
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Kafka Tutorial
Last updated on 12th Oct 2020, Big Data, Blog, Tutorials
Apache Kafka was originated at LinkedIn and later became an open sourced Apache project in 2011, then First-class Apache project in 2012. Kafka is written in Scala and Java. Apache Kafka is publish-subscribe based fault tolerant messaging system. It is fast, scalable and distributed by design.
This tutorial will explore the principles of Kafka, installation, operations and then it will walk you through with the deployment of Kafka cluster. Finally, we will conclude with real-time applica-tions and integration with Big Data Technologies.
Apache Kafka Tutorial provides the basic and advanced concepts of Apache Kafka. This tutorial is designed for both beginners and professionals.
Apache Kafka is an open-source stream-processing software platform which is used to handle the real-time data storage. It works as a broker between two parties, i.e., a sender and a receiver. It can handle about trillions of data events in a day.
Apache Kafka tutorial journey will cover all the concepts from its architecture to its core concepts.
What is Apache Kafka?
Apache Kafka is a software platform which is based on a distributed streaming process. It is a publish-subscribe messaging system which let exchanging of data between applications, servers, and processors as well. Apache Kafka was originally developed by LinkedIn, and later it was donated to the Apache Software Foundation. Currently, it is maintained by Confluent under Apache Software Foundation. Apache Kafka has resolved the lethargic trouble of data communication between a sender and a receiver.
What is a messaging system?
A messaging system is a simple exchange of messages between two or more persons, devices, etc. A publish-subscribe messaging system allows a sender to send/write the message and a receiver to read that message. In Apache Kafka, a sender is known as a producer who publishes messages, and a receiver is known as a consumer who consumes that message by subscribing it.
What is Streaming process?
A streaming process is the processing of data in parallelly connected systems. This process allows different applications to limit the parallel execution of the data, where one record executes without waiting for the output of the previous record. Therefore, a distributed streaming platform enables the user to simplify the task of the streaming process and parallel execution. Therefore, a streaming platform in Kafka has the following key capabilities:
- As soon as the streams of records occur, it processes it.
- It works similar to an enterprise messaging system where it publishes and subscribes streams of records.
- It stores the streams of records in a fault-tolerant durable way.
To learn and understand Apache Kafka, the aspirants should know the following four core APIs :
Producer API: This API allows/permits an application to publish streams of records to one or more topics. (discussed in later section)
Consumer API: This API allows an application to subscribe one or more topics and process the stream of records produced to them.
Streams API: This API allows an application to effectively transform the input streams to the output streams. It permits an application to act as a stream processor which consumes an input stream from one or more topics, and produce an output stream to one or more output topics.
Connector API: This API executes the reusable producer and consumer APIs with the existing data systems or applications.
Why Apache Kafka?

Apache Kafka is a software platform that has the following reasons which best describes the need of Apache Kafka.
- Apache Kafka is capable of handling millions of data or messages per second.
- Apache Kafka works as a mediator between the source system and the target system. Thus, the source system (producer) data is sent to the Apache Kafka, where it decouples the data, and the target system (consumer) consumes the data from Kafka.
- Apache Kafka is having extremely high performance, i.e., it has really low latency value less than 10ms which proves it as a well-versed software.
- Apache Kafka has a resilient architecture which has resolved unusual complications in data sharing.
- Organizations such as NETFLIX, UBER, Walmart, etc. and over thousands of such firms make use of Apache Kafka.
- Apache Kafka is able to maintain the fault-tolerance. Fault-tolerance means that sometimes a consumer successfully consumes the message that was delivered by the producer. But, the consumer fails to process the message back due to backend database failure, or due to presence of a bug in the consumer code. In such a situation, the consumer is unable to consume the message again. Consequently, Apache Kafka has resolved the problem by reprocessing the data.
- Learning Kafka is a good source of income. So, those who wish to raise their income in future in IT sector can learn.
