
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Apache Spark Tutorial
Last updated on 29th Sep 2020, Big Data, Blog, Tutorials
Apache Spark is an open-source cluster computing system that provides high-level API in Java, Scala, Python and R. It can access data from HDFS, Cassandra, HBase, Hive, Tachyon, and any Hadoop data source. And run in Standalone, YARN and Mesos cluster manager.
What is Spark?
Apache Spark is a general-purpose & lightning fast cluster computing system. It provides a high-level API. For example, Java, Scala, Python, and R. Apache Spark is a tool for Running Spark Applications. Spark is 100 times faster than Bigdata Hadoop and 10 times faster than accessing data from disk.
Spark is written in Scala but provides rich APIs in Scala, Java, Python, and R.
It can be integrated with Hadoop and can process existing Hadoop HDFS data. Follow this guide to learn How Spark is compatible with Hadoop?
It is saying that the images are the worth of a thousand words. To keep this in mind we have also provided a Spark video tutorial for more understanding of Apache Spark.
Why Spark?
After studying Apache Spark introduction let’s discuss, why Spark came into existence?
In the industry, there is a need for a general-purpose cluster computing tool as:
- Hadoop MapReduce can only perform batch processing.
- Apache Storm / S4 can only perform stream processing.
- Apache Impala / Apache Tez can only perform interactive processing
- Neo4j / Apache Giraph can only perform graph processing
Hence in the industry, there is a big demand for a powerful engine that can process the data in real-time (streaming) as well as in batch mode. There is a need for an engine that can respond in sub-second and perform in-memory processing.
Subscribe For Free Demo
Error: Contact form not found.
Apache Spark Definition says it is a powerful open-source engine that provides real-time stream processing, interactive processing, graph processing, in-memory processing as well as batch processing with very fast speed, ease of use and standard interface. This creates the difference between Hadoop vs Spark and also makes a huge comparison between Spark vs Storm.
Two main abstractions of apache spark
Apache Spark has a well-defined layer architecture which is designed on two main abstractions:
- Resilient Distributed Dataset (RDD): RDD is an immutable (read-only), fundamental collection of elements or items that can be operated on many devices at the same time (parallel processing). Each dataset in an RDD can be divided into logical portions, which are then executed on different nodes of a cluster.
- Directed Acyclic Graph (DAG): DAG is the scheduling layer of the Apache Spark architecture that implements stage-oriented scheduling. Compared to MapReduce that creates a graph in two stages, Map and Reduce, Apache Spark can create DAGs that contain many stages.
The Apache Spark framework uses a master–slave architecture that consists of a driver, which runs as a master node, and many executors that run across as worker nodes in the cluster. Apache Spark can be used for batch processing and real-time processing as well.
Working apache spark software
The basic Apache Spark architecture is shown in the figure below:
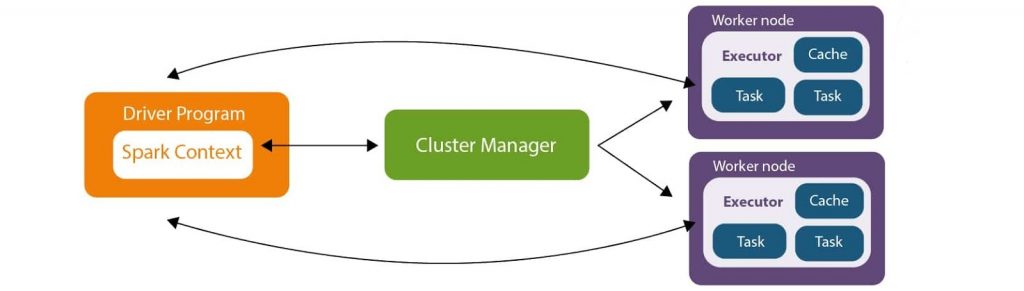
The Driver Program in the Apache Spark architecture calls the main program of an application and creates SparkContext. A SparkContext consists of all the basic functionalities. Spark Driver contains various other components such as DAG Scheduler, Task Scheduler, Backend Scheduler, and Block Manager, which are responsible for translating the user-written code into jobs that are actually executed on the cluster.
