
- An Overview of AWS Machine Learning Tutorial
- Mapplet In Informatica | Purpose and Implementation of Mapplets | Expert’s Top Picks | Free Guide Tutorial
- Spring Cloud Tutorial
- Azure IoT Hub Integration Tutorial | For Beginners Learn in 1 Day FREE
- Cloud Native Microservices Tutorial | A Comprehensive Guide
- Azure Stream Analytics | Learn in 1 Day FREE Tutorial
- Azure Data Warehouse | Learn in 1 Day FREE Tutorial
- AWS Lambda Tutorial | A Guide to Creating Your First Function
- Azure Logic Apps Tutorial – A beginners Guide & its Complete Overview
- Azure Service Bus Tutorial | Complete Overview – Just An Hour for FREE
- Introduction to Azure Service Fabric Tutorial | Learn from Scratch
- Amazon CloudWatch Tutorial | Ultimate Guide to Learn [BEST & NEW]
- AWS Data Pipeline Documentation Tutorial | For Beginners Learn in 1 Day FREE
- What is Azure App Service? | A Complete Guide for Beginners
- AWS Key Management Service | All You Need to Know
- Apigee Tutorial | A Comprehensive Guide for Beginners
- Kubernetes Tutorial | Step by Step Guide to Basic
- AWS SQS – Simple Queue Service Tutorial | Quickstart – MUST READ
- AWS Glue Tutorial
- MuleSoft
- Cloud Computing Tutorial
- AWS CloudFormation tutorial
- AWS Amazon S3 Bucket Tutorial
- Kubernetes Cheat Sheet Tutorial
- AWS IAM Tutorial
- Cloud Concepts And Models Tutorial
- Cloud Network Security Tutorial
- Azure Active Directory Tutorial
- NetApp Tutorial
- OpenStack tutorial
- AWS Cheat Sheet Tutorial
- Informatica Transformations Tutorial
- AWS vs AZURE Who is The Right Cloud Platform?
- How to Host your Static Website with AWS Tutorial
- VMware Tutorial
- Edge Computing Tutorial
- Cognitive Cloud Computing Tutorial
- Serverless Computing Tutorial
- Sharepoint Tutorial
- AWS Tutorial
- Microsoft Azure Tutorial
- IOT Tutorial
- An Overview of AWS Machine Learning Tutorial
- Mapplet In Informatica | Purpose and Implementation of Mapplets | Expert’s Top Picks | Free Guide Tutorial
- Spring Cloud Tutorial
- Azure IoT Hub Integration Tutorial | For Beginners Learn in 1 Day FREE
- Cloud Native Microservices Tutorial | A Comprehensive Guide
- Azure Stream Analytics | Learn in 1 Day FREE Tutorial
- Azure Data Warehouse | Learn in 1 Day FREE Tutorial
- AWS Lambda Tutorial | A Guide to Creating Your First Function
- Azure Logic Apps Tutorial – A beginners Guide & its Complete Overview
- Azure Service Bus Tutorial | Complete Overview – Just An Hour for FREE
- Introduction to Azure Service Fabric Tutorial | Learn from Scratch
- Amazon CloudWatch Tutorial | Ultimate Guide to Learn [BEST & NEW]
- AWS Data Pipeline Documentation Tutorial | For Beginners Learn in 1 Day FREE
- What is Azure App Service? | A Complete Guide for Beginners
- AWS Key Management Service | All You Need to Know
- Apigee Tutorial | A Comprehensive Guide for Beginners
- Kubernetes Tutorial | Step by Step Guide to Basic
- AWS SQS – Simple Queue Service Tutorial | Quickstart – MUST READ
- AWS Glue Tutorial
- MuleSoft
- Cloud Computing Tutorial
- AWS CloudFormation tutorial
- AWS Amazon S3 Bucket Tutorial
- Kubernetes Cheat Sheet Tutorial
- AWS IAM Tutorial
- Cloud Concepts And Models Tutorial
- Cloud Network Security Tutorial
- Azure Active Directory Tutorial
- NetApp Tutorial
- OpenStack tutorial
- AWS Cheat Sheet Tutorial
- Informatica Transformations Tutorial
- AWS vs AZURE Who is The Right Cloud Platform?
