
- Different Methodologies in Project Management
- Difference between Soap and Rest | Know more about it
- What is Python array? Learn with examples
- Best Career options after Engineering | Everything You Need to Know [OverView]
- What is list in Python ? All you need to know [ OverView ]
- What is Data Modelling? : All you need to know [ OverView ]
- What are Microservices? : A Complete Guide For Beginners with Best Practices
- What is Python Programming | A Definitive Guide with Best Practices
- All You Need To Know About Python List | A Complete Guide For Beginners with Best Practices
- What Is a Software Developer | Software Developer job description and duties | Everything You Need to Know
- What is Artificial Intelligence Chatbot?
- Kotlin vs Java | Know Their Differences and Which Should You Learn?
- What is Abstraction in Java | Implementations of Abstraction in Java | A Definitive Guide with Best Practices
- What are the Important Data Structures and Algorithms in Python?
- Go vs Python | Know Their Differences and Which Should You Learn?
- Best Python IDEs and Code Editors | Expert’s Top Picks | Everything You Need to Know
- Go Programming Language | Expert’s Top Picks | A Definitive Guide [ OverView ]
- Python Scopes and Their Built-in Functions | Everything You Need to Know | Expert’s Top Picks
- Python String Formatting | A Complete Guide For Beginners [ OverView ]
- Python Serialization | A Complete Guide For Beginners | Learning Guide
- What is .Net FrameWork? Uses and its Benefits | Everything You Need to Know
- What is Quality Assurance ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- What is Spike Testing ? : A Definitive Guide | Expert’s Top Picks | Free Guide Tutorial
- Average Full Stack Developer Salary in India [ For Freshers and Experience ]
- What is WSDL in Web Services ? Expert’s Top Picks | Free Guide Tutorial
- Virtual Instrumentation using Labview | Comprehensive Guide [ Explained ]
- Gradle vs Maven | Know Their Differences and Which Should You Learn?
- Python Sleep Method | Free Guide Tutorial & REAL-TIME Examples
- Kotlin vs Python | A Complete Guide with Best Practices
- Spring Boot vs Spring MVC | Differences and Which Should You Learn?
- IT Engineer Salary in India – How much does one earn?
- What is pip ? and Getting Started with Python pip | All you need to know [ OverView ]
- Node.js Installation on Windows and Ubuntu | Free Guide Tutorial
- Skills Needed for Full Stack Developers | All you need to know [ OverView ]
- What is Axios in React? and Its Uses [ OverView ]
- What is MEAN Stack? All you need to know [ OverView ]
- How to Install Node.JS on Ubuntu | Everything You Need to Know
- Average Annual Salary of a Python Certified Professional – Career Path
- What is Scala Programming? A Complete Guide with Best Practices
- What Is User Input in Python? Expert’s Top Picks
- Interface vs Abstract Class | Difference You Should Know
- Final Year Computer Science Project Ideas | All you need to know [ OverView ]
- Technical Architect | Free Guide Tutorial & REAL-TIME Examples
- Logical Programs in Java | Step-By-Step Process
- C++ vs Java | Difference You Should Know
- What is C Programming? Comprehensive Guide
- What Is a Quality Engineer? ( Everything You Need to Know )
- Python Project Ideas for Beginners | All you need to know
- How to Run Python Scripts? Comprehensive Guide
- Python Operators
- How To Install NumPy in Python?
- Top Software Courses to Get High Paying Jobs
- Loops In Python
- Tips to Avoid Application Rejection
- Top Young App Developers Who Became Millionaires
- Top Technical Courses After Graduation
- Node JS Architecture
- What is PyCharm?
- Resources To Help You Learn Java Programming
- How to Become a Software Engineer?
- Best Programming Languages to Learn in 2020
- Scala vs Python
- How to Become a Full Stack Developer?
- The Most Popular Java Applications Used World-wide
- What is Java String?
- Full Stack Developer vs Front End Developer vs Back End Developer
- Python Collections
- Identifiers in Python
- Dynamic Method Dispatch in Java
- Hadoop Ecosystem
- Method Overloading in Python
- Convert Decimal To Binary In Python
- How To Make A Chatbot In Python?
- How to Input a List in Python?
- Hash Tables and Hashmaps in Python
- Top Python Framework’s
- Python Split Method with Example
- Python Enumerate
- Inheritance in Java
- Init in Python
- Goto Statement in Python
- Literals in Java
- Polymorphism in Oops
- Socket Programming in Python
- Object Class in Java
- Break, Continue, and Pass Statements in Python
- Exception Handling in Java
- Java BASIC Programs
- Different Methodologies in Project Management
- Difference between Soap and Rest | Know more about it
- What is Python array? Learn with examples
- Best Career options after Engineering | Everything You Need to Know [OverView]
- What is list in Python ? All you need to know [ OverView ]
- What is Data Modelling? : All you need to know [ OverView ]
- What are Microservices? : A Complete Guide For Beginners with Best Practices
- What is Python Programming | A Definitive Guide with Best Practices
- All You Need To Know About Python List | A Complete Guide For Beginners with Best Practices
- What Is a Software Developer | Software Developer job description and duties | Everything You Need to Know
- What is Artificial Intelligence Chatbot?
