
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Hadoop Tutorial
Last updated on 25th Sep 2020, Big Data, Blog, Tutorials
Hadoop is an open source framework. It is provided by Apache to process and analyze a very huge volume of data. It is written in Java and currently used by Google, Facebook, LinkedIn, Yahoo, Twitter etc.
What is Hadoop
Hadoop is an open source framework from Apache and is used to store, process and analyze data which are very huge in volume. Hadoop is written in Java and is not OLAP (online analytical processing). It is used for batch/offline processing.It is being used by Facebook, Yahoo, Google, Twitter, LinkedIn and many more. Moreover it can be scaled up just by adding nodes in the cluster.
What’s with the name?
Hadoop was originally developed by Doug Cutting and Mike Cafarella. According to lore, Cutting named the software after his son’s toy elephant. An image of an elephant remains the symbol for Hadoop.
How is Hadoop related to big data?
Big data is becoming a catchall phrase, while Hadoop refers to a specific technology framework. Hadoop is a gateway that makes it possible to work with big data, or more specifically, large data sets that reside in a distributed environment. One way to define big data is data that is too big to be processed by relational database management systems (RDBMS). Hadoop helps overcome RDBMS limitations, so big data can be processed.
Hadoop Installation
Environment required for Hadoop: The production environment of Hadoop is UNIX, but it can also be used in Windows using Cygwin. Java 1.6 or above is needed to run Map Reduce Programs. For Hadoop installation from tarball on the UNIX environment you need
- 1. Java Installation
- 2. SSH installation
- 3. Hadoop Installation and File Configuration
1) Java Installation
Step 1. Type “java -version” in prompt to find if the java is installed or not. If not then download java from http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html . The tar filejdk-7u71-linux-x64.tar.gz will be downloaded to your system.
Step 2. Extract the file using the below command
- #tar zxf jdk-7u71-linux-x64.tar.gz
Step 3. To make java available for all the users of UNIX move the file to /usr/local and set the path. In the prompt switch to root user and then type the command below to move the jdk to /usr/lib.
- # mv jdk1.7.0_71 /usr/lib/
Now in ~/.bashrc file add the following commands to set up the path.
- # export JAVA_HOME=/usr/lib/jdk1.7.0_71
- # export PATH=PATH:$JAVA_HOME/bin
Now, you can check the installation by typing “java -version” in the prompt.
2) SSH Installation
SSH is used to interact with the master and slaves computer without any prompt for password. First of all create a Hadoop user on the master and slave systems
Subscribe For Free Demo
Error: Contact form not found.
- # useradd hadoop
- # passwd Hadoop
To map the nodes, open the hosts file present in /etc/ folder on all the machines and put the ip address along with their host name.
# vi /etc/hosts
Enter the lines below
190.12.1.114 hadoop-master
190.12.1.121 hadoop-salve-one
190.12.1.143 hadoop-slave-two
Set up an SSH key in every node so that they can communicate among themselves without a password. Commands for the same are:
- # su hadoop
- $ ssh-keygen -t rsa
- $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master
- $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1
- $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2
- $ chmod 0600 ~/.ssh/authorized_keys
- $ exit
3) Hadoop Installation
Hadoop can be downloaded from http://developer.yahoo.com/hadoop/tutorial/module3.html
Now extract the Hadoop and copy it to a location.