- How to Host your Static Website with AWS Tutorial
- VMware Tutorial
- Edge Computing Tutorial
- Cognitive Cloud Computing Tutorial
- Serverless Computing Tutorial
- Sharepoint Tutorial
- AWS Tutorial
- Microsoft Azure Tutorial
- IOT Tutorial

AWS Glue Tutorial
Last updated on 13th Oct 2020, Blog, Cloud Computing, Tutorials
AWS Glue is a cloud service that prepares data for analysis through automated extract, transform and load (ETL) processes. Glue also supports MySQL, Oracle, Microsoft SQL Server and PostgreSQL databases that run on Amazon Elastic Compute Cloud (EC2) instances in an Amazon Virtual Private Cloud.Nov 30, 2017.
As described above, AWS Glue is a fully managed ETL service that aims to take the difficulties out of the ETL process for organizations that want to get more out of their big data. The initial public release of AWS Glue was in August 2017. Since that date, Amazon has continued to actively release updates for AWS Glue with new features and functionality. Some of the most recent AWS Glue updates include:
- Support for Python 3.6 in Python shell jobs (June 2019).
- Support for connecting directly to AWS Glue via a virtual private cloud (VPC) endpoint (May 2019).
- Support for real-time, continuous logging for AWS Glue jobs with Apache Spark (May 2019).
- Support for custom CSV classifiers to infer the schema of CSV data (March 2019).
The arrival of AWS Glue fills a hole in Amazon’s cloud data processing services. Previously, AWS had services for data acquisition, storage, and analysis, yet it was lacking a solution for data transformation.
Subscribe For Free Demo
Error: Contact form not found.
What is AWS Glue?
- AWS Glue is a fully managed ETL service. This service makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it swiftly and reliably between various data stores.
- It comprises of components such as a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible scheduler that handles dependency resolution, job monitoring, and retries.
- AWS Glue is serverless, this means that there’s no infrastructure to set up or manage.
When Should I Use AWS Glue?
1. To build a data warehouse to organize, cleanse, validate, and format data.
- You can transform as well as move AWS Cloud data into your data store.
- You can also load data from disparate sources into your data warehouse for regular reporting and analysis.
- By storing it in a data warehouse, you integrate information from different parts of your business and provide a common source of data for decision making.
2. When you run serverless queries against your Amazon S3 data lake.
- AWS Glue can catalog your Amazon Simple Storage Service (Amazon S3) data, making it available for querying with Amazon Athena and Amazon Redshift Spectrum.
- With crawlers, your metadata stays in synchronization with the underlying data. Athena and Redshift Spectrum can directly query your Amazon S3 data lake with the help of the AWS Glue Data Catalog.
- With AWS Glue, you access as well as analyze data through one unified interface without loading it into multiple data silos.
3. When you want to create event-driven ETL pipelines
- You can run your ETL jobs as soon as new data becomes available in Amazon S3 by invoking your AWS Glue ETL jobs from an AWS Lambda function.
- You can also register this new dataset in the AWS Glue Data Catalog considering it as part of your ETL jobs.
4. To understand your data assets.
- You can store your data using various AWS services and still maintain a unified view of your data using the AWS Glue Data Catalog.
- View the Data Catalog to quickly search and discover the datasets that you own, and maintain the relevant metadata in one central repository.
- The Data Catalog also serves as a drop-in replacement for your external Apache Hive Metastore.
Under the hood of AWS Glue is:
- The AWS Glue Data Catalog, a metadata repository that contains references to data sources and targets that will be part of the ETL process.
- An ETL engine that automatically generates scripts in Python and Scala for use throughout the ETL process.
- A scheduler that can run jobs and trigger events based on time-based and other criteria.
The purpose of AWS Glue is to facilitate the construction of an enterprise-class data warehouse. Information can be moved into the data warehouse from a variety of sources, including transactional databases as well as the Amazon cloud.According to Amazon, there are many possible use cases for AWS Glue to simplify ETL tasks, including:
- Discovering metadata about your various databases and data stores, and archiving them in the AWS Glue Data Catalog.
