
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Apache Storm Tutorial
Last updated on 12th Oct 2020, Big Data, Blog, Tutorials
Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache Storm became a standard for distributed real-time processing system that allows you to process large amounts of data, similar to Hadoop. Apache Storm is written in Java and Clojure. It is continuing to be a leader in real-time analytics. This tutorial will explore the principles of Apache Storm, distributed messaging, installation, creating Storm topologies and deploy them to a Storm cluster, workflow of Trident, real-time applications and finally concludes with some useful examples.
What is Apache Storm?
Apache Storm is a distributed real-time big data-processing system. Storm is designed to process vast amounts of data in a fault-tolerant and horizontal scalable method. It is a streaming data framework that has the capability of highest ingestion rates. Though Storm is stateless, it manages distributed environment and cluster state via Apache ZooKeeper. It is simple and you can execute all kinds of manipulations on real-time data in parallel.
Apache Storm is continuing to be a leader in real-time data analytics. Storm is easy to set up, operate and it guarantees that every message will be processed through the topology at least once.
Apache Storm vs Hadoop
Basically Hadoop and Storm frameworks are used for analyzing big data. Both of them complement each other and differ in some aspects. Apache Storm does all the operations except persistency, while Hadoop is good at everything but lags in real-time computation. The following table compares the attributes of Storm and Hadoop.
| Storm | Hadoop |
|---|---|
| Real-time stream processing | Batch processing |
| Stateless | Stateful |
| Master/Slave architecture with ZooKeeper based coordination. The master node is called nimbus and slaves are supervisors. | Master-slave architecture with/without ZooKeeper based coordination. Master node is job tracker and slave node is task tracker. |
| A Storm streaming process can access tens of thousands messages per second on a cluster. | Hadoop Distributed File System (HDFS) uses the MapReduce framework to process vast amounts of data that takes minutes or hours. |
| Storm topology runs until shutdown by the user or an unexpected unrecoverable failure. | MapReduce jobs are executed in a sequential order and completed eventually. |
| Both are distributed and fault-tolerant | – |
| If nimbus / supervisor dies, restarting makes it continue from where it stopped, hence nothing gets affected. | If the JobTracker dies, all the running jobs are lost. |
Use-Cases of Apache Storm
Apache Storm is very famous for real-time big data stream processing. For this reason, most of the companies are using Storm as an integral part of their system. Some notable examples are as follows −
- Twitter − Twitter is using Apache Storm for its range of “Publisher Analytics products”. “Publisher Analytics Products” process each and every tweet and click in the Twitter Platform. Apache Storm is deeply integrated with Twitter infrastructure.
- NaviSite − NaviSite is using Storm for Event log monitoring/auditing system. Every log generated in the system will go through the Storm. Storm will check the message against the configured set of regular expressions and if there is a match, then that particular message will be saved to the database.
- Wego − Wego is a travel metasearch engine located in Singapore. Travel related data comes from many sources all over the world with different timing. Storm helps Wego to search real-time data, resolve concurrency issues and find the best match for the end-user.
Subscribe For Free Demo
Error: Contact form not found.
Apache Storm Benefits
Here is a list of the benefits that Apache Storm offers −
- 1. Storm is open source, robust, and user friendly. It could be utilized in small companies as well as large corporations.
- 2. Storm is fault tolerant, flexible, reliable, and supports any programming language.
- 3. Allows real-time stream processing.
- 4. Storm is unbelievably fast because it has enormous power of processing the data.
- 5. Storm can keep up the performance even under increasing load by adding resources linearly. It is highly scalable.
- 6. Storm performs data refresh and end-to-end delivery response in seconds or minutes depends upon the problem. It has very low latency.
- 7. Storm has operational intelligence.
- 8. Storm provides guaranteed data processing even if any of the connected nodes in the cluster die or messages are lost.
Apache Storm – Core Concepts
Apache Storm reads a raw stream of real-time data from one end and passes it through a sequence of small processing units and outputs the processed / useful information at the other end.
The following diagram depicts the core concept of Apache Storm.
