
- Using Firebase to Persist Data Tutorial | Complete Guide [STEP-IN]
- MongoDB and Node.js Tutorial | Create Database
- What Are the Benefits of Using MongoDB Tutorial | A Concise Tutorial Just An Hour
- PL/SQL Tutorial : Learn PL/SQL in 7 Days
- PostgreSQL Tutorial
- How to Download and Install SQL Server?
- Date Functions In SQL Server And MySQL Tutorial
- SQL Server Tutorial
- SQL Applications Tutorial
- Full Join in SQL
- SQL Command Cheat Sheet
- Data Modelling
- Order By and Group By in SQL Tutorial
- Apache Cassandra Interfaces Tutorial
- mysql workbench tutorial
- Apache Cassandra Architecture Tutorial
- NoSQL Database Tutorial
- Data Manipulation in SQL Tutorial
- SQL Server Reporting Services (SSRS) Tutorial
- Using Firebase to Persist Data Tutorial | Complete Guide [STEP-IN]
- MongoDB and Node.js Tutorial | Create Database
- What Are the Benefits of Using MongoDB Tutorial | A Concise Tutorial Just An Hour
- PL/SQL Tutorial : Learn PL/SQL in 7 Days
- PostgreSQL Tutorial
- How to Download and Install SQL Server?
- Date Functions In SQL Server And MySQL Tutorial
- SQL Server Tutorial
- SQL Applications Tutorial
- Full Join in SQL
- SQL Command Cheat Sheet
- Data Modelling
- Order By and Group By in SQL Tutorial
- Apache Cassandra Interfaces Tutorial
- mysql workbench tutorial
- Apache Cassandra Architecture Tutorial
- NoSQL Database Tutorial
- Data Manipulation in SQL Tutorial
- SQL Server Reporting Services (SSRS) Tutorial

NoSQL Database Tutorial
Last updated on 25th Sep 2020, Blog, Database, Tutorials
What is NoSQL Database?
NoSQL Database is a non-relational Data Management System that does not require a fixed schema. It avoids joins, and is easy to scale. The major purpose of using a NoSQL database is for distributed data stores with humongous data storage needs. NoSQL is used for Big data and real-time web apps. For example, companies like Twitter, Facebook and Google collect terabytes of user data every single day.
NoSQL database stands for “Not Only SQL” or “Not SQL.” Though a better term would be “NoREL”, NoSQL caught on. Carl Strozz introduced the NoSQL concept in 1998.
Traditional RDBMS uses SQL syntax to store and retrieve data for further insights. Instead, a NoSQL database system encompasses a wide range of database technologies that can store structured, semi-structured, unstructured and polymorphic data.
Why NoSQL?
The concept of NoSQL databases became popular with Internet giants like Google, Facebook, Amazon, etc. who deal with huge volumes of data. The system response time becomes slow when you use RDBMS for massive volumes of data.
What is NoSQL Database tutorial
To resolve this problem, we could “scale up” our systems by upgrading our existing hardware. This process is expensive.
The alternative for this issue is to distribute database load on multiple hosts whenever the load increases. This method is known as “scaling out.”
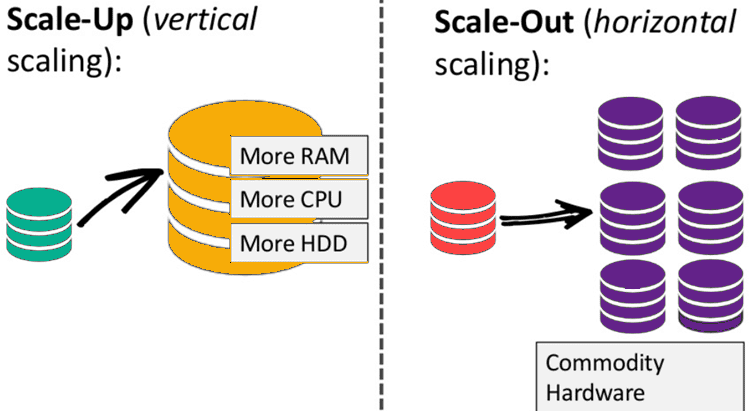
NoSQL database is non-relational, so it scales out better than relational databases as they are designed with web applications in mind.
