
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Spark Algorithm Tutorial
Last updated on 29th Sep 2020, Big Data, Blog, Tutorials
Industries are using Hadoop extensively to analyze their data sets. The reason is that Hadoop framework is based on a simple programming model (MapReduce) and it enables a computing solution that is scalable, flexible, fault-tolerant and cost effective. Here, the main concern is to maintain speed in processing large datasets in terms of waiting time between queries and waiting time to run the program.
Spark was introduced by Apache Software Foundation for speeding up the Hadoop computational computing software process.As against a common belief, Spark is not a modified version of Hadoop and is not, really, dependent on Hadoop because it has its own cluster management. Hadoop is just one of the ways to implement Spark.Spark uses Hadoop in two ways – one is storage and second is processing. Since Spark has its own cluster management computation, it uses Hadoop for storage purposes only.
Apache Spark
Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming. Apart from supporting all these workloads in a respective system, it reduces the management burden of maintaining separate tools.
Subscribe For Free Demo
Error: Contact form not found.
Evolution of Apache Spark
Spark is one of Hadoop’s sub projects developed in 2009 in UC Berkeley’s AMPLab by Matei Zaharia. It was Open Sourced in 2010 under a BSD license. It was donated to Apache software foundation in 2013, and now Apache Spark has become a top level Apache project from Feb-2014.
Why Spark?
As we know, there was no general purpose computing engine in the industry, since
- To perform batch processing, we were using Hadoop MapReduce.
- Also, to perform stream processing, we were using Apache Storm / S4.
- Moreover, for interactive processing, we were using Apache Impala / Apache Tez.
- To perform graph processing, we were using Neo4j / Apache Giraph.
Hence there was no powerful engine in the industry, that can process the data both in real-time and batch mode. Also, there was a requirement that one engine can respond in sub-second and perform in-memory processing.
Therefore, Apache Spark programming enters, it is a powerful open source engine. Since, it offers real-time stream processing, interactive processing, graph processing, in-memory processing as well as batch processing. Even with very fast speed, ease of use and standard interface. Basically, these features create the difference between Hadoop and Spark. Also makes a huge comparison between Spark vs Storm.
Components of Spark
The following illustration depicts the different components of Spark.
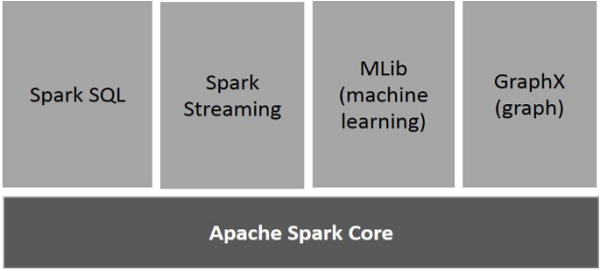
Apache Spark Core
Spark Core is the underlying general execution engine for spark platform that all other functionality is built upon. It provides In-Memory computing and referencing datasets in external storage systems.
Spark SQL
Spark SQL is a component on top of Spark Core that introduces a new data abstraction called SchemaRDD, which provides support for structured and semi-structured data.
Spark Streaming
Spark Streaming leverages Spark Core’s fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data.
MLlib (Machine Learning Library)
MLlib is a distributed machine learning framework above Spark because of the distributed memory-based Spark architecture. It is, according to benchmarks, done by the MLlib developers against the Alternating Least Squares (ALS) implementations. Spark MLlib is nine times as fast as the Hadoop disk-based version of Apache Mahout (before Mahout gained a Spark interface).
GraphX
GraphX is a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user-defined graphs by using Pregel abstraction API. It also provides an optimized runtime for this abstraction.
Features of Apache Spark
Apache Spark has the following features.
Speed
Spark helps to run an application in a Hadoop cluster, up to 100 times faster in memory, and 10 times faster when running on disk. This is possible by reducing the number of read/write operations to disk. It stores the intermediate processing data in memory.
Supports multiple languages
Spark provides built-in APIs in Java, Scala, or Python. Therefore, you can write applications in different languages. Spark comes up with 80 high-level operators for interactive querying.
Advanced Analytics
Spark not only supports ‘Map’ and ‘reduce’. It also supports SQL queries, Streaming data, Machine learning (ML), and Graph algorithms.
Dynamic in Nature
With Apache Spark, you can easily develop parallel applications. Spark offers you over 80 high-level operators.

Best Apache Spark Training Cover In-Depth Concepts By Top-Rated Instructors
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Multilingual
Apache Spark supports many languages for code writing such as Python, Java, Scala, etc.
Apache Spark is powerful
Apache Spark can handle many analytics challenges because of its low-latency in-memory data processing capability. It has well-built libraries for graph analytics algorithms and machine learning.
Increased access to Big data
Apache Spark is opening up various opportunities for big data and making As per the recent survey conducted by IBM’s announced that it will educate more than 1 million data engineers and data scientists on Apache Spark.
