
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Hadoop Architecture Tutorial
Last updated on 29th Sep 2020, Big Data, Blog, Tutorials
What Is Hadoop?
Apache Hadoop is an open-source framework to manage all types of data (Structured, Unstructured and Semi-structured).
As we all know, if we want to process, store and manage our data then RDBMS is the best solution. But, data should be in a structured format to handle it with RDBMS. Also, if the size of data increases, then RDBMS is not capable of handling it and we need to perform Database clean up regularly.
This may cause historical data loss and can’t generate accurate and reliable results in some of the industries like Weather forecast, Banking, Insurance, Sales, etc. Another problem with RDBMS is that if the main server goes down then we may lose our important data and suffer a lot.
In this tutorial, we will see how can we overcome these problems with Apache Hadoop.
Hadoop is a distributed file system and can store large volumes of data (data in petabyte and terabyte). Data processing speed is also very fast and provides reliable results as it has a very high fault-tolerance system.
Subscribe For Free Demo
Error: Contact form not found.
Hadoop is a Java-based open-source programming framework that supports the Storing and Processing of Large Data sets in a distributed computing environment.
Hadoop is based on a Cluster Concept using commodity hardware. It does not require any complex configuration and we can establish the Hadoop environment with cheaper, simple and lightweight configuration hardware.
Cluster concept in simple words is the Data that is stored in replication format on multiple machines so that when any issue or disaster happens on one of the locations where the data is residing then there must be a duplicate copy of that data available safely on another location.
Hadoop Features
We now know the exact definition of Hadoop. Let’s move one step forward and get familiarized with the terminologies that we use in Hadoop, learn its architecture and see how exactly it works on Bigdata.
Hadoop framework is based on the following concepts or modules:
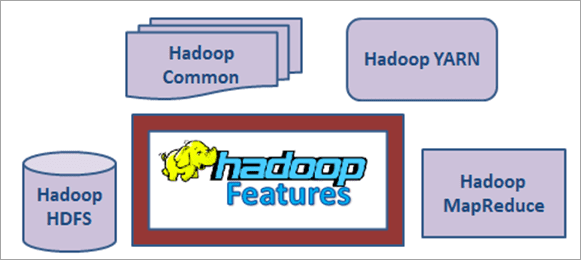
- Hadoop YARN
- Hadoop Common
- Hadoop HDFS (Hadoop Distributed File System)
- Hadoop MapReduce
1) Hadoop YARN: YARN stands for “Yet Another Resource Negotiator” that is used to manage the cluster technology of the cloud. It is used for job scheduling.
2) Hadoop Common: This is the detailed libraries or utilities used to communicate with the other features of Hadoop like YARN, MapReduce and HDFS.
3) Hadoop HDFS: Distributed File system is used in Hadoop to store and process a high volume of data. Also, it is used to access the data from the cluster.
4) Hadoop MapReduce: MapReduce is the main feature of Hadoop that is responsible for the processing of data in the cluster. It is using for job scheduling and monitoring of data processing.
Here, we have just included the definition of these features, but we will see a detailed description of all these features in our upcoming tutorials.
Apache Hadoop offers a scalable, flexible and reliable distributed computing big data framework for a cluster of systems with storage capacity and local computing power by leveraging commodity hardware. Hadoop follows a Master Slave architecture for the transformation and analysis of large datasets using Hadoop MapReduce paradigm. The 3 important hadoop components that play a vital role in the Hadoop architecture are –
- 1. Hadoop Distributed File System (HDFS) – Patterned after the UNIX file system
- 2. Hadoop MapReduce
- 3. Yet Another Resource Negotiator (YARN)
Hadoop Architecture Explained
Hadoop skillset requires thoughtful knowledge of every layer in the hadoop stack right from understanding about the various components in the hadoop architecture, designing a hadoop cluster, performance tuning it and setting up the top chain responsible for data processing.
Hadoop follows a master slave architecture design for data storage and distributed data processing using HDFS and MapReduce respectively. The master node for data storage is hadoop HDFS is the NameNode and the master node for parallel processing of data using Hadoop MapReduce is the Job Tracker. The slave nodes in the hadoop architecture are the other machines in the Hadoop cluster which store data and perform complex computations. Every slave node has a Task Tracker daemon and a DataNode that synchronizes the processes with the Job Tracker and NameNode respectively. In Hadoop architectural implementation the master or slave systems can be setup in the cloud or on-premise.

