
- Must-Know [LATEST] Apache NiFi Interview Questions and Answers
- [SCENARIO-BASED ] Mahout Interview Questions and Answers
- 40+ [REAL-TIME] Apache Ambari Interview Questions and Answers
- [50+] Big Data Greenplum DBA Interview Questions and Answers
- 40+ [REAL-TIME] Informatica Analyst Interview Questions and Answers
- Must-Know [LATEST] FileNet Interview Questions and Answers
- 20+ Must-Know SAS Grid Administration Interview Questions
- [SCENARIO-BASED ] Apache Flume Interview Questions and Answers
- Top Storm Interview Questions and Answers [ TO GET HIRED ]
- Cassandra Interview Questions and Answers
- Sqoop Interview Questions and Answers
- kafka Interview Questions and Answers
- Hive Interview Questions and Answers
- Big Data Hadoop Interview Questions and Answers
- Elasticsearch Interview Questions and Answers
- HDFS Interview Questions and Answers
- HBase Interview Questions and Answers
- MapReduce Interview Questions and Answers
- Pyspark Interview Questions and Answers
- Hadoop Interview Questions and Answers
- Apache Spark Interview Questions and Answers
- Must-Know [LATEST] Apache NiFi Interview Questions and Answers
- [SCENARIO-BASED ] Mahout Interview Questions and Answers
- 40+ [REAL-TIME] Apache Ambari Interview Questions and Answers
- [50+] Big Data Greenplum DBA Interview Questions and Answers
- 40+ [REAL-TIME] Informatica Analyst Interview Questions and Answers
- Must-Know [LATEST] FileNet Interview Questions and Answers
- 20+ Must-Know SAS Grid Administration Interview Questions
- [SCENARIO-BASED ] Apache Flume Interview Questions and Answers
- Top Storm Interview Questions and Answers [ TO GET HIRED ]
- Cassandra Interview Questions and Answers
- Sqoop Interview Questions and Answers
- kafka Interview Questions and Answers
- Hive Interview Questions and Answers
- Big Data Hadoop Interview Questions and Answers
- Elasticsearch Interview Questions and Answers
- HDFS Interview Questions and Answers
- HBase Interview Questions and Answers
- MapReduce Interview Questions and Answers
- Pyspark Interview Questions and Answers
- Hadoop Interview Questions and Answers
- Apache Spark Interview Questions and Answers

Big Data Hadoop Interview Questions and Answers
Last updated on 14th Oct 2020, Big Data, Blog, Interview Question
Hadoop is an open source, Java based framework used for storing and processing big data. The data is stored on inexpensive commodity servers that run as clusters. Its distributed file system enables concurrent processing and fault tolerance. Developed by Doug Cutting and Michael J. Cafarella, Hadoop uses the MapReduce programming model for faster storage and retrieval of data from its nodes. The framework is managed by Apache Software Foundation and is licensed under the Apache License 2.0
1. What do the four V’s of Big Data denote?
Ans:
IBM has a nice, simple explanation for the four critical features of big data:
- 1. Volume – Scale of data
- 2. Velocity – Analysis of streaming data
- 3. Variety – Different forms of data
- 4. Veracity – Uncertainty of data
2. How big data analysis helps businesses increase their revenue? Give examples.
Ans:
Big data analysis is helping businesses differentiate themselves – for example Walmart the world’s largest retailer in 2014 in terms of revenue – is using big data analytics to increase its sales through better predictive analytics, providing customized recommendations and launching new products based on customer preferences and needs. Walmart observed a significant 10% to 15% increase in online sales for $1 billion in incremental revenue. There are many more companies like Facebook, Twitter, LinkedIn, Pandora, JPMorgan Chase, Bank of America, etc. using big data analytics to boost their revenue.
3. Name some companies that use Hadoop.
Ans:
- Yahoo
- Netflix
- Amazon
- Adobe
- eBay
- Hulu
- Spotify
- Rubikloud
4. Differentiate between Structured and Unstructured data.
Ans:
Data which can be stored in traditional database systems in the form of rows and columns, for example the online purchase transactions can be referred to as Structured Data. Data which can be stored only partially in traditional database systems, for example, data in XML records can be referred to as semi structured data. Unorganized and raw data that cannot be categorized as semi structured or structured data is referred to as unstructured data. Facebook updates, Tweets on Twitter, Reviews, web logs, etc. are all examples of unstructured data.
5. What is a SequenceFile in Hadoop?
Ans:
Extensively used in MapReduce I/O formats, SequenceFile is a flat file containing binary key–value pairs. The map outputs are stored as SequenceFile internally. It provides Reader, Writer, and Sorter classes. The three SequenceFile formats are as follows:
- 1. Uncompressed key : value records
- 2. Record compressed key–value records : only ‘values’ are compressed here
- 3. Block compressed key–value records : both keys and values are collected in ‘blocks’ separately and compressed. The size of the ‘block’ is configurable
6. What is the role of a JobTracker in Hadoop?
Ans:
A JobTracker’s primary function is resource management (managing the TaskTrackers), tracking resource availability, and task life cycle management (tracking the tasks’ progress and fault tolerance).
- It is a process that runs on a separate node, often not on a DataNode.
- The JobTracker communicates with the NameNode to identify data location.
- It finds the best TaskTracker nodes to execute the tasks on the given nodes.
- It monitors individual TaskTrackers and submits the overall job back to the client.
- It tracks the execution of MapReduce workloads local to the slave node.
7. What is the use of RecordReader in Hadoop?
Ans:
Though InputSplit defines a slice of work, it does not describe how to access it. Here is where the RecordReader class comes into the picture, which takes the byte-oriented data from its source and converts it into record-oriented key–value pairs such that it is fit for the Mapper task to read it. Meanwhile, InputFormat defines this Hadoop RecordReader instance.
8. What is Speculative Execution in Hadoop?
Ans:
One limitation of Hadoop is that by distributing the tasks on several nodes, there are chances that few slow nodes limit the rest of the program. There are various reasons for the tasks to be slow, which are sometimes not easy to detect. Instead of identifying and fixing the slow-running tasks, Hadoop tries to detect when the task runs slower than expected and then launches other equivalent tasks as backup. This backup mechanism in Hadoop is speculative execution.
It creates a duplicate task on another disk. The same input can be processed multiple times in parallel. When most tasks in a job come to completion, the speculative execution mechanism schedules duplicate copies of the remaining tasks (which are slower) across the nodes that are free currently. When these tasks are finished, it is intimated to the JobTracker. If other copies are executing speculatively, Hadoop notifies the TaskTrackers to quit those tasks and reject their output.
Speculative execution is by default true in Hadoop.
To disable it, we can set
mapred.map.tasks.speculative.execution
and mapred.reduce.tasks.speculative.execution
JobConf options false.
9. What happens if you try to run a Hadoop job with an output directory that is already present?
Ans:
It will throw an exception saying that the output file directory already exists. To run the MapReduce job, you need to ensure that the output directory does not exist in the HDFS.
To delete the directory before running the job, we can use shell:
Hadoop fs –rmr /path/to/your/output/
Or the Java API:
- FileSystem.getlocal(conf).delete(outputDir, true);
10. How can you debug Hadoop code?
Ans:
First, we should check the list of MapReduce jobs currently running. Next, we need to see that there are no orphaned jobs running; if yes, we need to determine the location of RM logs.
Run:
ps –ef | grep –I ResourceManager
Then, look for the log directory in the displayed result. We have to find out the job ID from the displayed list and check if there is any error message associated with that job.
On the basis of RM logs, we need to identify the worker node that was involved in the execution of the task.
Now, we will login to that node and run the below code:
- ps –ef | grep –iNodeManager
Then, we will examine the Node Manager log. The majority of errors come from the user-level logs for each MapReduce job.
11. How to configure Replication Factor in HDFS?
Ans:
The hdfs-site.xml file is used to configure HDFS. Changing the dfs.replication property in hdfs-site.xml will change the default replication for all the files placed in HDFS.
We can also modify the replication factor on a per-file basis using the below:
Hadoop FS Shell:
- [training@localhost ~]$ hadoopfs –setrep –w 3 /my/fileConversely,
We can also change the replication factor of all the files under a directory.
- [training@localhost ~]$ hadoopfs –setrep –w 3 -R /my/dir
12. How to compress a Mapper output not touching Reducer output?
Ans:
To achieve this compression, we should set:
- conf.set(“mapreduce.map.output.compress”, true)
- conf.set(“mapreduce.output.fileoutputformat.compress”, false)
13. What is the difference between Map-side Join and Reduce-side Join?
Ans:
Map-side Join at Map side is performed when data reaches the Map. We need a strict structure for defining Map-side Join.
On the other hand, Reduce-side Join (Repartitioned Join) is simpler than Map-side Join since here the input datasets need not be structured. However, it is less efficient as it will have to go through sort and shuffle phases, coming with network overheads.
Subscribe For Free Demo
Error: Contact form not found.
