
- An Overview of AWS Machine Learning Tutorial
- Mapplet In Informatica | Purpose and Implementation of Mapplets | Expert’s Top Picks | Free Guide Tutorial
- Spring Cloud Tutorial
- Azure IoT Hub Integration Tutorial | For Beginners Learn in 1 Day FREE
- Cloud Native Microservices Tutorial | A Comprehensive Guide
- Azure Stream Analytics | Learn in 1 Day FREE Tutorial
- Azure Data Warehouse | Learn in 1 Day FREE Tutorial
- AWS Lambda Tutorial | A Guide to Creating Your First Function
- Azure Logic Apps Tutorial – A beginners Guide & its Complete Overview
- Azure Service Bus Tutorial | Complete Overview – Just An Hour for FREE
- Introduction to Azure Service Fabric Tutorial | Learn from Scratch
- Amazon CloudWatch Tutorial | Ultimate Guide to Learn [BEST & NEW]
- AWS Data Pipeline Documentation Tutorial | For Beginners Learn in 1 Day FREE
- What is Azure App Service? | A Complete Guide for Beginners
- AWS Key Management Service | All You Need to Know
- Apigee Tutorial | A Comprehensive Guide for Beginners
- Kubernetes Tutorial | Step by Step Guide to Basic
- AWS SQS – Simple Queue Service Tutorial | Quickstart – MUST READ
- AWS Glue Tutorial
- MuleSoft
- Cloud Computing Tutorial
- AWS CloudFormation tutorial
- AWS Amazon S3 Bucket Tutorial
- Kubernetes Cheat Sheet Tutorial
- AWS IAM Tutorial
- Cloud Concepts And Models Tutorial
- Cloud Network Security Tutorial
- Azure Active Directory Tutorial
- NetApp Tutorial
- OpenStack tutorial
- AWS Cheat Sheet Tutorial
- Informatica Transformations Tutorial
- AWS vs AZURE Who is The Right Cloud Platform?
- How to Host your Static Website with AWS Tutorial
- VMware Tutorial
- Edge Computing Tutorial
- Cognitive Cloud Computing Tutorial
- Serverless Computing Tutorial
- Sharepoint Tutorial
- AWS Tutorial
- Microsoft Azure Tutorial
- IOT Tutorial
- An Overview of AWS Machine Learning Tutorial
- Mapplet In Informatica | Purpose and Implementation of Mapplets | Expert’s Top Picks | Free Guide Tutorial
- Spring Cloud Tutorial
- Azure IoT Hub Integration Tutorial | For Beginners Learn in 1 Day FREE
- Cloud Native Microservices Tutorial | A Comprehensive Guide
- Azure Stream Analytics | Learn in 1 Day FREE Tutorial
- Azure Data Warehouse | Learn in 1 Day FREE Tutorial
- AWS Lambda Tutorial | A Guide to Creating Your First Function
- Azure Logic Apps Tutorial – A beginners Guide & its Complete Overview
- Azure Service Bus Tutorial | Complete Overview – Just An Hour for FREE
- Introduction to Azure Service Fabric Tutorial | Learn from Scratch
- Amazon CloudWatch Tutorial | Ultimate Guide to Learn [BEST & NEW]
- AWS Data Pipeline Documentation Tutorial | For Beginners Learn in 1 Day FREE
- What is Azure App Service? | A Complete Guide for Beginners
- AWS Key Management Service | All You Need to Know
- Apigee Tutorial | A Comprehensive Guide for Beginners
- Kubernetes Tutorial | Step by Step Guide to Basic
- AWS SQS – Simple Queue Service Tutorial | Quickstart – MUST READ
- AWS Glue Tutorial
- MuleSoft
- Cloud Computing Tutorial
- AWS CloudFormation tutorial
- AWS Amazon S3 Bucket Tutorial
- Kubernetes Cheat Sheet Tutorial
- AWS IAM Tutorial
- Cloud Concepts And Models Tutorial
- Cloud Network Security Tutorial
- Azure Active Directory Tutorial
- NetApp Tutorial
- OpenStack tutorial
- AWS Cheat Sheet Tutorial
- Informatica Transformations Tutorial
- AWS vs AZURE Who is The Right Cloud Platform?