- Creating ETL scripts in order to transform, denormalize, and enrich the data while en route from source to target.
- Automatically detecting changes in your database schema and adjusting the service in order to match them.
- Launching ETL jobs based on a particular trigger, schedule, or event.
- Collecting logs, metrics, and KPIs on your ETL operations for monitoring and reporting purposes.
- Handling errors and retrying in order to prevent stalling during the process.
- Scaling resources automatically in order to fit the needs of your current situation.
ETL engine
After data is cataloged, it is searchable and ready for ETL jobs. AWS Glue includes an ETL script recommendation system to create Python and Spark (PySpark) code, as well as an ETL library to execute jobs. A developer can write ETL code via the Glue custom library, or write PySpark code via the AWS Glue Console script editor.
A developer can also import custom PySpark code or libraries. The developer can also upload code for existing ETL jobs to an S3 bucket, then create a new Glue job to process the code. AWS also provides sample code for Glue in a GitHub repository.
AWS Glue Features
Since Amazon Glue is completely managed by AWS, deployment and maintenance is super simple. Below are some important features of Glue:
1. Integrated Data Catalog
The Data Catalog is a persistent metadata store for all kind of data assets in your AWS account. Your AWS account will have one Glue Data Catalog. This is the place where multiple disjoint systems can store their metadata. In turn, they can also use this metadata to query and transform the data. The catalog can store table definitions, job definition, and other control information that help manage the ETL environment inside Glue.
2. Automatic Schema Discovery
AWS Glue allows you to set up crawlers that connect to the different data source. It classifies the data, obtains the schema related info and automatically stores it in the data catalog. ETL jobs can then use this information to manage ETL operations.
3. Code Generation
AWS Glue comes with an exceptional feature that can automatically generate code to extract, transform and load your data. The only input Glue would need is the path/location where the data is stored. From there, glue creates ETL scripts by itself to transform, flatten and enrich data. Normally, scala and python code is generated for Apache spark.
4. Developer Endpoints
This is one of the best features of Amazon Glue and helps interactively develop ETL code. When Glue automatically generates a code for you, you will need to debug, edit and test the same. The Developer Endpoints provide you with this service. Using this, custom readers, writers or transformations can be created. These can further be imported into Glue ETL jobs as custom libraries.
5. Flexible Job Scheduler
One of the most important features of Glue is that it can be invoked as per schedule, on-demand or on an event trigger basis. Also, you can simply start multiple jobs in parallel. Using the scheduler, you can also build complex ETL pipelines by specifying dependencies across jobs. AWS Glue ETL always retries the jobs in case they fail. They also automatically initiate filtering for infected or bad data. All kinds of inter job dependencies will be handled by Glue.
AWS Glue jobs can execute on a schedule. A developer can schedule ETL jobs at a minimum of five-minute intervals. AWS Glue cannot handle streaming data.
If a dev team prefers to orchestrate its workloads, the service allows scheduled, on-demand and job completion triggers. A scheduled trigger executes jobs at specified intervals, while an on-demand trigger executes when prompted by the user. With a job completion trigger, single or multiple jobs can execute when a job finishes. These jobs can trigger at the same time or sequentially, and they can also trigger from an outside service, such as AWS Lambda.
Benefits
Cost effective
AWS Glue is serverless. There is no infrastructure to provision or manage. AWS Glue handles provisioning, configuration, and scaling of the resources required to run your ETL jobs on a fully managed, scale-out Apache Spark environment. You pay only for the resources used while your jobs are running.
Less hassle
AWS Glue is integrated across a wide range of AWS services, meaning less hassle for you when onboarding. AWS Glue natively supports data stored in Amazon Aurora and all other Amazon RDS engines, Amazon Redshift, and Amazon S3, as well as common database engines and databases in your Virtual Private Cloud (Amazon VPC) running on Amazon EC2.