14. How can you transfer data from Hive to HDFS?
Ans:
By writing the query:
- hive> insert overwrite directory ‘/’ select * from emp;
We can write our query for the data we want to import from Hive to HDFS. The output we receive will be stored in part files in the specified HDFS path.
15. What are the main components of a Hadoop Application?
Ans:
Hadoop applications have a wide range of technologies that provide great advantage in solving complex business problems.
Core components of a Hadoop application are-
- 1. Hadoop Common
- 2. HDFS
- 3. Hadoop MapReduce
- 4. YARN
Data Access Components are – Pig and Hive
Data Storage Component is – HBase
Data Integration Components are – Apache Flume, Sqoop, Chukwa
Data Management and Monitoring Components are – Ambari, Oozie and Zookeeper.
Data Serialization Components are – Thrift and Avro
Data Intelligence Components are – Apache Mahout and Drill.
16. What is Hadoop streaming?
Ans:
Hadoop distribution has a generic application programming interface for writing Map and Reduce jobs in any desired programming language like Python, Perl, Ruby, etc. This is referred to as Hadoop Streaming. Users can create and run jobs with any kind of shell script or executable as the Mapper or Reducers. The latest tool for Hadoop streaming is Spark.
17. What is the best hardware configuration to run Hadoop?
Ans:
The best configuration for executing Hadoop jobs is dual core machines or dual processors with 4GB or 8GB RAM that use ECC memory. Hadoop highly benefits from using ECC memory though it is not low – end. ECC memory is recommended for running Hadoop because most of the Hadoop users have experienced various checksum errors by using non ECC memory. However, the hardware configuration also depends on the workflow requirements and can change accordingly.
18. What are the most commonly defined input formats in Hadoop?
Ans:
The most common Input Formats defined in Hadoop are:
Text Input Format- This is the default input format defined in Hadoop.
Key Value Input Format- This input format is used for plain text files wherein the files are broken down into lines.
Sequence File Input Format- This input format is used for reading files in sequence.
19. What are the steps involved in deploying a big data solution?
Ans:
i) Data Ingestion – The foremost step in deploying big data solutions is to extract data from different sources which could be an Enterprise Resource Planning System like SAP, any CRM like Salesforce or Siebel , RDBMS like MySQL or Oracle, or could be the log files, flat files, documents, images, social media feeds. This data needs to be stored in HDFS. Data can either be ingested through batch jobs that run every 15 minutes, once every night and so on or through streaming in real-time from 100 ms to 120 seconds.
ii) Data Storage – The subsequent step after ingesting data is to store it either in HDFS or NoSQL databases like HBase. HBase storage works well for random read/write access whereas HDFS is optimized for sequential access.
iii) Data Processing – The ultimate step is to process the data using one of the processing frameworks like mapreduce, spark, pig, hive, etc.
20. How will you choose various file formats for storing and processing data using Apache Hadoop ?
Ans:
The decision to choose a particular file format is based on the following factors-
- 1. Schema evolution to add, alter and rename fields.
- 2. Usage patterns like accessing 5 columns out of 50 columns vs accessing most of the columns.
- 3. Splitability to be processed in parallel.
- 4. Read/Write/Transfer performance vs block compression saving storage space
21. Give the different file formats used with hadoop.
Ans:
File Formats that can be used with Hadoop – CSV, JSON, Columnar, Sequence files, AVRO, and Parquet file.
CSV Files- CSV files are an ideal fit for exchanging data between hadoop and external systems. It is advisable not to use header and footer lines when using CSV files.
JSON Files- Every JSON File has its own record. JSON stores both data and schema together in a record and also enables complete schema evolution and splitability. However, JSON files do not support block level compression.
Avro FIles- This kind of file format is best suited for long term storage with Schema. Avro files store metadata with data and also let you specify an independent schema for reading the files.
Parquet Files- A columnar file format that supports block level compression and is optimized for query performance as it allows selection of 10 or less columns from 50+ columns records.
22. What are the differences between Hadoop and Spark?
Ans:
| Criteria | Hadoop | Spark |
|---|---|---|
| Dedicated storage | HDFS | None |
| Speed of processing | Average | Excellent |
| Libraries | Separate tools available | Spark Core, SQL, Streaming, MLlib, and GraphX |
23. What are the real-time industry applications of Hadoop?
Ans:
Hadoop, well known as Apache Hadoop, is an open-source software platform for scalable and distributed computing of large volumes of data. It provides rapid, high performance, and cost-effective analysis of structured and unstructured data generated on digital platforms and within the enterprise. It is used in almost all departments and sectors today.
Here are some of the instances where Hadoop is used:
- 1. Managing traffic on streets
- 2. Streaming processing
- 3. Content management and archiving emails
- 4. Processing rat brain neuronal signals using a Hadoop computing cluster
- 5. Fraud detection and prevention
- 6. Advertisements targeting platforms are using Hadoop to capture and analyze clickstream, transaction, video, and social media data
- 7. Managing content, posts, images, and videos on social media platforms
- 8. Analyzing customer data in real time for improving business performance
- 8. Public sector fields such as intelligence, defense, cyber security, and scientific research
- 10. Getting access to unstructured data such as output from medical devices, doctor’s notes, lab results, imaging reports, medical correspondence, clinical data, and financial data
24. How is Hadoop different from other parallel computing systems?
Ans:
Hadoop is a distributed file system that lets you store and handle massive amounts of data on a cloud of machines, handling data redundancy.
The primary benefit of this is that since data is stored in several nodes, it is better to process it in a distributed manner. Each node can process the data stored on it instead of spending time on moving the data over the network.
On the contrary, in the relational database computing system, we can query data in real time, but it is not efficient to store data in tables, records, and columns when the data is huge.
Hadoop also provides a scheme to build a column database with Hadoop HBase for runtime queries on rows.
25. In what all modes Hadoop can be run?
Ans:
Hadoop can be run in three modes:
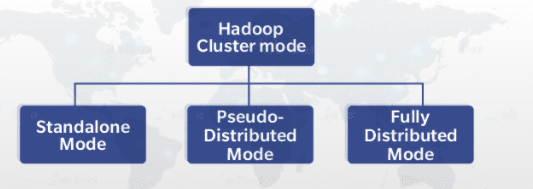
Standalone mode:The default mode of Hadoop, it uses a local file system for input and output operations. This mode is mainly used for the debugging purpose, and it does not support the use of HDFS. Further, in this mode, there is no custom configuration required for mapred-site.xml, core-site.xml, and hdfs-site.xml files. This mode works much faster when compared to other modes.
Pseudo-distributed mode (Single-node Cluster): In this case, you need configuration for all the three files mentioned above. In this case, all daemons are running on one node, and thus both Master and Slave nodes are the same.
Fully distributed mode (Multi-node Cluster): This is the production phase of Hadoop (what Hadoop is known for) where data is used and distributed across several nodes on a Hadoop cluster. Separate nodes are allotted as Master and Slave.
26. What is distributed cache?
Ans:
Distributed cache in Hadoop is a service by MapReduce framework to cache files when needed.
Once a file is cached for a specific job, Hadoop will make it available on each DataNode both in system and in memory, where map and reduce tasks are executed. Later, you can easily access and read the cache file and populate any collection (like array, hashmap) in your code.

27. What are distributed cache benefits?
Ans:
Benefits of using distributed cache are as follows:
It distributes simple, read-only text/data files and/or complex types such as jars, archives, and others. These archives are then un-archived at the slave node.
Distributed cache tracks the modification timestamps of cache files, which notify that the files should not be modified until a job is executed.
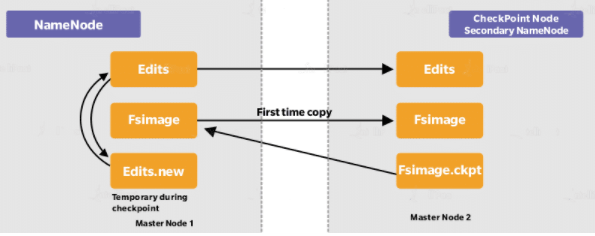
28. Explain the difference between NameNode, Checkpoint NameNode, and Backup Node.
Ans:
NameNode is the core of HDFS that manages the metadata—the information of which file maps to which block locations and which blocks are stored on which DataNode. In simple terms, it’s the data about the data being stored. NameNode supports a directory tree-like structure consisting of all the files present in HDFS on a Hadoop cluster. It uses the following files for namespace:
- 1. fsimage file: It keeps track of the latest Checkpoint of the namespace.
- 2. edits file: It is a log of changes that have been made to the namespace since Checkpoint.
Checkpoint NameNode has the same directory structure as NameNode and creates Checkpoints for namespace at regular intervals by downloading the fsimage, editing files, and margining them within the local directory. The new image after merging is then uploaded to NameNode. There is a similar node like Checkpoint, commonly known as the Secondary Node, but it does not support the ‘upload to NameNode’ functionality.
