
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Apache Impala Tutorial
Last updated on 12th Oct 2020, Big Data, Blog, Tutorials
Basically, to overcome the slowness of Hive Queries, Cloudera offers a separate tool and that tool is what we call Impala. However, there is much more to know about the Impala. So, in this Impala Tutorial for beginners, we will learn the whole concept of Cloudera Impala. It includes Impala’s benefits, working as well as its features.
Subscribe For Free Demo
Error: Contact form not found.
Apache Impala
- Apache Impala is a massively parallel processing query engine that executes on the Hadoop platform. It is an open source software, which was developed on the basis of Google’s Dremel paper.
- It is an interactive SQL like query engine that runs on top of Hadoop Distributed File System (HDFS). Moreover, Impala is used as a scalable parallel database technology provided to Hadoop, which enables the users to issue low-latency SQL queries to the data stored in HDFS and Apache HBase without requiring data movement or transformation.
- Impala integrates with the Apache Hive metastore database to share database table information between both the components. Analysts and Data Scientists perform analytical operations on data stored in Hadoop and advertises it via SQL tools. It helps to provide large-scale data processing (via MapReduce), and interactive queries. Furthermore, it can be processed on the same system using the same data and metadata, which helps to eliminate the need to shift data sets into specialized systems.
Reasons for using Apache Impala
- 1. Apache Impala combines flexibility and scalability of Hadoop with the SQL support and multi-user performance of the traditional analytic database, by using components such as HDFS, Metastore, HBase, Sentry, and YARN.
- 2. With Apache Impala, users can easily communicate with the HDFS or HBase by using SQL like queries in a faster way as compared to the other SQL engines like Apache Hive.
- 3. Apache Impala can read almost every file format like Parquet, RCFile, Avro, used by Apache Hadoop.
- 4. Moreover, it uses the same SQL syntax (Hive SQL), metadata, user interface, and ODBC driver as Apache Hive, thus providing a familiar and unified platform for the batch-oriented or the real-time queries.
- 5. Also, Impala is not based on the MapReduce algorithms like Apache Hive does. It implements a distributed architecture based on the daemon processes that are responsible for all the aspects of the query execution. Thus this reduces the latency of using MapReduce and makes Apache Impala faster and better than Apache Hive.
Where to use Apache Impala
- When there is a need for the low latent results, we can use Impala.
- When we need to analyze the partial data, then we can use Apache Impala.
- For doing any quick analysis, we can opt for Impala.
- We can use Apache Impala when we need to obtain results in real-time.
- Apache Impala is best when we need to process the same kind of queries several times.
Architecture of Apache Impala
The above image depicts Impala Architecture. Apache Impala runs on the number of systems in the Apache Hadoop cluster. Unlike the traditional storage systems, Apache impala is not coupled with its storage engine. It is decoupled with its storage engine. Impala has three core components, that are, Impala daemon (Impalad), Impala Statestore, and the Impala Catalog services.
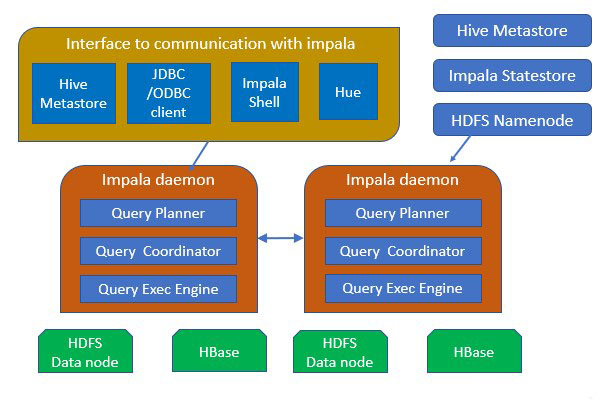
Let us see each one in detail.