More power
AWS Glue automates much of the effort in building, maintaining, and running ETL jobs. AWS Glue crawls your data sources, identifies data formats, and suggests schemas and transformations. AWS Glue automatically generates the code to execute your data transformations and loading processes.
Use cases
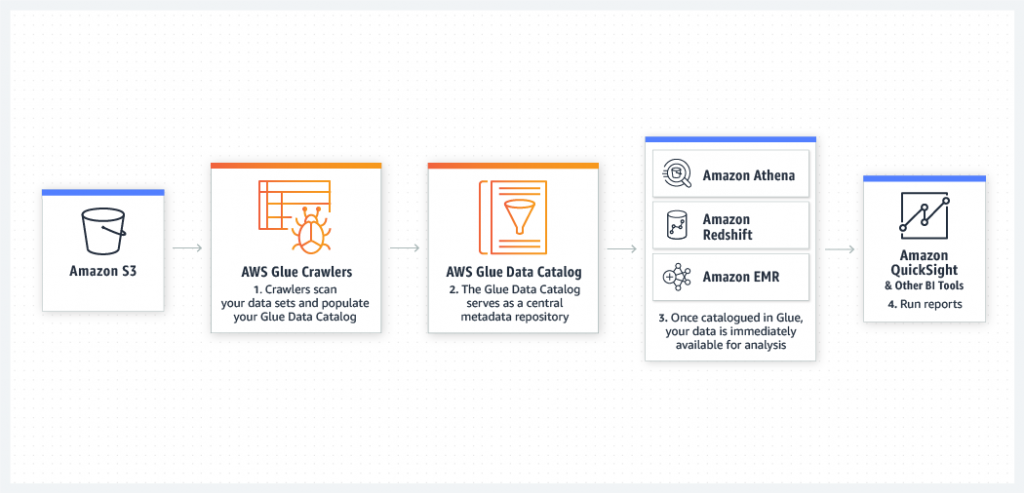
Queries against an Amazon S3 data lake
Data lakes are an increasingly popular way to store and analyze both structured and unstructured data. If you want to build your own custom Amazon S3 Data Lake, AWS Glue can make all your data immediately available for analytics without moving the data.
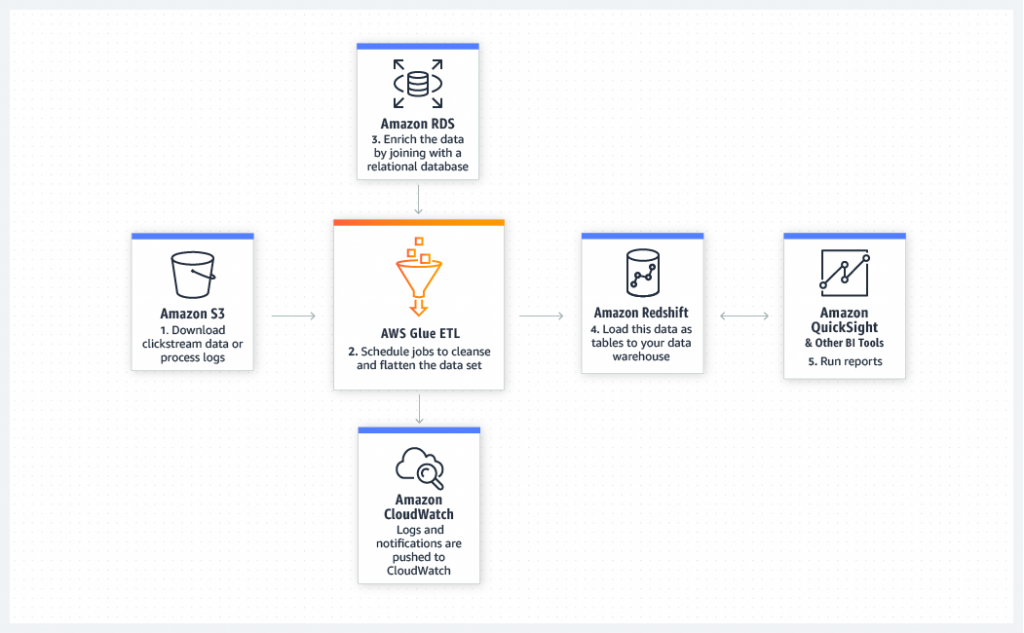
Analyze log data in your data warehouse
Prepare your clickstream or process log data for analytics by cleaning, normalizing, and enriching your data sets using AWS Glue. AWS Glue generates the schema for your semi-structured data, creates ETL code to transform, flatten, and enrich your data, and loads your data warehouse on a recurring basis.