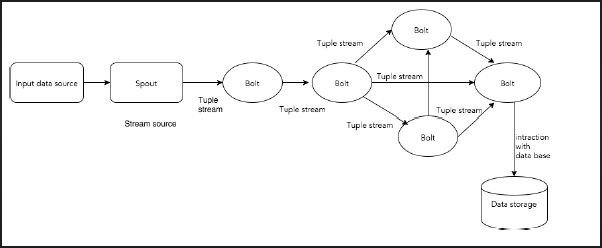
Let us now have a closer look at the components of Apache Storm −
| Components | Description |
|---|---|
| Tuple | Tuple is the main data structure in Storm. It is a list of ordered elements. By default, a Tuple supports all data types. Generally, it is modelled as a set of comma separated values and passed to a Storm cluster. |
| Stream | Stream is an unordered sequence of tuples. |
| Spouts | Source of stream. Generally, Storm accepts input data from raw data sources like Twitter Streaming API, Apache Kafka queue, Kestrel queue, etc. Otherwise you can write spouts to read data from data sources. “ISpout” is the core interface for implementing spouts. Some of the specific interfaces are IRichSpout, BaseRichSpout, KafkaSpout, etc. |
| Bolts | Bolts are logical processing units. Spouts pass data to bolts and bolts process and produce a new output stream. Bolts can perform the operations of filtering, aggregation, joining, interacting with data sources and databases. Bolt receives data and emits to one or more bolts. “IBolt” is the core interface for implementing bolts. Some of the common interfaces are IRichBolt, IBasicBolt, etc. |
Topology
Spouts and bolts are connected together and they form a topology. Real-time application logic is specified inside Storm topology. In simple words, a topology is a directed graph where vertices are computed and edges are streams of data.
A simple topology starts with spouts. Spout emits the data to one or more bolts. Bolt represents a node in the topology having the smallest processing logic and the output of a bolt can be emitted into another bolt as input.
Storm keeps the topology always running, until you kill the topology. Apache Storm’s main job is to run the topology and will run any number of topologies at a given time.
Tasks
Now you have a basic idea on spouts and bolts. They are the smallest logical unit of the topology and a topology is built using a single spout and an array of bolts. They should be executed properly in a particular order for the topology to run successfully. The execution of each and every spout and bolt by Storm is called as “Tasks”. In simple words, a task is either the execution of a spout or a bolt. At a given time, each spout and bolt can have multiple instances running in multiple separate threads.
Workers
A topology runs in a distributed manner, on multiple worker nodes. Storm spreads the tasks evenly on all the worker nodes. The worker node’s role is to listen for jobs and start or stop the processes whenever a new job arrives.
Stream Grouping
Streams of data flow from spouts to bolts or from one bolt to another bolt. Stream grouping controls how the tuples are routed in the topology and helps us to understand the tuples flow in the topology. There are four in-built groupings as explained below.
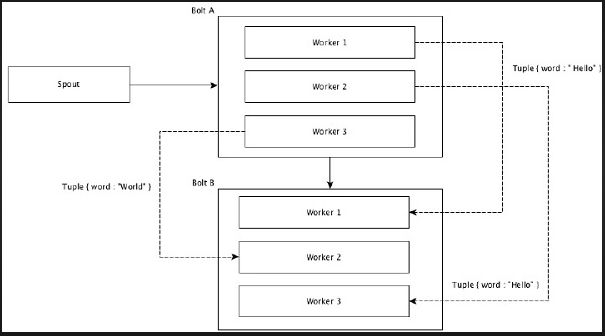
Shuffle Grouping
In shuffle grouping, an equal number of tuples is distributed randomly across all of the workers executing the bolts. The following diagram depicts the structure.
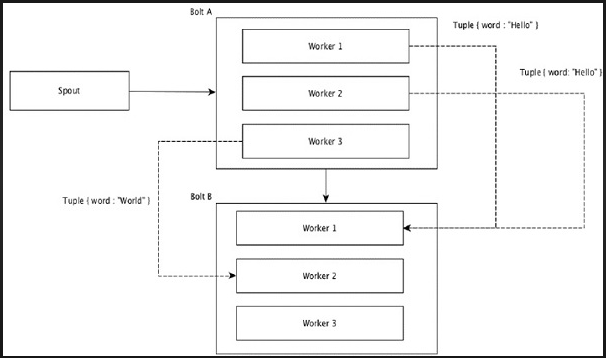
Field Grouping
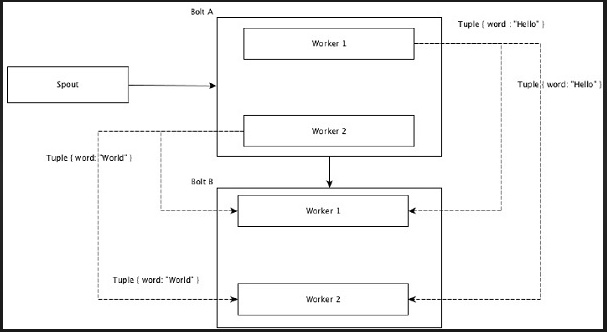
The fields with the same values in tuples are grouped together and the remaining tuples kept outside. Then, the tuples with the same field values are sent forward to the same worker executing the bolts. For example, if the stream is grouped by the field “word”, then the tuples with the same string, “Hello” will move to the same worker. The following diagram shows how Field Grouping works.
