
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial
- File formats in Hadoop Tutorial | A Concise Tutorial Just An Hour
- Controlling Hadoop Jobs Using Oozie Tutorial | The Complete Guide
- Apache Spark Streaming Tutorial | Best Guide For Beginners
- What is Elasticsearch | Tutorial for Beginners
- Amazon Kinesis : Process & Analyze Streaming Data | The Ultimate Student Guide
- Apache Camel Tutorial – EIP, Routes, Components | Ultimate Guide to Learn [BEST & NEW]
- Apache NiFi (Cloudera DataFlow) | Become an expert with Free Online Tutorial
- Kafka Tutorial : Learn Kafka Configuration
- Apache Sqoop Tutorial
- Spark And RDD Cheat Sheet Tutorial
- Apache Pig Tutorial
- Talend
- Cassandra Tutorial
- Kafka Tutorial
- HBase Tutorial
- Spark Java Tutorial
- ELK Stack Tutorial
- Netbeans Tutorial
- PySpark MLlib Tutorial
- Spark RDD Optimization Techniques Tutorial
- Apache Spark & Scala Tutorial
- Apache Impala Tutorial
- Apache Oozie: A Concise Tutorial Just An Hour | LearnoVita
- Apache Storm Advanced Concepts Tutorial
- Apache Storm Tutorial
- Hadoop Mapreduce tutorial
- Hive cheat sheet
- Spark Algorithm Tutorial
- Apache Spark Tutorial
- Apache Cassandra Data Model Tutorial
- Big Data Applications Tutorial
- Advanced Hive Concepts and Data File Partitioning Tutorial
- Hadoop Architecture Tutorial
- Big Data and Hadoop Ecosystem Tutorial
- Apache Mahout Tutorial
- Hadoop Tutorial
- BIG DATA Tutorial

Apache Sqoop Tutorial
Last updated on 13th Oct 2020, Big Data, Blog, Tutorials
Sqoop tutorial provides basic and advanced concepts of Sqoop. Our Sqoop tutorial is designed for beginners and professionals.
Sqoop is an open source framework provided by Apache. It is a command-line interface application for transferring data between relational databases and Hadoop
Our Sqoop tutorial includes all topics of Apache Sqoop with Sqoop features, Sqoop Installation, Starting Sqoop, Sqoop Import, Sqoop where clause, Sqoop Export, Sqoop Integration with Hadoop ecosystem etc.
Subscribe For Free Demo
Error: Contact form not found.
What is Sqoop?
Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and external datastores such as relational databases, enterprise data warehouses.
Sqoop is used to import data from external datastores into Hadoop Distributed File System or related Hadoop eco-systems like Hive and HBase. Similarly, Sqoop can also be used to extract data from Hadoop or its eco-systems and export it to external datastores such as relational databases, enterprise data warehouses. Sqoop works with relational databases such as Teradata, Netezza, Oracle, MySQL, Postgres etc.
Why is Sqoop used?
For Hadoop developers, the interesting work starts after data is loaded into HDFS. Developers play around the data in order to find the magical insights concealed in that Big Data. For this, the data residing in the relational database management systems need to be transferred to HDFS, play around the data and might need to transfer back to relational database management systems. In reality of Big Data world, Developers feel the transferring of data between relational database systems and HDFS is not that interesting, tedious but too seldom required. Developers can always write custom scripts to transfer data in and out of Hadoop, but Apache Sqoop provides an alternative.
Sqoop automates most of the process, depends on the database to describe the schema of the data to be imported. Sqoop uses MapReduce framework to import and export the data, which provides parallel mechanism as well as fault tolerance. Sqoop makes developers life easy by providing command line interface. Developers just need to provide basic information like source, destination and database authentication details in the sqoop command. Sqoop takes care of remaining part.
Sqoop provides many salient features like:
- Full Load
- Incremental Load
- Parallel import/export
- Import results of SQL query
- Compression
- Connectors for all major RDBMS Databases
- Kerberos Security Integration
- Load data directly into Hive/Hbase
- Support for Accumulo
Sqoop is Robust, has great community support and contributions. Sqoop is widely used in most of the Big Data companies to transfer data between relational databases and Hadoop.
Where is Sqoop used?
Relational database systems are widely used to interact with the traditional business applications. So, relational database systems has become one of the sources that generate Big Data.