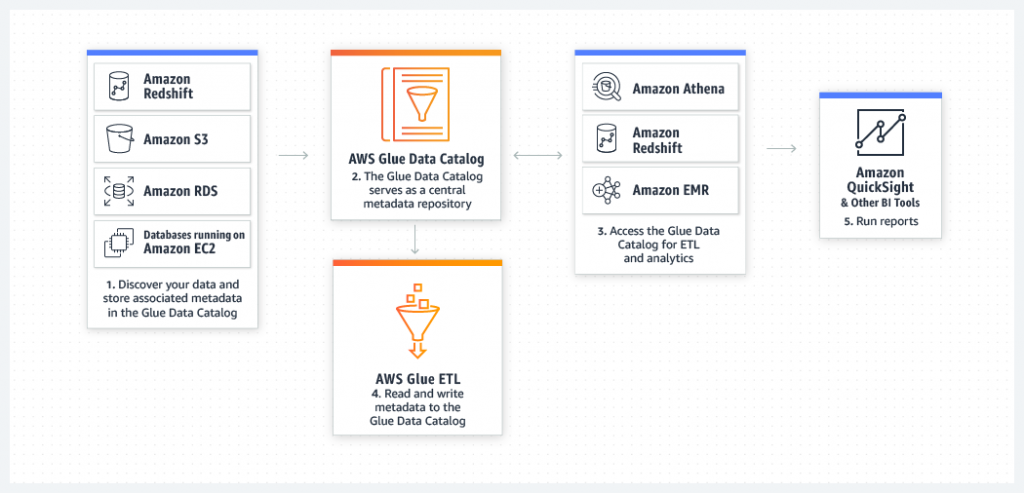
Unified view of your data across multiple data stores
You can use the AWS Glue Data Catalog to quickly discover and search across multiple AWS data sets without moving the data. Once the data is cataloged, it is immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
Event-driven ETL pipelines
AWS Glue can run your ETL jobs based on an event, such as getting a new data set. For example, you can use an AWS Lambda function to trigger your ETL jobs to run as soon as new data becomes available in Amazon S3. You can also register this new dataset in the AWS Glue Data Catalog as part of your ETL jobs.
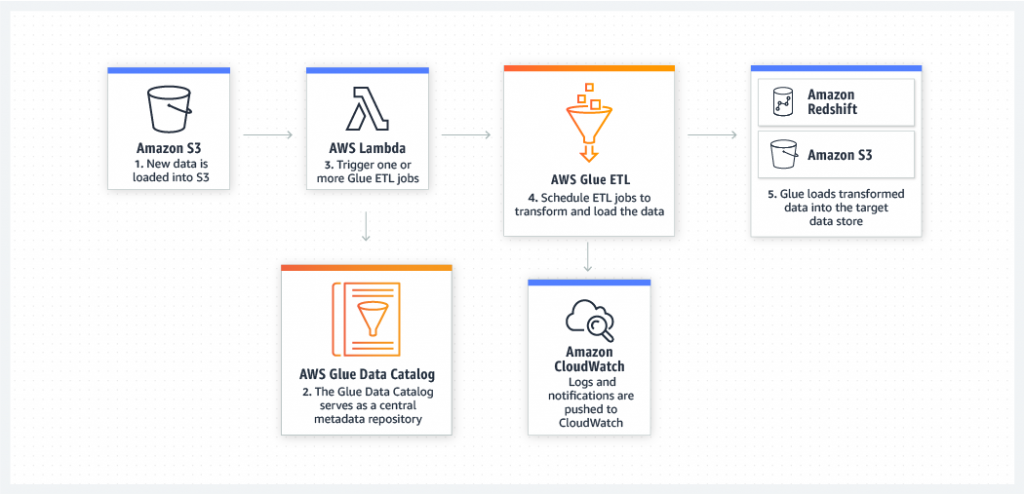
AWS Glue Use Cases
This section highlights the most common use cases of Glue. You can use Glue with some of the famous tools and applications listed below:
- AWS Glue with Athena
In Athena, you can easily use AWS Glue Catalog to create databases and tables, which can later be queried. Alternatively, you can use Athena in AWS Glue ETL to create the schema and related services in Glue.