Features of NoSQL
Non-relational
- NoSQL databases never follow the relational model
- Never provide tables with flat fixed-column records
- Work with self-contained aggregates or BLOBs
- Doesn’t require object-relational mapping and data normalization
- No complex features like query languages, query planners,
referential integrity joins, ACID
Schema-free
- NoSQL databases are either schema-free or have relaxed schemas
- Do not require any sort of definition of the schema of the data
- Offers heterogeneous structures of data in the same domain
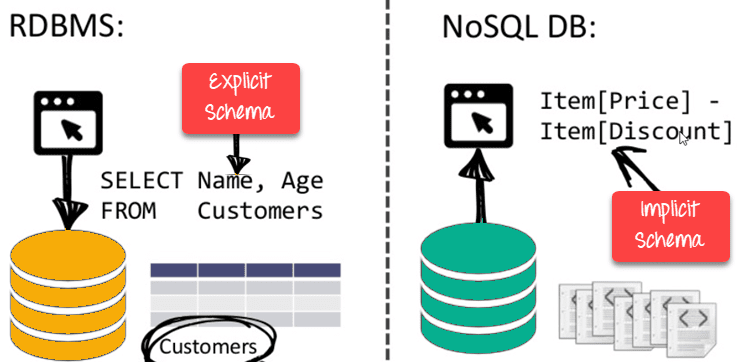
NoSQL is Schema-Free
Simple API
- Offers easy to use interfaces for storage and querying data provided
- APIs allow low-level data manipulation & selection methods
- Text-based protocols mostly used with HTTP REST with JSON
- Mostly used no standard based query language
- Web-enabled databases running as internet-facing services
Subscribe For Free Demo
Error: Contact form not found.
Distributed
- Multiple NoSQL databases can be executed in a distributed fashion
- Offers auto-scaling and fail-over capabilities
- Often ACID concept can be sacrificed for scalability and throughput
- Mostly no synchronous replication between distributed nodes Asynchronous Multi-Master Replication, peer-to-peer, HDFS Replication
- Only providing eventual consistency
- Shared Nothing Architecture. This enables less coordination and higher distribution.
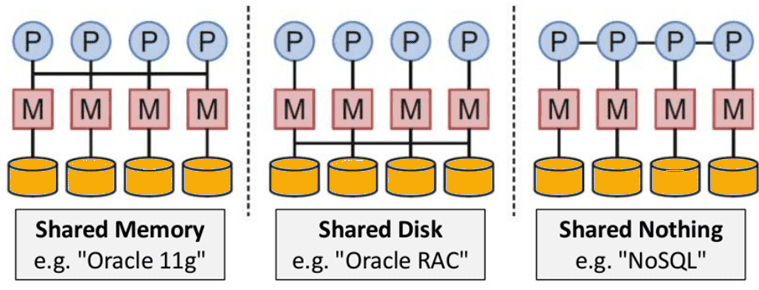
NoSQL is Shared Nothing.
Multi-Model
NoSQL databases are extremely flexible in case of handling the data. These databases can easily ingest semi-structured, unstructured, and structured data. Architects, programmers, and developers prefer to use NoSQL databases since they make it easier to handle a variety of agile requirements of application development.
Some of the popular data models are a document, graph, key-value, and wide-column. The basic idea behind using NoSQL is to support multiple varieties of data models which would allow you to use a single data in multiple types of data models without the need to create or manage a totally different database.
Flexible
The relational databases are designed in such a way that they can handle only the primarily structured data, whereas the NoSQL database tutorials indicate that the systems can handle multiple data types with ease.
Easily Scalable
Relational databases can sure scale but they cannot do it easily or even cheaply. There are certain NoSQL databases that feature peer-to-peer and masterless architecture with
all the nodes being the same.
This makes easy scaling for adapting to the complexity and volume of data of the cloud applications. This scalability is also responsible for improving the performance and allowing the availability of continuous and high write/read speeds.
Zero Downtime
Another important feature which you must learn from the NoSQL tutorial is that NoSQLdatabases are attributed with zero downtime. The masterless architecture of this database makes this possible.
This architecture is what introduces the possibility of managing multiple data copies across the various nodes. This means that, even if a node fails or goes down, another node would have the data copy which can be easily and quickly accessed. This is very significant when one considers the downtime costs.