If you would like more information about Big Data and Hadoop Certification training, please click the orange “Request Info” button on top of this page.
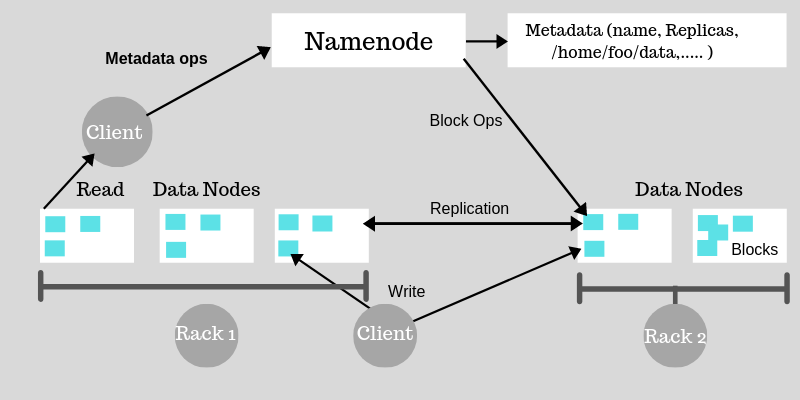
Role of Distributed Storage – HDFS in Hadoop Application Architecture Implementation
A file on HDFS is split into multiple bocks and each is replicated within the Hadoop cluster. A block on HDFS is a blob of data within the underlying file system with a default size of 64MB.The size of a block can be extended up to 256 MB based on the requirements.

Hadoop Distributed File System (HDFS) stores the application data and file system metadata separately on dedicated servers. NameNode and DataNode are the two critical components of the Hadoop HDFS architecture. Application data is stored on servers referred to as DataNodes and file system metadata is stored on servers referred to as NameNode. HDFS replicates the file content on multiple DataNodes based on the replication factor to ensure reliability of data. The NameNode and DataNode communicate with each other using TCP based protocols. For the Hadoop architecture to be performance efficient, HDFS must satisfy certain pre-requisites –
- All the hard drives should have a high throughput.
- Good network speed to manage intermediate data transfer and block replications.

Enroll in Best Big Data Hadoop Training & Certification Courses and Get Hired By TOP MNCs
Weekday / Weekend BatchesSee Batch DetailsNameNode
All the files and directories in the HDFS namespace are represented on the NameNode by Inodes that contain various attributes like permissions, modification timestamp, disk space quota, namespace quota and access times. NameNode maps the entire file system structure into memory. Two files fsimage and edits are used for persistence during restarts.
- Fsimage file contains the Inodes and the list of blocks which define the metadata.It has a complete snapshot of the file systems metadata at any given point of time.
- The edits file contains any modifications that have been performed on the content of the fsimage file.Incremental changes like renaming or appending data to the file are stored in the edit log to ensure durability instead of creating a new fsimage snapshot everytime the namespace is being altered.
When the NameNode starts, fsimage file is loaded and then the contents of the edits file are applied to recover the latest state of the file system. The only problem with this is that over the time the edits file grows and consumes all the disk space resulting in slowing down the restart process. If the hadoop cluster has not been restarted for months together then there will be a huge downtime as the size of the edits file will be increase. This is when Secondary NameNode comes to the rescue. Secondary NameNode gets the fsimage and edits log from the primary NameNode at regular intervals and loads both the fsimage and edit logs file to the main memory by applying each operation from edits log file to fsimage. Secondary NameNode copies the new fsimage file to the primary NameNode and also will update the modified time of the fsimage file to fstime file to track when then fsimage file has been updated.
DataNode
DataNode manages the state of an HDFS node and interacts with the blocks .A DataNode can perform CPU intensive jobs like semantic and language analysis, statistics and machine learning tasks, and I/O intensive jobs like clustering, data import, data export, search, decompression, and indexing. A DataNode needs lot of I/O for data processing and transfer.
On startup every DataNode connects to the NameNode and performs a handshake to verify the namespace ID and the software version of the DataNode. If either of them does not match then the DataNode shuts down automatically. A DataNode verifies the block replicas in its ownership by sending a block report to the NameNode. As soon as the DataNode registers, the first block report is sent. DataNode sends heartbeat to the NameNode every 3 seconds to confirm that the DataNode is operating and the block replicas it hosts are available.