Audience :
This tutorial has been prepared for professionals aspiring to make a career in Big Data Analytics using Apache Kafka messaging system. It will give you enough understanding on how to use Kafka clusters.
Subscribe For Free Demo
Error: Contact form not found.
Prerequisites :
Before proceeding with this tutorial, you must have a good understanding of Java, Scala, Dis-tributed messaging system, and Linux environment.
In Big Data, an enormous volume of data is used. Regarding data, we have two main challenges.The first challenge is how to collect large volume of data and the second challenge is to analyze the collected data. To overcome those challenges, you must need a messaging system.
Kafka is designed for distributed high throughput systems. Kafka tends to work very well as a replacement for a more traditional message broker. In comparison to other messaging systems, Kafka has better throughput, built-in partitioning, replication and inherent fault-tolerance, which makes it a good fit for large-scale message processing applications.
What is a Messaging System?
A Messaging System is responsible for transferring data from one application to another, so the applications can focus on data, but not worry about how to share it. Distributed messaging is based on the concept of reliable message queuing. Messages are queued asynchronously between client applications and messaging system. Two types of messaging patterns are available − one is point to point and the other is publish-subscribe (pub-sub) messaging system. Most of the messaging patterns follow pub-sub.
Point to Point Messaging System :
In a point-to-point system, messages are persisted in a queue. One or more consumers can consume the messages in the queue, but a particular message can be consumed by a maximum of one consumer only. Once a consumer reads a message in the queue, it disappears from that queue. The typical example of this system is an Order Processing System, where each order will be processed by one Order Processor, but Multiple Order Processors can work as well at the same time. The following diagram depicts the structure.
Publish-Subscribe Messaging System :
In the publish-subscribe system, messages are persisted in a topic. Unlike point-to-point system, consumers can subscribe to one or more topic and consume all the messages in that topic. In the Publish-Subscribe system, message producers are called publishers and message consumers are called subscribers. A real-life example is Dish TV, which publishes different channels like sports, movies, music, etc., and anyone can subscribe to their own set of channels and get them whenever their subscribed channels are available.
Benefits :
Following are a few benefits of Kafka −
- Reliability − Kafka is distributed, partitioned, replicated and fault tolerance.
- Scalability − Kafka messaging system scales easily without down time..
- Durability − Kafka uses Distributed commit log which means messages persists on disk as fast as possible, hence it is durable..
- Performance − Kafka has high throughput for both publishing and subscribing messages. It maintains stable performance even many TB of messages are stored.
Kafka is very fast and guarantees zero downtime and zero data loss.
Use Cases :
Kafka can be used in many Use Cases. Some of them are listed below −
- Metrics − Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
- Log Aggregation Solution − Kafka can be used across an organization to collect logs from multiple services and make them available in a standard format to multiple con-sumers.
- Stream Processing − Popular frameworks such as Storm and Spark Streaming read data from a topic, processes it, and write processed data to a new topic where it becomes available for users and applications. Kafka’s strong durability is also very useful in the context of stream processing.
Need for Kafka :
Kafka is a unified platform for handling all the real-time data feeds. Kafka supports low latency message delivery and gives guarantee for fault tolerance in the presence of machine failures. It has the ability to handle a large number of diverse consumers. Kafka is very fast, performs 2 million writes/sec. Kafka persists all data to the disk, which essentially means that all the writes go to the page cache of the OS (RAM). This makes it very efficient to transfer data from page cache to a network socket.
Fundamentals :
Before moving deep into the Kafka, you must aware of the main terminologies such as topics, brokers, producers and consumers. The following diagram illustrates the main terminologies and the table describes the diagram components in detail.
In the above diagram, a topic is configured into three partitions. Partition 1 has two offset factors 0 and 1. Partition 2 has four offset factors 0, 1, 2, and 3. Partition 3 has one offset factor 0. The id of the replica is same as the id of the server that hosts it.
Assume, if the replication factor of the topic is set to 3, then Kafka will create 3 identical replicas of each partition and place them in the cluster to make available for all its operations. To balance a load in cluster, each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.
