
- Must-Know [LATEST] Apache NiFi Interview Questions and Answers
- [SCENARIO-BASED ] Mahout Interview Questions and Answers
- 40+ [REAL-TIME] Apache Ambari Interview Questions and Answers
- [50+] Big Data Greenplum DBA Interview Questions and Answers
- 40+ [REAL-TIME] Informatica Analyst Interview Questions and Answers
- Must-Know [LATEST] FileNet Interview Questions and Answers
- 20+ Must-Know SAS Grid Administration Interview Questions
- [SCENARIO-BASED ] Apache Flume Interview Questions and Answers
- Top Storm Interview Questions and Answers [ TO GET HIRED ]
- Cassandra Interview Questions and Answers
- Sqoop Interview Questions and Answers
- kafka Interview Questions and Answers
- Hive Interview Questions and Answers
- Big Data Hadoop Interview Questions and Answers
- Elasticsearch Interview Questions and Answers
- HDFS Interview Questions and Answers
- HBase Interview Questions and Answers
- MapReduce Interview Questions and Answers
- Pyspark Interview Questions and Answers
- Hadoop Interview Questions and Answers
- Apache Spark Interview Questions and Answers
- Must-Know [LATEST] Apache NiFi Interview Questions and Answers
- [SCENARIO-BASED ] Mahout Interview Questions and Answers
- 40+ [REAL-TIME] Apache Ambari Interview Questions and Answers
- [50+] Big Data Greenplum DBA Interview Questions and Answers
- 40+ [REAL-TIME] Informatica Analyst Interview Questions and Answers
- Must-Know [LATEST] FileNet Interview Questions and Answers
- 20+ Must-Know SAS Grid Administration Interview Questions
- [SCENARIO-BASED ] Apache Flume Interview Questions and Answers
- Top Storm Interview Questions and Answers [ TO GET HIRED ]
- Cassandra Interview Questions and Answers
- Sqoop Interview Questions and Answers
- kafka Interview Questions and Answers
- Hive Interview Questions and Answers
- Big Data Hadoop Interview Questions and Answers
- Elasticsearch Interview Questions and Answers
- HDFS Interview Questions and Answers
- HBase Interview Questions and Answers
- MapReduce Interview Questions and Answers
- Pyspark Interview Questions and Answers
- Hadoop Interview Questions and Answers
- Apache Spark Interview Questions and Answers

[50+] Big Data Greenplum DBA Interview Questions and Answers
Last updated on 26th Sep 2022, Big Data, Blog, Interview Question
1. The way to check the distribution policy of check table sales?
Ans:
- psql>d sales
- Table” public. sales”
| kind | Modifiers |
|---|---|
| id | number |
| date | date |
2. What number of user schemas are there within the database?
Ans:
Use”dn” at the p sql prompt.
3. Once was my table last analyzed within the Greenplum database?
Ans:
Ans:4. The way to check the dimensions of a table?
Ans:
Table and Index:
- P sql> choose pg_size_pretty(pg_total_relation_size(‘schema.tablename’));
- Replace schema.tablename together with your search table
5. The way to start/stop decibel in admin mode?
Ans:
Admin Mode Utility mode
The gpstart with choice (-R) stands for Admin mode or restricted mode wherever solely superusers will connect with the info once the info opens mistreatment this selection.
Utility mode permits you to attach to solely individual segments once started mistreatment gpstart -m, for example< to attach to solely master instance only:
- PGOPTIONS=’-c gp_session_role=utility’ p sql
6. The way to check the Schema size?
Ans:
- P sql> choose schemaname ,round(sum(pg_total_relation_size(schemaname||’.’||tablename))/1024/1024) “Size_MB”
- from pg_tables wherever schema name=’SCHEMA NAME’ cluster by 1;
- [ connected Article: Analytics Tools in huge information ]
7. The way to check the info size?
Ans:
To see the dimensions of the precise database:
- P sql> choose pg_size_pretty(pg_database_size(‘DATBASE_NAME’)); Example:
- gpdb=# choose pg_size_pretty(pg_database_size(‘gpdb’));
- pg_size_pretty
- 24 MB
- (1 row)
To see all info sizes:
- psql> choose datname,pg_size_pretty(pg_database_size(datname)) from pg_database;
8. The way to check partitioned off table size together with indexes and partitions?
Ans:
Table size with partitions:
The following SQL provides you employee_dailly table size, which has partitions.
