family that is created specifically to represent that query.
Design queries first then table:
Design queries your application will need, and model the data around that instead of modeling the data first, as you would in the relational world.
Timestamp:
Supply a timestamp (or clock) with each query. This is important because Cassandra uses timestamps to determine the most recent write value.
What is CQL?
CQL is a simple api meant for accessing Cassandra.CQL adds an abstraction layer that hides implementation details of this structure and provides native syntaxes for collections and other common encodings.
Common ways to access CQL are:
- Start cqlsh, the Python-based command-line client, on the command line of a Cassandra node.
- For developing applications, use one of the C#, Java, or Python open-source drivers.
- Use the set_cql_version Thrift method for programmatic access
Below are common operation we can do with CQL
1. Creating and using key space:
- cqlsh> CREATE KEYSPACE demodb WITH REPLICATION = { ‘class’ :
- ‘NetworkTopologyStrategy’, ‘datacenter1’ : 3 };
- USE demodb;
2. Alter KeySpace
- ALTER KEYSPACE ” demodb ” WITH REPLICATION = { ‘class’ : ‘SimpleStrategy’,
- ‘replication_factor’ : 2};
3. Create Table
- CREATE TABLE emp ( empID int, deptID int, first_name varchar,last_name varchar, PRIMARY KEY (empID, deptID));
4. Insert into table
- INSERT INTO emp (empID, deptID, first_name, last_name) VALUES (104, 15, ‘jane’, ‘smith’);
5. Select query Select * from emp;
Scaling online library with Cassandra
Let’s talk about a very simple example of an online books library. In relation databases the system will have multiple normalized schemas. Few of very important one are described below:
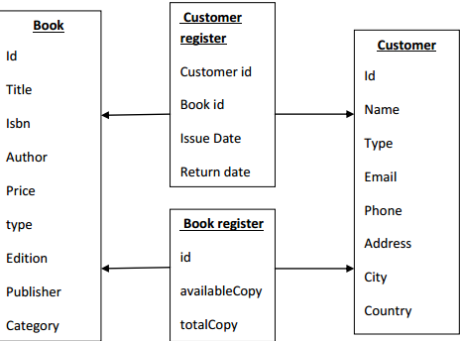
As with the introduction of “free users” and “unlimited books at my disposal” features in online book libraries, the popularity of the app increased to great extent .Resultant was a flood of customer data. These made RDBMS setup unstable and business decided to go with Cassandra to mitigate the issue.
Before designing the Cassandra table we need to find out all possible queries which key space shall support.
Most fired queries would be:
- 1. Get books of category with availability >0
- 2. Get books from same author Queries for business point of view
- 3. Get Customer liking per geographic location
- 4. Most liked category
So in order to incorporate this quicker we need to denormalize data and create new column families.
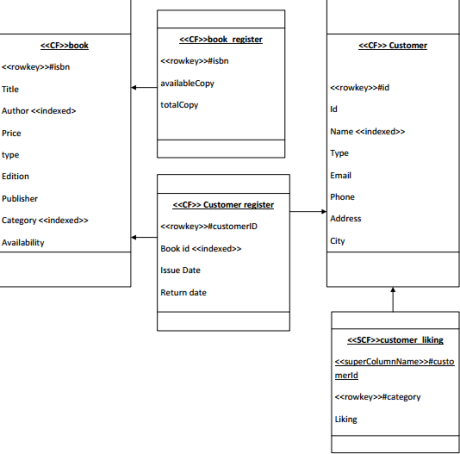
Cassandra Client API
There are multiple client api available for Cassandra Training. However the preferred interface to Cassandra 1.2 and 2.0 is CQL. Earlier it used to be thrift.