S.No | Components and Description |
|---|---|
| 1 | TopicsA stream of messages belonging to a particular category is called a topic. Data is stored in topics.Topics are split into partitions. For each topic, Kafka keeps a mini-mum of one partition. Each such partition contains messages in an immutable ordered sequence. A partition is implemented as a set of segment files of equal sizes. |
| 2 | PartitionTopics may have many partitions, so it can handle an arbitrary amount of data. |
| 3 | Partition offsetEach partitioned message has a unique sequence id called as offset. |
| 4 | Replicas of partitionReplicas are nothing but backups of a partition. Replicas are never read or write data. They are used to prevent data loss. |
| 5 | BrokersBrokers are simple system responsible for maintaining the pub-lished data. Each broker may have zero or more partitions per topic. Assume, if there are N partitions in a topic and N number of brokers, each broker will have one partition.Assume if there are N partitions in a topic and more than N brokers (n + m), the first N broker will have one partition and the next M broker will not have any partition for that particular topic.Assume if there are N partitions in a topic and less than N brokers (n-m), each broker will have one or more partition sharing among them. This scenario is not recommended due to unequal load distri-bution among the broker. |
| 6 | Kafka ClusterKafka’s having more than one broker are called as Kafka cluster. A Kafka cluster can be expanded without downtime. These clusters are used to manage the persistence and replication of message data. |
| 7 | ProducersProducers are the publisher of messages to one or more Kafka topics. Producers send data to Kafka brokers. Every time a producer pub-lishes a message to a broker, the broker simply appends the message to the last segment file. Actually, the message will be appended to a partition. Producer can also send messages to a partition of their choice. |
| 8 | ConsumersConsumers read data from brokers. Consumers subscribes to one or more topics and consume published messages by pulling data from the brokers. |
| 9 | LeaderLeader is the node responsible for all reads and writes for the given partition. Every partition has one server acting as a leader. |
| 10 | FollowerNode which follows leader instructions are called as follower. If the leader fails, one of the follower will automatically become the new leader. A follower acts as normal consumer, pulls messages and up dates its own data store. |
Basic Operations :
First let us start implementing single node-single broker configuration and we will then migrate our setup to single node-multiple brokers configuration.
Hopefully you would have installed Java, ZooKeeper and Kafka on your machine by now. Before moving to the Kafka Cluster Setup, first you would need to start your ZooKeeper because Kafka Cluster uses ZooKeeper.
Single Node-Single Broker Configuration :
In this configuration you have a single ZooKeeper and broker id instance. Following are the steps to configure it −
Creating a Kafka Topic − Kafka provides a command line utility named kafka-topics.sh to create topics on the server. Open new terminal and type the below example.
We just created a topic named Hello-Kafka with a single partition and one replica factor. The above created output will be similar to the following output −
Output − Created topic Hello-Kafka
Once the topic has been created, you can get the notification in Kafka broker terminal window and the log for the created topic specified in “/tmp/kafka-logs/“ in the config/server.properties file.

Take Your Career to Next Level with Kafka Training to Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Single Node-Multiple Brokers Configuration :
Before moving on to the multiple brokers cluster setup, first start your ZooKeeper server.
Create Multiple Kafka Brokers − We have one Kafka broker instance already in con-fig/server.properties. Now we need multiple broker instances, so copy the existing server.prop-erties file into two new config files and rename it as server-one.properties and server-two.prop-erties.
Tools :
Kafka Tool packaged under “org.apache.kafka.tools.*. Tools are categorized into system tools and replication tools.
System Tools :
System tools can be run from the command line using the run class script.
Some of the system tools are mentioned below −
- Kafka Migration Tool − This tool is used to migrate a broker from one version to an-other.
- Mirror Maker − This tool is used to provide mirroring of one Kafka cluster to another.
- Consumer Offset Checker − This tool displays Consumer Group, Topic, Partitions, Off-set, logSize, Owner for the specified set of Topics and Consumer Group.