1. Impala Daemon
Impala daemon is the core component of Apache Impala. It is physically represented by an impalad process. Impala daemon runs on each machine where Impala is installed. The main functions of Impala daemon are:
- It performs reads and writes to the data files.
- It accepts the queries transferred from the impala-shell command, JDBC, Hue, or ODBC.
- Impala Daemon parallelizes the queries and distributes the work across the Hadoop cluster.
- It transmits the intermediate query results back to the central coordinator.
- The Impala daemons constantly communicate with the StateStore in order to confirm which daemons are healthy and are ready to accept new work.
- Also, Impala daemons receive the broadcast messages from the catalog daemon (discussed below) whenever
- Any of the Impala daemon either creates, drops, or alters, any type of object.
- When Impala processes the INSERT or the LOAD DATA statement.
We can deploy Impala daemons in one of the following ways:
- 1. Co-locate HDFS and Impala, and each Impala daemon should run on the same host as the DataNode.
- 2. Deploy Impala separately in a compute cluster, and it can read data remotely from the HDFS, S3, ADLS, etc.
2. Impala Statestore
Impala Statestore is the one who checks on the health of all the Impala daemons in the cluster, and continuously passes on its findings to each of the Impala daemons. The Impala Statestore is physically represented by the daemon process named statestored. We only need a statestore process on one host in the cluster. So, if any of the Impala daemon goes offline because of a network error, hardware failure, software issue, or any other reason, then the Impala StateStore informs all the other Impala daemons. This is done to ensure that the future queries do not make requests to the failed Impala daemon.
Impala Statestore is not always critical for the normal operation of the Impala cluster. If in case the StateStore is not running, then also the Impala daemons will run and distribute the work among themselves as usual. In this case, the cluster becomes less robust when the other Impala daemons fail, and the metadata will become less consistent. When the Impala StateStore comes back, then it re-establishes the communication with all the Impala daemons and continues its monitoring and broadcasting functions.

Get Accredited Pega Certification Course By Experts Training
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
3. Impala Catalog Service
The Catalog Service is another Impala component that passes the metadata changes from the Impala SQL statements to all the Impala daemons in the cluster. The Impala Catalog Service is physically represented by the daemon process named catalog.
We only need a catalog process on the one host in the cluster. Since the requests are passed via the StateStore daemon, it is best to run the statestored and catalogued process on the same host.
The Impala catalog service prevents the need for issuing REFRESH and the INVALIDATE METADATA statements when the metadata changes were performed by the statements issued through Apache Impala.
When we create a table or load data through Apache Hive, then we have to issue the REFRESH or the INVALIDATE METADATA on the Impala node before executing any query there.
Note:
The features like load balancing and high availability are applied to an impala daemon. The process such as statestored and catalogued do not have any special requirements for the high availability, because failure in any of them does not result in the data loss. If any of these two daemons become unavailable because of an outage on the particular host, then we can stop the Impala service by:
- Deleting the Impala StateStore and the Impala Catalog Server roles,
- And then adding the roles on the different host,
- And finally restarting the Impala service.
Data Storage in Apache Impala
Apache Impala uses two media to store its data: Hadoop Distributed File System or HDFS and HBase.
Hadoop Distributed File System or HDFS:
- Impala depends on the redundancy provided by HDFS to protect from hardware or network outages on individual nodes.
- In HDFS, Impala table data is represented as data files in HDFS file formats and compression codecs. For creating a new table, Impala reads these files regardless of their file names. New data is added in the files with names controlled by Impala.
HBase:
- It is a database storage system built on top of HDFS without built-in SQL support.
- It provides an alternative storage medium for Impala data. When you define a table in Impala and map it to its equivalent table in HBase, you can query the data of the HBase tables through Impala.
- In addition, you can perform join queries including both Impala and HBase tables.
Impala Shell Commands
The Impala Shell Commands were classified into three categories:
- 1. General Commands
- 2. Query specific options
- 3. Table and Database-specific options
Let us now explore each in detail.