- AWS Glue for Non-native JDBC Data Sources
AWS Glue by default has native connectors to data stores that will be connected via JDBC. This can be used in AWS or anywhere else on the cloud as long as they are reachable via an IP. AWS Glue natively supports the following data stores- Amazon Redshift, Amazon RDS ( Amazon Aurora, MariaDB, MSSQL Server, MySQL, Oracle, PgSQL.)

Enroll in Best AWS Glue Training and Get Hired by TOP MNCs
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- AWS Glue integrated with AWS Data Lake
AWS Glue can be integrated with AWS Data Lake. Further, ETL processes can be run to ingest, clean, transform and structure data that is important to you.
- Snowflake with AWS Glue
Snowflake has great plugins that seamlessly gel with AWS Glue. Snowflake data warehouse customers can manage their programmatic data integration process without worrying about physically maintain it or maintaining any kind of servers and spark clusters. This allows you to get the benefits of Snowflake’s query pushdown, SQL translation into Snowflake and Spark workloads.
AWS Glue Limitations and Challenges
While there are many noteworthy features of AWS glue, there are some serious limitations as well.
- In comparison to the other ETL options available today, Glue has only a few pre-built components. Also, given it is developed by and for the AWS Console, it is not open to match all kinds of environments.
- Glue works well only with ETL from JDBC and S3 (CSV) data sources. In case you are looking to load data from other cloud applications, File Storage Base, etc. Glue would not be able to support.
- Using Glue, all data is first staged on S3. This sync has no option for incremental sync from your data source. This can be limiting if you are looking ETL data in real-time.
- Glue is a managed AWS Service for Apache spark and not a full-fledged ETL solution. Tons of new work is required to optimize pyspark and scala for Glue.
- Glue does not give any control over individual table jobs. ETL is applicable to the complete database.
- While Glue provides support to writing transformations in scala and python, it does not provide an environment to test the transformation. You are forced to deploy your transformation on parts of real data, thereby making the process slow and painful.
- Glue does not have good support for traditional relational database type of queries. Only SQL types of queries are supported that too through some complicated virtual table.
- The learning curve for Glue is steep. If you are looking to use glue for your ETL needs, then you would have to ensure that your team comprises engineering resources that have a strong knowledge of spark concepts.
- The soft limit of handling concurrent jobs is 3 only, though it can be increased by building a queue for handling limits. You will have to write a script to handle a smart auto-DPU to adjust the input data size.
AWS Glue Concepts
You define jobs in AWS Glue to accomplish the work that’s required to extract, transform, and load (ETL) data from a data source to a data target. You typically perform the following actions:
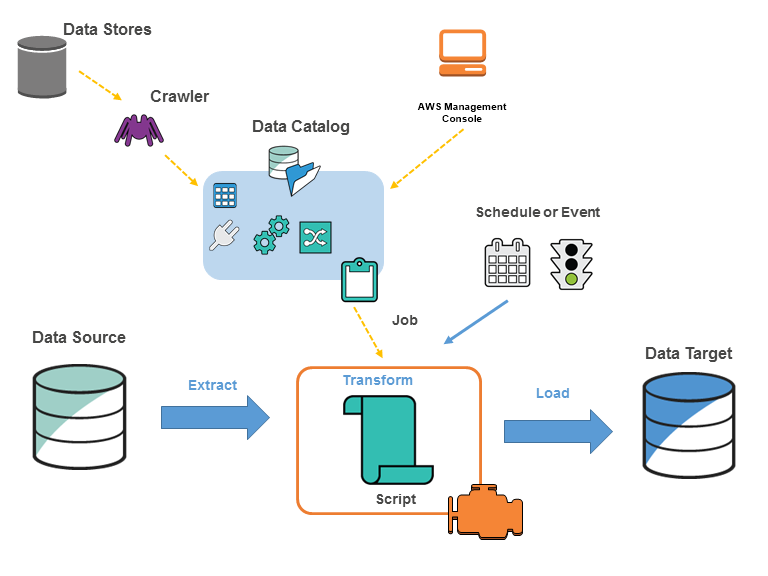
- Firstly, you define a crawler to populate your AWS Glue Data Catalog with metadata table definitions. You point your crawler at a data store, and the crawler creates table definitions in the Data Catalog.In addition to table definitions, the Data Catalog contains other metadata that is required to define ETL jobs. You use this metadata when you define a job to transform your data.