- select schemaname,tablename,round(sum(pg_total_relation_size(schemaname || ‘.’ || partition table name))/1024/1024) “MB” from pg_partitions wherever table name=’employee_daily’ cluster by one,2;
| Schemaname | Tablename | MB |
|---|---|---|
| public | employee_daily | 254 |
9. However, do I purchase assistance on the syntax to change the table?
Ans:
In pl sql session kind halter table which is able to show the syntax:
- gpdb=# h alter table
10. Outline greenplum architecture?
Ans:
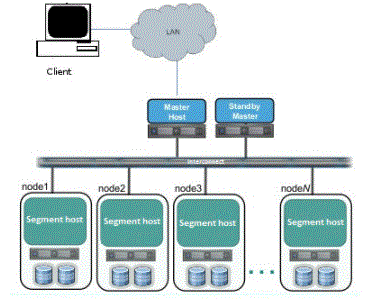
11. The way to connect in utility mode?
Ans:
From master host
- PGOPTIONS=’-c gp_session_role=utility’ p sql -p -h
Where:
- port is segment/ master info port.
- hostname is segment/master hostname.
12. Where/How to seek out decibel logs?
Ans:
Master:Master gp db log file is found within the $MASTER_DATA_DIRECTORY/pg_log/ directory and also the file name depends on the info “log_filename” parameter.
- $MASTER_DATA_DIRECTORY/pg_log/gpdb-yyyy-mm-dd_000000.csv –>Log file format with default installation.
- ~pgadmin/gpAdminLogs/ –>gpstart,gpstop,gpstate and alternative utility logs.
Segments:Primary segments run below SQL to visualize log file location
- select db id,hostname,datadir||’/pg_log’ from gp_configuration wherever content not in (-1) and is primary is true;
Mirror Segments run below SQL to visualize log file location:
- select db id,hostname,datadir||’/pg_log’
13. The way to see the list of obtainable functions in Greenplum DB?
Ans:
- df schema name.function name (schemaname perform|and performance} name support wildcard characters)
- test=# df pub*.*test*
- List of operate
| Schema | Name | Result information kind |
|---|---|---|
| public | bugtest | number |
| public | check | mathematician |
| public | check | void |
14. The way to check whether or not Greenplum server is up and running?
Ans:
The gpstate is the utility to examine gp db standing.Use gpstate -Q to indicate a fast standing. confer with gpstate –help for additional choices.
Sample output:
- [gpadmin@stinger2]/export/home/gpadmin>gpstate -Q
- gpadmin-[INFO]:-Obtaining GPDB array kind, [Brief], please wait…
- gpadmin-[INFO]:-Obtaining GPDB array kind, [Brief], please wait…
- gpadmin-[INFO]:-Quick Greenplum info standing from Master instance solely
- gpadmin-[INFO]:———————————————————-
- gpadmin-[INFO]:-GPDB fault action worth = readonly
- gpadmin-[INFO]:-Valid count in standing read = four
- gpadmin-[INFO]:-Invalid count in standing read = zero
- gpadmin-[INFO]:———————————————————-
15. The way to recover the associate degree invalid segment?
Ans:
Without “-F ” choice – the primary files are going to be compared, the distinction found and solely totally different files are going to be synched (the -first stage may last a protracted time if there are too several files within the information directory). while not the “-F” choice – The modification trailing log is going to be sent and applied to the mirror.
With the “-F” choice – the whole information directory is going to be resynched. With the “-F” choice – the whole information directory is going to be resynched.