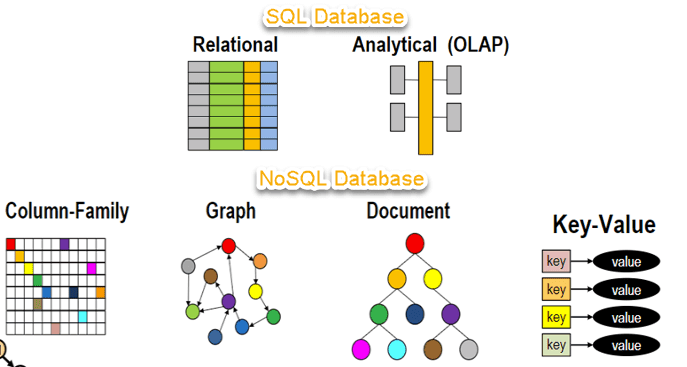
Types of NoSQL Databases
NoSQL Databases are mainly categorized into four types: Key-value pair, Column-oriented, Graph-based and Document-oriented. Every category has its unique attributes and limitations. None of the above-specified databases is better to solve all the problems. Users should select the database based on their product needs.
Types of NoSQL Databases:
- Key-value Pair Based
- Column-oriented Graph
- Graphs based
- Document-oriented
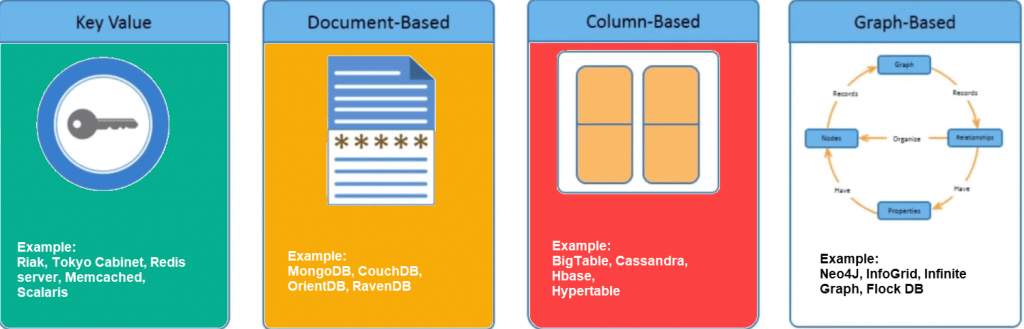
Key Value Pair Based
Data is stored in key/value pairs. It is designed in such a way to handle lots of data and heavy load.
Key-value pair storage databases store data as a hash table where each key is unique, and the value can be a JSON, BLOB(Binary Large Objects), string, etc.
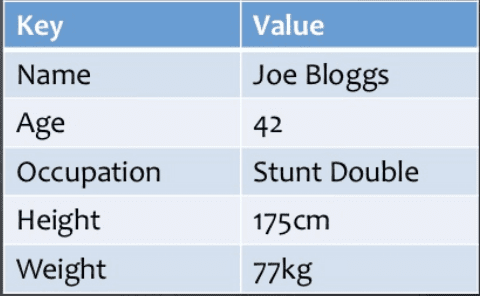
It is one of the most basic types of NoSQL databases. This kind of NoSQL database is used as a collection, dictionaries, associative arrays, etc. Key value stores help the developer to store schema-less data. They work best for shopping cart contents.
Redis, Dynamo, Riak are some examples of key-value store DataBases. They are all based on Amazon’s Dynamo paper.
Column-based
Column-oriented databases work on columns and are based on BigTable paper by Google. Every column is treated separately. Values of single column databases are stored contiguously.
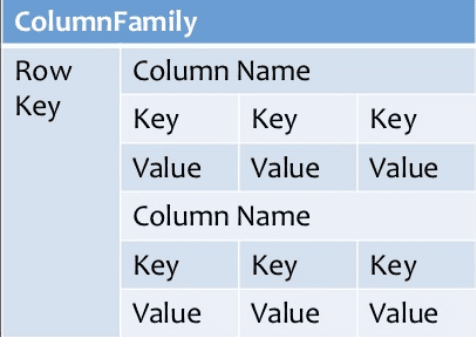
Column based NoSQL database
They deliver high performance on aggregation queries like SUM, COUNT, AVG, MIN etc. as the data is readily available in a column.