Replication Tool :
Kafka replication is a high level design tool. The purpose of adding replication tool is for stronger durability and higher availability. Some of the replication tools are mentioned below −
- Create Topic Tool − This creates a topic with a default number of partitions, replication factor and uses Kafka’s default scheme to do replica assignment.
- List Topic Tool − This tool lists the information for a given list of topics. If no topics are provided in the command line, the tool queries Zookeeper to get all the topics and lists the information for them. The fields that the tool displays are topic name, partition, leader, replicas, isr.
- Add Partition Tool − Creation of a topic, the number of partitions for topic has to be specified. Later on, more partitions may be needed for the topic, when the volume of the topic will increase. This tool helps to add more partitions for a specific topic and also allows manual replica assignment of the added partitions.
Apache Kafka ArchitectureWe have already learned the basic concepts of Apache Kafka. These basic concepts, such as Topics, partitions, producers, consumers, etc., together forms the Kafka architecture.As different applications design the architecture of Kafka accordingly, there are the following essential parts required to design Apache Kafka architecture.Data Ecosystem: Several applications that use Apache Kafka forms an ecosystem. This ecosystem is built for data processing. It takes inputs in the form of applications that create data, and outputs are defined in the form of metrics, reports, etc. The below diagram represents a circulatory data ecosystem for Kafka.Kafka Cluster: A Kafka cluster is a system that comprises of different brokers, topics, and their respective partitions. Data is written to the topic within the cluster and read by the cluster itself.Producers: A producer sends or writes data/messages to the topic within the cluster. In order to store a huge amount of data, different producers within an application send data to the Kafka cluster.Consumers: A consumer is the one that reads or consumes messages from the Kafka cluster. There can be several consumers consuming different types of data form the cluster. The beauty of Kafka is that each consumer knows from where it needs to consume the data.Brokers: A Kafka server is known as a broker. A broker is a bridge between producers and consumers. If a producer wishes to write data to the cluster, it is sent to the Kafka server. All brokers lie within a Kafka cluster itself. Also, there can be multiple brokers.Topics: It is a common name or a heading given to represent a similar type of data. In Apache Kafka, there can be multiple topics in a cluster. Each topic specifies different types of messages.Partitions: The data or message is divided into small subparts, known as partitions. Each partition carries data within it having an offset value. The data is always written in a sequential manner. We can have an infinite number of partitions with infinite offset values. However, it is not guaranteed that to which partition the message will be written.ZooKeeper: A ZooKeeper is used to store information about the Kafka cluster and details of the consumer clients. It manages brokers by maintaining a list of them. Also, a ZooKeeper is responsible for choosing a leader for the partitions. If any changes like a broker die, new topics, etc., occurs, the ZooKeeper sends notifications to Apache Kafka. A ZooKeeper is designed to operate with an odd number of Kafka servers. Zookeeper has a leader server that handles all the writes, and rest of the servers are the followers who handle all the reads. However, a user does not directly interact with the Zookeeper, but via brokers. No Kafka server can run without a zookeeper server. It is mandatory to run the zookeeper server.
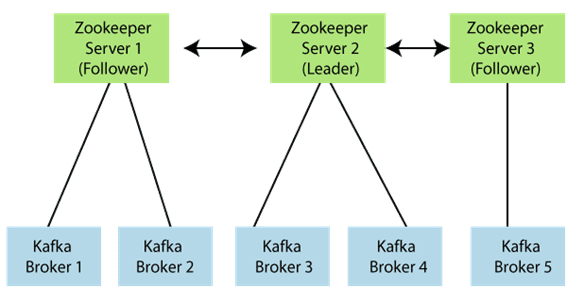
In the above figure, there are three zookeeper servers where server 2 is the leader, and the other two are chosen as its followers. The five brokers are connected to these servers. Automatically, the Kafka cluster will come to know when brokers are down, more topics are added, etc..Hence, on combining all the necessities, a Kafka cluster architecture is designed.