- Kotlin vs Java | Know Their Differences and Which Should You Learn?
- What is Abstraction in Java | Implementations of Abstraction in Java | A Definitive Guide with Best Practices
- What are the Important Data Structures and Algorithms in Python?
- Go vs Python | Know Their Differences and Which Should You Learn?
- Best Python IDEs and Code Editors | Expert’s Top Picks | Everything You Need to Know
- Go Programming Language | Expert’s Top Picks | A Definitive Guide [ OverView ]
- Python Scopes and Their Built-in Functions | Everything You Need to Know | Expert’s Top Picks
- Python String Formatting | A Complete Guide For Beginners [ OverView ]
- Python Serialization | A Complete Guide For Beginners | Learning Guide
- What is .Net FrameWork? Uses and its Benefits | Everything You Need to Know
- What is Quality Assurance ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- What is Spike Testing ? : A Definitive Guide | Expert’s Top Picks | Free Guide Tutorial
- Average Full Stack Developer Salary in India [ For Freshers and Experience ]
- What is WSDL in Web Services ? Expert’s Top Picks | Free Guide Tutorial
- Virtual Instrumentation using Labview | Comprehensive Guide [ Explained ]
- Gradle vs Maven | Know Their Differences and Which Should You Learn?
- Python Sleep Method | Free Guide Tutorial & REAL-TIME Examples
- Kotlin vs Python | A Complete Guide with Best Practices
- Spring Boot vs Spring MVC | Differences and Which Should You Learn?
- IT Engineer Salary in India – How much does one earn?
- What is pip ? and Getting Started with Python pip | All you need to know [ OverView ]
- Node.js Installation on Windows and Ubuntu | Free Guide Tutorial
- Skills Needed for Full Stack Developers | All you need to know [ OverView ]
- What is Axios in React? and Its Uses [ OverView ]
- What is MEAN Stack? All you need to know [ OverView ]
- How to Install Node.JS on Ubuntu | Everything You Need to Know
- Average Annual Salary of a Python Certified Professional – Career Path
- What is Scala Programming? A Complete Guide with Best Practices
- What Is User Input in Python? Expert’s Top Picks
- Interface vs Abstract Class | Difference You Should Know
- Final Year Computer Science Project Ideas | All you need to know [ OverView ]
- Technical Architect | Free Guide Tutorial & REAL-TIME Examples
- Logical Programs in Java | Step-By-Step Process
- C++ vs Java | Difference You Should Know
- What is C Programming? Comprehensive Guide
- What Is a Quality Engineer? ( Everything You Need to Know )
- Python Project Ideas for Beginners | All you need to know
- How to Run Python Scripts? Comprehensive Guide
- Python Operators
- How To Install NumPy in Python?
- Top Software Courses to Get High Paying Jobs
- Loops In Python
- Tips to Avoid Application Rejection
- Top Young App Developers Who Became Millionaires
- Top Technical Courses After Graduation
- Node JS Architecture
- What is PyCharm?
- Resources To Help You Learn Java Programming
- How to Become a Software Engineer?
- Best Programming Languages to Learn in 2020
- Scala vs Python
- How to Become a Full Stack Developer?
- The Most Popular Java Applications Used World-wide
- What is Java String?
- Full Stack Developer vs Front End Developer vs Back End Developer
- Python Collections
- Identifiers in Python
- Dynamic Method Dispatch in Java
- Hadoop Ecosystem
- Method Overloading in Python
- Convert Decimal To Binary In Python
- How To Make A Chatbot In Python?
- How to Input a List in Python?
- Hash Tables and Hashmaps in Python
- Top Python Framework’s
- Python Split Method with Example
- Python Enumerate
- Inheritance in Java
- Init in Python
- Goto Statement in Python
- Literals in Java
- Polymorphism in Oops
- Socket Programming in Python
- Object Class in Java
- Break, Continue, and Pass Statements in Python
- Exception Handling in Java
- Java BASIC Programs

Hadoop Ecosystem
Last updated on 25th Sep 2020, Artciles, Blog, Software Engineering
Hadoop Ecosystem
Hadoop is a framework which deals with Big Data but unlike any other framework it’s not a simple framework, it has its own family for processing different things which is tied up in one umbrella called the Hadoop Ecosystem.
The Hadoop Ecosystem is neither a programming language nor a service; it is a platform or framework which solves big data problems. You can consider it as a suite that encompasses a number of services (ingesting, storing, analyzing, and maintaining) inside it
Subscribe For Free Demo
Error: Contact form not found.