- $ mkdir /usr/hadoop
- $ sudo tar vxzf hadoop-2.2.0.tar.gz ?c /usr/hadoop
Change the ownership of Hadoop folder
- $sudo chown -R hadoop usr/hadoop
Change the Hadoop configuration files:
All the files are present in /usr/local/Hadoop/etc/hadoop
1) In hadoop-env.sh file add
- 1. export JAVA_HOME=/usr/lib/jvm/jdk/jdk1.7.0_71
2) In core-site.xml add following between configuration tabs,
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://hadoop-master:9000</value>
- </property>
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- </configuration>
3) In hdfs-site.xml add following between configuration tabs,
- <configuration>
- <property>
- <name>dfs.data.dir</name>
- <value>usr/hadoop/dfs/name/data</value>
- <final>true</final>
- </property>
- <property>
- <name>dfs.name.dir</name>
- <value>usr/hadoop/dfs/name</value>
- <final>true</final>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
4) Open the Mapred-site.xml and make the change as shown below
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>hadoop-master:9001</value>
- </property>
- </configuration>
5) Finally, update your $HOME/.bashrc
- cd $HOME
- vi .bashrc
Append following lines in the end and save and exit
#Hadoop variables
export JAVA_HOME=/usr/lib/jvm/jdk/jdk1.7.0_71
export HADOOP_INSTALL=/usr/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
On the slave machine install Hadoop using the command below
- # su hadoop
- $ cd /opt/hadoop
- $ scp -r hadoop hadoop-slave-one:/usr/hadoop
- $ scp -r hadoop hadoop-slave-two:/usr/Hadoop
Configure master node and slave node
- $ vi etc/hadoop/masters
hadoop-master
- $ vi etc/hadoop/slaves
hadoop-slave-one
hadoop-slave-two
After this format the name node and start all the demons
- # su hadoop
- $ cd /usr/hadoop
- $ bin/hadoop namenode -format
- $ cd $HADOOP_HOME/sbin
- $ start-all.sh
The easiest step is the usage of cloudera as it comes with all the stuffs pre-installed which can be downloaded from http://content.udacity-data.com/courses/ud617/Cloudera-Udacity-Training-VM-4.1.1.c.zip
Hadoop Architecture
At its core, Hadoop has two major layers namely −
- Processing/Computation layer (MapReduce), and
- Storage layer (Hadoop Distributed File System).

MapReduce
MapReduce is a parallel programming model for writing distributed applications devised at Google for efficient processing of large amounts of data (multi-terabyte data-sets), on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner. The MapReduce program runs on Hadoop which is an Apache open-source framework.
Hadoop Distributed File System
The Hadoop Distributed File System (HDFS) is based on the Google File System (GFS) and provides a distributed file system that is designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. It is highly fault-tolerant and is designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications having large datasets.
Apart from the above-mentioned two core components, Hadoop framework also includes the following two modules −
- Hadoop Common − These are Java libraries and utilities required by other Hadoop modules.
- Hadoop YARN − This is a framework for job scheduling and cluster resource management.
How Does Hadoop Work?
It is quite expensive to build bigger servers with heavy configurations that handle large scale processing, but as an alternative, you can tie together many commodity computers with single-CPU, as a single functional distributed system and practically, the clustered machines can read the dataset in parallel and provide a much higher throughput. Moreover, it is cheaper than one high-end server. So this is the first motivational factor behind using Hadoop that it runs across clustered and low-cost machines.
Hadoop runs code across a cluster of computers. This process includes the following core tasks that Hadoop performs −
- Data is initially divided into directories and files. Files are divided into uniform sized blocks of 128M and 64M (preferably 128M).
- These files are then distributed across various cluster nodes for further processing.
- HDFS, being on top of the local file system, supervises the processing.
- Blocks are replicated for handling hardware failure.
- Checking that the code was executed successfully.
- Performing the sort that takes place between the map and reduce stages.
- Sending the sorted data to a certain computer.
- Writing the debugging logs for each job.
Core elements of Hadoop
There are four basic elements to Hadoop:
HDFS
MapReduce
YARN
Common.
HDFS
Hadoop works across clusters of commodity servers. Therefore there needs to be a way to coordinate activity across the hardware. Hadoop can work with any distributed file system, however the Hadoop Distributed File System is the primary means for doing so and is the heart of Hadoop technology. HDFS manages how data files are divided and stored across the cluster. Data is divided into blocks, and each server in the cluster contains data from different blocks. There is also some built-in redundancy.
