
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Spark And RDD Cheat Sheet Tutorial
Last updated on 12th Oct 2020, Big Data, Blog, Tutorials
Apache Spark is an open-source cluster computing framework. Its primary purpose is to handle the real-time generated data.Spark was built on the top of the Hadoop MapReduce. It was optimized to run in memory whereas alternative approaches like Hadoop’s MapReduce writes data to and from computer hard drives. So, Spark processes the data much quicker than other alternatives.
Why Spark?
As we know, there was no general purpose computing engine in the industry, since
- To perform batch processing, we were using Hadoop MapReduce.
- Also, to perform stream processing, we were using Apache Storm / S4.
- Moreover, for interactive processing, we were using Apache Impala / Apache Tez.
- To perform graph processing, we were using Neo4j / Apache Giraph.
Hence there was no powerful engine in the industry, that can process the data both in real-time and batch mode. Also, there was a requirement that one engine can respond in sub-second and perform in-memory processing.
Therefore, Apache Spark programming enters, it is a powerful open source engine. Since, it offers real-time stream processing, interactive processing, graph processing, in-memory processing as well as batch processing. Even with very fast speed, ease of use and standard interface. Basically, these features create the difference between Hadoop and Spark. Also makes a huge comparison between Spark vs Storm.
Features of Apache Spark
1.Fast
It provides high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
2.Easy to Use
It facilitates writing applications in Java, Scala, Python, R, and SQL. It also provides more than 80 high-level operators.
3.Generality
It provides a collection of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming.
4.Lightweight
It is a light unified analytics engine which is used for large scale data processing.
Runs Everywhere – It can easily run on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud.
Uses of Spark
1.Data integration:
The data generated by systems are not consistent enough to combine for analysis. To fetch consistent data from systems we can use processes like Extract, transform, and load (ETL). Spark is used to reduce the cost and time required for this ETL process.
2.Stream processing:
It is always difficult to handle the real-time generated data such as log files. Spark is capable enough to operate streams of data and refuses potentially fraudulent operations.
3.Machine learning:
Machine learning approaches become more feasible and increasingly accurate due to enhancement in the volume of data. As spark is capable of storing data in memory and can run repeated queries quickly, it makes it easy to work on machine learning algorithms.
4.Interactive analytics:
Spark is able to generate responses rapidly. So, instead of running pre-defined queries, we can handle the data interactively.
5.Apache Spark Components
In this Apache Spark Tutorial, we discuss Spark Components. It puts the promise for faster data processing as well as easier development. It is only possible because of its components. All these Spark components resolved the issues that occurred while using Hadoop MapReduce.
Now let’s discuss each Spark Ecosystem Component one by one-
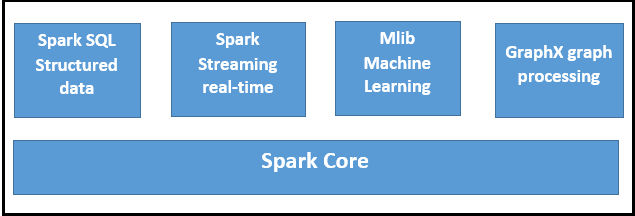
Apache Spark Ecosystem Components
a.Spark Core
Spark Core is a central point of Spark. Basically, it provides an execution platform for all the Spark applications. Moreover, to support a wide array of applications, Spark Provides a generalized platform.
b.Spark SQL
On the top of Spark, Spark SQL enables users to run SQL/HQL queries. We can process structured as well as semi-structured data, by using Spark SQL. Moreover, it offers to run unmodified queries up to 100 times faster on existing deployments. To learn Spark SQL in detail, follow this link.
Subscribe For Free Demo
Error: Contact form not found.
c.Spark Streaming
Basically, across live streaming, Spark Streaming enables a powerful interactive and data analytics application. Moreover, the live streams are converted into micro-batches that are executed on top of spark cores. Learn Spark Streaming in detail.
d.Spark MLlib
Machine learning library delivers both efficiencies as well as the high-quality algorithms. Moreover, it is the hottest choice for a data scientist. Since it is capable of in-memory data processing, that improves the performance of iterative algorithms drastically.
e.Spark GraphX
Basically, Spark GraphX is the graph computation engine built on top of Apache Spark that enables to process graph data at scale.
f.SparkR
Basically, to use Apache Spark from R. It is an R package that gives a light-weight frontend. Moreover, it allows data scientists to analyze large datasets. Also allows running jobs interactively on them from the R shell. Although, the main idea behind SparkR was to explore different techniques to integrate the usability of R with the scalability of Spark. Follow the link to learn SparkR in detail.
Spark Architecture
The Spark follows the master-slave architecture. Its cluster consists of a single master and multiple slaves.