General Commands
- help : The Impala shell command help gives us the complete list of all the commands available in Apache Impala.
- version : The Impala shell command version gives us the current version of the Impala.
- history : The Impala shell command history displays the last 10 commands that are executed in the Impala shell
- connect : The Impala shell command connect is used for connecting to the given instance of Impala. If we do not specify any instance, then by default, it will connect to the default port 21000.
- exit | quit : We use the exit or quit command for coming out of the Impala shell.
Query specific options
- profile: The Impala shell command profile displays the low-level information related to the recent query. We used this command for diagnosis and the performance tuning of the query.
- explain: The Impala shell command explain returns the execution plan for a given query.
Table and Database specific options
- alter: The Impala shell command alter modifies the structure and the name of the table in Impala.
- describe : The Impala shell command describe gives the metadata information of a table. It contains information such as columns and their data types.
- drop: The Impala shell command drop removes the construct from Impala. The construct can be a table, a database function, or a view.
- insert : The Impala shell command insert appends the data (columns) into the table or for overriding the data of the existing table.
- select : The Impala shell command select is used for performing the desired operation on the particular dataset. This command selects the dataset on which we have to perform some action.
- show : The Impala shell command show displays the metastore of the constructs like tables, databases, etc.
- use : The Impala shell command use changes the current context to the desired database.
Impala Features
Impala provides support for:
1. Impala offers support for most common SQL-92 features of Hive Query Language (HiveQL). It includes SELECT, joins, and aggregate functions.
2. Moreover, it also provides support for HDFS, HBase, and Amazon Simple Storage System (S3) storage. It includes:
- HDFS file formats: delimited text files, Parquet, Avro, SequenceFile, and RCFile.
- Compression codecs: Snappy, GZIP, Deflate, BZIP.
3. Also, supports common data access interfaces. Includes:
- JDBC driver.
- ODBC driver.
4. However, it supports Hue Beeswax and the Impala Query UI.
5. Also, supports impala-shell command-line interface.
6. Moreover, supports Kerberos authentication.
Benefits of Apache Impala
Following are some of the benefits of Impala:
- Impala is a flexible engine that integrates well with the existing Hadoop components. This enables the use of files stored in HDFS, different data formats available in HDFS, security, metadata and storage management used by MapReduce, Apache Hive, and other Hadoop software.
- Further, Impala adds capabilities that make SQL querying easier than before.
- The Impala architecture also enhances SQL query speed on Hadoop data. The fast turnaround of Impala queries enables new categories of solutions.
- Impala introduces high flexibility to the familiar database Extract, Transform, and Load process. You can access data with a combination of different Impala and Hadoop components without duplicating or converting the data.
- When the query speed is slow, use the Parquet (pahr-key) columnar file format for a faster response. This format easily reorganizes data for maximum performance of data warehouse-style queries.
- For users and business intelligence tools that use SQL, Impala introduces an effective development model to handle new kinds of analysis.
- The combination of Big Data and Impala makes SQL easy to use. Impala also provides flexibility for your Big Data workflow. SQL capabilities of Impala, such as filtering, calculating, sorting, and formatting, let you perform these operations in Impala. This helps organize the query results for presentation.
Advantages of Impala
There are several advantages of Impala which are given as follows:-
- 1. Fast Speed: We can process data in HDFS at very fast speed by using Impala.
- 2. Migrating data is not necessary: We don’t need to transform and move data stored on Hadoop even if the data processing is carried where the data resides.
- 3. Big Data: A user can easily store and manage a large amount of data.
- 4. Languages: Impala does not have issues with language support, because it supports all languages.
- 5. High Performance: It offers high performance and low latency tasks for Hadoop.
- 6. Distributed: It provides a distributive environment in which a query is distributed among different clusters for reducing workload and provides convenient scalability.
- 7. Easy Access: We can easily access the data that is stored in HDFS, HBase, and Amazon s3 without requiring the knowledge of Java.