16. The way to produce a Database?
Ans:
There are 2 ways that to make a gpdb info mistreatment psql session or the Greenplum createdb utility:
Using p sql session:
- gpdb=# h produce the info
Command: Produce info
Description: Produce a replacement info
Syntax:
- CREATE info name [ [ WITH ] [ OWNER [=] db_owner ] [ templet [=] templet ] [ secret writing [=] secret writing ] [
- TABLESPACE [=] tablespace ] [ affiliation LIMIT [=] connlimit ] ] mistreatment create db utility:
- Usage: $GPHOME/bin/createdb –help
- createdb [OPTION]… [DBNAME] [DESCRIPTION]
Options:
- -D, –tablespace=TABLESPACE default tablespace for the info
- -E, –encoding=ENCODING secret writing for the info
- -O, –owner=OWNER info user to possess the new info
- -T, –template=TEMPLATE templet info to repeat
17. However, do I purchase a listing of databases during a Greenplum cluster?
Ans:
- gpdb=# l (lowercase letter “l”)
List of databases
| Name | Owner | Secret writing |
|---|---|---|
| gp db | gp admin | UTF8 |
| P perfmon | gp admin | UTF8 |
| postgres | gp admin | UTF8 |
| template0 | gp admin | UTF8 |
| template1 | gp admin | UTF8 |
Check below SQL for additional details on dbs.
- gpdb=# choose * from pg_database;
18. The way to delete/drop associate degree existing info in Greenplum?
Ans:
- gpdb=# h DROP info
- Command: DROP info
- Description: take away a info
- Syntax:DROP info [ IF EXISTS ] name
- Also check drop db utility:
- $GPHOME/bin/dropdb –help
- drop db removes PostgreSQL info.
- Usage:
- dropdb [OPTION]… DBNAME
19. Where am I able to get assistance on Postgres p sql commands?
Ans:
In p sql session
- “ ?” – for all pl sql session facilitate
- “h ” For any SQL syntax.
20. What’s the greenplum database?
Ans:
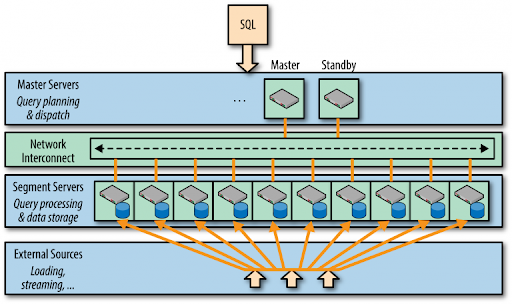
21. gpstart unsuccessful what ought to I do?
Ans:
- Check upstart log come in ~pgadmin/gpAdminLogs/gpstart_yyyymmdd.log
- Take a glance at the pg begin log file for a lot of details in
- $MASTER_DATA_DIRECTORY/pg_log/startup.log
22. Why would we like gp stop -m and gpstart -m?
Ans:
The gpstart -m command permits you to begin the master solely and with none of the info segments and is employed primarily by support to induce system level information/configuration. associate users wouldn’t often or maybe commonly use it.
23. What’s the procedure to induce elimination of mirror segments?
Ans:
There aren’t any utilities on the market to get rid of mirrors from Greenplum. you would like to create positive all primary segments square measure smart then you’ll take away the mirror configuration from gp_configuration in three.x.
24. A way to run gp checkcat?
Ans:
The gp checkcat tool is employed to envision catalog inconsistencies between master and segments. It may be found within the $GPHOME/bin/lib directory:
- Usage: gp checkcat
- [db name]
- -?
- -B parallel: variety of employee threads
- -g dir : generate SQL to rectify catalog corruption, place it in dir
- -h host : decibel hostname
- -p port : decibel port variety
- -P passwd : decibel parole
- -o : check OID consistency
- -U uname : decibel User Name
- -v : long-winded
Example:
- gp checkcat gp db >gpcheckcat_gpdb_logfile.
25. What’s the distinction between pg_dump and gp_dump?
Ans:
| pg_ dump | gp_ dump |
|---|---|
| pg_dump – Non-parallel backup utility, you would like an enormous filing system wherever the backup is created within the master node solely. | gp_dump – Parallel backup utility. The backups are created within the master and segments filing system. |
26. What’s a medico detective and the way I run it in Greenplum?
Ans:
The detective utility collects data from a running Greenplum information system and creates a bzip2-compressed tar computer file. This computer file helps with the designation of Greenplum information errors or system failures. for a lot of details check facilitation. medico detective –help
27. A way to delete a standby?
Ans:
To remove the presently designed standby master host from your Greenplum information system, run the subsequent command within the master only: # gpinitstandby -r
28. A way to re-sync a standby?
Ans:
Use this feature if you have already got a standby master designed, and simply wish to resynchronize the info between the first and backup master host. The Greenplum system catalog tables won’t be updated. # gpinitstandby -n (resynchronize).