As we are dealing with Big Data, Hadoop stores and processes the Big Data using different processing frameworks like MapReduce, Hive, HBase, Cassandra, Pig etc and storage frameworks like HDFS to achieve benefit of distributed computing and distributed storage. In order to store and analyze the Big Data from relational databases, Data need to be transferred between database systems and Hadoop Distributed File System (HDFS). Here, Sqoop comes into picture. Sqoop acts like a intermediate layer between Hadoop and relational database systems. You can import data and export data between relational database systems and Hadoop and its eco-systems directly using sqoop.
Key Features of Sqoop
There are many salient features of Sqoop, which shows us the several reasons to learn sqoop.
a. Parallel import/export
While it comes to import and export the data, Sqoop uses YARN framework. Basically, that offers fault tolerance on top of parallelism.
b. Connectors for all major RDBMS Databases
However, for multiple RDBMS databases, Sqoop offers connectors, covering almost the entire circumference.
c. Import results of SQL query
Also, in HDFS, we can import the result returned from an SQL query.
d. Incremental Load
Moreover, we can load parts of table whenever it is updated. Since Sqoop offers the facility of the incremental load.
e. Full Load
It is one of the important features of sqoop, in which we can load the whole table by a single command in Sqoop. Also, by using a single command we can load all the tables from a database.
f. Kerberos Security Integration
Basically, Sqoop supports Kerberos authentication. Where Kerberos defined as a computer network authentication protocol. That works on the basis of ‘tickets’ to allow nodes communicating over a non-secure network to prove their identity to one another in a secure manner.
g. Load data directly into HIVE/HBase
Basically, for analysis, we can load data directly into Apache Hive. Also, can dump your data in HBase, which is a NoSQL database.
h. Compression
By using deflate(gzip) algorithm with –compress argument, We can compress your data. Moreover, it is also possible by specifying –compression-codec argument. In addition, we can also load compressed table in Apache Hive.
i. Support for Accumulo
It is possible that rather than a directory in HDFS we can instruct Sqoop to import the table in Accumulo.
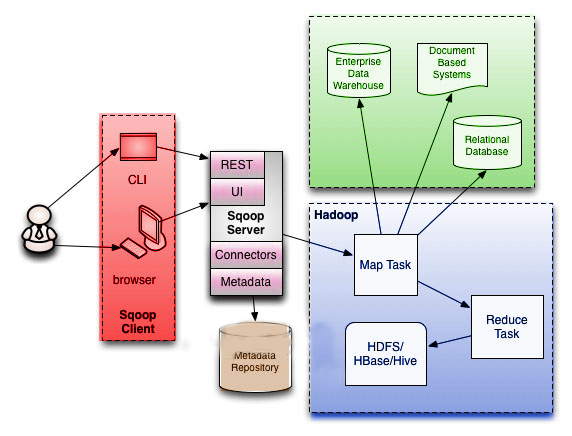
Sqoop Architecture
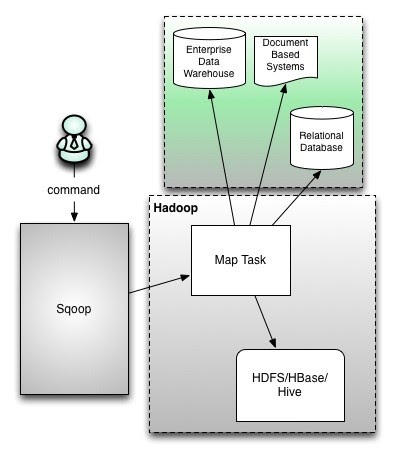
Sqoop Architecture
Sqoop provides command line interface to the end users. Sqoop can also be accessed using Java APIs. Sqoop command submitted by the end user is parsed by Sqoop and launches Hadoop Map only job to import or export data because Reduce phase is required only when aggregations are needed. Sqoop just imports and exports the data; it does not do any aggregations.
Sqoop parses the arguments provided in the command line and prepares the Map job. Map job launch multiple mappers depends on the number defined by user in the command line. For Sqoop import, each mapper task will be assigned with part of data to be imported based on key defined in the command line. Sqoop distributes the input data among the mappers equally to get high performance. Then each mapper creates connection with the database using JDBC and fetches the part of data assigned by Sqoop and writes it into HDFS or Hive or HBase based on the option provided in the command line.
Apache SQOOP Connector operates for a wide range of popular relational databases such as MySQL, Oracle, SQL Server, PostgreSQL, and IBM DB2. Each sub connector within SQOOP knows how to connect and interact with a corresponding relational database for data export and import. It also serves a provision to connect to any database which is capable to use Java’s JDBC protocol. The connector also performs the optimization for MySQL and PostgreSQL databases which use database-specific APIs in order to perform bulk transfers efficiently.