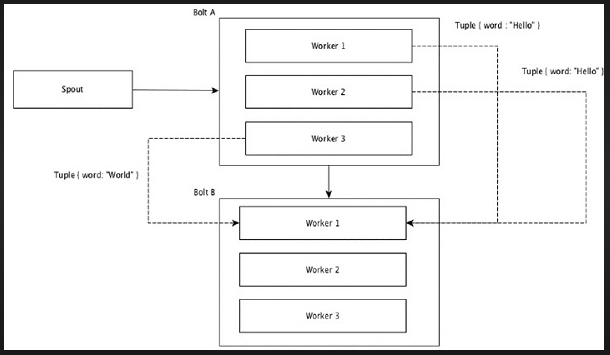
Global Grouping
All the streams can be grouped and forward to one bolt. This grouping sends tuples generated by all instances of the source to a single target instance (specifically, pick the worker with lowest ID).
All Grouping
All Grouping sends a single copy of each tuple to all instances of the receiving bolt. This kind of grouping is used to send signals to bolts. All grouping is useful for join operations.
Apache Storm – Cluster Architecture
One of the main highlights of the Apache Storm is that it is a fault-tolerant, fast with no “Single Point of Failure” (SPOF) distributed application. We can install Apache Storm in as many systems as needed to increase the capacity of the application.
Let’s have a look at how the Apache Storm cluster is designed and its internal architecture. The following diagram depicts the cluster design.
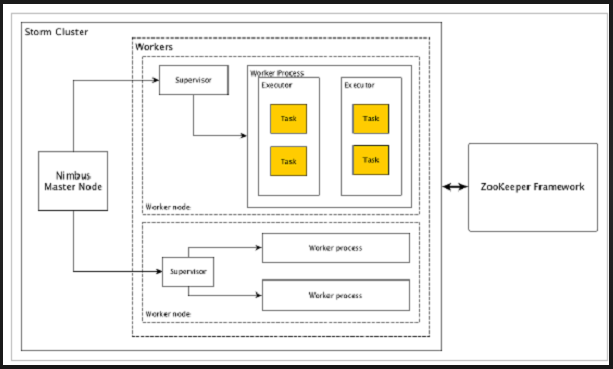
Apache Storm has two types of nodes, Nimbus (master node) and Supervisor (worker node). Nimbus is the central component of Apache Storm. The main job of Nimbus is to run the Storm topology. Nimbus analyzes the topology and gathers the task to be executed. Then, it will distribute the task to an available supervisor.
A supervisor will have one or more worker processes. Supervisor will delegate the tasks to worker processes. Worker process will spawn as many executors as needed and run the task. Apache Storm uses an internal distributed messaging system for the communication between nimbus and supervisors.

Get On-Demand Apache Storm Training to Build Your Skills & Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
| Components | Description |
|---|---|
| Nimbus | Nimbus is a master node of the Storm cluster. All other nodes in the cluster are called worker nodes. Master node is responsible for distributing data among all the worker nodes, assigning tasks to worker nodes and monitoring failures. |
| Supervisor | The nodes that follow instructions given by the nimbus are called as Supervisors. A supervisor has multiple worker processes and it governs worker processes to complete the tasks assigned by the nimbus. |
| Worker process | A worker process will execute tasks related to a specific topology. A worker process will not run a task by itself, instead it creates executors and asks them to perform a particular task. A worker process will have multiple executors. |
| Executor | An executor is nothing but a single thread spawn by a worker process. An executor runs one or more tasks but only for a specific spout or bolt. |
| Task | A task performs actual data processing. So, it is either a spout or a bolt. |
| ZooKeeper framework | Apache ZooKeeper is a service used by a cluster (group of nodes) to coordinate between themselves and maintain shared data with robust synchronization techniques. Nimbus is stateless, so it depends on ZooKeeper to monitor the working node status.ZooKeeper helps the supervisor to interact with the nimbus. It is responsible to maintain the state of nimbus and supervision. |
Storm is stateless in nature. Even though stateless nature has its own disadvantages, it actually helps Storm to process real-time data in the best possible and quickest way.