Spark Driver and SparkContext collectively watch over the job execution within the cluster. Spark Driver works with the Cluster Manager to manage various other jobs. Cluster Manager does the resource allocating work. And then, the job is split into multiple smaller tasks which are further distributed to worker nodes.
Whenever an RDD is created in the SparkContext, it can be distributed across many worker nodes and can also be cached there.
Worker nodes execute the tasks assigned by the Cluster Manager and return it back to the Spark Context.
An executor is responsible for the execution of these tasks. The lifetime of executors is the same as that of the Spark Application. If we want to increase the performance of the system, we can increase the number of workers so that the jobs can be divided into more logical portions.
Cluster Managers
The SparkContext can work with various Cluster Managers, like Standalone Cluster Manager, Yet Another Resource Negotiator (YARN), or Mesos, which allocate resources to containers in the worker nodes. The work is done inside these containers.
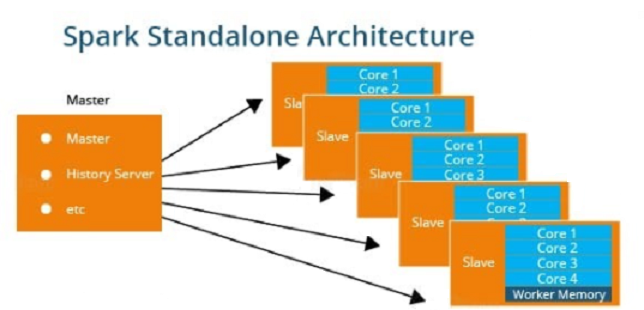
Standalone Cluster
Standalone Master is the Resource Manager and Standalone Worker is the worker in the Spark Standalone Cluster.
In the Standalone Cluster mode, there is only one executor to run the tasks on each worker node.
A client establishes a connection with the Standalone Master, asks for resources, and starts the execution process on the worker node.
Here, the client is the application master, and it requests the resources from the Resource Manager. In this Cluster Manager, we have a Web UI to view all clusters and job statistics.
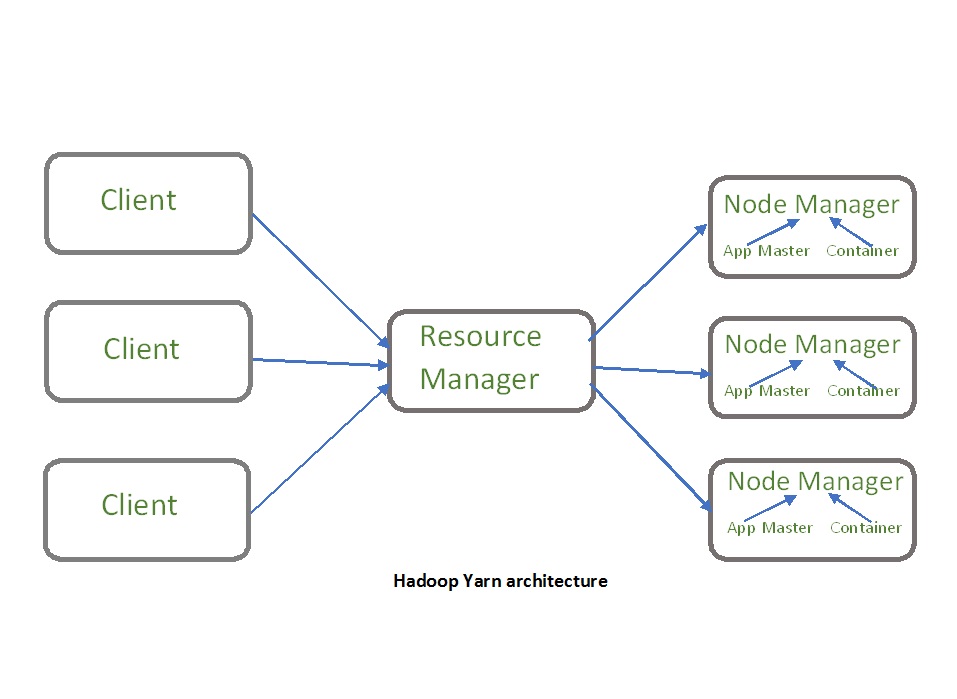
Hadoop YARN (Yet Another Resource Negotiator)
YARN takes care of resource management for the Hadoop ecosystem. It has two components:
- Resource Manager: It manages resources on all applications in the system. It consists of a Scheduler and an Application Manager. The Scheduler allocates resources to various applications.