29. A way to add mirrors to the array?
Ans:
The gp add mirrors utility configures mirror phase instances to associate existing Greenplum information system that was at first designed with primary phase instances solely.
For a lot of details check facilitation.
- # gp add mirrors –help
30. Outline Greenplum end point architecture?
Ans:
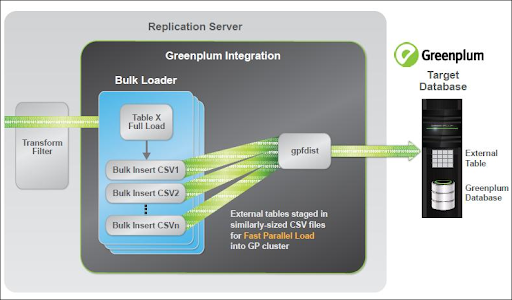
31. A way to see primary to mirror mapping?
Ans:
From the information catalog following question list configuration on content ID, you’ll find out primary and mirror for every content.
gpdb=# choose * from gp_configuration order by content. Note: ranging from GPDB four.x, gp_segment_configuration table is employed instead. gpdb=# choose * from gp_segment_configuration order by db id;
32. A way to run gp checkperf IO/netperf?
Ans:
Create a directory wherever you have got free area and customary altogether hosts.
For network I/O check for every nic card:
gp checkperf -f seg_host_file_nic-1 -r N -d /data/gpcheckperf > seg_host_file_nic_1.outgpcheckperf -f seg_host_file_nic-2 -r N -d /data/gpcheckperf > seg_host_file_nic_2.out
For disk I/O:
33. A way to update postgresql.conf and reload it?
Ans:
In GP 4.0 version check gp config utility to vary postgresql.conf parameters. In the 3.X version manually modify parameters in postgres.conf for a lot of details check Greenplum Administrator’s Guide.
34. A way to manage pg_hba.conf?
Ans:
The pg_hba.conf file of the master instance controls consumer access and authentication to your Greenplum system. Check Greenplum Administrator’s Guide for directions to add/change contents of this file.
35. However would you implement compression and probably justify the compression types?
Ans:
Table level Column level
Table-level compression is applied to a complete table. Column-level compression is applied to a particular column. you’ll apply completely different|completely different} column-level compression algorithms to different columns.
36. A way to add a replacement user to the database?
Ans:
- Use produce user utility to make users. See produce user –help for a lot of details.
- You can additionally use SQL commands in the p sql prompt to make users.
- For example: produce USER or ROLE
37. A way to produce a password-free sure env b/w all the phase hosts?
Ans:
Use gpssh-exkeys
38. A way to check decibel version and version at init DB?
Ans:
To check the version:
- P sql> choose version();
- or
- postgres –gp-version
- To check medico version at install:
- P sql> choose * from gp_version_at_initdb;
39. What’s a vacuum and once ought to I run this?
Ans:
VACUUM reclaims storage occupied by deleted tuples. In traditional GPDB operation, tuples that square measure deleted or obsoleted by associate update aren’t physically off from their table.
40. Associate introduction to greenplum?
Ans:
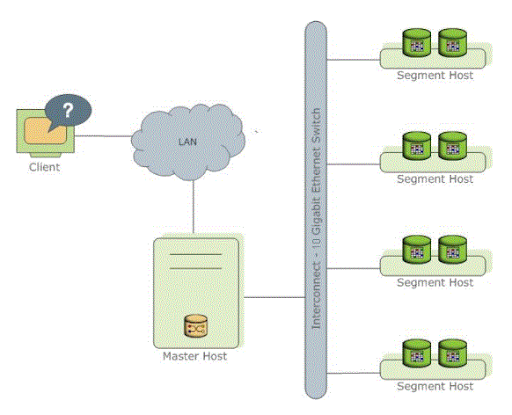
42. What square measure resource queues?
Ans:
Resource queues square measure accustomed to Greenplum information employment management. All user/queries may be prioritized victimization Resource queues. see Admin guide for a lot of details.