Storm is not entirely stateless though. It stores its state in Apache ZooKeeper. Since the state is available in Apache ZooKeeper, a failed nimbus can be restarted and made to work from where it left. Usually, service monitoring tools like monit will monitor Nimbus and restart it if there is any failure.
Apache Storm also has an advanced topology called Trident Topology with state maintenance and it also provides a high-level API like Pig. We will discuss all these features in the coming chapters.
Apache Storm – Workflow
A working Storm cluster should have one nimbus and one or more supervisors. Another important node is Apache ZooKeeper, which will be used for the coordination between the nimbus and the supervisors.
Let us now take a close look at the workflow of Apache Storm −
- 1. Initially, the nimbus will wait for the “Storm Topology” to be submitted to it.
- 2. Once a topology is submitted, it will process the topology and gather all the tasks that are to be carried out and the order in which the task is to be executed.
- 3. Then, the nimbus will evenly distribute the tasks to all the available supervisors.
- 4. At a particular time interval, all supervisors will send heartbeats to the nimbus to inform that they are still alive.
- 5. When a supervisor dies and doesn’t send a heartbeat to the nimbus, then the nimbus assigns the tasks to another supervisor.
- 6. When the nimbus itself dies, supervisors will work on the already assigned task without any issue.
- 7. Once all the tasks are completed, the supervisor will wait for a new task to come in.
- 8. In the meantime, the dead nimbus will be restarted automatically by service monitoring tools.
- 9. The restarted nimbus will continue from where it stopped. Similarly, the dead supervisor can also be restarted automatically. Since both the nimbus and the supervisor can be restarted automatically and both will continue as before, Storm is guaranteed to process all the tasks at least once.
- 10. Once all the topologies are processed, the nimbus waits for a new topology to arrive and similarly the supervisor waits for new tasks.
By default, there are two modes in a Storm cluster −
- Local mode − This mode is used for development, testing, and debugging because it is the easiest way to see all the topology components working together. In this mode, we can adjust parameters that enable us to see how our topology runs in different Storm configuration environments. In Local mode, storm topologies run on the local machine in a single JVM.
- Production mode − In this mode, we submit our topology to the working storm cluster, which is composed of many processes, usually running on different machines. As discussed in the workflow of storm, a working cluster will run indefinitely until it is shut down.
Storm – Distributed Messaging System
Apache Storm processes real-time data and the input normally comes from a message queuing system. An external distributed messaging system will provide the input necessary for the realtime computation. Spout will read the data from the messaging system and convert it into tuples and input into the Apache Storm. The interesting fact is that Apache Storm uses its own distributed messaging system internally for the communication between its nimbus and supervisor.
What is a Distributed Messaging System?
Distributed messaging is based on the concept of reliable message queuing. Messages are queued asynchronously between client applications and messaging systems. A distributed messaging system provides the benefits of reliability, scalability, and persistence.
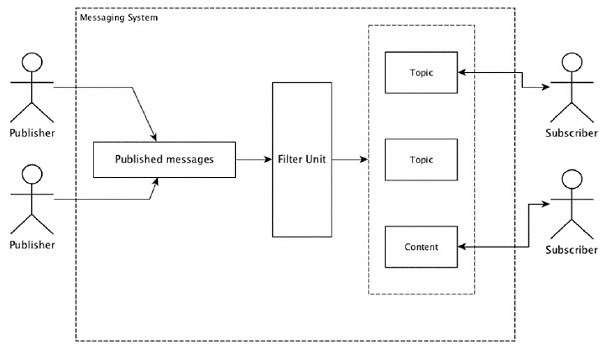
Most of the messaging patterns follow the publish-subscribe model (simply Pub-Sub) where the senders of the messages are called publishers and those who want to receive the messages are called subscribers.
Once the message has been published by the sender, the subscribers can receive the selected message with the help of a filtering option. Usually we have two types of filtering, one is topic-based filtering and another one is content-based filtering.
Note that the pub-sub model can communicate only via messages. It is a very loosely coupled architecture; even the senders don’t know who their subscribers are. Many of the message patterns enable message brokers to exchange published messages for timely access by many subscribers. A real-life example is Dish TV, which publishes different channels like sports, movies, music, etc., and anyone can subscribe to their own set of channels and get them whenever their subscribed channels are available.