- Node Manager: Node Manager consists of an Application Manager and a Container. Each task of MapReduce runs in a container. An application or job thus requires one or more containers, and the Node Manager monitors these containers and resource usage. This is reported to the Resource Manager.
YARN also provides security for authorization and authentication of web consoles for data confidentiality. Hadoop uses Kerberos to authenticate its users and services.
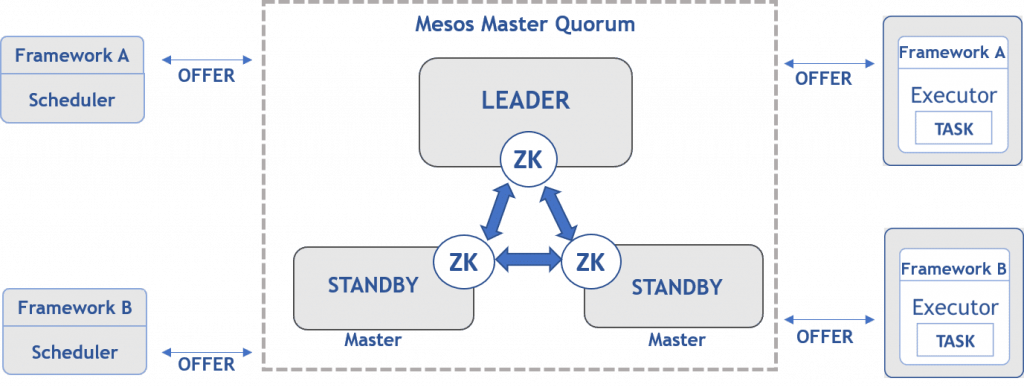
Apache Mesos
Apache Mesos handles the workload from many sources by using dynamic resource sharing and isolation. It helps in deploying and managing applications in large-scale cluster environments. Apache Mesos consists of three components:
- Mesos Master: Mesos Master provides fault tolerance (the capability to operate and recover loss when a failure occurs). A cluster contains many Mesos Masters.
- Mesos Slave: Mesos Slave is an instance that offers resources to the cluster. Mesos Slave assigns resources only when a Mesos Master assigns a task.
- Mesos Frameworks: Mesos Frameworks allow applications to request resources from the cluster so that the application can perform the tasks.
This brings us to the end of this section. To sum up, Spark helps us break down the intensive and high-computational jobs into smaller, more concise tasks which are then executed by the worker nodes. It also achieves the processing of real-time or archived data using its basic architecture.
Apache Spark Components
Apache Spark puts the promise for faster data processing and easier development. How does Spark achieve this? To answer this question, let’s introduce the Apache Spark ecosystem which is the important topic in Apache Spark introduction that makes Spark fast and reliable. These components of Spark resolve the issues that cropped up while using Hadoop MapReduce.
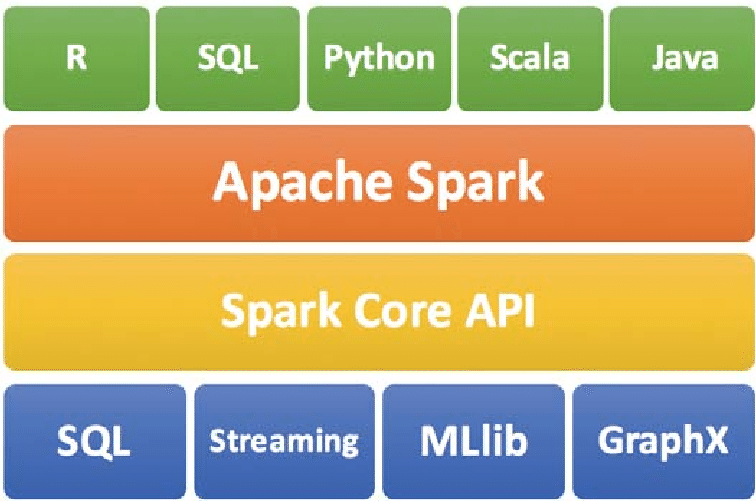
Here we are going to discuss Spark Ecosystem Components one by one
Spark Core
It is the kernel of Spark, which provides an execution platform for all the Spark applications. It is a generalized platform to support a wide array of applications.