43. What’s gp_toolkit?
Ans:
The gp_toolkit could be an information_schema, that has several tables, views and functions to better manage Greenplum information once decibel is up. In 3.x earlier versions, it had been spoken as gp_jetpack.
44. What square measures the main variations between Oracle and Greenplum?
Ans:
Oracle could be an on-line database where as Greenplum is MPP nature.
45. Tell ME a number of the aspects/implementations/configurations you’ve got tired Greenplum?
Ans:
A configuration like port modification, Active directory authentication, pg_hba.conf changes, postgresql.conf changes, gp f dist, etc.
46. What parameters are you able to use to manage work in a very Greenplum database?
Ans:
Workload management is finished by making resource queues and assignment varied limits.
47. However would you troubleshoot AN issue/error/problem once there’s nobody on the market to assist you otherwise you area unit all by yourself?
Ans:
Look at the log files. querying the doctor perfmon and tools schema for varied knowledge and statistics.
48. What’s sensible and unhealthy concerning the Greenplum, compared to Oracle and Greenplum?
Ans:
Greenplum is constructed on the height of Postgresql. it’s a shared-nothing, MPP design best for knowledge storage env. sensible for giant knowledge analytics functions. Oracle is AN general-purpose info.
49. What’s greenplum text mining data?
Ans:
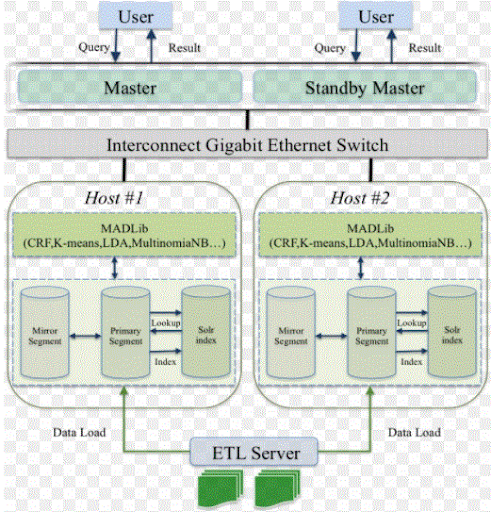
50. What would you be doing to assemble statistics within the database? yet to reclaim the space?
Ans:
VACUUM FULL, CTAS.
A VACUUM FULL can reclaim all expired row houses, however could be a terribly pricey operation and should take AN intolerably while to complete on giant, distributed Greenplum info tables.
A VACUUM FULL isn’t suggested in Greenplum info.
51. What would {you do|you area unit doing} once a user or users are protesting that a specific question is running slow?
Ans:
- Look at the question arrange
- Look at the network performance
- Look at the resource queues
- Look at the interconnect performance
- Look at the question itself i.e. if it are often written in a very additional economical manner
52. That choice would you employ to export the DDL of the info or table?
Ans:
s (-s | –schema-only Dump solely the article definitions (schema), not data.)
53. Once you restore from a backup taken from gp_dump, are you able to import a table?
Ans:
NO. affirmative if throughout the gp_dump you secured one table solely.
54. What’s the distinction Between Vacuum And Vacuum Full?
Ans:
Unless you wish to come back house to the OS in order that different tables or different components of the system will use that house, you ought to use VACUUM VACUUM FULL is barely required once you have a table that’s largely dead rows, that is, the overwhelming majority of its contents are deleted. Even then, there’s no purpose to mistreat VACUUM FULL.
55. My SQL question is running terribly slow. It absolutely was running fine yesterday. What ought to I do?
Ans:
- Check that your association to the Greenplum cluster remains smart if you’re employing a remote consumer. you’ll do that by running the SQL domestically to the MD cluster.
- Check that the system tables and user tables concerned aren’t distended or inclined. browse jetpack or Greenplum toolkit documentation concerning the way to do that.