The following table describes some of the popular high throughput messaging systems −
| Distributed messaging system | Description |
|---|---|
| Apache Kafka | Kafka was developed at LinkedIn corporation and later it became a sub-project of Apache. Apache Kafka is based on brokerenabled, persistent, distributed publish-subscribe model. Kafka is fast, scalable, and highly efficient. |
| RabbitMQ | RabbitMQ is an open source distributed robust messaging application. It is easy to use and runs on all platforms. |
| JMS(Java Message Service) | JMS is an open source API that supports creating, reading, and sending messages from one application to another. It provides guaranteed message delivery and follows the publish-subscribe model. |
| ActiveMQ | ActiveMQ messaging system is an open source API of JMS. |
| ZeroMQ | ZeroMQ is broker-less peer-peer message processing. It provides push-pull, router-dealer message patterns. |
| Kestrel | Kestrel is a fast, reliable, and simple distributed message queue. |
Thrift Protocol
Thrift was built at Facebook for cross-language services development and remote procedure call (RPC). Later, it became an open source Apache project. Apache Thrift is an Interface Definition Language and allows to define new data types and services implementation on top of the defined data types in an easy manner.
Apache Thrift is also a communication framework that supports embedded systems, mobile applications, web applications, and many other programming languages. Some of the key features associated with Apache Thrift are its modularity, flexibility, and high performance. In addition, it can perform streaming, messaging, and RPC in distributed applications.
Storm extensively uses Thrift Protocol for its internal communication and data definition. Storm topology is simply Thrift Structs. Storm Nimbus that runs the topology in Apache Storm is a Thrift service.

Learn Practical Oriented Apache Storm Training & Certification Course from Real Time Experts
Weekday / Weekend BatchesSee Batch DetailsInstalling Storm in a Single Node Cluster
- For installing Storm, you need to have Zookeeper in your single node cluster. So, let’s start with the installation of Zookeeper.
Zookeeper Installation
Step 1: Download Zookeeper from the below link:
Step 2: After downloading, untar it by using the command.
- tar -xvzf zookeeper-3.4.6.tar.gz
Step 3: Now, create a directory for storing the Zookeeper data, as it needs to store the PID’s of the processes that are running. Here we have created the folder with the name zookeeper in the zookeeper-3.4.6 directory.
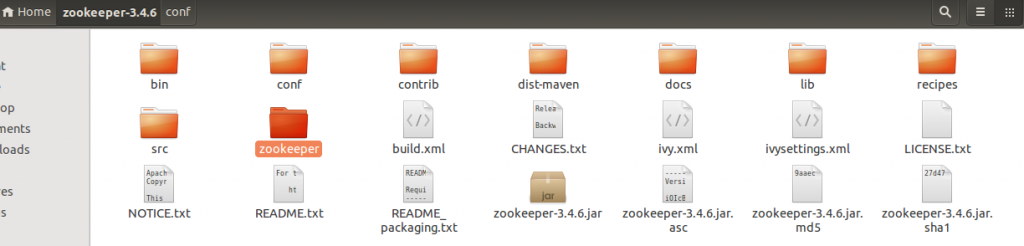
Step 4: Next, move into the conf folder of the installed Zookeeper and copy the zoo_sample.cfg file as zoo.cfg using the command,
- cp zoo_sample.cfg zoo.cfg
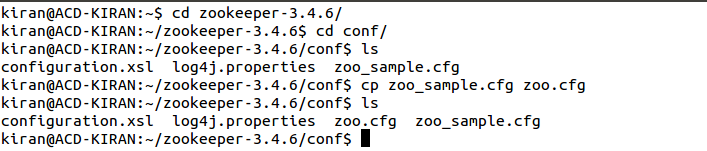
- Now, open the zoo.cfg and give the path of the directory created for storing zookeeper’s data. You can refer to the below screenshot for the same.