Best Kafka Certification Course with Industry Standard Topics From Real-Time Experts
Weekday / Weekend BatchesSee Batch DetailsApplications :
Kafka supports many of today’s best industrial applications. We will provide a very brief overview of some of the most notable applications of Kafka in this chapter.
Twitter :
Twitter is an online social networking service that provides a platform to send and receive user tweets. Registered users can read and post tweets, but unregistered users can only read tweets. Twitter uses Storm-Kafka as a part of their stream processing infrastructure.
LinkedIn :
Apache Kafka is used at LinkedIn for activity stream data and operational metrics. Kafka mes-saging system helps LinkedIn with various products like LinkedIn Newsfeed, LinkedIn Today for online message consumption and in addition to offline analytics systems like Hadoop. Kafka’s strong durability is also one of the key factors in connection with LinkedIn.
Netflix :
Netflix is an American multinational provider of on-demand Internet streaming media. Netflix uses Kafka for real-time monitoring and event processing.
Mozilla :
Mozilla is a free-software community, created in 1998 by members of Netscape. Kafka will soon be replacing a part of Mozilla current production system to collect performance and usage data from the end-user’s browser for projects like Telemetry, Test Pilot, etc.
Oracle :
Oracle provides native connectivity to Kafka from its Enterprise Service Bus product called OSB (Oracle Service Bus) which allows developers to leverage OSB built-in mediation capabilities to implement staged data pipelines.
Kafka: Advantages and Disadvantages

Advantages of Apache Kafka
Following advantages of Apache Kafka makes it worthy:
- Low Latency: Apache Kafka offers low latency value, i.e., upto 10 milliseconds. It is because it decouples the message which lets the consumer to consume that message anytime.
- High Throughput: Due to low latency, Kafka is able to handle more number of messages of high volume and high velocity. Kafka can support thousands of messages in a second. Many companies such as Uber use Kafka to load a high volume of data.
- Fault tolerance: Kafka has an essential feature to provide resistant to node/machine failure within the cluster.
- Durability: Kafka offers the replication feature, which makes data or messages to persist more on the cluster over a disk. This makes it durable.
- Reduces the need for multiple integrations: All the data that a producer writes go through Kafka. Therefore, we just need to create one integration with Kafka, which automatically integrates us with each producing and consuming system.
- Easily accessible: As all our data gets stored in Kafka, it becomes easily accessible to anyone.
- Distributed System: Apache Kafka contains a distributed architecture which makes it scalable. Partitioning and replication are the two capabilities under the distributed system.
- Real-Time handling: Apache Kafka is able to handle real-time data pipeline. Building a real-time data pipeline includes processors, analytics, storage, etc.
- Batch approach: Kafka uses batch-like use cases. It can also work like an ETL tool because of its data persistence capability.
- Scalability: The quality of Kafka to handle large amount of messages simultaneously make it a scalable software product.
Disadvantages Of Apache Kafka
With the above advantages, there are following limitations/disadvantages of Apache Kafka:
- Do not have complete set of monitoring tools: Apache Kafka does not contain a complete set of monitoring as well as managing tools. Thus, new startups or enterprises fear to work with Kafka.
- Message tweaking issues: The Kafka broker uses system calls to deliver messages to the consumer. In case, the message needs some tweaking, the performance of Kafka gets significantly reduced. So, it works well if the message does not need to change.
- Do not support wildcard topic selection: Apache Kafka does not support wildcard topic selection. Instead, it matches only the exact topic name. It is because selecting wildcard topics make it incapable to address certain use cases.
- Reduces Performance: Brokers and consumers reduce the performance of Kafka by compressing and decompressing the data flow. This not only affects its performance but also affects its throughput.
- Clumsy Behaviour: Apache Kafka most often behaves a bit clumsy when the number of queues increases in the Kafka Cluster.
- Lack some message paradigms: Certain message paradigms such as point-to-point queues, request/reply, etc. are missing in Kafka for some use cases.