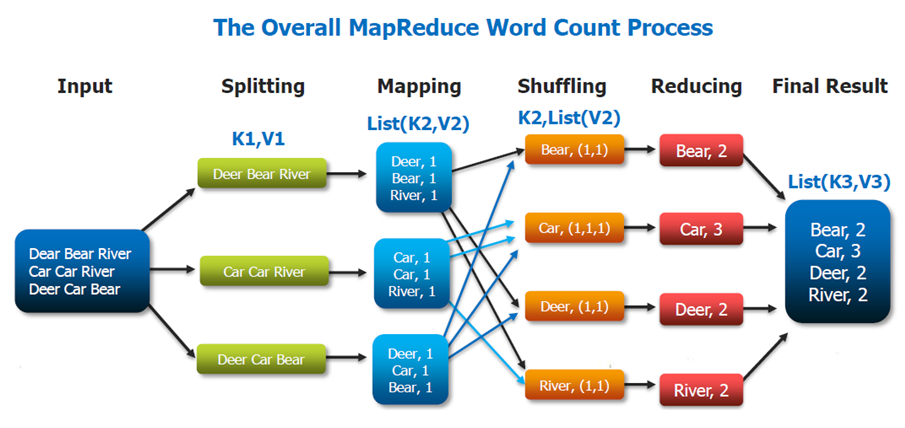
Role of Distributed Computation – MapReduce in Hadoop Application Architecture Implementation
The heart of the distributed computation platform Hadoop is its java-based programming paradigm Hadoop MapReduce. Map or Reduce is a special type of directed acyclic graph that can be applied to a wide range of business use cases. Map function transforms the piece of data into key-value pairs and then the keys are sorted where a reduce function is applied to merge the values based on the key into a single output.
How does the Hadoop MapReduce architecture work?
The execution of a MapReduce job begins when the client submits the job configuration to the Job Tracker that specifies the map, combine and reduce functions along with the location for input and output data. On receiving the job configuration, the job tracker identifies the number of splits based on the input path and select Task Trackers based on their network vicinity to the data sources. Job Tracker sends a request to the selected Task Trackers.
The processing of the Map phase begins where the Task Tracker extracts the input data from the splits. Map function is invoked for each record parsed by the “InputFormat” which produces key-value pairs in the memory buffer. The memory buffer is then sorted to different reducer nodes by invoking the combine function. On completion of the map task, Task Tracker notifies the Job Tracker. When all Task Trackers are done, the Job Tracker notifies the selected Task Trackers to begin the reduce phase. Task Tracker reads the region files and sorts the key-value pairs for each key. The reduce function is then invoked which collects the aggregated values into the output file.
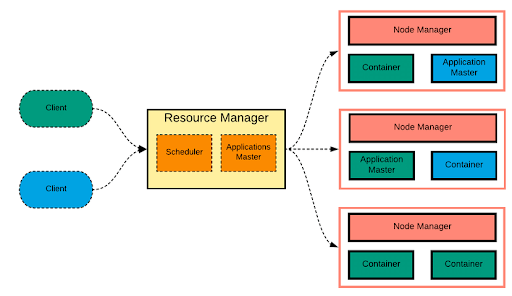
Yet Another Resource Navigator (YARN)
Apache Hadoop YARN is the job scheduling and resource management technology in the open-source Hadoop distributed processing framework. Yarn allows different data processing engines like stream processing, interactive processing, as well as batch processing to process and execute data stored in the HDFS (Hadoop Distributed File System). It is one of the core components of Hadoop that extends the power of Hadoop to other evolving technologies so that they can be benefitted from the HDFS which is the most renowned and popular storage system of the contemporary tech-world. Apart from resource management, YARN is a data operating system for Hadoop 2.x and also does job scheduling. It facilitates Hadoop to process other purpose-built data processing systems other than the MapReduce. It allows the processing of several frameworks on the same hardware where Hadoop is deployed.
Despite being thoroughly proficient at data processing and computations, Hadoop had a few shortcomings like scalability issues, delays in batch processing, etc. as it relied on MapReduce for processing big datasets. With YARN, Hadoop is now able to aid a diversity of processing approaches and has a greater array of applications. Hadoop YARN clusters are now able to stream interactive querying and run data processing side by side with MapReduce batch jobs. YARN framework runs even on the non-MapReduce applications, thus overcoming the shortcomings of Hadoop 1.0.
Advantages of Hadoop
- 1. Scalable: Hadoop is a profoundly scalable storage platform since it can store and disperse extremely datasets across several economical servers that work in parallel. In contrast to conventional relational database systems (RDBMS) that can’t scale to process a lot of data.