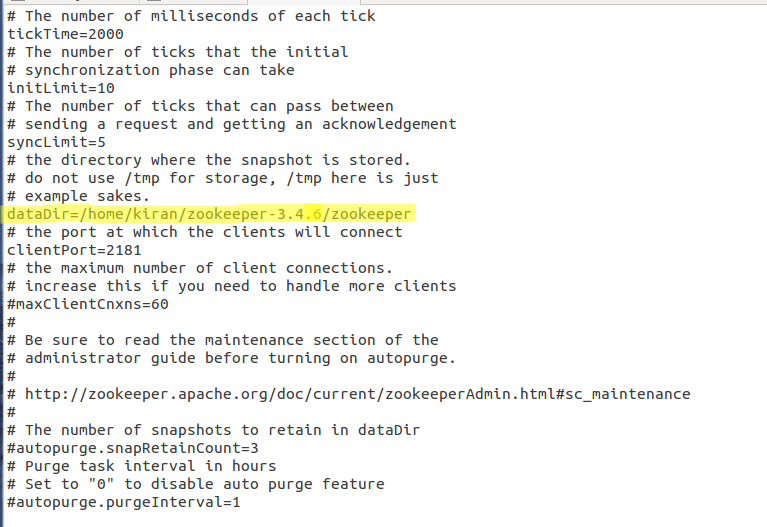
- We are done! We have successfully installed the Zookeeper service in your single node Hadoop cluster.
- Let’s now export the path of Zookeeper into a bashrc file. Move into your home directory using cd command and open the bashrc file using the command gedit .bashrc and type the below lines in the bashrc file.
- #set Zookeeper home
- export ZOOKEEPER_HOME=/home/kiran/zookeeper-3.4.6[Here you should give the path of the installed zookeeper directory]
- export PATH=$PATH:$ZOOKEEPER_HOME/bin
- After adding the lines, close and save the file.
- Now, source the file using the command source .bashrc.

Step 5: Start the Zookeeper service by typing the command,
- ZkServer.sh start
Now, let’s move on to the installation of Storm.
Storm Installation:
Step 1: Download Storm from the below link:
Step 2: After downloading, untar it by using the below command:
- tar -xvzf apache-storm-1.0.1.tar.gz
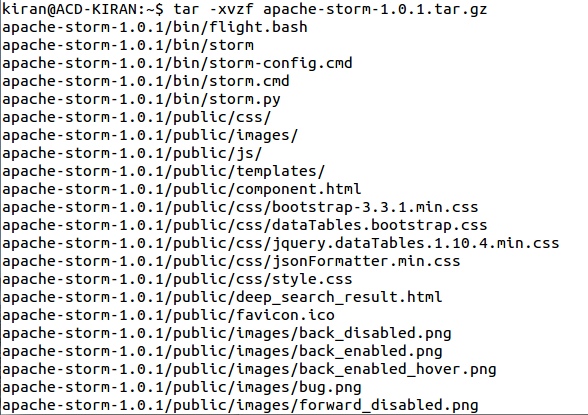
Step 3: Now, create a folder in the location of your choice, for storing the Storm data. We have created a folder in the apache-storm-1.0.1 directory itself.
Step 4: Now, move into the conf folder and open the storm.yaml file and add the below specified properties. Before that please note that in the storm.local.dir you need to give the path of the directory created for storing Storm data.
storm.zookeeper.servers:
- 1. “localhost”
- 2. storm.local.dir:”/home/kiran/apache-storm-1.0.1/data”[Here you need to give the unrated apache-storm-1.0.1 directory]
- 3. nimbus.host: “localhost”
- 4. supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 5. After adding these properties, close and save the file.
Step 5: Now open the bashrc file from your home directory and export the path for Storm. Add the below lines in your bashrc file.
- #set Storm home
- export STORM_HOME=/home/kiran/apache-storm-1.0.1
- export PATH=$PATH:$STORM_HOME/bin
- After adding the lines, close and save the file.
- Next, source the file using the command source .bashrc.

Step 6: Start the Storm services using the below commands.As like a Hadoop cluster, storm cluster also has two kinds of nodes
1.Master Node
2.Worker Nodes
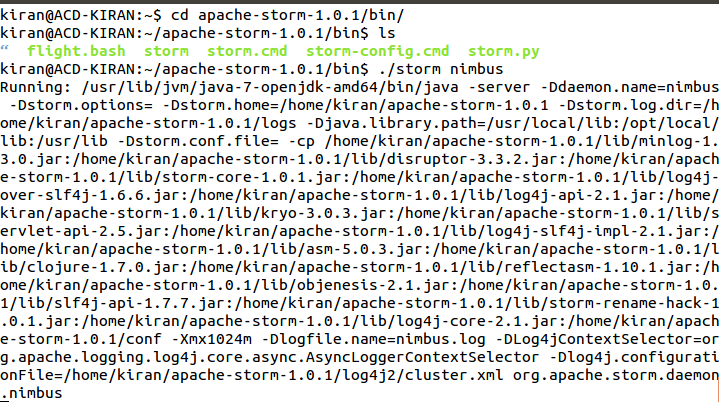
- 1. The master node runs a daemon called “Nimbus” that is similar to Hadoop’s “Job Tracker”. Nimbus is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures.