YARN
It would be nice if YARN could be thought of as the string that holds everything together, but in an environment where terms like Oozie, tuple and Sqoop are common, of course it’s not that simple. YARN is an acronym for Yet Another Resource Negotiator. As the full name implies, YARN helps manage resources across the cluster environment. It breaks up resource management, job scheduling, and job management tasks into separate daemons. Key elements include the ResourceManager (RM), the NodeManager (NM) and the ApplicationMaster (AM).
Think of the ResourceManager as the final authority for assigning resources for all the applications in the system. The NodeManagers are agents that manage resources (e.g. CPU, memory, network, etc.) on each machine. NodeManagers report to the ResourceManager. ApplicationMaster serves as a library that sits between the two. It negotiates resources with ResourceManager and works with one or more NodeManagers to execute tasks for which resources were allocated.

Best Hadoop Training with Advanced Concepts from Real Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
MapReduce
MapReduce provides a method for parallel processing on distributed servers. Before processing data, MapReduce converts that large blocks into smaller data sets called tuples. Tuples, in turn, can be organized and processed according to their key-value pairs. When MapReduce processing is complete, HDFS takes over and manages storage and distribution for the output. The shorthand version of MapReduce is that it breaks big data blocks into smaller chunks that are easier to work with.
The “Map” in MapReduce refers to the Map Tasks function. Map Tasks is the process of formatting data into key-value pairs and assigning them to nodes for the “Reduce” function, which is executed by Reduce Tasks, where data is reduced to tuples. Both Map Tasks and Reduce Tasks use worker nodes to carry out their functions.
JobTracker is a component of the MapReduce engine that manages how client applications submit MapReduce jobs. It distributes work to TaskTracker nodes. TaskTracker attempts to assign processing as close to where the data resides as possible.
Note that MapReduce is not the only way to manage parallel processing in the Hadoop environment.
Common
Common, which is also known as Hadoop Core, is a set of utilities that support the other Hadoop components. Common is intended to give the Hadoop framework ways to manage typical (common) hardware failures.
Hadoop File System
Hadoop File System was developed using distributed file system design. It is run on commodity hardware. Unlike other distributed systems, HDFS is highly fault tolerant and designed using low-cost hardware.
HDFS holds a very large amount of data and provides easier access. To store such huge data, the files are stored across multiple machines. These files are stored in redundant fashion to rescue the system from possible data losses in case of failure. HDFS also makes applications available for parallel processing.
Features of HDFS
- It is suitable for distributed storage and processing.
- Hadoop provides a command interface to interact with HDFS.
- The built-in servers of namenode and datanode help users to easily check the status of the cluster.
- Streaming access to file system data.
- HDFS provides file permissions and authentication.
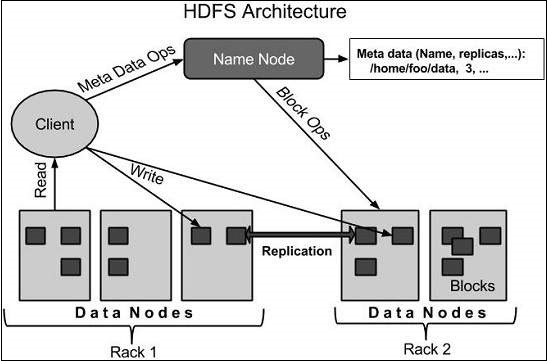
HDFS Architecture
Given below is the architecture of a Hadoop File System.
HDFS follows the master-slave architecture and it has the following elements.
Namenode
The namenode is the commodity hardware that contains the GNU/Linux operating system and the namenode software. It is a software that can be run on commodity hardware. The system having the namenode acts as the master server and it does the following tasks −
- Manages the file system namespace.
- Regulates client’s access to files.
- It also executes file system operations such as renaming, closing, and opening files and directories.
Datanode
The datanode is a commodity hardware having the GNU/Linux operating system and datanode software. For every node (Commodity hardware/System) in a cluster, there will be a datanode. These nodes manage the data storage of their system.
- Datanodes perform read-write operations on the file systems, as per client request.
- They also perform operations such as block creation, deletion, and replication according to the instructions of the namenode.