- 2. Cost-Effective: Hadoop likewise offers a very cost-effective storage solution for organizations detonating on datasets. The issue with Relational database management systems is that it is incredibly cost restrictive to scale to such an extent so as to process such huge volumes of data. With an end goal to diminish costs, numerous organizations in the past would have needed to down-sample data and group it depending on certain assumptions regarding which data was the most significant. The raw data would be erased, as it would be too cost-restrictive to keep.
- 3. Adaptable: Hadoop empowers organizations to effortlessly access new data sources and tap into various kinds of data (both structured and unstructured) to create an incentive from that data. This implies organizations can utilize Hadoop to get profitable business stats from data, for example, social media, email-conversations, etc.
- 4. Quick: Hadoop’s one of a storage method depends on a distributed file system that fundamentally ‘maps’ data wherever it is situated on a cluster The tools for data processing are often on the same servers where the data is located, resulting in a much faster data processing. In case you’re managing enormous volumes of unstructured data, Hadoop can proficiently process terabytes of information in just minutes.
- 5. Resilient to failure: A major advantage of using Hadoop is its adaptation to internal failure and fault tolerance. When data is sent to an individual node, that data is also replicated to other nodes in the cluster, which means that in the event of failure, there is another copy available for use.
Hadoop Architecture Design – Best Practices to Follow
- Use good-quality commodity servers to make it cost efficient and flexible to scale out for complex business use cases. One of the best configurations for Hadoop architecture is to begin with 6 core processors, 96 GB of memory and 1 0 4 TB of local hard drives. This is just a good configuration but not an absolute one.
- For faster and efficient processing of data, move the processing in close proximity to data instead of separating the two.
- Hadoop scales and performs better with local drives so use Just a Bunch of Disks (JBOD) with replication instead of redundant array of independent disks (RAID).
- Design the Hadoop architecture for multi-tenancy by sharing the compute capacity with capacity scheduler and share HDFS storage.
- Do not edit the metadata files as it can corrupt the state of the Hadoop cluster.
Facebook Hadoop Architecture
With 1.59 billion accounts (approximately 1/5th of worlds total population) , 30 million FB users updating their status at least once each day, 10+ million videos uploaded every month, 1+ billion content pieces shared every week and more than 1 billion photos uploaded every month – Facebook uses hadoop to interact with petabytes of data. Facebook runs world’s largest Hadoop Cluster with more than 4000 machine storing hundreds of millions of gigabytes of data. The biggest hadoop cluster at Facebook has about 2500 CPU cores and 1 PB of disk space and the engineers at Facebook load more than 250 GB of compressed data (is greater than 2 TB of uncompressed data) into HDFS daily and there are 100’s of hadoop jobs running daily on these datasets.
Where is the data stored at Facebook?
135 TB of compressed data is scanned daily and 4 TB compressed data is added daily. Wondering where is all this data stored? Facebook has a Hadoop/Hive warehouse with two level network topology having 4800 cores, 5.5 PB storing up to 12TB per node. 7500+ hadoop hive jobs run in production cluster per day with an average of 80K compute hours. Non-engineers i.e. analysts at Facebook use Hadoop through hive and aprroximately 200 people/month run jobs on Apache Hadoop.
Hadoop/Hive warehouse at Facebook uses a two level network topology –
- 4 Gbit/sec to top level rack switch
- 1 Gbit/sec from node to rack switch
Yahoo Hadoop Architecture
Hadoop at Yahoo has 36 different hadoop clusters spread across Apache HBase, Storm and YARN, totalling 60,000 servers made from 100’s of different hardware configurations built up over generations.Yahoo runs the largest multi-tenant hadoop installation in the world withh broad set of use cases. Yahoo runs 850,000 hadoop jobs daily.
For organizations planning to implement hadoop architecture in production, the best way to determine whether Hadoop is right for their company is – to determine the cost of storing and processing data using Hadoop. Compare the determined cost to the cost of legacy approach for managing data.
CONCLUSION
Hadoop is an open-source framework that helps in a fault-tolerant system. It can store large amounts of data and helps in storing reliable data. The two parts of storing data in HDFS and processing it through map-reduce help in working properly and efficiently. It has an architecture that helps in managing all blocks of data and also having the most recent copy by storing it in FSimage and edit logs. The replication factor also helps in having copies of data and getting them back whenever there is a failure. HDFS also moves removed files to the trash directory for optimal usage of space.