Backup Node provides similar functionality as Checkpoint, enforcing synchronization with NameNode. It maintains an up-to-date in-memory copy of the file system namespace and doesn’t require getting hold of changes after regular intervals. The Backup Node needs to save the current state in-memory to an image file to create a new Checkpoint.
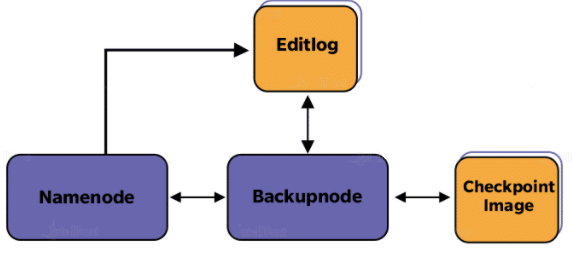
29. Define DataNode. How does NameNode tackle DataNode failures?
Ans:
DataNode stores data in HDFS; it is a node where actual data resides in the file system. Each DataNode sends a heartbeat message to notify that it is alive. If the NameNode does not receive a message from the DataNode for 10 minutes, the NameNode considers the DataNode to be dead or out of place and starts the replication of blocks that were hosted on that DataNode such that they are hosted on some other DataNode. A BlockReport contains a list of the all blocks on a DataNode. Now, the system starts to replicate what was stored in the dead DataNode.
The NameNode manages the replication of the data blocks from one DataNode to another. In this process, the replication data gets transferred directly between DataNodes such that the data never passes the NameNode.
30. What are the core methods of a Reducer?
Ans:
The three core methods of a Reducer are as follows:
setup(): This method is used for configuring various parameters such as input data size and distributed cache.
- public void setup (context)
reduce(): Heart of the Reducer is always called once per key with the associated reduced task.
- public void reduce(Key, Value, context)
cleanup(): This method is called to clean the temporary files, only once at the end of the task.
- public void cleanup (context)
31. Why do we need Hadoop?
Ans:
The picture of Hadoop came into existence to deal with Big Data challenges. The challenges with Big Data are-
Storage – Since data is very large, storing such a huge amount of data is very difficult.
Security – Since the data is huge in size, keeping it secure is another challenge.
Analytics – In Big Data, most of the time we are unaware of the kind of data we are dealing with. So analyzing that data is even more difficult.
Data Quality – In the case of Big Data, data is very messy, inconsistent and incomplete.
Discovery – Using a powerful algorithm to find patterns and insights are very difficult.
Hadoop is an open-source software framework that supports the storage and processing of large data sets. Apache Hadoop is the best solution for storing and processing Big data because:
Apache Hadoop stores huge files as they are (raw) without specifying any schema.
High scalability – We can add any number of nodes, hence enhancing performance dramatically.
Reliable – It stores data reliably on the cluster despite machine failure.
High availability – In Hadoop data is highly available despite hardware failure. If a machine or hardware crashes, then we can access data from another path.
Economic – Hadoop runs on a cluster of commodity hardware which is not very expensive
32. What are the Features of Hadoop?
Ans:
The various Features of Hadoop are:
Open Source – Apache Hadoop is an open source software framework. Open source means it is freely available and even we can change its source code as per our requirements.
Distributed processing – As HDFS stores data in a distributed manner across the cluster. MapReduce processes the data in parallel on the cluster of nodes.
Fault Tolerance – Apache Hadoop is highly Fault-Tolerant. By default, each block creates 3 replicas across the cluster and we can change it as per needment. So if any node goes down, we can recover data on that node from the other node. Framework recovers failures of nodes or tasks automatically.
Reliability – It stores data reliably on the cluster despite machine failure.
High Availability – Data is highly available and accessible despite hardware failure. In Hadoop, when a machine or hardware crashes, then we can access data from another path.
Scalability – Hadoop is highly scalable, as one can add the new hardware to the nodes.
Economic- Hadoop runs on a cluster of commodity hardware which is not very expensive. We do not need any specialized machine for it.
Easy to use – No need for clients to deal with distributed computing, the framework takes care of all the things. So it is easy to use.
33. Compare Hadoop and RDBMS?
Ans:
Apache Hadoop is the future of the database because it stores and processes a large amount of data. Which will not be possible with the traditional database. There is some difference between Hadoop and RDBMS which are as follows:
| Features | RDBMS | Hadoop |
|---|---|---|
| Architecture | Traditional RDBMS have ACID properties | Hadoop is a distributed computing framework having two main components namely, Distributed file system (HDFS) and MapReduce |
| Data acceptance | RDBMS accepts only structured data | Hadoop can accept both structured as well as unstructured data. It is a great feature of Hadoop, as we can store everything in our database and there will be no data loss |
| Scalability | RDBMS is a traditional database which provides vertical scalability. So if the data increases for storing then we have to increase particular system configuration | Hadoop provides horizontal scalability. So we just have to add one or more nodes to the cluster if there is any requirement for an increase in data |
| OLTP (Real-time data processing) and OLAP | Traditional RDBMS support OLTP (Real-time data processing) | OLTP is not supported in Apache Hadoop. Apache Hadoop supports large scale Batch Processing workloads (OLAP) |
| Cost | Licensed software, therefore we have to pay for the software | Hadoop is an open source framework, so we don’t need to pay for software |
34. What are the features of Standalone (local) mode?
Ans:
By default, Hadoop runs in a single-node, non-distributed mode, as a single Java process. Local mode uses the local file system for input and output operation. One can also use it for debugging purposes. It does not support the use of HDFS. Standalone mode is suitable only for running programs during development for testing. Further, in this mode, there is no custom configuration required for configuration files. Configuration files are:
- core-site.xml
- hdfs-site.xml files.
- mapred-site.xml
- yarn-default.xml
35. What are the features of Pseudo mode?
Ans:
Just like the Standalone mode, Hadoop can also run on a single-node in this mode. The difference is that each Hadoop daemon runs in a separate Java process in this Mode. In Pseudo-distributed mode, we need configuration for all the four files mentioned above. In this case, all daemons are running on one node and thus, both Master and Slave nodes are the same.
The pseudo mode is suitable for both for development and in the testing environment. In the Pseudo mode, all the daemons run on the same machine.

Build Your Big data Hadoop Skills with Hadoop Training By Real Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
36. What are the features of Fully-Distributed mode?
Ans:
In this mode, all daemons execute in separate nodes forming a multi-node cluster. Thus, we allow separate nodes for Master and Slave.
We use this mode in the production environment, where ‘n’ number of machines form a cluster. Hadoop daemons run on a cluster of machines. There is one host onto which NameNode is running and the other hosts on which DataNodes are running. Therefore, NodeManager installs on every DataNode. And it is also responsible for the execution of the task on every single DataNode.
The ResourceManager manages all these NodeManager. ResourceManager receives the processing requests. After that, it passes the parts of the request to the corresponding NodeManager accordingly.
37. What are the limitations of Hadoop?
Ans:
Various limitations of Hadoop are:
Issue with small files – Hadoop is not suited for small files. Small files are the major problems in HDFS. A small file is significantly smaller than the HDFS block size (default 128MB). If you are storing these large numbers of small files, HDFS can’t handle these lots of files. HDFS works with a small number of large files for storing data sets rather than larger numbers of small files. If one uses a huge number of small files, then this will overload the namenode. Since namenode stores the namespace of HDFS.
HAR files, Sequence files, and Hbase overcome small files issues.
Processing Speed – With parallel and distributed algorithms, MapReduce processes large data sets. MapReduce performs the task: Map and Reduce. MapReduce requires a lot of time to perform these tasks thereby increasing latency. As data is distributed and processed over the cluster in MapReduce. So, it will increase the time and reduce processing speed.
Support only Batch Processing – Hadoop supports only batch processing. It does not process streamed data and hence, overall performance is slower. MapReduce framework does not leverage the memory of the cluster to the maximum.
Iterative Processing – Hadoop is not efficient for iterative processing. As hadoop does not support cyclic data flow. That is the chain of stages in which the input to the next stage is the output from the previous stage.
Vulnerable by nature – Hadoop is entirely written in Java, a language most widely used. Hence java has been most heavily exploited by cyber-criminal. Therefore it implicates in numerous security breaches.
Security- Hadoop can be challenging in managing the complex application. Hadoop is missing encryption at storage and network levels, which is a major point of concern. Hadoop supports Kerberos authentication, which is hard to manage.