Column-based NoSQL databases are widely used to manage data warehouses, business intelligence, CRM, Library card catalogs,
HBase, Cassandra, HBase, Hypertable are examples of column based databases.
Document-Oriented
Document-Oriented NoSQL DB stores and retrieves data as a key value pair but the value part is stored as a document. The document is stored in JSON or XML formats. The value is understood by the DB and can be queried.
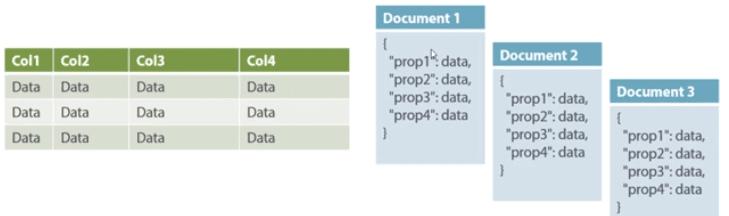
Relational Vs. Document
In this diagram on your left you can see we have rows and columns, and in the right, we have a document database which has a similar structure to JSON. Now for the relational database, you have to know what columns you have and so on. However, for a document database, you have a data store like JSON object. You are not required to define which makes it flexible.
The document type is mostly used for CMS systems, blogging platforms, real-time analytics & e-commerce applications. It should not be used for complex transactions which require multiple operations or queries against varying aggregate structures.
Amazon SimpleDB, CouchDB, MongoDB, Riak, Lotus Notes, MongoDB, are popular Document originated DBMS systems.
Graph-Based
A graph type database stores entities as well the relations amongst those entities. The entity is stored as a node with the relationship as edges. An edge gives a relationship between nodes. Every node and edge has a unique identifier.
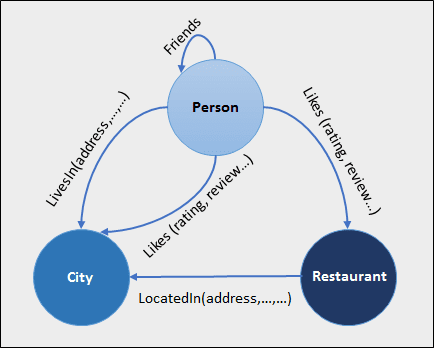
Compared to a relational database where tables are loosely connected, a Graph database is multi-relational in nature. Traversing relationships are fast as they are already captured into the DB, and there is no need to calculate them.
Graph based database mostly used for social networks, logistics, spatial data.
Neo4J, Infinite Graph, OrientDB, FlockDB are some popular graph-based databases.
Query Mechanism tools for NoSQL
The most common data retrieval mechanism is the REST-based retrieval of a value based on its key/ID with GET resource
Document store Database offers more difficult queries as they understand the value in a key-value pair. For example, CouchDB allows defining views with MapReduce
What is the CAP Theorem?
CAP theorem is also called brewer’s theorem. It states that is impossible for a distributed data store to offer more than two out of three guarantees
- 1. Consistency
- 2. Availability
- 3. Partition Tolerance
Consistency:
The data should remain consistent even after the execution of an operation. This means once data is written, any future read request should contain that data. For example, after updating the order status, all the clients should be able to see the same data.
Availability:
The database should always be available and responsive. It should not have any downtime.
Partition Tolerance:
Partition Tolerance means that the system should continue to function even if the communication among the servers is not stable. For example, the servers can be partitioned into multiple groups which may not communicate with each other. Here, if part of the database is unavailable, other parts are always unaffected.
Eventual Consistency
The term “eventual consistency” means to have copies of data on multiple machines to get high availability and scalability. Thus, changes made to any data item on one machine has to be propagated to other replicas.
Data replication may not be instantaneous as some copies will be updated immediately while others in due course of time. These copies may be mutually, but in due course of time, they become consistent. Hence, the name’s eventual consistency.