Demand for Spark Developers
Apache Spark not only benefits your organization but you as well. Spark developers are so in-demand that companies offer attractive benefits and provide flexible work timings just to hire experts skilled in Apache Spark. As per PayScale the average salary for Data Engineer with Apache Spark skills is $100,362. For people who want to make a career in big data, technology can learn Apache Spark. You will find various ways to bridge the skills gap for getting data-related jobs, but the best way is to take formal training which will provide you hands-on work experience and also learn through hands-on projects.
Open-source community
The best thing about Apache Spark is, it has a massive Open-source community behind it.
Limitations of Apache Spark
As we know Apache Spark is the next Gen Big data tool that is being widely used by industries but there are certain limitations of Apache Spark due to which industries have started shifting to Apache Flink– 4G of Big Data.
No Support for Real-time Processing
In Spark Streaming, the arriving live stream of data is divided into batches of the pre-defined interval, and each batch of data is treated like Spark Resilient Distributed Database (RDDs). Then these RDDs are processed using the operations like map, reduce, join etc. The result of these operations is returned in batches. Thus, it is not real time processing but Spark is near real-time processing of live data. Micro-batch processing takes place in Spark Streaming.
Problem with Small File
If we use Spark with Hadoop, we come across a problem with a small file. HDFS provides a limited number of large files rather than a large number of small files. Another place where Spark legs behind is we store the data gzipped in S3. This pattern is very nice except when there are lots of small gzipped files. Now the work of the Spark is to keep those files on network and uncompress them. The gzipped files can be uncompressed only if the entire file is on one core. So a large span of time will be spent in burning their core unzipping files in sequence.
In the resulting RDD, each file will become a partition; hence there will be a large amount of tiny partitions within an RDD. Now if we want efficiency in our processing, the RDDs should be repartitioned into some manageable format. This requires extensive shuffling over the network.
No File Management System
Apache Spark does not have its own file management system, thus it relies on some other platform like Hadoop or another cloud-based platform which is one of the Spark known issues.
Expensive
In-memory capability can become a bottleneck when we want cost-efficient processing of big data as keeping data in memory is quite expensive, the memory consumption is very high, and it is not handled in a user-friendly manner. Apache Spark requires lots of RAM to run in-memory, thus the cost of Spark is quite high.
Less number of Algorithms
Spark MLlib lags behind in terms of a number of available algorithms like Tanimoto distance.
Manual Optimization
The Spark job requires to be manually optimized and is adequate to specific datasets. If we want to partition and cache in Spark to be correct, it should be controlled manually.
Iterative Processing
In Spark, the data iterates in batches and each iteration is scheduled and executed separately.
Latency
Apache Spark has higher latency as compared to Apache Flink.
Window Criteria
Spark does not support record based window criteria. It only has time-based window criteria.
Back Pressure Handling
Back pressure is built up of data at an input-output when the buffer is full and not able to receive the additional incoming data. No data is transferred until the buffer is empty. Apache Spark is not capable of handling pressure implicitly rather it is done manually.
Domain Scenarios of Apache Spark
Today, there is widespread deployment of big data tools. With each passing day, the requirements of enterprises increase, and therefore there is a need for a faster and more efficient form of data processing. Most streaming data is in an unstructured format, coming in thick and fast continuously. Here in this Apache Spark tutorial, we look at how Spark is used successfully in different industries.
Banking
Spark is being more and more adopted by the banking sector. It is mainly used here for financial fraud detection with the help of Spark ML. Banks use Spark to handle credit risk assessment, customer segmentation, and advertising. Apache Spark is also used to analyze social media profiles, forum discussions, customer support chat, and emails. This way of analyzing data helps organizations make better business decisions.
E-commerce
Spark is widely used in the e-commerce industry. Spark Machine Learning, along with streaming, can be used for real-time data clustering. Businesses can share their findings with other data sources to provide better recommendations to their customers. Recommendation systems are mostly used in the e-commerce industry to show new trends.
Healthcare
Apache Spark is a powerful computation engine to perform advanced analytics on patient records. It helps keep track of patients’ health records easily. The healthcare industry uses Spark to deploy services to get insights such as patient feedback, hospital services, and to keep track of medical data.
Media
Many gaming companies use Apache Spark for finding patterns from their real-time in-game events. With this, they can derive further business opportunities by customizing such as adjusting the complexity-level of the game automatically according to players’ performance, etc. Some media companies, like Yahoo, use Apache Spark for targeted marketing, customizing news pages based on readers’ interests, and so on. They use tools such as Machine Learning algorithms for identifying the readers’ interests category. Eventually, they categorize such news stories in various sections and keep the reader updated on a timely basis.
Travel
Many people land up with travel planners to make their vacation a perfect one, and these travel companies depend on Apache Spark for offering various travel packages. TripAdvisor is one such company that uses Apache Spark to compare different travel packages from different providers. It scans through hundreds of websites to find the best and reasonable hotel price, trip package, etc.