Basic Commands and Syntax for Sqoop
Sqoop-Import
Sqoop import command imports a table from an RDBMS to HDFS. Each record from a table is considered as a separate record in HDFS. Records can be stored as text files, or in binary representation as Avro or SequenceFiles.
Generic Syntax:
$ sqoop import (generic args) (import args)
$ sqoop-import (generic args) (import args)
The Hadoop specific generic arguments must precede any import arguments, and the import arguments can be of any order.
Importing a Table into HDFS
Syntax:
$ sqoop import –connect –table –username –password –target-dir
–connect Takes JDBC url and connects to database
–table Source table name to be imported
–username Username to connect to database
–password Password of the connecting user
–target-dir Imports data to the specified directory
Importing Selected Data from Table
Syntax:
$ sqoop import –connect –table –username –password –columns –where
–columns Selects subset of columns
–where Retrieves the data which satisfies the condition
Importing Data from Query
Syntax:
$ sqoop import –connect –table –username –password –query
–query Executes the SQL query provided and imports the results
Incremental Exports
Syntax:
$ sqoop import –connect –table –username –password –incremental –check-column –last-value
Sqoop import supports two types of incremental imports:
- Append
- Lastmodified.
Append mode is to be used when new rows are continually being added with increasing values. Column should also be specified which is continually increasing with –check-column. Sqoop imports rows whose value is greater than the one specified with –last-value. Lastmodified mode is to be used when records of the table might be updated, and each such update will set the current timestamp value to a last-modified column. Records whose check column timestamp is more recent than the timestamp specified with –last-value are imported.
Notes:
- In JDBC connection string, database host shouldn’t be used as “localhost” as Sqoop launches mappers on multiple data nodes and the mapper will not able to connect to DB host.
- “–password” parameter is insecure as any one can read it from command line. –P option can be used, which prompts for password in console. Otherwise, it is recommended to use –password-file pointing to the file containing password (Make sure you have revoked permission to unauthorized users).
Few arguments helpful with Sqoop import:
| Argument | Description |
|---|---|
| –num-mappers,-m | Mappers to Launch |
| –fields-terminated-by | Field Separator |
| –lines-terminated-by | End of line seprator |
Importing Data into Hive
Below mentioned Hive arguments is used with the sqoop import command to directly load data into Hive:
| Argument | Description |
|---|---|
| –hive-home | Override $HIVE_HOME path |
| –hive-import | Import tables into Hive |
| –hive-overwrite | Overwrites existing Hive table data |
| –create-hive-table | Creates Hive table and fails if that table already exists |
| –hive-table | Sets the Hive table name to import |
| –hive-drop-import-delims | Drops delimiters like\n, \r, and \01 from string fields |
| –hive-delims-replacement | Replaces delimiters like \n, \r, and \01 from string fields with user defined delimiters |
| –hive-partition-key | Sets the Hive partition key |
| –hive-partition-value | Sets the Hive partition value |
| –map-column-hive | Overrides default mapping from SQL type datatypes to Hive datatypes |

Learn Apache Sqoop Training Course with Master Advanced Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Syntax:
$ sqoop import –connect –table –username –password –hive-import –hive-table
Specifying –hive-import, Sqoop imports data into Hive table rather than HDFS directory.
Importing Data into HBase
Below mentioned HBase arguments is used with the sqoop import command to directly load data into HBase:
| Argument | Description |
|---|---|
| –column-family | Sets column family for the import |
| –hbase-create-table | If specified, creates missing HBase tables and fails if already exists |
| –hbase-row-key | Specifies which column to use as the row key |
| –hbase-table | Imports to Hbase table |
Syntax:
$ sqoop import –connect –table –username –password –hbase-table
Specifying –hbase-table, Sqoop will import data into HBase rather than HDFS directory.
Sqoop-Import-all-Tables
The import-all-tables imports all tables in a RDBMS database to HDFS. Data from each table is stored in a separate directory in HDFS. Following conditions must be met in order to use sqoop-import-all-tables:
- Each table should have a single-column primary key.
- You should import all columns of each table.
- You should not use splitting column, and should not check any conditions using where clause.
Generic Syntax:
$ sqoop import-all-tables (generic args) (import args)
$ sqoop-import-all-tables (generic args) (import args)
Sqoop specific arguments are similar with sqoop-import tool, but few options like –table, –split-by, –columns, and –where arguments are invalid.