Best Hands-on Practical Nosql Databases Training By Top-Rated Instructors
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
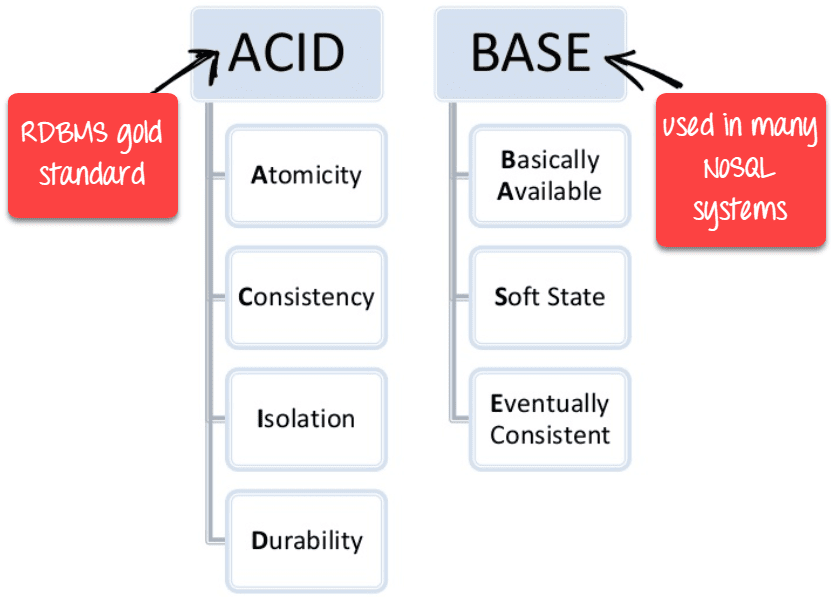
BASE: Basically Available, Soft state, Eventual consistency
- Basically, available means DB is available all the time as per CAP theorem
- Soft state means even without an input; the system state may change
- Eventual consistency means that the system will become consistent over time
Some Advantages of NoSQL Databases
Here we will be discussing some of the main advantages of NoSQL databases with examples.
Dynamic Schemas
You must be wondering what dynamic schema means? In Relational Databases like Oracle, MySQL we define table structures, right? For example, if we want to save records of Student Data, then we will have to create a table named Student, add columns to it, like student_id, student_name etc, this is called a defined schema, wherein we define the structure before saving any data.
If in future we plan to add some more related data in our Student table, then we will have to add a new column to our table. Which is easy, if we have less data in our tables, but what if we have millions of records. Migration to the updated schema would be a hectic job. NoSQL databases solve this problem, as in a NoSQL database, schema definition is not required.
Sharding
In Sharding, large databases are partitioned into small, faster and easily manageable databases.
The (classic) Relational Databases follow a vertical architecture where a single server holds the data, as all the data is related. Relational Databases does not provide Sharding feature by default, to achieve this a lot of efforts has to be put in, because transactional integrity(Inserting/Updating data in transactions), Multiple table JOINS etc cannot be easily achieved in distributed architecture in case of Relational Databases.
NoSQL Databases have the Sharding feature as default. No additional efforts required. They automatically spread the data across servers, fetch the data in the fastest time from the server which is free, while maintaining the integrity of data.
Replication
Auto data replication is also supported in NoSQL databases by default. Hence, if one DB server goes down, data is restored using its copy created on another server in the network.
Integrated Caching
Many NoSQL databases have support for Integrated Caching, where the frequently demanded data is stored in cache to make the queries faster.
Disadvantages of NoSQL
- No standardization rules
- Limited query capabilities
- RDBMS databases and tools are comparatively mature
- It does not offer any traditional database capabilities, like consistency when multiple transactions are performed simultaneously.
- When the volume of data increases it is difficult to maintain unique values as keys become difficult
- Doesn’t work as well with relational data
- The learning curve is stiff for new developers
- Open source options are not so popular for enterprises.
Differences between SQL and NoSQL
The table below summarizes the main differences between SQL and NoSQL databases.