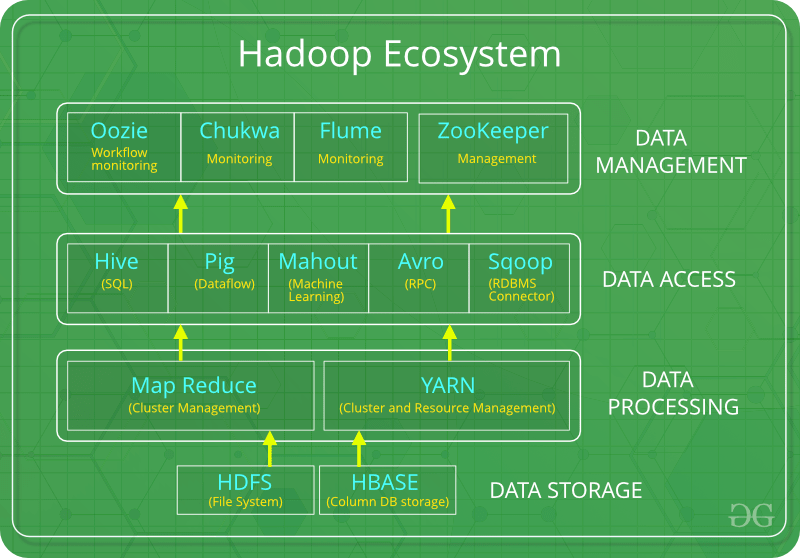
Components of Hadoop Ecosystem
As we have seen an overview of Hadoop Ecosystem and well-known open-source examples, now we are going to discuss the list of Hadoop Components individually and their specific roles in big data processing.
The components of Hadoop ecosystems are:
- 1.HDFS
- 2.HBASE
- 3.YARN
- 4.Sqoop
- 5.Apache Flume
- 6.Hadoop Map Reduce
- 7.Apache Pig
- 8.Hive
- 9.Apache Drill
- 10.Apache Zookeeper
- 11.Oozie
HDFS
Hadoop Distributed File System is the backbone of Hadoop which runs on java language and stores data in Hadoop applications. They act as a command interface to interact with Hadoop. the two components of HDFS – Data node, Name Node. Name node the main node manages file systems and operates all data nodes and maintains records of metadata updating. In case of deletion of data, they automatically record it in Edit Log. Data Node (Slave Node) requires vast storage space due to the performance of reading and write operations. They work according to the instructions of the Name Node. The data nodes are hardware in the distributed system.
HBASE
It is an open-source framework storing all types of data and doesn’t support the SQL database. They run on top of HDFS and are written in java language. Most companies use them for its features like supporting all types of data, high security, use of HBase tables. They play a vital role in analytical processing. The two major components of HBase are HBase master, Regional Server. The HBase master is responsible for load balancing in a Hadoop cluster and controls the failover. They are responsible for performing administration roles. The role of the regional server would be a worker node and responsible for reading, writing data in the cache.
YARN
It’s an important component in the ecosystem and called an operating system in Hadoop which provides resource management and job scheduling tasks. The components are Resource and Node manager, Application manager and container. They also act as guards across Hadoop clusters. They help in the dynamic allocation of cluster resources, increase in the data center process and allow multiple access engines.
Sqoop
It is a tool that helps in data transfer between HDFS and MySQL and gives hand-on to
import and export data, they have a connector for fetching and connecting data.
Apache Spark
It is an open-source cluster computing framework for data analytics and an essential data processing engine. It is written in Scala and comes with packaged standard libraries. They are used by many companies for their high processing speed and stream processing.
Apache Flume
It is a distributed service collecting a large amount of data from the source (web server) and moves back to its origin and transferred to HDFS. The three components are Source, sink, and channel.
Hadoop Map Reduce
It is responsible for data processing and acts as a core component of Hadoop. Map Reduce is a processing engine that does parallel processing in multiple systems of the same cluster. This technique is based on the divide and conquers method and it is written in java programming. Due to parallel processing, it helps in the speedy process to avoid congestion traffic and efficiently improves data processing.
Apache Pig
Data Manipulation of Hadoop is performed by Apache Pig and uses Pig Latin Language. It helps in the reuse of code and easy to read and write code.
Hive
It is an open-source Platform software for performing data warehousing concepts, it manages to query large data sets stored in HDFS. It is built on top of the Hadoop Ecosystem. The language used by Hive is the Hive Query language. The user submits the hive queries with metadata which converts SQL into Map-reduce jobs and given to the Hadoop cluster which consists of one master and many numbers of slaves.
Apache Drill
Apache Drill is an open-source SQL engine which processes non-relational databases and File systems. They are designed to support Semi-structured databases found in Cloud storage. They have good Memory management capabilities to maintain garbage collection. The added features include Columnar representation and using distributed joins.
Apache Zookeeper
It is an API that helps in distributed Coordination. Here a node called Znode is created by an application in the Hadoop cluster. They do services like Synchronization, Configuration. It sorts out the time-consuming coordination in the Hadoop Ecosystem.
Oozie
Oozie is a java web application that maintains many workflows in a Hadoop cluster. Having Web service APIs controls over a job is done anywhere. It is popular for handling Multiple jobs effectively.
Conclusion
This concludes a brief introductory note on Hadoop Ecosystem. Apache Hadoop has gained popularity due to its features like analyzing stack of data, parallel processing and helps in Fault Tolerance. The core components of Ecosystems involve Hadoop common, HDFS, Map-reduce and Yarn. To build an effective solution. It is necessary to learn a set of Components, each component does their unique job as they are the Hadoop Functionality.