- Check with your DBA that the Greenplum interconnect remains performing arts properly.
- This can be done by checking for born packets on the interconnect “netstat -i” and by running gp checkperf. it’s conjointly attainable that a section is experiencing hardware issues, which may be found within the output of d mesg or in.
- cd $MASTER_DATA_DIRECTORY – Master directory.
- cd $MASTER_DATA_DIRECTORY/pg_logs — Master
56. What are the backup choices offered at OS level?
Ans:
Solaris: zfs snapshots at the classification system level.
All OS: gp crondump / gp_dump.
class=”blog-title-4″>57. What’s gp crondump?
Ans:
Wrapper utility for gp_dump, which may be referred to as directly or from a crontab entry.
Example: gp crondump -x
58. However do I clone my production info to the PreProd / QA environment?
Ans:
- Prod and QA on identical GPDB clusters, use produce info model.
- If Prod and QA are on totally different clusters, use backup and restore utilities.
59. What’s the associate introduction Greenplum ETL Tool?
Ans:
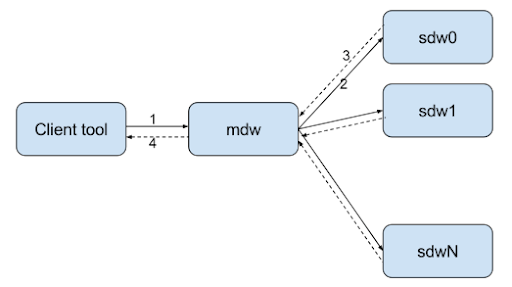
60. What are the tools offered in Greenplum to require backup and restores?
Ans:
For non-parallel backups: Another helpful command for obtaining knowledge out of the info is the COPY too.
For parallel backups: gp_dump and gp crondump for backups and gp_restore for restore method.
61. The way to generate DDL for a table?
Ans:
Use pg_dump utility to come up with DDL.
Example:
- pg_dump -t njonna.accounts -s -f ddl_accounts.sql
Where:
- -f ddl_accounts.sql is an associated computer file.
- -s dump solely schema no knowledge
62. What’s an MPP database?
Ans:
An MPP info may be a info that’s optimized to be processed in parallel several|for several} operations to be performed by many process units at a time. MPP (massively parallel process) is the coordinated processing of a program by multiple processors engaged on totally different elements of the program.
63. Is Hadoop a knowledge lake?
Ans:
To put it merely, Hadoop may be a technology that may be wont to build knowledge lakes. A knowledge lake is associated with design, whereas Hadoop may be a part of that design. In other words, Hadoop is the platform for knowledge lakes.
64. That library is employed by Greenplum for info analytics?
Ans:
Apache MADlib is an ASCII text file library for scalable in-database analytics. The Greenplum MADlib extension provides the flexibility to run machine learning and deep learning workloads in an exceedingly Greenplum info.
65. Will Greenplum store unstructured data?
Ans:
Pivotal Greenplum five.0 entails many enhancements for semi-structured/unstructured processing as well as the GPText extension, the JSON knowledge kind, and improved XML data type support.
66. What’s knowledge lake storage?
Ans:
A data lake may be a storage repository that holds a massive quantity of information in its native format till it’s required for analytics applications. whereas a standard knowledge warehouse stores knowledge in gradable dimensions and tables, {a knowledge|a knowledge|and information} lake uses a flat design to store data, primarily in files or object storage.
67. What sort of info is Greenplum?
Ans:
Greenplum info may be a massively data processing (MPP) info server with associate design specially designed to manage large-scale analytic knowledge warehouses and business intelligence workloads.
68. What’s Greenplum Hadoop?
Ans:
It is a massively data processing (MPP) info server with associate design specially designed to manage large-scale analytic knowledge warehouses and business intelligence workloads. It supported PostgreSQL ASCII text file technology.