| SQL Databases | NoSQL Databases | |
|---|---|---|
| Data Storage Model | Tables with fixed rows and columns | Document: JSON documents, Key-value: key-value pairs, Wide-column: tables with rows and dynamic columns, Graph: nodes and edges |
| Development History | Developed in the 1970s with a focus on reducing data duplication | Developed in the late 2000s with a focus on scaling and allowing for rapid application change driven by agile and DevOps practices. |
| Examples | Oracle, MySQL, Microsoft SQL Server, and PostgreSQL | Document: MongoDB and CouchDB, Key-value: Redis and DynamoDB, Wide-column: Cassandra and HBase, Graph: Neo4j and Amazon Neptune |
| Primary Purpose | General purpose | Document: general purpose, Key-value: large amounts of data with simple lookup queries, Wide-column: large amounts of data with predictable query patterns, Graph: analyzing and traversing relationships between connected data |
| Schemas | Rigid | Flexible |
| Scaling | Vertical (scale-up with a larger server) | Horizontal (scale-out across commodity servers) |
| Multi-Record ACID Transactions | Supported | Most do not support multi-record ACID transactions. However, some—like MongoDB—do. |
| Joins | Typically required | Typically not required |
| Data to Object Mapping | Requires ORM (object-relational mapping) | Many do not require ORMs. MongoDB documents map directly to data structures in most popular programming languages. |
There are plenty of NoSQL databases that are available. Each of these different NoSQL databases has a specific function and there are certain pros and cons linked to each of them. You can pick a particular NoSQL data to learn based on these differences.
Here are some of the popular NoSQL databases, learning about which can be hugely beneficial to you.
1. MongoDB – NoSQL Database
MongoDB is a NoSQL database written in C++ language. Some of its drivers use the C programming language as the base. MongoDB is a document oriented database where it stores data in collections instead of tables. The best part of MongoDB is that the drivers are available for almost all the popular programming languages.
In today’s competitive technological world, every company has started hosting its enterprise applications over the cloud in order to expand the business globally, provide faster services and to personalise the customer’s experience with the application and overall business. And NoSQL has become the first choice in database technology for developing such applications.
2. Redis
This is an in-memory open-source NoSQL database that implements an in-memory, distributed store of key-value with the optional durability. It also can be used in the form of a message broker and cache.
Hashes, strings, sets, lists, sorted sets of range queries, hyper logs, bitmaps and geospatial indexes containing radius queries, are some data structures supported by the Redis NoSQL database.
3. Apache Cassandra
This is a distributed and open-source NoSQL database which is completely free. This database management system has been designed in such a way that it can handle large amounts of different data types across several commodity servers.
And, this is done by providing greater availability with no point for failure. This NoSQL database is the ideal choice when high availability with scalability is required without a compromise in the performance.
The linear scalability and fault tolerance which has been proven on cloud infrastructure and commodity hardware, make Apache Cassandra the ideal platform for managing and handling critical data types.
4. Apache HBase
Apache HBase is a non-relational, open-source and distributed type of data model and is generally written in Java. It was initially developed as an entity of Apache Software Foundation’s project called Apache Hadoop.
It runs on top of the Hadoop Distributed File System and provides capabilities that are similar to that of Google’s Bigtable.
5. Couchbase
Couchbase was originally referred to as Membase and is a distributed and open-source multi-model database which is document-oriented and is optimized for interactive applications. You can learn this from the NoSQL tutorial for beginners’ official documentation and tutorials. There are also a few online free sessions that are offered to learn this NoSQL database.
How NoSQL Databases Work
One way of understanding the appeal of NoSQL databases from a design perspective is to look at how the data models of a SQL and a NoSQL database might look in an oversimplified example using address data.
The SQL Case. For an SQL database, setting up a database for addresses begins with the logical construction of the format and the expectation that the records to be stored are going to remain relatively unchanged. After analyzing the expected query patterns, an SQL database might optimize storage in two tables, one for basic information and one pertaining to being a customer, with last name being the key to both tables. Each row in each table is a single customer, and each column has the following fixed attributes:
- Last name :: first name :: middle initial :: address fields :: email address :: phone number
- Last name :: date of birth :: account number :: customer years :: communication preferences
The NoSQL Case. In the section Types of NoSQL Databases above, there were four types described, and each has its own data model.
Each type of NoSQL database would be designed with a specific customer situation in mind, and there would be technical reasons for how each kind of database would be organized. The simplest type to describe is the document database, in which it would be natural to combine both the basic information and the customer information in one JSON document. In this case, each of the SQL column attributes would be fields and the details of a customer’s record would be the data values associated with each field.
For example: Last_name: “Jones”, First_name: “Mary”, Middle_initial: “S”, etc
NoSQL databases have one important thing in common: they do not rely on the traditional row-and-column schema that relational databases use. But from that point, NoSQL databases diverge. Here we explore the main types of NoSQL databases along with examples of how they are used in practice.