Syntax:
$ sqoop-import-all-tables —connect –username –password
Sqoop-Export
Sqoop export command exports a set of files in a HDFS directory back to RDBMS tables. The target table should already exist in the database.
Generic Syntax:
$ sqoop export (generic args) (export args)
$ sqoop-export (generic args) (export args)
Sqoop export command prepares INSERT statements with set of input data then hits the database. It is for exporting new records, If the table has unique value constant with primary key, export job fails as the insert statement fails. If you have updates, you can use –update-key option. Then Sqoop prepares UPDATE statement which updates the existing row, not the INSERT statements as earlier.
Syntax:
$ sqoop-export —connect –username –password –export-dir
Sqoop-Job
Sqoop job command allows us to create a job. Job remembers the parameters used to create job, so they can be invoked any time with same arguments.
Generic Syntax:
$ sqoop job (generic args) (job args) [– [subtool name] (subtool args)]
$ sqoop-job (generic args) (job args) [– [subtool name] (subtool args)]
Sqoop-job makes work easy when we are using incremental import. The last value imported is stored in the job configuration of the sqoop-job, so for the next execution it directly uses from configuration and imports the data.
Sqoop-job options:
| Argument | Description |
|---|---|
| –create | Defines a new job with the specified job-id (name). Actual sqoop import command should be seperated by “–“ |
| –delete | Deletes a saved job. |
| –exec | Executes the saved job. |
| –show | Show the save job configuration |
| –list | Lists all the saved jobs |
Syntax:
$ sqoop job –create — import –connect –table
Sqoop-Codegen
Sqoop-codegen command generates Java class files which encapsulate and interpret imported records. The Java definition of a record is initiated as part of the import process. For example, if Java source is lost, it can be recreated. New versions of a class can be created which use different delimiters between fields, and so on.
Generic Syntax:
$ sqoop codegen (generic args) (codegen args)
$ sqoop-codegen (generic args) (codegen args)
Syntax:
$ sqoop codegen –connect –table
Sqoop-Eval
Sqoop-eval command allows users to quickly run simple SQL queries against a database and the results are printed on to the console.
Generic Syntax:
$ sqoop eval (generic args) (eval args)
$ sqoop-eval (generic args) (eval args)
Syntax:
$ sqoop eval –connect –query “SQL query”
Using this, users can be sure that they are importing the data as expected.
Sqoop-List-Database
Used to list all the database available on RDBMS server.
Generic Syntax:
$ sqoop list-databases (generic args) (list databases args)
$ sqoop-list-databases (generic args) (list databases args)
Syntax:
$ sqoop list-databases –connect
Sqoop-List-Tables
Used to list all the tables in a specified database.
Generic Syntax:
$ sqoop list-tables (generic args) (list tables args)
$ sqoop-list-tables (generic args) (list tables args)
Syntax:
$ sqoop list-tables –connect
Sqoop Merge
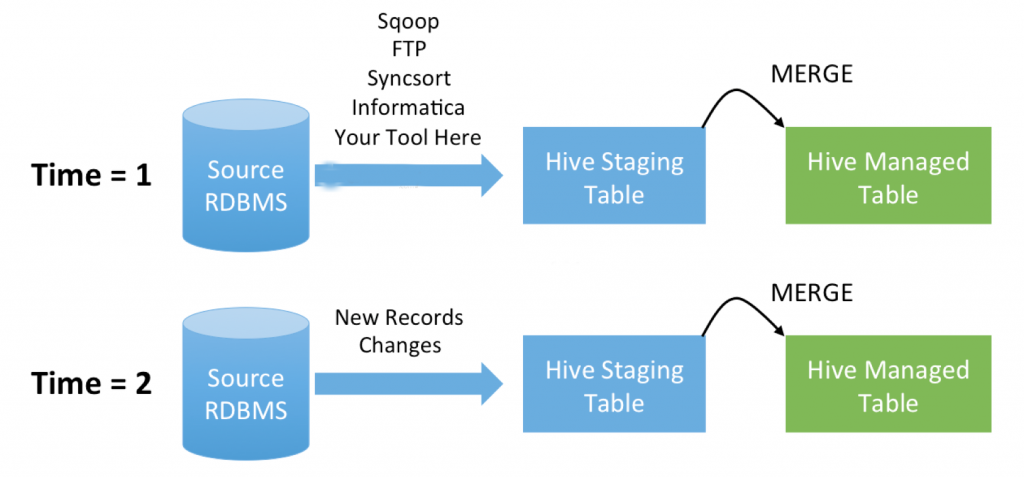
Objective
While it comes to combine two datasets we generally use a merge tool in Sqoop. However, there are many more insights of Sqoop Merge available. So, in this article, we will learn the whole concept of Sqoop Merge. Also, we will see the syntax of Sqoop merge as well as arguments to understand the whole topic in depth.