- import com.datastax.driver.core.BoundStatement;
- import com.datastax.driver.core.Cluster;
- import com.datastax.driver.core.PreparedStatement;
- import com.datastax.driver.core.ResultSet;
- import com.datastax.driver.core.Row;
- import com.datastax.driver.core.Session;
- import com.datastax.driver.core.Statement;
- import com.datastax.driver.core.querybuilder.QueryBuilder;
- public class CassandraCliClientExample {
- static void main(String[] args) {
- // Connect to the cluster and keyspace “library”
- Cluster cluster = Cluster.builder().addContactPoint(“localhost”)
- .build();
- Session session = cluster.connect(“library”);
- /**
- * *other ways to create cluster cluster =
- * Cluster.builder().addContactPoint(“192.168.0.30”)
- * .withRetryPolicy(DefaultRetryPolicy.INSTANCE) .build();session =
- * cluster.connect(“library”); cluster =
- * Cluster.builder().addContactPoint(“192.168.0.30”)
- * .withRe.tryPolicy(DefaultRetryPolicy.INSTANCE)
- * .withLoadBalancingPolicy( new TokenAwarePolicy(new
- * DCAwareRoundRobinPolicy())) .build(); session =
- * cluster.connect(“library”);
- ***/
- // Insert one record into the customer table
- session.execute(“INSERT INTO customer (last_name, age, city, email, firstname)
- VALUES (‘Ram’, 35, ‘Delhi’, ‘Ram@example.com’, ‘Shree’)”);
- //Use select to get the customer we just entered
- ResultSet results = session.execute(“SELECT * FROM customer WHERE
- last_name=’Delhi'”);
- for (Row row : results) {
- System.out.format(“%s %dn”, row.getString(“firstname”),row.getInt(“age”));
- }
- // Update the same customer with a new age
- session.execute(“update customer set age = 36 where lastname = ‘Delhi'”);
- // Select and show the change
- results = session.execute(“select * from customer where lastname=’Delhi'”);
- for (Row row : results) {
- System.out.format(“%s %dn”, row.getString(“firstname”), row.getInt(“age”));
- }
- // Delete the customer from the customer table
- session.execute(“DELETE FROM customer WHERE lastname = ‘Delhi'”);
- // Show that the customer is gone
- result= session.execute(“SELECT * FROM customer”);
- for (Row row : results) {
- System.out.format(“%s %d %s %s %sn”, row.getString(“lastname”),
- row.getInt(“age”), row.getString(“city”),
- row.getString(“email”), row.getString(“firstname”));
- }
- // Insert one record into the customer table
- PreparedStatement statement = session.prepare(“INSERT INTO customer”
- + “(last_name, age, city, email, firstname)”
- + “VALUES (?,?,?,?,?);”);
- BoundStatement boundStatement = new BoundStatement(statement);
- session.execute(boundStatement.bind(“Ram”, 35, “Delhi”,
- “ram@example.com”, “Shree”));
- // Use select to get the customer we just entered
- Statement select = QueryBuilder.select().all().from(“library”, “customer”)
- .where(QueryBuilder.eq(“lastname”, “Ram”));
- results = session.execute(select);
- for (Row row : results) {
- System.out.format(“%s %d n”, row.getString(“firstname”),
- row.getInt(“age”));
- }
- // Delete the customer from the customer table
- Statement delete = QueryBuilder.delete().from(“customer”)
- .where(QueryBuilder.eq(“lastname”, “Ram”));
- results = session.execute(delete);
- // Show that the customer is gone
- select = QueryBuilder.select().all().from(“library”, “customer”);
- results = session.execute(select);
- for (Row row : results) {
- System.out.format(“%s %d %s %s %sn”, row.getString(“lastname”),
- row.getInt(“age”), row.getString(“city”),
- row.getString(“email”), row.getString(“firstname”));
- }
- // Clean up the connection by closing it
- cluster.close();
- }
- }
Cassandra Performance Tuning: Methodologies
There are multiple dimensions where Cassandra performance can be tuned. Some of them are described below:
Write Operations:
Commit log and data dirs (sstables) should be on different disks. Commit log uses sequential write however, if SSTables share the same drive with commit log , I/O contention between commit log & SSTables may deteriorate commit log writes and SSTable reads.
Read Operations:
A good rule of thumb is 4 concurrent_reads per processor core. May increase the value for systems with fast I/O storage.
Cassandra Compaction Contention:
Reduce the frequency of memtable flush by increasing the memtable size or preventing too pre-mature flushing. Less frequent memtable flush results in fewer SSTables files and less compaction. Fewer compaction reduces SSTables I/O contention, and therefore improves read operations. Bigger memtables absorb more overwrites for updates to the same keys, and therefore accommodate more read/write operations between each flushes.
Memory Cache:
Do not increase Cassandra cache size unless there is enough physical memory (RAM). Avoid memory swapping at any cost.
Row Cache:
The row cache holds the entire content of a row in memory. It provides data caching instead of reading data from the disk. good if the column’s data is small so the cache is big enough to hold most of the hotspot data. Bad if the column’s data is too large so the cache is not big enough to hold most of the hotspot data. It’s bad for high write/read ratios. By default, it is off. If the hit ratio is below 30%, row cache should be disabled.
Key Cache Tuning:
The key cache holds the location of data in memory for each column family. It’s Effective if there are hot data spots & cannot use row cache effectively because of the large column size. By default, Cassandra caches 200000 keys per column family. Use the absolute number for keys_cached instead of percentage.
JVM:
Minimum and Maximum Java Heap Size should be half of available physical memory. Size of the young generation heap should be 1/4 of Java Heap. Do NOT increase the size without confirming there are enough available physical memory- Always reserves memory for OS File cache.
A detailed understanding of Apache Cassandra is available in this blog post for your perusal!