The Spark architecture depends upon two abstractions:
- Resilient Distributed Dataset (RDD)
- Directed Acyclic Graph (DAG)
Resilient Distributed Datasets (RDD)
The Resilient Distributed Datasets are the group of data items that can be stored in-memory on worker nodes. Here,
- Resilient: Restore the data on failure.
- Distributed: Data is distributed among different nodes.
- Dataset: Group of data.
Directed Acyclic Graph (DAG)
Directed Acyclic Graph is a finite directed graph that performs a sequence of computations on data. Each node is an RDD partition, and the edge is a transformation on top of data. Here, the graph refers to navigation whereas directed and acyclic refers to how it is done.
Let’s understand the Spark architecture.
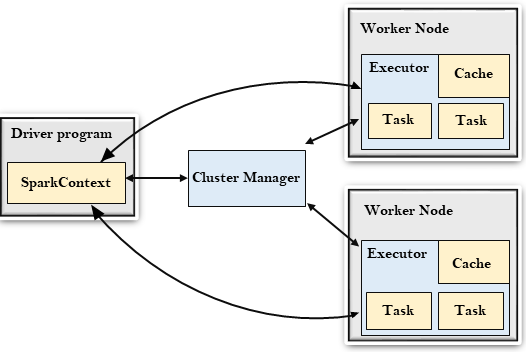
Driver Program
The Driver Program is a process that runs the main() function of the application and creates the SparkContext object. The purpose of SparkContext is to coordinate the spark applications, running as independent sets of processes on a cluster.
To run on a cluster, the SparkContext connects to a different type of cluster managers and then perform the following tasks: –
- It acquires executors on nodes in the cluster.
- Then, it sends your application code to the executors. Here, the application code can be defined by JAR or Python files passed to the SparkContext.
- At last, the SparkContext sends tasks to the executors to run.
Cluster Manager
- The role of the cluster manager is to allocate resources across applications. The Spark is capable enough of running on a large number of clusters.
- It consists of various types of cluster managers such as Hadoop YARN, Apache Mesos and Standalone Scheduler.
- Here, the Standalone Scheduler is a standalone spark cluster manager that facilitates to install Spark on an empty set of machines.
Worker Node
- The worker node is a slave node
- Its role is to run the application code in the cluster.
Executor
- An executor is a process launched for an application on a worker node.
- It runs tasks and keeps data in memory or disk storage across them.
- It reads and writes data to external sources.
- Every application contains its executor.
Task
- A unit of work that will be sent to one executor.
What is RDD?
The RDD (Resilient Distributed Dataset) is Spark’s core abstraction. It is a collection of elements, partitioned across the nodes of the cluster so that we can execute various parallel operations on it.There are two ways to create RDDs:Parallelizing an existing data in the driver programReferencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop InputFormat.
Parallelized Collections
To create a parallelized collection, call SparkContext’s parallelize method on an existing collection in the driver program. Each element of collection is copied to form a distributed dataset that can be operated on in parallel.External Datasets
In Spark, the distributed datasets can be created from any type of storage sources supported by Hadoop such as HDFS, Cassandra, HBase and even our local file system. Spark provides the support for text files, SequenceFiles, and other types of Hadoop InputFormat.
RDD Operations
The RDD provides the two types of operations:
- Transformation
- Action
Transformation
In Spark, the role of transformation is to create a new dataset from an existing one. The transformations are considered lazy as they only computed when an action requires a result to be returned to the driver program.
Let’s see some of the frequently used RDD Transformations.
Transformation | Description |
| map(func) | It returns a new distributed dataset formed by passing each element of the source through a function func. |
| filter(func) | It returns a new dataset formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Here, each input item can be mapped to zero or more output items, so func should return a sequence rather than a single item. |
| mapPartitions(func) | It is similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T. |
| mapPartitionsWithIndex(func) | It is similar to mapPartitions that provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T. |
| sample(withReplacement, fraction, seed) | It samples the fraction fraction of the data, with or without replacement, using a given random number generator seed. |
| union(otherDataset) | It returns a new dataset that contains the union of the elements in the source dataset and the argument. |
| intersection(otherDataset) | It returns a new RDD that contains the intersection of elements in the source dataset and the argument. |
| distinct([numPartitions])) | It returns a new dataset that contains the distinct elements of the source dataset. |
| groupByKey([numPartitions]) | It returns a dataset of (K, Iterable) pairs when called on a dataset of (K, V) pairs. |
| reduceByKey(func, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral “zero” value. |
| sortByKey([ascending], [numPartitions]) | It returns a dataset of key-value pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. |
| join(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| cogroup(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable, Iterable)) tuples. This operation is also called groupWith. |
| cartesian(otherDataset) | When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| pipe(command, [envVars]) | Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. |
| coalesce(numPartitions) | It decreases the number of partitions in the RDD to numPartitions. |
| repartition(numPartitions) | It reshuffles the data in the RDD randomly to create either more or fewer partitions and balance it across them. |
| repartitionAndSortWithinPartitions(partitioner) | It repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. |
Action
In Spark, the role of action is to return a value to the driver program after running a computation on the dataset.