What is Sqoop Merge?
While it comes to combine two datasets we generally use a merge tool in Sqoop. Especially, where entries in one dataset should overwrite entries of an older dataset. To understand it well, let’s see an example of a sqoop merge.
Here, an incremental import run in last-modified mode will generate multiple datasets in HDFS where successively newer data appears in each dataset. Moreover, this tool will “flatten” two datasets into one, taking the newest available records for each primary key.
In addition, here we assume that there is a unique primary key value in each record when we merge the datasets. Moreover, –merge-key specifies the column for the primary key. Also, make sure that data loss may occur if multiple rows in the same dataset have the same primary key.
Also, we must use the auto-generated class from a previous import to parse the dataset and extract the key column. Moreover, with –class-name and –jar-file we should specify the class name as well as jar file. Although, we can recreate the class using the codegen tool if this is not available.
To be more specific, this tool typically runs after an incremental import with the date-last-modified mode (sqoop import –incremental lastmodified …).
Now let’s suppose that two incremental imports were performed, in an HDFS directory where some older data named older and newer data named newer.
Sqoop Job
Objective
In this Sqoop Tutorial, we discuss what is Sqoop Job. Sqoop Job allows us to create and work with saved jobs in sqoop. First, we will start with a brief introduction to a Sqoop Saved Job. Afterward, we will move forward to the sqoop job, we will learn purpose and syntax of a sqoop job. Also, we will cover the method to create a job in Sqoop and Sqoop Job incremental import.
Saved Jobs in Sqoop
Basically, by issuing the same command multiple times we can perform imports and exports in sqoop repeatedly. Moreover, we can say it is a most expected scenario while using the incremental import capability.
In addition, we can define saved jobs by Sqoop. Basically, that makes this process easier. Moreover, to execute a Sqoop command at a later time we need some information that configuration information is recorded by a sqoop saved job.
Moreover, note that the job descriptions are saved to a private repository stored in $HOME/.sqoop/, by default. Also, we can configure Sqoop to instead use a shared metastore. However, that makes saved jobs available to multiple users across a shared cluster.
What is a Sqoop Job?
Basically, Sqoop Job allows us to create and work with saved jobs. However, to specify a job, Saved jobs remember the parameters we use. Hence, we can re-execute them by invoking the job by its handle. However, we use this re-calling or re-executing in the incremental import. That can import the updated rows from the RDBMS table to HDFS.
In other words, to perform an incremental import if a saved job is configured, then state regarding the most recently imported rows is updated in the saved job. Basically, that allows the job to continually import only the newest rows.
Sqoop Saved Jobs and Passwords
Basically, multiple users can access Sqoop metastore since it is not a secure resource. Hence, Sqoop does not store passwords in the metastore. So, for the security purpose, you will be prompted for that password each time you execute the job if we create a sqoop job that requires a password.
In addition, by setting sqoop.metastore.client.record.password to true in the configuration we can easily enable passwords in the metastore.
Note: If we are executing saved jobs via Oozie we have to set sqoop.metastore.client.record.password to true. It is important since when executed as Oozie tasks, Sqoop cannot prompt the user to enter passwords.
Sqoop Job Incremental Imports
Basically, by comparing the values in a check column against a reference value for the most recent import all the sqoop incremental imports are performed.
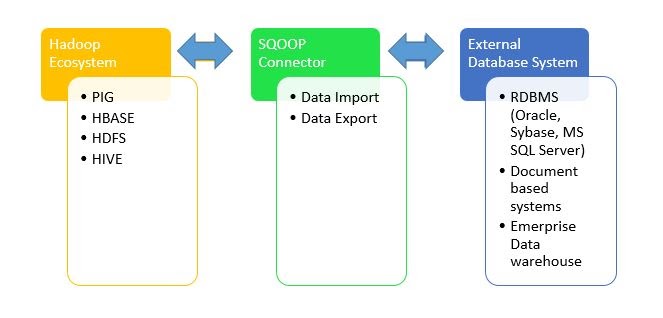
Sqoop Connectors and Drivers
Objective
While it comes to the Hadoop ecosystem, the use of words “connector” and “driver” interchangeably, mean completely different things in the context of Sqoop. For every Sqoop invocation, we need both Sqoop Connectors and drivers. However, there is a lot of confusion about the use and understanding of these Sqoop concepts.