Spark SQL
It enables users to run SQL/HQL queries on the top of Spark. Using Apache Spark SQL, we can process structured as well as semi-structured data. It also provides an engine for Hive to run unmodified queries up to 100 times faster on existing deployments.
Spark Streaming
Apache Spark Streaming enables powerful interactive and data analytics applications across live streaming data. The live streams are converted into micro-batches which are executed on top of spark core.
Spark MLlib
It is the scalable machine learning library which delivers both efficiencies as well as the high-quality algorithm. Apache Spark MLlib is one of the hottest choices for Data Scientist due to its capability of in-memory data processing, which improves the performance of iterative algorithms drastically.
Spark GraphX
Apache Spark GraphX is the graph computation engine built on top of spark that enables to process graph data at scale.
SparkR
It is an R package that gives a light-weight frontend to use Apache Spark from R. It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell. The main idea behind SparkR was to explore different techniques to integrate the usability of R with the scalability of Spark.
Resilient Distributed Dataset – RDD
In this section of Apache Spark Tutorial, we will discuss the key abstraction of Spark known as RDD.
Resilient Distributed Dataset (RDD) is the fundamental unit of data in Apache Spark, which is a distributed collection of elements across cluster nodes and can perform parallel operations. Spark RDDs are immutable but can generate new RDD by transforming existing RDD.
There are three ways to create RDDs in Spark:
- Parallelized collections – We can create parallelized collections by invoking the parallelize method in the driver program.
- External datasets – By calling a textFile method one can create RDDs. This method takes the URL of the file and reads it as a collection of lines.
- Existing RDDs – By applying transformation operation on existing RDDs we can create new RDD.
Apache Spark RDDs support two types of operations:
- Transformation – Creates a new RDD from the existing one. It passes the dataset to the function and returns a new dataset.
- Action – Spark Action returns the final result to the driver program or writes it to the external data store.
Spark Shell
Apache Spark provides an interactive spark-shell. It helps Spark applications to easily run on the command line of the system. Using the Spark shell we can run/test our application code interactively. Spark can read from many types of data sources so that it can access and process a large amount of data.
Domain Scenarios of apache spark
Today, there is widespread deployment of big data tools. With each passing day, the requirements of enterprises increase, and therefore there is a need for a faster and more efficient form of data processing. Most streaming data is in an unstructured format, coming in thick and fast continuously.
Banking
Spark is being more and more adopted by the banking sector. It is mainly used here for financial fraud detection with the help of Spark ML. Banks use Spark to handle credit risk assessment, customer segmentation, and advertising. Apache Spark is also used to analyze social media profiles, forum discussions, customer support chat, and emails. This way of analyzing data helps organizations make better business decisions.

Get JOB Oriented Apache Spark Certification Course with Industry Standard Modules
Weekday / Weekend BatchesSee Batch DetailsE-commerce
Spark is widely used in the e-commerce industry. Spark Machine Learning, along with streaming, can be used for real-time data clustering. Businesses can share their findings with other data sources to provide better recommendations to their customers. Recommendation systems are mostly used in the e-commerce industry to show new trends.
Healthcare
Apache Spark is a powerful computation engine to perform advanced analytics on patient records. It helps keep track of patients’ health records easily. The healthcare industry uses Spark to deploy services to get insights such as patient feedback, hospital services, and to keep track of medical data.
Media
Many gaming companies use Apache Spark for finding patterns from their real-time in-game events. With this, they can derive further business opportunities by customizing such as adjusting the complexity-level of the game automatically according to players’ performance, etc. Some media companies, like Yahoo, use Apache Spark for targeted marketing, customizing news pages based on readers’ interests, and so on. They use tools such as Machine Learning algorithms for identifying the readers’ interests category. Eventually, they categorize such news stories in various sections and keep the reader updated on a timely basis.