38. Compare Hadoop 2 and Hadoop 3?
Ans:
| Hadoop 2 | Hadoop 3 |
|---|---|
| In Hadoop 2, the minimum supported version of Java is Java 7 | In Hadoop 3, it is Java 8 |
| Hadoop 2, handles fault tolerance by replication (which is wastage of space) | Hadoop 3 handles it by Erasure coding |
| For data balancing Hadoop 2 uses HDFS balancer | For data balancing Hadoop 3 uses Intra-data node balancer |
| In Hadoop 2 some default ports are Linux ephemeral port range. So at the time of startup, they will fail to bind | In Hadoop 3 these ports have been moved out of the ephemeral range |
| In hadoop 2, HDFS has 200% overhead in storage space | Hadoop 3 has 50% overhead in storage space |
| Hadoop 2 has features to overcome SPOF (single point of failure). So whenever NameNode fails, it recovers automatically | Hadoop 3 recovers SPOF automatically with no need of manual intervention to overcome it |
39. Explain Data Locality in Hadoop?
Ans:
Hadoop major drawback was cross-switch network traffic due to the huge volume of data. To overcome this drawback, Data locality came into the picture. It refers to the ability to move the computation close to where the actual data resides on the node, instead of moving large data to computation. Data locality increases the overall throughput of the system.
In Hadoop, HDFS stores datasets. Datasets are divided into blocks and stored across the datanodes in the Hadoop cluster. When a user runs the MapReduce job then NameNode sends this MapReduce code to the datanodes on which data is available related to MapReduce job.
Data locality has three categories:
- 1. Data local – In this category data is on the same node as the mapper working on the data. In such cases, the proximity of the data is closer to the computation. This is the most preferred scenario.
- 2. Intra – Rack- In this scenario mapper runs on the different nodes but on the same rack. As it is not always possible to execute the mapper on the same datanode due to constraints.
- 3. Inter-Rack – In these scenarios mapper runs on the different rack. As it is not possible to execute mapper on a different node in the same rack due to resource constraints.
40. What is Safe Mode in Hadoop?
Ans:
Safemode in Apache Hadoop is a maintenance state of NameNode. During which NameNode doesn’t allow any modifications to the file system. During Safe Mode, the HDFS cluster is read-only and doesn’t replicate or delete blocks. At the startup of NameNode:
- It loads the file system namespace from the last saved FsImage into its main memory and the edited log file.
- Merges edits log files on FsImage and results in a new file system namespace.
- Then it receives block reports containing information about block location from all datanodes.
SafeMode NameNode performs a collection of block reports from datanodes. NameNode enters safe mode automatically during its start up. NameNode leaves Safemode after the DataNodes have reported that most blocks are available. Use the command:
- hadoop dfsadmin –safemode get: To know the status of Safemode
- bin/hadoop dfsadmin –safemode enter: To enter Safe Mode
- hadoop dfsadmin -safemode leave: To come out of Safemode
NameNode front page shows whether safe mode is on or off.
41. What is the problem with small files in Hadoop?
Ans:
Hadoop is not suited for small data. Hadoop HDFS lacks the ability to support the random reading of small files. Small file in HDFS is smaller than the HDFS block size (default 128 MB). If we are storing these huge numbers of small files, HDFS can’t handle these lots of files. HDFS works with a small number of large files for storing large datasets. It is not suitable for a large number of small files. A large number of many small files overload NameNode since it stores the namespace of HDFS.
Solution:
HAR (Hadoop Archive) Files deal with small file issues. HAR has introduced a layer on top of HDFS, which provides an interface for file accessing. Using the Hadoop archive command we can create HAR files. This file runs a MapReduce job to pack the archived files into a smaller number of HDFS files. Reading through files in as HAR is not more efficient than reading through files in HDFS. Since each HAR file access requires two index files read as well the data file to read, this makes it slower.
Sequence Files also deal with small file problems. In this, we use the filename as key and the file contents as the value. If we have 10,000 files of 100 KB, we can write a program to put them into a single sequence file. And then we can process them in a streaming fashion.
42. What is a “Distributed Cache” in Apache Hadoop?
Ans:
In Hadoop, data chunks process independently in parallel among DataNodes, using a program written by the user. If we want to access some files from all the DataNodes, then we will put that file to a distributed cache.
MapReduce framework provides Distributed Cache to caches files needed by the applications. It can cache read-only text files, archives, jar files etc.
Once we have cached a file for our job. Then, Hadoop will make it available on each data node where map/reduce tasks are running. Then, we can access files from all the datanodes in our map and reduce job.
An application which needs to use distributed cache should make sure that the files are available on URLs. URLs can be either hdfs:// or http://. Now, if the file is present on the mentioned URLs. The user mentions it to be cache file to distributed cache. This framework will copy the cache file on all the nodes before starting tasks on those nodes. By default the size of the distributed cache is 10 GB. We can adjust the size of the distributed cache using local.cache.size.
43. How is security achieved in Hadoop?
Ans:
Apache Hadoop achieves security by using Kerberos.
At a high level, there are three steps that a client must take to access a service when using Kerberos. Thus, each of which involves a message exchange with a server.
Authentication – The client authenticates itself to the authentication server. Then, receives a timestamped Ticket-Granting Ticket (TGT).
Authorization – The client uses the TGT to request a service ticket from the Ticket Granting Server.
Service Request – The client uses the service ticket to authenticate itself to the server.
44. Why does one remove or add nodes in a Hadoop cluster frequently?
Ans:
The most important features of the Hadoop is its utilization of Commodity hardware. However, this leads to frequent Datanode crashes in a Hadoop cluster.
Another striking feature of Hadoop is the ease of scale by the rapid growth in data volume.
Hence, due to above reasons, administrators Add/Remove DataNodes in a Hadoop Cluster.
45. What is throughput in Hadoop?
Ans:
The amount of work done in a unit time is Throughput. Because of bellow reasons HDFS provides good throughput:
The HDFS is Write Once and Read Many Models. It simplifies the data coherency issues as the data written once, one can not modify it. Thus, provides high throughput data access.
Hadoop works on the Data Locality principle. This principle states that moves computation to data instead of data to computation. This reduces network congestion and therefore, enhances the overall system throughput.
46. How to restart NameNode or all the daemons in Hadoop?
Ans:
By following methods we can restart the NameNode:
1. You can stop the NameNode individually using /sbin/hadoop-daemon.sh stop namenode command. Then start the NameNode using /sbin/hadoop-daemon.sh start namenode.
2. Use
- /sbin/stop-all.sh
and then use
- /sbin/start-all.sh
these commands which will stop all the demons first. Then start all the daemons.
The sbin directory inside the Hadoop directory stores these script files.
47. What does jps command do in Hadoop?
Ans:
The jbs command helps us to check if the Hadoop daemons are running or not. Thus, it shows all the Hadoop daemons that are running on the machine. Daemons are Namenode, Datanode, ResourceManager, NodeManager etc.
48. What are the main hdfs-site.xml properties?
Ans:
hdfs-site.xml – This file contains the configuration setting for HDFS daemons. hdfs-site.xml also specifies default block replication and permission checking on HDFS.
The three main hdfs-site.xml properties are:
- 1. dfs.name.dir gives you the location where NameNode stores the metadata (FsImage and edit logs). And also specify where DFS should locate – on the disk or in the remote directory.
- 2. dfs.data.dir gives the location of DataNodes where it stores the data.
- 3. fs.checkpoint.dir is the directory on the file system. On which secondary NameNode stores the temporary images of edit logs. Then this EditLogs and FsImage will merge for backup.
49. What is fsck?
Ans:
fsck is the File System Check. Hadoop HDFS uses the fsck (filesystem check) command to check for various inconsistencies. It also reports the problems with the files in HDFS. For example, missing blocks for a file or under-replicated blocks. It is different from the traditional fsck utility for the native file system. Therefore it does not correct the errors it detects.
Normally NameNode automatically corrects most of the recoverable failures. Filesystem check also ignores open files. But it provides an option to select all files during reporting. The HDFS fsck command is not a Hadoop shell command. It can also run as bin/hdfs fsck. Filesystem check can run on the whole file system or on a subset of files.
Usage:
- 1. hdfs fsck <path>
- 2. [-list-corruptfileblocks |
- 3. [-move | -delete | -openforwrite]
- 4. [-files [-blocks [-locations | -racks]]]
- 5. [-includeSnapshots]
- 6. Path- Start checking from this path
- 7. -delete- Delete corrupted files.
- 8. -files- Print out the checked files.
- 9. -files –blocks- Print out the block report.
- 10. -files –blocks –locations- Print out locations for every block.
- 11. -files –blocks –rack- Print out network topology for data-node locations
- 12. -includeSnapshots- Include snapshot data if the given path indicates or include snapshottable directory.
- 13. -list -corruptfileblocks- Print the list of missing files and blocks they belong to.
50. How to debug Hadoop code?
Ans:
First, check the list of MapReduce jobs currently running. Then, check whether orphaned jobs are running or not; if yes, you need to determine the location of RM logs.
- First of all, Run: and then, look for the log directory in the displayed result. Find out the job-id from the displayed list. Then check whether the error message is associated with that job or not.
- ps –ef| grep –I ResourceManager
- Now, on the basis of RM logs, identify the worker node which involves in the execution of the task.
- Now, login to that node and run-
- ps –ef| grep –I NodeManager
- Examine the NodeManager log.
- The majority of errors come from user level logs for each map-reduce job.