- AWS Glue can generate a script to transform your data or you can also provide the script in the AWS Glue console or API.
- You can run your job on-demand, or you can set it up to start when a specified trigger occurs. The trigger can be a time-based schedule or an event.
- When your job runs, a script extracts data from your data source, transforms the data, and loads it to your data target. This script runs in an Apache Spark environment in AWS Glue.
AWS Glue Terminology
| Terminology | Description |
| Data Catalog | The persistent metadata store in AWS Glue. It contains table definitions, job definitions, and other control information to manage your AWS Glue environment. |
| Classifier | Determines the schema of your data. AWS Glue provides classifiers for common file types, such as CSV, JSON, AVRO, XML, and others. |
| Connection | It contains the properties that are required to connect to your data store. |
| Crawler | A program that connects to a data store (source or target), progresses through a prioritized list of classifiers to determine the schema for your data and then creates metadata tables in the Data Catalog. |
| Database | A set of associated Data Catalog table definitions organized into a logical group in AWS Glue. |
| Data Store, Data Source, Data Target | A data store is a repository for persistently storing your data. Data source is a data store that is used as input to a process or transform. A data target is a data store that a process or transform writes to. |
| Development Endpoint | An environment that you can use to develop and test your AWS Glue ETL scripts. |
| Job | The business logic is required to perform ETL work. It is composed of a transformation script, data sources, and data targets. |
| Notebook Server | A web-based environment that you can use to run your PySpark statements. PySpark is a Python dialect for ETL programming. |
| Script | Code that extracts data from sources, transforms it and loads it into targets. AWS Glue generates PySpark or Scala scripts. |
| Table | It is the metadata definition that represents your data. A table defines the schema of your data. |
| Transform | You use the code logic to manipulate your data into a different format. |
| Trigger | Initiates an ETL job. You can define triggers based on a scheduled time or event. |
How does AWS Glue work?
Here I am going to demonstrate an example where I will create a transformation script with Python and Spark. I will also cover some basic Glue concepts such as crawler, database, table, and job.
1.Create a data source for AWS Glue:
Glue can read data from a database or S3 bucket. For example, I have created an S3 bucket called glue-bucket-edureka. Create two folders from S3 console and name them read and write. Now create a text file with the following data and upload it to the read folder of S3 bucket.
rank,movie_title,year,rating
- The Shawshank Redemption,1994,9.2
- The Godfather,1972,9.2
- The Godfather: Part II,1974,9.0
- The Dark Knight,2008,9.0
- 12 Angry Men,1957,8.9
- Schindler’s List,1993,8.9
- The Lord of the Rings: The Return of the King,2003,8.9
- Pulp Fiction,1994,8.9
- The Lord of the Rings: The Fellowship of the Ring,2001,8.8
- Fight Club,1999,8.8
2.Crawl the data source to the data catalog:
In this step, we will create a crawler. The crawler will catalog all files in the specified S3 bucket and prefix. All the files should have the same schema. In Glue crawler terminology the file format is known as a classifier. The crawler identifies the most common classifiers automatically including CSV, json and parquet. Our sample file is in the CSV format and will be recognized automatically.