Travel
Many people land up with travel planners to make their vacation a perfect one, and these travel companies depend on Apache Spark for offering various travel packages. TripAdvisor is one such company that uses Apache Spark to compare different travel packages from different providers. It scans through hundreds of websites to find the best and reasonable hotel price, trip package, etc.
Apache spark cases
Finding a Spark at Yahoo!
Yahoo! has over 1 billion monthly users. Therefore, it has to manage its data arriving at a fast rate on a huge scale. It uses a Hadoop cluster with more than 40,000 nodes to process data. So, it wanted a lightning-fast computing framework for data processing. Hence, Yahoo! adopted Apache Spark to solve its problem.
How Apache Spark Enhanced Data Science at Yahoo!
Although Spark is a quite fast computing engine, it is in demand for many other reasons as follows:
- It works with various programming languages.
- It has an efficient in-memory processing.
- It can be deployed over Hadoop through YARN.
Yahoo! checked Spark over Hadoop using a project, which was intended to explore the power of Spark and Hadoop together. The project was implemented using Spark’s Scala API, which gets executed much faster through Spark, where Hadoop took more time for the same process.
Although Spark’s speed and efficiency is impressive, Yahoo! isn’t removing its Hadoop architecture. They need both; Spark will be preferred for real-time streaming and Hadoop will be used for batch processing. The most interesting fact here is that both can be used together through YARN.
Apache Spark at eBay
An American multinational e-commerce corporation, eBay creates a huge amount of data every day. eBay has lots of existing users, and it adds a huge number of new members every day. Except for sellers and buyers, the most important asset for eBay is data. eBay directly connects buyers and sellers. So, a lightning-fast engine is required to handle huge volumes of this real-time streaming data.
Apache Spark is mainly used to redefine better customer experience and overall performance at eBay. Apache Spark and Hadoop YARN combine the powerful functionalities of both. Hadoop’s thousands of nodes can be leveraged with Spark through YARN.
Applications of apache spark
Since the time of its inception in 2009 and its conversion to an open-source technology, Apache Spark has taken the Big Data world by storm. It has become one of the largest open-source communities that includes over 200 contributors. The prime reason behind its success is its ability to process heavy data faster than ever before.
Spark is a widely used technology adopted by most of the industries. Let’s look at some of the prominent Apache Spark applications:
- Machine Learning: Apache Spark is equipped with a scalable Machine Learning Library called MLlib that can perform advanced analytics such as clustering, classification, dimensionality reduction, etc. Some of the prominent analytics jobs like predictive analysis, customer segmentation, sentiment analysis, etc., make Spark an intelligent technology.
- Fog computing: With the influx of big data concepts, IoT has acquired a prominent space for the invention of more advanced technologies. Based on the theory of connecting digital devices with the help of small sensors, this technology deals with a humongous amount of data emanating from numerous sources. This requires parallel processing, which is certainly not possible on Cloud Computing. Therefore, Fog computing, which decentralizes the data and storage, uses Spark Streaming as a solution to this problem.
- Event detection: The feature of Spark Streaming allows organizations to keep track of rare and unusual behaviors for protecting the systems. Institutions, such as financial, security, and health organizations, use triggers to detect potential risks.
- Interactive analysis: Among the most notable features of Apache Spark is its ability to support interactive analysis. Unlike MapReduce that supports batch processing, Apache Spark processes data faster, because of which it can process exploratory queries without sampling.
Along with Apache Spark applications, now, check out some of the most popular companies that are utilizing various applications of Apache Spark:
- Uber: Uber uses Kafka, Spark Streaming, and HDFS for building a continuous ETL pipeline.
- Pinterest: One of the successful web and mobile application companies, Pinterest uses Spark Streaming in order to gain deep insight into customer engagement details.
- Conviva: The pinnacle video company, Conviva deploys Spark for optimizing the videos and handling live traffic.