51. Explain Hadoop streaming?
Ans:
Hadoop distribution provides generic application programming interface (API). This allows writing Map and Reduce jobs in any desired programming language. The utility allows creating/running jobs with any executable as Mapper/Reducer.
For example:
- 1. hadoop jar hadoop-streaming-3.0.jar \
- 2. -input myInputDirs \
- 3. -output myOutputDir \
- 4. -mapper /bin/cat \
- 5. -reducer /usr/bin/wc
In the example, both the Mapper and reducer are executables. That reads the input from stdin (line by line) and emits the output to stdout. The utility allows creating/submitting Map/Reduce jobs to an appropriate cluster. It also monitors the progress of the job until it completes. Hadoop Streaming uses both streaming command options as well as generic command options. Be sure to place the generic options before the streaming. Otherwise, the command will fail.
The general line syntax shown below:
- Hadoop command [genericOptions] [streamingOptions]
52. What does hadoop-metrics.properties file do?
Ans:
Statistical information exposed by the Hadoop daemons is Metrics. Hadoop framework uses it for monitoring, performance tuning and debugging.
By default, there are many metrics available. Thus, they are very useful for troubleshooting.
Hadoop framework uses hadoop-metrics.properties for ‘Performance Reporting’ purpose. It also controls the reporting for Hadoop. The API provides an abstraction so we can implement on top of a variety of metrics client libraries. The choice of client library is a configuration option. And different modules within the same application can use different metrics implementation libraries.
This file is present inside /etc/hadoop.
53. How Hadoop’s CLASSPATH plays a vital role in starting or stopping in Hadoop daemons?
Ans:
CLASSPATH includes all directories containing jar files required to start/stop Hadoop daemons.
For example- HADOOP_HOME/share/hadoop/common/lib contains all the utility jar files. We cannot start/ stop Hadoop daemons if we don’t set CLASSPATH.
We can set CLASSPATH inside /etc/hadoop/hadoop-env.sh file. The next time you run hadoop, the CLASSPATH will automatically add. That is, you don’t need to add CLASSPATH in the parameters each time you run it.
54. What are the different commands used to startup and shutdown Hadoop daemons?
Ans:
To start all the hadoop daemons use:
- ./sbin/start-all.sh
Then, to stop all the Hadoop daemons use:
- ./sbin/stop-all.sh
You can also start all the dfs daemons together using
- ./sbin/start-dfs.sh
Yarn daemons together using
- ./sbin/start-yarn.sh
MR Job history server using the following command to start the history srver.
- /sbin/mr-jobhistory-daemon.sh
Then, to stop these daemons we can use
- ./sbin/stop-dfs.sh
- ./sbin/stop-yarn.sh
- /sbin/mr-jobhistory-daemon.sh stop historyserver
Finally, the last way is to start all the daemons individually. Then, stop them individually:
- ./sbin/hadoop-daemon.sh start namenode
- ./sbin/hadoop-daemon.sh start datanode
- ./sbin/yarn-daemon.sh start resourcemanager
- ./sbin/yarn-daemon.sh start nodemanager
- ./sbin/mr-jobhistory-daemon.sh start historyserver
55. What is configured in /etc/hosts and what is its role in setting a Hadoop cluster?
Ans:
./etc/hosts file contains the hostname and their IP address of that host. It also maps the IP address to the hostname. In hadoop cluster, we store all the hostnames (master and slaves) with their IP address in ./etc/hosts. So, we can use hostnames easily instead of IP addresses.

56. How is the splitting of files invoked in the Hadoop framework?
Ans:
Input file store data for Hadoop MapReduce task’s, and these files typically reside in HDFS. InputFormat defines how these input files split and read. It is also responsible for creating InputSplit, which is the logical representation of data. InputFormat also splits into records. Then, mapper will process each record (which is a key-value pair). Hadoop framework invokes Splitting of the file by running getInputSplit() method. This method belongs to the InputFormat class (like FileInputFormat) defined by the user.
57. Is it possible to provide multiple input to Hadoop? If yes then how?
Ans:
Yes, it is possible by using MultipleInputs class.
For example:
If we had weather data from the UK Met Office. And we want to combine with the NCDC data for our maximum temperature analysis. Then, we can set up the input as follows:
- MultipleInputs.addInputPath(job,ncdcInputPath,TextInputFormat.class,MaxTemperatureMapper.class);
- MultipleInputs.addInputPath(job,metofficeInputPath,TextInputFormat.class, MetofficeMaxTemperatureMapper.class);
The above code replaces the usual calls to FileInputFormat.addInputPath() and job.setmapperClass(). Both the Met Office and NCDC data are text based. So, we use TextInputFormat for each. And, we will use two different mappers, as the two data sources have different line format. The MaxTemperatureMapperr reads NCDC input data and extracts the year and temperature fields. The MetofficeMaxTemperatureMappers reads Met Office input data. Then, extracts the year and temperature fields.
58. Is it possible to have hadoop job output in multiple directories? If yes, how?
Ans:
Yes, it is possible by using following approaches:
a. Using MultipleOutputs class-
This class simplifies writing output data to multiple outputs.
- MultipleOutputs.addNamedOutput(job,”OutputFileName”,OutputFormatClass,keyClass,valueClass);
The API provides two overloaded write methods to achieve this
- MultipleOutput.write(‘OutputFileName”, new Text (key), new Text(value));
Then, we need to use overloaded write method, with an extra parameter for the base output path. This will allow to write the output file to separate output directories.
- MultipleOutput.write(‘OutputFileName”, new Text (key), new Text(value), baseOutputPath);
Then, we need to change your baseOutputpath in each of our implementation.
b. Rename/Move the file in driver class-
This is the easiest hack to write output to multiple directories. So, we can use MultipleOutputs and write all the output files to a single directory. But the file names need to be different for each category.
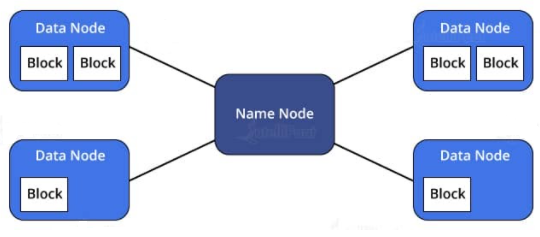
59. What is HDFS- Hadoop Distributed File System?
Ans:
Hadoop distributed file system (HDFS) is the primary storage system of Hadoop. HDFS stores very large files running on a cluster of commodity hardware. It works on the principle of storage of less number of large files rather than the huge number of small files. HDFS stores data reliably even in the case of hardware failure. It provides high throughput access to the application by accessing in parallel.
Components of HDFS:
- NameNode – It is also known as Master node. Namenode stores meta-data i.e. number of blocks, their replicas and other details.
- DataNode – It is also known as Slave. In Hadoop HDFS, DataNode is responsible for storing actual data. DataNode performs read and write operation as per request for the clients in HDFS.
60. Explain NameNode and DataNode in HDFS?
Ans:
NameNode – It is also known as Master node. Namenode stores meta-data i.e. number of blocks, their location, replicas and other details. This meta-data is available in memory in the master for faster retrieval of data. NameNode maintains and manages the slave nodes, and assigns tasks to them. It should be deployed on reliable hardware as it is the centerpiece of HDFS.
Task of NameNode
- 1. Manage file system namespace.
- 2. Regulates client’s access to files.
- 3. In HDFS, NameNode also executes file system execution such as naming, closing, opening files and directories.
61. Explain DataNode in HDFS
Ans:
DataNode – It is also known as Slave. In Hadoop HDFS, DataNode is responsible for storing actual data in HDFS. DataNode performs read and write operation as per request for the clients. One can deploy the DataNode on commodity hardware.
Task of DataNode
- 1. In HDFS, DataNode performs various operations like block replica creation, deletion, and replication according to the instruction of NameNode.
- 2. DataNode manages data storage of the system.
62. Why is block size set to 128 MB in Hadoop HDFS?
Ans:
Block is a continuous location on the hard drive which stores the data. In general, FileSystem stores data as a collection of blocks. HDFS stores each file as blocks, and distributes it across the Hadoop cluster. In HDFS, the default size of the data block is 128 MB, which we can configure as per our requirement. Block size is set to 128 MB:
To reduce the disk seeks (IO). Larger the block size, lesser the file blocks and less number of disk seek and transfer of the block can be done within respectable limits and that too parallelly.
HDFS have huge data sets, i.e. terabytes and petabytes of data. If we take 4 KB block size for HDFS, just like Linux file system, which has 4 KB block size, then we would be having too many blocks and therefore too much metadata. Managing this huge number of blocks and metadata will create huge overhead and traffic which is something which we don’t want. So, the block size is set to 128 MB.
On the other hand, block size can’t be so large that the system is waiting a very long time for the last unit of data processing to finish its work.