- In the left panel of the Glue management console click Crawlers.
- Click the blue Add crawler button.
- Give the crawler a name such as glue-demo-edureka-crawler.
- In Add a data store menu choose S3 and select the bucket you created. Drill down to select the read folder.
- In Choose an IAM role create new. Name the role to for example glue-demo-edureka-iam-role.
- In Configure the crawler’s output add a database called glue-demo-edureka-db.
When you are back in the list of all crawlers, tick the crawler that you created. Click Run crawler.
3. The crawled metadata in Glue tables:
Once the data has been crawled, the crawler creates a metadata table from it. You find the results from the Tables section of the Glue console. The database that you created during the crawler setup is just an arbitrary way of grouping the tables. Glue tables don’t contain the data but only the instructions on how to access the data.
4. AWS Glue jobs for data transformations:
From the Glue console left panel go to Jobs and click blue Add job button. Follow these instructions to create the Glue job:
- Name the job as glue-demo-edureka-job.
- Choose the same IAM role that you created for the crawler. It can read and write to the S3 bucket.
- Type: Spark.
- Glue version: Spark 2.4, Python 3.
- This job runs: A new script to be authored by you.
- Security configuration, script libraries, and job parameters
- Maximum capacity: 2. This is the minimum and costs about 0.15$ per run.
- Job timeout: 10. Prevents the job to run longer than expected.
- Click Next and then Save job and edit the script.
5. Editing the Glue script to transform the data with Python and Spark:
Copy the following code to your Glue script editor Remember to change the bucket name for the s3_write_path variable. Save the code in the editor and click Run job.
IMPORT LIBRARIES AND SET VARIABLES
Import python modules
from datetime import datetime
Import pyspark modules
Import glue modules
Initialize contexts and session
Parameters
EXTRACT (READ DATA)
Log starting time
Read movie data to Glue dynamic frame
dynamic_frame_read = glue_context.create_dynamic_frame.from_catalog(database = glue_db, table_name = glue_tbl)
Convert dynamic frame to data frame to use standard pyspark functions
data_frame = dynamic_frame_read.toDF()
TRANSFORM (MODIFY DATA)
Create a decade column from year
Group by decade: Count movies, get average rating
Print result table
Note: Show function is an action. Actions force the execution of the data frame plan. With big data the slowdown would be significant without cacching.
data_frame_aggregated.show(10)
LOAD (WRITE DATA)
Create just 1 partition, because there is so little data
data_frame_aggregated = data_frame_aggregated.repartition(1)
Convert back to dynamic frame
dynamic_frame_write = DynamicFrame.fromDF(data_frame_aggregated, glue_context, “dynamic_frame_write”)
Write data back to S3
Here you could create S3 prefixes according to a values in specified columns
“partitionKeys”: [“decade”]
Log end time
The detailed explanations are commented in the code. Here is the high-level description:
- Read the movie data from S3
- Get movie count and rating average for each decade
- Write aggregated data back to S3
The execution time with 2 Data Processing Units (DPU) was around 40 seconds. A relatively longduration is explained by the start-up overhead
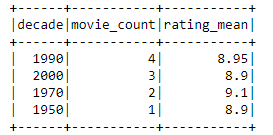
The data transformation script creates summarized movie data. For example, 2000 decade has 3 movies in IMDB top 10 with average rating 8.9. You can download the result file from the write folder of your S3 bucket. Another way to investigate the job would be to take a look at the CloudWatch logs.
The data is stored back to S3 as a CSV in the “write” prefix. The number of partitions equals the number of the output files.
With this, we have come to the end of this article on AWS Glue. I hope you have understood everything that I have explained here.
Conclusion
For many developers and IT professionals, AWS Glue has successfully helped them reduce the complexity and manual labor involved in the ETL process since its release in August 2017.
However, the drawbacks of AWS Glue, such as the newness of the service and the difficult learning curve, mean that it’s not the right choice for every situation. Companies that are looking for a more well-established, user-friendly, fully managed ETL solution with strong customer support would do well to check out Xplenty.