Let’s see some of the frequently used RDD Actions.
Action | Description |
| reduce(func) | It aggregates the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | It returns all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count() | It returns the number of elements in the dataset. |
| first() | It returns the first element of the dataset (similar to take(1)). |
| take(n) | It returns an array with the first n elements of the dataset. |
| takeSample(withReplacement, num, [seed]) | It returns an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered(n, [ordering]) | It returns the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile(path) | It is used to write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark calls toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile(path)(Java and Scala) | It is used to write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. |
| saveAsObjectFile(path)(Java and Scala) | It is used to write the elements of the dataset in a simple format using Java serialization, which can then be loaded usingSparkContext.objectFile(). |
| countByKey() | It is only available on RDDs of type (K, V). Thus, it returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | It runs a function func on each element of the dataset for side effects such as updating an Accumulator or interacting with external storage systems. |
RDD Persistence
Spark provides a convenient way to work on the dataset by persisting it in memory across operations. While persisting an RDD, each node stores any partitions of it that it computes in memory. Now, we can also reuse them in other tasks on that dataset.
We can use either persist() or cache() method to mark an RDD to be persisted. Spark?s cache is fault-tolerant. In any case, if the partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it.
There is an availability of different storage levels which are used to store persisted RDDs. Use these levels by passing a StorageLevel object (Scala, Java, Python) to persist(). However, the cache() method is used for the default storage level, which is StorageLevel.MEMORY_ONLY.

Learn Apache Spark Training with In-Depth Concepts to Build Your Skills
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
RDD Shared Variables
In Spark, when any function passes a transformation operation, then it is executed on a remote cluster node. It works on different copies of all the variables used in the function. These variables are copied to each machine, and no updates to the variables on the remote machine are reverted to the driver program.
Broadcast variable
The broadcast variables support a read-only variable cached on each machine rather than providing a copy of it with tasks. Spark uses broadcast algorithms to distribute broadcast variables for reducing communication cost.
The execution of spark actions passes through several stages, separated by distributed “shuffle” operations. Spark automatically broadcasts the common data required by tasks within each stage. The data broadcasted this way is cached in serialized form and deserialized before running each task.
Accumulator
The Accumulator are variables that are used to perform associative and commutative operations such as counters or sums. The Spark provides support for accumulators of numeric types. However, we can add support for new types.
Limitations of Apache Spark Programming
There are many limitations of Apache Spark. Let’s learn all one by one:

a.No Support for Real-time Processing
Basically, Spark is near real-time processing of live data. In other words, Micro-batch processing takes place in Spark Streaming. Hence we can not say Spark is completely a Real-time Processing engine.
b.Problem with Small File
In RDD, each file is a small partition. It means there is a large amount of tiny partitions within an RDD. Hence, if we want efficiency in our processing, the RDDs should be repartitioned into some manageable format. Basically, that demands extensive shuffling over the network.
c.No File Management System
A major issue is Spark does not have its own file management system. Basically, it relies on some other platform like Hadoop or another cloud-based platform.
d.Expensive
While we desire cost-efficient processing of big data, Spark turns out to be very expensive. Since keeping data in memory is quite expensive. However the memory consumption is very high, and it is not handled in a user-friendly manner. Moreover, we require lots of RAM to run in-memory, thus the cost of spark is much higher.
e.Less number of Algorithms
Spark MLlib has very few available algorithms. For example, Tanimoto distance.
f.Manual Optimization
It is necessary that the Spark job is manually optimized and is adequate to specific datasets. Moreover, to partition and cache in spark to be correct, it is must to control it manually.
g.Iterative Processing
Basically, here data iterates in batches. Also, each iteration is scheduled and executed separately.
h. Latency
In comparison with Flink, Apache Spark has higher latency.
i. Window Criteria
Spark only supports time-based window criteria not record based window criteria.
Conclusion
As a result, we have seen every aspect of Apache Spark, what is Apache spark programming and spark definition, History of Spark, why Spark is needed, Components of Apache Spark, Spark RDD, Features of Spark RDD, Spark Streaming, Features of Apache Spark, Limitations of Apache Spark, Apache Spark use cases. In this tutorial we were trying to cover all spark notes, hope you get desired information in it if you feel to ask any query, feel free to ask in the comment section.