63. How data or file is written into HDFS?
Ans:
When a client wants to write a file to HDFS, it communicates to the namenode for metadata. The Namenode responds with details of a number of blocks, replication factors. Then, on the basis of information from NameNode, clients split files into multiple blocks. After that client starts sending them to the first DataNode. The client sends block A to Datanode 1 with other two Data Nodes details.
When Datanode 1 receives block A sent from the client, Datanode 1 copy same block to Datanode 2 of the same rack. As both the Datanodes are in the same rack so block transfer via rack switch. Now Datanode 2 copies the same block to Datanode 3. As both the Datanodes are in different racks so block transfer via an out-of-rack switch.
After the Datanode receives the blocks from the client. Then Datanode sends write confirmation to Namenode. Now Datanode sends write confirmation to the client. The Same process will repeat for each block of the file. Data transfer happens in parallel for faster write of blocks.
64. Can multiple clients write into an HDFS file concurrently?
Ans:
Multiple clients cannot write into an HDFS file at same time. Apache Hadoop HDFS follows single writer multiple reader models. The client which opens a file for writing, the NameNode grants a lease. Now suppose, some other client wants to write into that file. It asks NameNode for the write operation. NameNode first checks whether it has granted the lease for writing into that file to someone else or not. When someone already acquires the lease, then, it will reject the write request of the other client.
65. How data or file is read in HDFS?
Ans:
To read from HDFS, the first client communicates to the namenode for metadata. A client comes out of the namenode with the name of files and its location. The Namenode responds with details of the number of blocks, replication factor. Now the client communicates with Datanode where the blocks are present. Clients start reading data parallel from the Datanode. It read on the basis of information received from the namenodes.
Once a client or application receives all the blocks of the file, it will combine these blocks to form a file. For read performance improvement, the location of each block ordered by their distance from the client. HDFS selects the replica which is closest to the client. This reduces the read latency and bandwidth consumption. It first read the block in the same node. Then another node in the same rack, and then finally another Datanode in another rack.
66. Why does HDFS store data using commodity hardware despite the higher chance of failures?
Ans:
HDFS stores data using commodity hardware because HDFS is highly fault-tolerant. HDFS provides fault tolerance by replicating the data blocks. And then distribute it among different DataNodes across the cluster. By default, replication factor is 3 which is configurable. Replication of data solves the problem of data loss in unfavorable conditions. And unfavorable conditions are crashing the node, hardware failure and so on. So, when any machine in the cluster goes down, then the client can easily access their data from another machine. And this machine contains the same copy of data blocks.
67. How is indexing done in HDFS?
Ans:
Hadoop has a unique way of indexing. Once Hadoop framework stores the data as per the block size. HDFS will keep on storing the last part of the data which will say where the next part of the data will be. In fact, this is the base of HDFS.
68. What is a Heartbeat in HDFS?
Ans:
Heartbeat is the signal that NameNode receives from the DataNodes to show that it is functioning (alive). NameNode and DataNode do communicate using Heartbeat. If after a certain time of heartbeat NameNode does not receive any response from DataNode, then that Node is dead. The NameNode then schedules the creation of new replicas of those blocks on other DataNodes.
Heartbeats from a Datanode also carry information about total storage capacity. Also, carry the fraction of storage in use, and the number of data transfers currently in progress.
The default heartbeat interval is 3 seconds. One can change it by using dfs.heartbeat.interval in hdfs-site.xml.
69. How to copy a file into HDFS with a different block size to that of existing block size configuration?
Ans:
One can copy a file into HDFS with a different block size by using:
–Ddfs.blocksize=block_size, where block_size is in bytes.
So, let us explain it with an example:
Suppose, you want to copy a file called test.txt of size, say of 128 MB, into the hdfs. And for this file, you want the block size to be 32MB (33554432 Bytes) in place of the default (128 MB). So, you would issue the following command:
- Hadoop fs –Ddfs.blocksize=33554432
- –copyFromlocal/home/dataflair/test.txt/sample_hdfs
Now, you can check the HDFS block size associated with this file by:
hadoop fs –stat %o/sample_hdfs/test.txt
Else, you can also use the NameNode web UI for seeing the HDFS directory.
70. Why does HDFS perform replication, although it results in data redundancy?
Ans:
In HDFS, Replication provides the fault tolerance. Data replication is one of the most important and unique features of HDFS. Replication of data solves the problem of data loss in unfavorable conditions. Unfavorable conditions are crashing the node, hardware failure and so on. HDFS by default creates 3 replicas of each block across the cluster in Hadoop. And we can change it as per the need. So, if any node goes down, we can recover data on that node from the other node.
In HDFS, Replication will lead to the consumption of a lot of space. But the user can always add more nodes to the cluster if required. It is very rare to have free space issues in the practical cluster. The very first reason to deploy HDFS was to store huge data sets. Also, one can change the replication factor to save HDFS space. Or one can also use different codec provided by the Hadoop to compress the data.
71. What is the default replication factor and how will you change it?
Ans:
The default replication factor is 3. One can change this in following three ways:
- By adding this property to hdfs-site.xml:
- <property>
- <name>dfs.replication</name>
- <value>5</value>
- <description>Block Replication</description>
- </property>
You can also change the replication factor on per-file basis using the command:
- hadoop fs –setrep –w 3 / file_location
You can also change replication factor for all the files in a directory by using:
- hadoop fs –setrep –w 3 –R / directoey_location
72. Explain Hadoop Archives?
Ans:
Apache Hadoop HDFS stores and processes large (terabytes) data sets. However, storing a large number of small files in HDFS is inefficient, since each file is stored in a block, and block metadata is held in memory by the namenode.
Reading through small files normally causes lots of seeks and lots of hopping from datanode to datanode to retrieve each small file, all of which is inefficient data access pattern.
Hadoop Archive (HAR) basically deals with small files issue. HAR pack a number of small files into a large file, so, one can access the original files in parallel transparently (without expanding the files) and efficiently.
Hadoop Archives are special format archives. It maps to a file system directory. Hadoop Archive always has a *.har extension. In particular, Hadoop MapReduce uses Hadoop Archives as an Input.
73. What do you mean by the High Availability of a NameNode in Hadoop HDFS?
Ans:
In Hadoop 1.0, NameNode is a single point of Failure (SPOF), if namenode fails, all clients including MapReduce jobs would be unable to read, write file or list files. In such an event, the whole Hadoop system would be out of service until a new namenode is brought online.
Hadoop 2.0 overcomes this single point of failure by providing support for multiple NameNode. High availability feature provides an extra NameNode (active standby NameNode) to Hadoop architecture which is configured for automatic failover. If Active NameNode fails, then Standby Namenode takes all the responsibility of the active node and the cluster continues to work.
The initial implementation of HDFS namenode high availability provided for single active namenode and single standby namenode. However, some deployment requires high degree fault-tolerance, this is enabled by new version 3.0, which allows the user to run multiple standby namenode. For instance, by configuring three namenode and five journal nodes, the cluster is able to tolerate the failure of two nodes rather than one.
74. What is Fault Tolerance in HDFS?
Ans:
Fault-tolerance in HDFS is the working strength of a system in unfavorable conditions ( like the crashing of the node, hardware failure and so on). HDFS control faults by the process of replica creation. When a client stores a file in HDFS, then the file is divided into blocks and blocks of data are distributed across different machines present in the HDFS cluster. And, It creates a replica of each block on other machines present in the cluster. HDFS, by default, creates 3 copies of a block on other machines present in the cluster. If any machine in the cluster goes down or fails due to unfavorable conditions, then also, the user can easily access that data from other machines in the cluster in which the replica of the block is present.
75. What is Rack Awareness?
Ans:
Rack Awareness improves the network traffic while reading/writing file. In which NameNode chooses the DataNode which is closer to the same rack or nearby rack. NameNode achieves rack information by maintaining the rack IDs of each DataNode. This concept chooses Data Nodes based on the rack information. In HDFS, NameNode makes sure that all the replicas are not stored on the same rack or single rack. It follows the Rack Awareness Algorithm to reduce latency as well as fault tolerance.
Default replication factor is 3, according to the Rack Awareness Algorithm. Therefore, the first replica of the block will store on a local rack. The next replica will store on another datanode within the same rack. And the third replica is stored on a different rack.
In Hadoop, we need Rack Awareness because it improves:
- Data high availability and reliability.
- The performance of the cluster.
- Network bandwidth.
76. Explain the Single point of Failure in Hadoop?
Ans:
In Hadoop 1.0, NameNode is a single point of Failure (SPOF). If the namenode fails, all clients would be unable to read/write files. In such an event, the whole Hadoop system would be out of service until the new namenode is up.
Hadoop 2.0 overcomes this SPOF by providing support for multiple NameNode. High availability feature provides an extra NameNode to Hadoop architecture. This feature provides automatic failover. If the active NameNode fails, then Standby-Namenode takes all the responsibility of the active node. And the cluster continues to work.