- 2. To Start storm nimbus, open a new terminal and move into the bin directory of installed Storm and type the command.
- ./storm nimbus
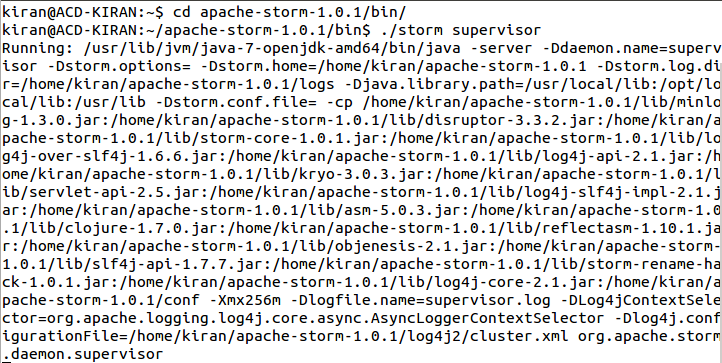
- Each worker node runs a daemon called the “Supervisor”. The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it.
- To start the Storm supervisor, open a new terminal and move into the bin directory of the installed Storm and type the command.
- ./storm supervisor
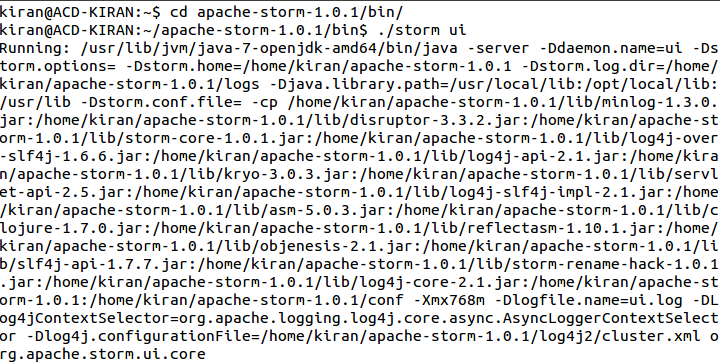
- Storm jobs can be traced using its web interface. Storm provides a web user interface from the default port 8080.
- To start the Storm UI, open a new terminal and move into the bin directory of installed Storm and type the command,
- ./storm ui
- Now, you can check the Storm services running by using the jps command. You can refer to the below screenshot for the same.
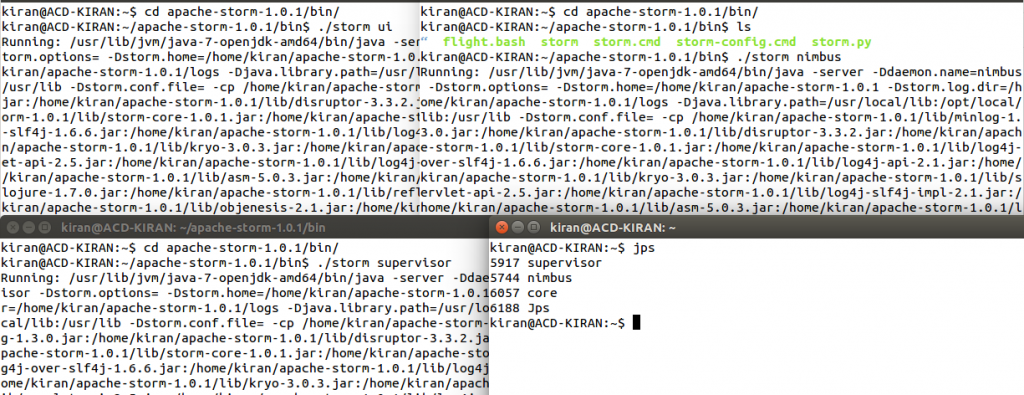
- You can also check the status of your Storm cluster by using the UI. For that, open any web browser and type localhost:8080, where 8080 is the port where Storm is running. You can check the status of your Storm using the web UI. You can refer to the below screenshot for the same.