Steps to install apache
Step 1: Ensure if Java is installed on your system
Before installing Spark, Java is a must-have for your system. The following command will verify the version of Java installed on your system:
- $java -version
If Java is already installed on your system, you get to see the following output:
java version “1.7.0_71”
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
You have to install Java if it is not installed on your system.
Step 2: Now, ensure if Scala is installed on your system
Installing the Scala programming language is mandatory before installing Spark as it is important for Spark’s implementation. The following command will verify the version of Scala used in your system:
- $scala -version
If the Scala application is already installed on your system, you get to see the following response on the screen:
Scala code runner version 2.11.6 — Copyright 2002-2013, LAMP/EPFL
If you don’t have Scala, then you have to install it on your system. Let’s see how to install Scala.
Step 3: First, download Scala
You need to download the latest version of Scala. Here, you will see the scala-2.11.6 version being used. After downloading, you will be able to find the Scala tar file in the Downloads folder.
Step 4: Now, install Scala
You must follow the given steps to install Scala on your system:
- Extract the Scala tar file using the following command:
- $ tar xvf scala-2.11.6.tgz
- Move Scala software files to the directory (/usr/local/scala) using the following commands:
- $ su –
- Password:
- # cd /home/Hadoop/Downloads/
- # mv scala-2.11.6 /usr/local/scala
- # exit
- Set PATH for Scala using the following command:
- $ export PATH = $PATH:/usr/local/scala/bin
- Now, verify the installation of Scala by checking the version of it
- $scala -version
If your Scala installation is successful, then you will get the following output:
Scala code runner version 2.11.6 — Copyright 2002-2013, LAMP/EPFL
Now, you are welcome to the core of this tutorial section on ‘Download Apache Spark.’ Once, you are ready with Java and Scala on your systems, go to Step 5.
Step 5: Download Apache Spark
After finishing with the installation of Java and Scala, now, in this step, you need to download the latest version of Spark by using the following command:
- spark-1.3.1-bin-hadoop2.6 version
After this, you can find a Spark tar file in the Downloads folder.
Step 6: Install Spark
Follow the below steps for installing Apache Spark.
- Extract the Spark tar file using the following command:
- $ tar xvf spark-1.3.1-bin-hadoop2.6.tgz
- Move Spark software files to the directory using the following commands:
- /usr/local/spark
- $ su –
- Password:
- # cd /home/Hadoop/Downloads/
- # mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
- # exit
- Now, configure the environment for Spark
For this, you need to add the following path to ~/.bashrc file which will add the location, where the Spark software files are located to the PATH variable type.
export PATH = $PATH:/usr/local/spark/bin
- Use the below command for sourcing the ~/.bashrc file
- $ source ~/.bashrc
With this, you have successfully installed Apache Spark on your system. Now, you need to verify it.
Step 7: Verify the Installation of Spark on your system
The following command will open the Spark shell application version:
- $spark-shell
If Spark is installed successfully, then you will be getting the following output:
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark’s default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service naming ‘HTTP class server’ on p
What is spark data frame
In Spark, DataFrames are the distributed collections of data, organized into rows and columns. Each column in a DataFrame has a name and an associated type. DataFrames are similar to traditional database tables, which are structured and concise. We can say that DataFrames are relational databases with better optimization techniques.
Spark DataFrames can be created from various sources, such as Hive tables, log tables, external databases, or the existing RDDs. DataFrames allow the processing of huge amounts of data.
Spark datasets
Datasets are an extension of the DataFrame APIs in Spark. In addition to the features of DataFrames and RDDs, datasets provide various other functionalities.
They provide an object-oriented programming interface, which includes the concepts of classes and objects.
Datasets were introduced when Spark 1.6 was released. They provide the convenience of RDDs, the static typing of Scala, and the optimization features of DataFrames.
Datasets are a collection of Java Virtual Machine (JVM) objects that use Spark’s Catalyst Optimizer to provide efficient processing.
Conclusion
In addition to the MapReduce operations, one can also implement SQL queries and process streaming data through Spark, which were the drawbacks for Hadoop-1. With Spark, developers can develop with Spark features either on a stand-alone basis or combine them with MapReduce programming techniques.