The initial implementation of Namenode high availability provided for single active/standby namenode. However, some deployment requires high degree fault-tolerance. So new version 3.0 enables this feature by allowing the user to run multiple standby namenode. For instance configuring three namenode and five journal nodes. So, the cluster is able to tolerate the failure of two nodes rather than one.
77. Explain Erasure Coding in Hadoop?
Ans:
In Hadoop, by default HDFS replicates each block three times for several purposes. Replication in HDFS is a very simple and robust form of redundancy to shield against the failure of a datanode. But replication is very expensive. Thus, 3.x replication scheme has 200% overhead in storage space and other resources.
Thus, Hadoop 2.x introduced Erasure Coding, a new feature to use in the place of Replication. It also provides the same level of fault tolerance with less space store and 50% storage overhead.
Erasure Coding uses Redundant Array of Inexpensive Disk (RAID). RAID implements EC through striping. In which it divides logical sequential data (such as a file) into the smaller unit (such as bit, byte or block). Then, stores data on different disk.
Encoding- In this process, RAID calculates and sort Parity cells for each strip of data cells. And recover error through the parity. Erasure coding extends a message with redundant data for fault tolerance. EC codec operates on uniformly sized data cells. In Erasure Coding, codec takes a number of data cells as input and produces parity cells as the output. Data cells and parity cells together are called an erasure coding group.
There are two algorithms available for Erasure Coding:
- 1. XOR Algorithm
- 2. Reed-Solomon Algorithm
78. What is Disk Balancer in Hadoop
Ans:
HDFS provides a command line tool called Diskbalancer. It distributes data evenly on all disks of a datanode. This tool operates against a given datanode and moves blocks from one disk to another.
Disk balancer works by creating a plan (set of statements) and executing that plan on the datanode. Thus, the plan describes how much data should move between two disks. A plan composes multiple steps. Move step has source disk, destination disk and the number of bytes to move. And the plan will execute against an operational datanode.
By default, disk balancer is not enabled; Hence, to enable disk balancer dfs.disk.balancer.enabled must be set true in hdfs-site.xml.
When we write a new block in hdfs, then, the datanode uses volume choosing the policy to choose the disk for the block. Each directory is the volume in hdfs terminology. Thus, two such policies are:
- 1. Round-robin: It distributes the new blocks evenly across the available disks.
- 2. Available space: It writes data to the disk that has maximum free space (by percentage).
79. How would you check whether your NameNode is working or not?
Ans:
There are several ways to check the status of the NameNode. Mostly, one uses the jps command to check the status of all daemons running in the HDFS.
80. Is the Namenode machine the same as a DataNode machine as in terms of hardware?
Ans:
Unlike the DataNodes, a NameNode is a highly available server. That manages the File System Namespace and maintains the metadata information. Metadata information is a number of blocks, their location, replicas and other details. It also executes file system execution such as naming, closing, opening files/directories.
Therefore, NameNode requires higher RAM for storing the metadata for millions of files. Whereas, DataNode is responsible for storing actual data in HDFS. It performs read and write operations as per request of the clients. Therefore, Datanode needs to have a higher disk capacity for storing huge data sets.
81. What are file permissions in HDFS and how HDFS check permissions for files or directory?
Ans:
For files and directories, Hadoop distributed file system (HDFS) implements a permissions model. For each file or directory, thus, we can manage permissions for a set of 3 distinct user classes:
The owner, group, and others.
The 3 different permissions for each user class: Read (r), write (w), and execute(x).
- For files, the r permission is to read the file, and the w permission is to write to the file.
- For directories, the r permission is to list the contents of the directory. The w permission is to create or delete the directory.
- X permission is to access a child of the directory.
HDFS check permissions for files or directory:
- 1. We can also check the owner’s permissions if the username matches the owner of the directory.
- 2. If the group matches the directory’s group, then Hadoop tests the user’s group permissions.
- 3. Hadoop tests the “other” permission when the owner and the group names don’t match.
- 4. If none of the permissions checks succeed, the client’s request is denied.
82. If DataNode increases, then do we need to upgrade NameNode?
Ans:
Namenode stores meta-data i.e. number of blocks, their location, replicas. This meta-data is available in memory in the master for faster retrieval of data. NameNode maintains and manages the slave nodes, and assigns tasks to them. It regulates client’s access to files.
It also executes file system execution such as naming, closing, opening files/directories.
During Hadoop installation, framework determines NameNode based on the size of the cluster. Mostly we don’t need to upgrade the NameNode because it does not store the actual data. But it stores the metadata, so such requirements rarely arise.
83. What is Hadoop MapReduce?
Ans:
MapReduce is the data processing layer of Hadoop. It is the framework for writing applications that process the vast amount of data stored in the HDFS. It processes a huge amount of data in parallel by dividing the job into a set of independent tasks (sub-job). In Hadoop, MapReduce works by breaking the processing into phases: Map and Reduce.
Map- It is the first phase of processing. In which we specify all the complex logic/business rules/costly code. The map takes a set of data and converts it into another set of data. It also breaks individual elements into tuples (key-value pairs).
Reduce- It is the second phase of processing. In which we specify light-weight processing like aggregation/summation. Reduce takes the output from the map as input. After that, it combines tuples (key-value) based on the key. And then, modifies the value of the key accordingly.
84. Why Hadoop MapReduce?
Ans:
When we store a huge amount of data in HDFS, the first question arises is, how to process this data?
Transferring all this data to a central node for processing is not going to work. And we will have to wait forever for the data to transfer over the network. Google faced this same problem with its Distributed Goggle File System (GFS). It solved this problem using a MapReduce data processing model.
Challenges before MapReduce:
- 1. Costly – All the data (terabytes) in one server or as a database cluster which is very expensive. And also hard to manage.
- 2. Time-consuming – By using a single machine we cannot analyze the data (terabytes) as it will take a lot of time.
MapReduce overcome these challenges:
- 1. Cost-efficient – It distributes the data over multiple low config machines.
- 2. Time-efficient – If we want to analyze the data. We can write the analysis code in the Map function. And the integration code in the Reduce function and execute it. Thus, this MapReduce code will go to every machine which has a part of our data and executes on that specific part. Hence instead of moving terabytes of data, we just move kilobytes of code. So this type of movement is time-efficient.
85. What is the key- value pair in MapReduce?
Ans:
Hadoop MapReduce implements a data model, which represents data as key-value pairs. Both input and output to MapReduce Framework should be in Key-value pairs only.
In Hadoop, if the schema is static we can directly work on the column instead of key-value. But, the schema is not static. We will work on keys and values. Keys and values are not the intrinsic properties of the data. But the user analyzing the data chooses a key-value pair. A Key-value pair in Hadoop MapReduce generate in following way:
- InputSplit- It is the logical representation of data. InputSplit represents the data which an individual Mapper will process.
- RecordReader- It communicates with the InputSplit (created by InputFormat). And converts the split into records. Records are in form of Key-value pairs that are suitable for reading by the mapper. By Default RecordReader uses TextInputFormat for converting data into a key-value pair.
Key- It is the byte offset of the beginning of the line within the file, so it will be unique if combined with the file.
Value- It is the contents of the line, excluding line terminators. For Example file content is- on the top of the crumpetty Tree
Key- 0
Value- on the top of the crumpetty Tree
86. Why does MapReduce use the key-value pair to process the data?
Ans:
MapReduce works on unstructured and semi-structured data apart from structured data. One can read the Structured data like the ones stored in RDBMS by columns. But handling unstructured data is feasible using key-value pairs. And the very core idea of MapReduce works on the basis of these pairs. Framework map data into a collection of key-value pairs by mapper and reducer on all the pairs with the same key. So as stated by Google themselves in their research publication. In most of the computations-
Map operation applies on each logical “record” in our input. This computes a set of intermediate key-value pairs. Then apply reduce operation on all the values that share the same key. This combines the derived data properly.
In conclusion, we can say that key-value pairs are the best solution to work on data problems on MapReduce.
87. How many Mappers run for a MapReduce job in Hadoop?
Ans:
Mapper task processes each input record (from RecordReader) and generates a key-value pair. The number of mappers depends on 2 factors:
The amount of data we want to process along with block size. It depends on the number of InputSplit. If we have the block size of 128 MB and we expect 10TB of input data, thus we will have 82,000 maps. Ultimately InputFormat determines the number of maps.
The configuration of the slave i.e. number of core and RAM available on the slave. The right number of maps/nodes can be between 10-100. Hadoop framework should give 1 to 1.5 cores of the processor to each mapper. Thus, for a 15 core processor, 10 mappers can run.
In a MapReduce job, by changing the block size one can control the number of Mappers. Hence, by Changing block size the number of InputSplit increases or decreases.
By using JobConf’s conf.setNumMapTasks(int num) one can increase the number of map tasks manually.
Mapper= {(total data size)/ (input split size)}
If data size= 1 Tb and input split size= 100 MB
Hence, Mapper= (1000*1000)/100= 10,000
88. How many Reducers run for a MapReduce job in Hadoop?
Ans:
Reducer takes a set of an intermediate key-value pair produced by the mapper as the input. Then runs a reduce function on each of them to generate the output. Thus, the output of the reducer is the final output, which it stores in HDFS. Usually, in the reducer, we do aggregation or summation sort of computation.