69. What’s greenplum UAP components?
Ans:
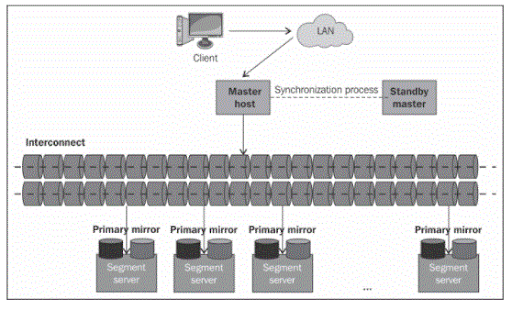
70. What’s the distinction between PostgreSQL and Greenplum?
Ans:
Greenplum is each a knowledge warehouse and transactional or operational data store. Greenplum as an info tool employs a shared-nothing design as compared to PostgreSQL.
71. What’s the position Of Pg_hba/logfile/master_data_directory?
Ans:
- cd $MASTER_DATA_DIRECTORY – Master directory.
- pg_hba.conf and postgres.conf location and totally different GPDB internal directories.
- cd $MASTER_DATA_DIRECTORY/pg_logs — Master info log files location
72. What are Greenplum Performance Monitor and also the thanks to Install?
Ans:
It is an observation tool that collects statistics on system and question performance and builds historical data.
73. Are you ready to justify the strategy of knowledge Migration From Oracle To Greenplum?
Ans:
Their unit of measurement in some ways. Simplest steps unit of measurement Unload data into csv files, manufacture tables in greenplum info comparable to Oracle, manufacture external table, begin gp f dist inform to external table location, Load data into greenplum. you’ll put together the gp load utility. transfer creates an external table at runtime.
74. What’s Multi-version control?
Ans:
Multi-version concurrency management or MVCC is employed to avoid spare protection of the info. This removes the postponement for the user to log into his info. This feature or postponement happens once somebody else is accessing the content. All transactions are unbroken as a record.
75. What are the new characteristics of PostgreSQL nine.1?
Ans:
During the method of changing the project, one will ne’er make certain that options can enter and which of them won’t build the cut. The project has precise and demanding standards for quality, and a few patches could or might not match them before the set point.
76. The way to activate temporal arrangement, And Checking what quantity Time a question Takes To Execute?
Ans:
- You can flip in temporal arrangement per session before you run your SQL with the temporal arrangement command.
- You can run justify analysis against your SQL statement to induce the temporal arrangement.
77. Is polar greenplum free?
Ans:
As mentioned throughout this post, Greenplum is AN open supply information therefore the community version is completely liberal to transfer and use.
78. The way to See the worth Of Guc?
Ans:
By connecting the GPDB information victimization p sql question catalog or do show parameters.
Example:
- gp db# choose name,setting from pg_settings wherever name=’GUC’;
- gp db# show
79. What’s greenplum physical architecture?
Ans:
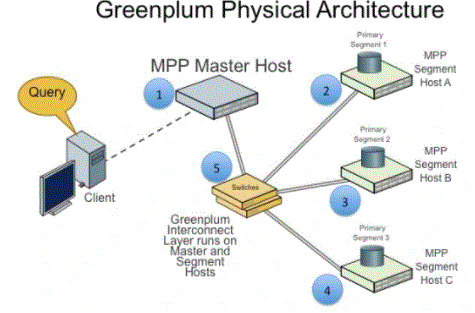
An external table may be a Greenplum information table backed with information that resides outside of the information. You produce a legible external table to scan information from the external information supply and build a writable external table to jot down information to the external supply.
80. What square measures external tables in Greenplum?
Ans:
An external table may be a Greenplum information table backed with information that resides outside of the information. You produce a legible external table to scan information from the external information supply and build a writable external table to jot down information to the external supply.
81. However, do I produce an external table in Greenplum?
Ans:
CREATE EXTERNAL net TABLE log_output (linenum int, message text) EXECUTE ‘/var/load_scripts/get_log_data.sh’ ON HOST FORMAT ‘TEXT’ (DELIMITER ‘|’); produce a writable external table named sales_out that uses gp f dist to jot down output information to a file named sales. out .
82. What’s Gpfdist in Greenplum?
Ans:
Gpf dist is Greenplum information parallel file distribution program. it’s utilized by legible external tables and gp load to serve external table files to any or all Greenplum information segments in parallel.