NOSQL Database Examples
Document database example
Document databases store data in a document data model using JSON (JavaScript Object Notation) or XML objects. Each document contains markup that identifies fields and values. The values can vary over the usual types including strings, numbers, Booleans, arrays, and nested data.
Enhancing its flexibility, the document data model can vary from record to record. It’s popular with developers because JSON documents capture structures that typically align with objects developers are working with in code.
NoSQL databases are usually implemented with a horizontal, scale-out architecture that provides a clear path to supporting huge amounts of data or traffic.
Creating a single view of data (sometimes called customer 360) is an important challenge for many businesses. At many organizations, data has been siloed by department: the shipping data is separate from the product data which is in turn separate from the customer data, which sales and customer service may each have a version of.
AO.com, one of the largest electronics stores in the UK, needed to create a single view of their data to support applications, including their call center, their fraud team, and their GDPR compliance efforts. After reviewing a number of NoSQL databases, AO.com chose MongoDB Atlas. According to Jon Vines, Software Development Team Lead at AO.com, “It soon became clear that MongoDB’s document model was the best choice for us. It supports rich customer objects that we can further enrich at any stage without expensive schema migrations.”
Key-value database example
Key-value databases use a very simple schema: a unique key is paired with a collection of values, where the values can be anything from a string to a large binary object. One way that databases using this structure gain in performance is that there are no complex queries.
MediaWiki software is used by Wikipedia, as well as tens of thousands of other websites. Memcached is an in-memory key-value object store that MediaWiki uses for caching values to reduce the need to perform expensive computations and to reduce load on the database servers. This provides a high-performance, distributed system that speeds up dynamic web applications.
In this example of a key-value store, a unique key is used to store small chunks of arbitrary data (strings, and other objects) from results of database calls, API calls, or page rendering. Performance is increased by caching the results of a database query into Memcached for some arbitrary amount of time, such as 5 minutes, and then querying Memcached first for the results instead of the database.
Wide-column store example
A wide-column store handles data using a modified table model. Data is stored using key rows that can be associated with one or more dynamic columns. What makes this model so flexible is that the structure of the column data can vary from row to row. Wide-column stores are often used for storing large amounts of data: billions of rows with millions of columns.
Ebay uses wide-column store Cassandra as part of its inventory management system, which supports critical use cases and applications that need both real-time and analytics capabilities.
Graph database example
Connecting data in relational databases requires creating JOINs between tables. Such JOINs take a very long time.
If you are building an application where you need to traverse the connections between data rapidly, a graph database may be a good fit. Think about real-time recommendations on an e-commerce site, where the application needs to connect data about what the user is looking for, what the user has bought in the past, what users like this user have bought, what preferences and interests the user has, what products go well with the product being viewed, what is currently in stock, and more. The ability to connect all that data in real-time in the best case leads to a suggestion that grabs the user’s attention and interest, representing a new sale or an add-on to an existing order. This is one example of a use case for a graph database.
Sometimes the answer to a data problem is not one type of NoSQL database but multiple data stores. Storing data in multiple databases is referred to as polyglot persistence.
For example, Zephyr built a platform that integrates diverse healthcare data using a document database (MongoDB) and a graph database (Neo4j). Zephyr (which was subsequently purchased by Anju Life Sciences Software) stores the bulk of its data in MongoDB in a flexible JSON format while Neo4j is used to store relationships between data elements as nodes and edges, with pointers back to the full data in MongoDB.
Summary
- NoSQL is a non-relational DMS, that does not require a fixed schema, avoids joins, and is easy to scale
- The concept of NoSQL databases became popular with Internet giants like Google, Facebook, Amazon, etc. who deal with huge volumes of data
- In the year 1998- Carlo Strozzi use the term NoSQL for his lightweight, open-source relational database
- NoSQL databases never follow the relational model it is either schema-free or has relaxed schemas
- Four types of NoSQL Database are 1).Key-value Pair Based 2).Column-oriented Graph 3). Graphs based 4).Document-oriented
- NOSQL can handle structured, semi-structured, and unstructured data with equal effect
- CAP theorem consists of three words Consistency, Availability, and Partition Tolerance
- BASE stands for Basically Available, Soft state, Eventual consistency
- The term “eventual consistency” means to have copies of data on multiple machines to get high availability and scalability
- NOSQL offer limited query capabilities