With the help of Job.setNumreduceTasks(int) the user set the number of reducers for the job. Hence the right number of reducers are set by the formula:
0.95 Or 1.75 multiplied by (<no. of nodes> * <no. of the maximum container per node>).
With 0.95, all the reducers can launch immediately and start transferring map outputs as the map finish.
With 1.75, faster node finishes the first round of reduces and then launch the second wave of reduces.
By increasing the number of reducers:
- 1. Framework overhead increases
- 2. Increases load balancing
- 3. Lowers the cost of failures
89. What is the difference between Reducer and Combiner in Hadoop MapReduce?
Ans:
The Combiner is a Mini-Reducer that performs local reduce tasks. The Combiner runs on the Map output and produces the output to reducer input. A combiner is usually used for network optimization. Reducer takes a set of an intermediate key-value pair produced by the mapper as the input. Then runs a reduce function on each of them to generate the output. An output of the reducer is the final output.
- Unlike a reducer, the combiner has a limitation. i.e. the input or output key and value types must match the output types of the mapper.
- Combiners can operate only on a subset of keys and values. i.e. combiners can execute on functions that are commutative.
- Combiner functions take input from a single mapper. While reducers can take data from multiple mappers as a result of partitioning.
90. What happens if the number of reducers is 0 in Hadoop?
Ans:
If we set the number of reducers to 0, then no reducer will execute and no aggregation will take place. In such a case, we will prefer a “Map-only job” in Hadoop. In a map-Only job, the map does all tasks with its InputSplit and the reducer does no job. Map output is the final output.
Between map and reduce phases there is key, sort, and shuffle phase. Sort and shuffle phase are responsible for sorting the keys in ascending order. Then grouping values based on the same keys. This phase is very expensive. If a reduced phase is not required we should avoid it. Avoiding the reduced phase would eliminate sort and shuffle phase as well. This also saves network congestion. As in shuffling an output of a mapper travels to the reducer, when data size is huge, large data travel to the reducer.
91. What do you mean by shuffling and sorting in MapReduce?
Ans:
Shuffling and Sorting takes place after the completion of map task. Shuffle and sort phase in hadoop occurs simultaneously.
Shuffling- It is the process of transferring data from the mapper to reducer. i.e., the process by which the system sorts the key-value output of the map tasks and transfer it to the reducer.
So, the shuffle phase is necessary for the reducer, otherwise, they would not have any input. As shuffling can start even before the map phase has finished. So this saves some time and completes the task in less time.
Sorting- Mapper generate the intermediate key-value pair. Before starting the reducer, MapReduce framework sorts these key-value pairs by the keys.
Sorting helps reducers to easily distinguish when a new reduced task should start. Thus saves time for the reducer.
Shuffling and sorting are not performed at all if you specify zero reducers (setNumReduceTasks(0)).
92. What is the fundamental difference between a MapReduce InputSplit and HDFS block?
Ans:
| Fundamentals | Block | InputSplit |
|---|---|---|
| Definition | Block is the continuous location on the hard drive where HDFS stores data. In general, File System stores data as a collection of blocks. In a similar way, HDFS stores each file as blocks, and distributes it across the Hadooper cluster | Input Split represents the data which an individual Mapper will process. Further split divides into records. Each record (which is a key-value pair) will be processed by the map |
| Data representation | It is the physical representation of data | It is the logical representation of data. Thus, during data processing in MapReduce program or other processing techniques use InputSplit. In MapReduce, an important thing is that InputSplit does not contain the input data. Hence, it is just a reference to the data |
| Size | The default size of the HDFS block is 128 MB which is configured as per our requirement. All blocks of the file are of the same size except the last block. The last Block can be of the same size or smaller. In Hadoop, the files split into 128 MB blocks and then stored into HadoopFilesystem | Split size is approximately equal to block size, by default |
Example
Consider an example, where we need to store the file in HDFS. HDFS stores files as blocks. Block is the smallest unit of data that can store or retrieve from the disk. The default size of the block is 128MB. HDFS breaks files into blocks and stores these blocks on different nodes in the cluster. We have a file of 130 MB, so HDFS will break this file into 2 blocks.
Now, if we want to perform MapReduce operation on the blocks, it will not process, as the 2nd block is incomplete. InputSplit solves this problem. InputSplit will form a logical grouping of blocks as a single block. As the InputSplit include a location for the next block. It also includes the byte offset of the data needed to complete the block.
From this, we can conclude that InputSplit is only a logical chunk of data. i.e. it has just the information about blocks address or location. Thus, during MapReduce execution, Hadoop scans through the blocks and create InputSplits. Split act as a broker between block and mapper.
93. How to submit extra files(jars, static files) for a MapReduce job during runtime?
Ans:
MapReduce framework provides Distributed Cache to caches files needed by the applications. It can cache read-only text files, archives, jar files etc.
First of all, an application which needs to use distributed cache to distribute a file should make sure that the files are available on URLs. Hence, URLs can be either hdfs:// or http://. Now, if the file is present on the hdfs:// or http://urls. Then, the user mentions it to be a cache file to distribute. This framework will copy the cache file on all the nodes before starting tasks on those nodes. The files are only copied once per job. Applications should not modify those files.
By default the size of the distributed cache is 10 GB. We can adjust the size of the distributed cache using local.cache.size.
94. What is Apache Hadoop YARN?
Ans:
YARN is a powerful and efficient feature rolled out as a part of Hadoop 2.0.YARN is a large scale distributed system for running big data applications.
95. Is YARN a replacement of Hadoop MapReduce?
Ans:
YARN is not a replacement of Hadoop but it is a more powerful and efficient technology that supports MapReduce and is also referred to as Hadoop 2.0 or MapReduce 2.
96. What are the additional benefits YARN brings into Hadoop?
Ans:
Effective utilization of the resources as multiple applications can be run in YARN all sharing a common resource.In Hadoop MapReduce there are separate slots for Map and Reduce tasks whereas in YARN there is no fixed slot. The same container can be used for Map and Reduce tasks leading to better utilization.
YARN is backward compatible so all the existing MapReduce jobs.
Using YARN, one can even run applications that are not based on the MaReduce model
97. How can native libraries be included in YARN jobs?
Ans:
There are two ways to include native libraries in YARN jobs-
By setting the -Djava.library.path on the command line but in this case there are chances that the native libraries might not be loaded correctly and there is a possibility of errors.
The better option to include native libraries is to set the LD_LIBRARY_PATH in the .bashrc file.
98. Differentiate between NFS, Hadoop NameNode and JournalNode.
Ans:
HDFS is a write once file system so a user cannot update the files once they exist either they can read or write to it. However, under certain scenarios in the enterprise environment like file uploading, file downloading, file browsing or data streaming –it is not possible to achieve all this using the standard HDFS. This is where a distributed file system protocol Network File System (NFS) is used. NFS allows access to files on remote machines just similar to how local file system is accessed by applications.
Namenode is the heart of the HDFS file system that maintains the metadata and tracks where the file data is kept across the Hadoop cluster.
StandBy Nodes and Active Nodes communicate with a group of lightweight nodes to keep their state synchronized. These are known as Journal Nodes.
99. How is the distance between two nodes defined in Hadoop?
Ans:
Measuring bandwidth is difficult in Hadoop so the network is denoted as a tree in Hadoop. The distance between two nodes in the tree plays a vital role in forming a Hadoop cluster and is defined by the network topology and java interface DNS Switch Mapping. The distance is equal to the sum of the distance to the closest common ancestor of both the nodes. The method getDistance(Node node1, Node node2) is used to calculate the distance between two nodes with the assumption that the distance from a node to its parent node is always 1.
100. How will you test data quality ?
Ans:
The entire data that has been collected could be important but all data is not equal so it is necessary to first define from where the data came , how the data would be used and consumed. Data that will be consumed by vendors or customers within the business ecosystem should be checked for quality and needs to be cleaned. This can be done by applying stringent data quality rules and by inspecting different properties like conformity, perfection, repetition, reliability, validity, completeness of data, etc.
101. On what concept the Hadoop framework works?
Ans:
Hadoop Framework works on the following two core components-
HDFS – Hadoop Distributed File System is the java based file system for scalable and reliable storage of large datasets. Data in HDFS is stored in the form of blocks and it operates on the Master Slave Architecture.
Hadoop MapReduce – This is a java based programming paradigm of Hadoop framework that provides scalability across various Hadoop clusters. MapReduce distributes the workload into various tasks that can run in parallel. Hadoop jobs perform 2 separate tasks- jobs. The map job breaks down the data sets into key-value pairs or tuples. The reduce job then takes the output of the map job and combines the data tuples into smaller sets of tuples. The reduce job is always performed after the map job is executed.