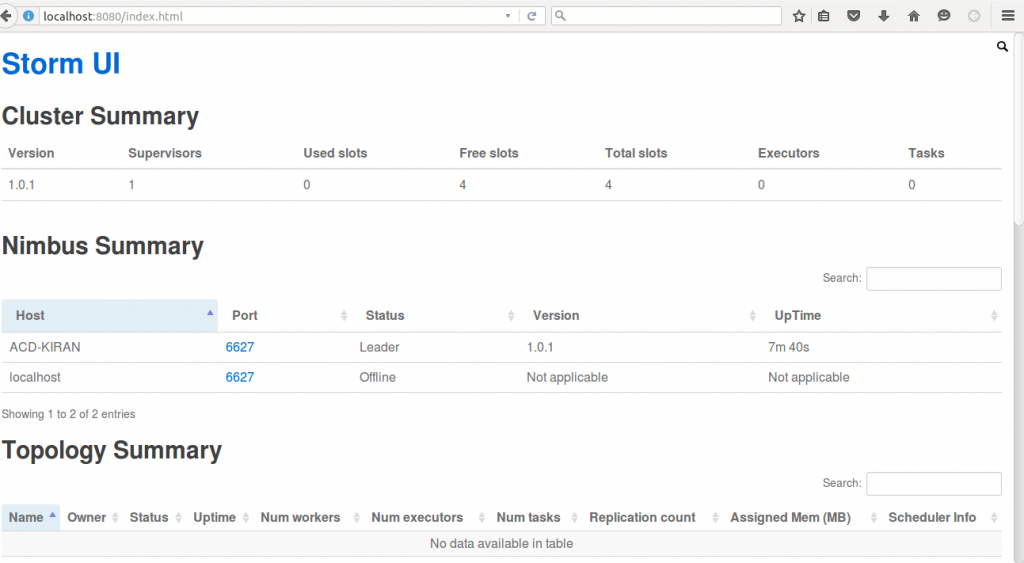
- In the above screen shot, we can see the web UI of Storm in a single node cluster..
Features of Storm
- 1. Fast: Storm has been reported to process up to 1 million tuples per second per node.
- 2. Horizontally scalable: Being fast is a necessary feature to build a high volume/velocity data processing platform, but a single-node will have an upper limit on the number of events that it can process per second. A node represents a single machine in your setup that executes Storm applications. Storm, being a distributed platform, allows you to add more nodes to your Storm cluster and increase the processing capacity of your application. Also, it is linearly scalable, which means that you can double the processing capacity by doubling the nodes.
- 3. Fault tolerant: Units of work are executed by worker processes in a Storm cluster. When a worker dies, Storm will restart that worker, and if the node on which the worker is running dies, Storm will restart that worker on some other node in the cluster. The description of the worker process is mentioned in the Configuring the parallelism of a topology section of, Setting Up a Storm Cluster.
- 4. Guaranteed data processing: Storm provides strong guarantees that each message passed on to it to process will be processed at least once. In the event of failures, Storm will replay the lost tuples. Also, it can be configured so that each message will be processed only once.
- 5. Easy to operate: Storm is simple to deploy and manage. Once the cluster is deployed, it requires little maintenance.
- 6. Programming language agnostic: Even though the Storm platform runs on Java Virtual Machine, the applications that run over it can be written in any programming language that can read and write to standard input and output streams.
Properties of Storm
- 1. Simple to program: If you’ve ever tried doing real-time processing from scratch, you’ll understand how painful it can become. With Storm, complexity is dramatically reduced.
- 2. Support for multiple programming languages: It’s easier to develop in a JVM-based language, but Storm supports any language as long as you use or implement a small intermediary library.
- 3. Fault-tolerant: The Storm cluster takes care of workers going down, reassigning tasks when necessary.
- 4. Scalable: All you need to do in order to scale is add more machines to the cluster. Storm will reassign tasks to new machines as they become available.
- 5. Reliable: All messages are guaranteed to be processed at least once. If there are errors, messages might be processed more than once, but you’ll never lose any message.
- 6. Fast: Speed was one of the key factors driving Storm’s design.
- 7. Transactional: You can get exactly once messaging semantics for pretty much any computation.
Advantages:
- Apache Storm is a highly real-time analysis platform and hence permits real-time processing.
- It is open-source and user-friendly so incorporated with small and high industries.
- It is high-speedy, valid and generates genuine and authentic results.
- It has the operational potential of intelligence and strong capacity for processing.
- It can absorb vast volume and giant velocity of data so much compatible with big datasets.
- It is attainable, flexible and assists any programming language
Conclusion:
The storm is a free and open source distributed real-time computation framework written in Clojure programming language. Apache storm is an advanced big data processing engine that processes real-time streaming data at an unprecedented (never done or known before) Speed, which is faster than Apache Hadoop.