Block
Generally the user data is stored in the files of HDFS. The file in a file system will be divided into one or more segments and/or stored in individual data nodes. These file segments are called blocks. In other words, the minimum amount of data that HDFS can read or write is called a Block. The default block size is 64MB, but it can be increased as per the need to change in HDFS configuration.
Goals of HDFS
- Fault detection and recovery − Since HDFS includes a large number of commodity hardware, failure of components is frequent. Therefore HDFS should have mechanisms for quick and automatic fault detection and recovery.
- Huge datasets − HDFS should have hundreds of nodes per cluster to manage the applications having huge datasets.
- Hardware at data − A requested task can be done efficiently, when the computation takes place near the data. Especially where huge datasets are involved, it reduces the network traffic and increases the throughput.
Hadoop Flavors
This section of Hadoop Tutorial talks about the various flavors of Hadoop.
- Apache — Vanilla flavor, as the actual code is residing in Apache repositories
- Hortonworks — Popular distribution in the industry
- Cloudera — It is the most popular in the industry
- MapR — It has rewritten HDFS and its HDFS is faster as compared to others
- IBM — Proprietary distribution is known as Big Insights
All the databases have provided native connectivity with Hadoop for fast data transfer, because, to transfer data from Oracle to Hadoop, you need a connector.
All flavors are almost the same and if you know one, you can easily work on other flavors as well.
Examples of Hadoop
Here are five examples of Hadoop use cases:
- 1. Financial services companies use analytics to assess risk, build investment models, and create trading algorithms; Hadoop has been used to help build and run those applications.
- 2. Retailers use it to help analyze structured and unstructured data to better understand and serve their customers.
- 3. In the asset-intensive energy industry Hadoop-powered analytics are used for predictive maintenance, with input from Internet of Things (IoT) devices feeding data into big data programs.

- 4. Telecommunications companies can adapt all the aforementioned use cases. For example, they can use Hadoop-powered analytics to execute predictive maintenance on their infrastructure. Big data analytics can also plan efficient network paths and recommend optimal locations for new cell towers or other network expansion. To support customer-facing operations telcos can analyze customer behavior and billing statements to inform new service offerings.
- 5. There are numerous public sector programs, ranging from anticipating and preventing disease outbreaks to crunching numbers to catch tax cheats.
Hadoop is used in these and other big data programs because it is effective, scalable, and is well supported by large vendor and user communities. Hadoop is a de facto standard in big data.
Advantages of Hadoop
- Hadoop framework allows the user to quickly write and test distributed systems. It is efficient, and it automatically distributes the data and work across the machines and in turn, utilizes the underlying parallelism of the CPU cores.
- Hadoop does not rely on hardware to provide fault-tolerance and high availability (FTHA), rather Hadoop library itself has been designed to detect and handle failures at the application layer.
- Servers can be added or removed from the cluster dynamically and Hadoop continues to operate without interruption.
- Another big advantage of Hadoop is that apart from being open source, it is compatible on all the platforms since it is Java based.
Job opportunities and salary structures of Hadoop developers
Big data is growing at a rapid speed, and the organizations also started to depend on these data to harness the hidden insights out of it. IDC estimates that the growth of the organizations depends on how effectively they utilize Big data. To process these data organizations requires skilled human resource.
According to Forbes, the recent study shows massive growth in the percentage of industries, looking for candidates who have excellent analytical skills to drive insights from big data. Technical services, manufacturing, IT, Retail, and Finance industries are among the top in hiring the Big data professionals. The requirement in these industries may vary according to their level of usage of big data.
The median advertised salary for a professional with big data expertise is $1,24,000 per annum. There are Different jobs available in this category which are Big Data Platform Engineer, Information System developer, Software Engineer, Data Quality director and many other roles also there.
Conclusion
In this tutorial, we learned what is Hadoop, differences between RDBMS vs Hadoop, Advantages, Components, and Architecture of Hadoop.
This framework is responsible for processing big data and analyzing it. We saw MapReduce, YARN, and HDFS are working in the cluster.