In this article, we will learn the whole concept of Sqoop Connectors and Drivers in Sqoop. Also, we will see an example of Sqoop connector and Sqoop driver to understand both. Moreover, we will see how Sqoop connectors partition, Sqoop connectors format Sqoop connectors extractor and Sqoop connectors loader. Let’s start discussing how we use these concepts in Sqoop to transfer data between Hadoop and other systems.
What is a Sqoop Driver?
Basically, in Sqoop “driver” simply refers to a JDBC Driver. Moreover, JDBC is nothing but a standard Java API for accessing relational databases and some data warehouses. Likewise, the JDK does not have any default implementation also, the Java language prescribes what classes and methods this interface contains. In addition, for writing their own implementation each database vendor is responsible. However, that will communicate with the corresponding database with its native protocol.
What are the Sqoop Connectors?
Basically, for communication with relational database systems, Structured Query Language (SQL) programing language is designed. Almost every database has its own dialect of SQL, there is a standard prescribing how the language should look like. Usually, the basics are working the same across all databases, although, some edge conditions might be implemented differently. However, SQL is a very general query processing language. So, we can say for importing data or exporting data out of the database server, it is not always the optimal way.
Moreover, there is a basic connector that is shipped with Sqoop. That is what we call Generic JDBC Connector in Sqoop. However, by name, it’s using only the JDBC interface for accessing metadata and transferring data. So we can say this may not be the most optimal for your use case still this connector will work on most of the databases out of the box. Also, Sqoop ships with specialized connectors. Like for MySQL, PostgreSQL, Oracle, Microsoft SQL Server, DB2, and Netezza. Hence, we don’t need to download extra connectors to start transferring data. Although, we have special connectors available on the internet which can add support for additional database systems or improve the performance of the built-in connectors.
How to use Sqoop Drivers and Connectors?
Let’s see how Sqoop connects to the database to demonstrate how we use drivers and connectors.
Sqoop will try to load the best performance depending on specified command-line arguments and all available connectors. Basically, with Sqoop scanning this process begins all extra manually downloaded connectors to confirm if we can use one.
Ultimately, we have determined both Sqoop connector and driver. After that, we can establish the connection between the Sqoop client and the target database.
Sqoop Supported Databases
Objective
Basically, we can not use every database out of the box, also some databases may be used in an inefficient manner in Sqoop. So, in this article, we will study Sqoop supported databases. Also, we mention the specific versions of databases for which Sqoop supports.
What are Sqoop Supported Databases?
Basically, JDBC is a compatibility layer. However, that allows a program to access many different databases through a common API. Although slight differences in the SQL language spoken by each database may mean that we can not use every database out of the box, also some databases may be used in an inefficient manner in Sqoop.
Sqoop Troubleshooting
Objective
While working on Sqoop, there is the possibility of many failure encounters. So, to troubleshoot any failure there are several steps we should follow. So, in this article, “Sqoop Troubleshooting” we will learn the Sqoop troubleshooting process or we can say Apache sqoop known issues. Also, we will learn sqoop troubleshooting tips to troubleshoot in a better way.
General Sqoop Troubleshooting Process
While running Sqoop, there are several steps we should follow. Basically, that will help to troubleshoot any failure that we encounter. Such as:
- Generally, we can turn on verbose output by executing the same command again. It will help to identify errors. Also, by specifying the –verbose option. Basically, the Sqoop troubleshooting process produces more debug output on the console. Hence we can easily inspect them.
- Also, to see if there are any specific failures recorded we can look at the task logs from Hadoop. Since failure may occur while task execution is not relayed correctly to the console.
- Basically, Sqoop troubleshooting is just that the necessary input files or input/output tables are present. Moreover, it can be accessed by the user that Sqoop is executing as or connecting to the database as. Since there is a possibility that the necessary files or tables are present. However, it is not necessary that Sqoop connects can access these files.
- Generally, we need to break the job into two separate actions, to see where the problem really occurs. Especially, if you are doing a compound action try breaking them. While compound actions can be like populating a Hive table or partition in a hive.
Conclusion
As a result, we have seen in this Apache Sqoop Tutorial, what is Sqoop. Moreover, we have learned all the tools, working, and Sqoop commands. Also, we have learned the way to Import and Export Sqoop. Afterward, we have learned in Apache Sqoop Tutorial, basic usage of Sqoop.