- How to Host your Static Website with AWS Tutorial
- VMware Tutorial
- Edge Computing Tutorial
- Cognitive Cloud Computing Tutorial
- Serverless Computing Tutorial
- Sharepoint Tutorial
- AWS Tutorial
- Microsoft Azure Tutorial
- IOT Tutorial

AWS Amazon S3 Bucket Tutorial
Last updated on 10th Oct 2020, Blog, Cloud Computing, Tutorials
Amazon S3
Amazon Simple Storage Service (Amazon S3) is a scalable, high-speed, web-based cloud storage service. The service is designed for online backup and archiving of data and applications on Amazon Web Services. Amazon S3 was designed with a minimal feature set and created to make web-scale computing easier for developers.
Subscribe For Free Demo
Error: Contact form not found.
AWS S3 – Objective
In our previous AWS Tutorial, we learned AWS EBS (Elastic Block Store). In this Amazon S3 Tutorial, we will see what is AWS S3. Moreover, we will discuss the benefits of Amazon S3. At last, we will study some uses of Amazon Web Services S3.
What is Amazon S3?
Nowadays companies want to collect, store, and analyze their data which is large in amount. Moreover, they want to provide the security to them. The large storage problems bring complexities to the companies and slow down their innovation. AWS S3 stores the data in the large amount and provides scalability, durability, and security Amazon S3 works with the business process and it allows anyone to securely run queries of the data without moving it to the separate analytics platform.
Do you know about AWS Management Console?
Amazon S3 lets you store an abundance of data and from anywhere. It also provides integration from the largest community of third-party solutions, system integrator partner and other AWS services.
Benefits of AWS S3
Amazon S3 has innumerable benefits and some of them are stated below-
a. Compliance Capability
Amazon S3 supports three different forms of encryption. For auditing purpose, S3 provides a secure integration with AWS Cloudtrail to monitor and retain storage API call activities. Amazon Macie is a platform by AWS which uses machine learning to automatically discover, arrange and secure the data in AWS. S3 also supports security standards and compliance certifications. This helps customers to satisfy compliance requirements for virtually every regulatory agency around the globe.
b. Flexible Management
Storage administrators help to arrange report and visualize data usage. This will help to monitor the data and reduce cost while improving the services. Amazon S3 along with the AWS Lambda helps customers to log activities, define alerts and many more functions without managing any other infrastructure.
c. Flexible data transfer
Amazon S3 provides myriads of ways to transfer data into the Amazon S3. This is possible with the help of the API which transfers the data through the internet. Direct connect is one of the major sources for the data transfer among S3 which helps to transfer data to the public as well as private networks. AWS snowball provides a petabyte-level data transfer system. AWS Storage gateway provides the on-premises storage gateway which sends the data directly to the cloud through the premises of the user.
d. A systematic way of work
AWS S3 allows the user to run the Big data analytics on a particular system without moving it to another analytics system. Amazon Redshift spectrum allows the user to run both the data warehouse and the S3. AWS S3 select helps the user to retrieve the data back which the user is in need of the S3 objects. Amazon Athena provides the user the vast amount of unstructured data to a user familiar with SQL.
e. Durability, Availability, and Scalability
Amazon S3 is most durable as it works on global cloud infrastructure. The data is transferred within three physical availability zones which are far away from the AWS Region. The S3 is available in most of the places and it offers AWS customer an easier and effective way to design and operate applications and database.
4. Uses of Amazon S3
These are the AWS S3 Uses, let’s discuss them one by one:
a. Data Archiving
AWS S3 and Amazon Glacier help the customer by providing storage facility to meet the need of compliance archives as the organizations need fast access to the data. To meet the system retention Amazon Glacier provides Write once read much storage. Lifecycle policies make transitioning data between Amazon S3 and Amazon Glacier storage classes simple.
b. Large Data Storage and Analytics
A large amount of the data which can be of different types can be stored in the S3 bucket and it can be used as a data lake for big data analytics. AWS S3 provides us with many services which help us to manage big Data by reducing cost and increasing the speed of innovation.
c. Backup and recovery
AWS S3 provides highly durable and secure places for backing up and archiving the data. Amazon S3 and Amazon Glacier provide four different storage classes. This helps to optimize cost and performance while meeting the Recovery Point Objective and Recovery Time Objective.
Amazon S3 features
S3 provides 99.999999999% durability for objects stored in the service and supports multiple security and compliance certifications. An administrator can also link S3 to other AWS security and monitoring services, including CloudTrail, CloudWatch and Macie. There’s also an extensive partner network of vendors that link their services directly to S3.
Data can be transferred to S3 over the public internet via access to S3 APIs. There’s also Amazon S3 Transfer Acceleration for faster movement over long distances, as well as AWS Direct Connect for a private, consistent connection between S3 and an enterprise’s own data center. An administrator can also use AWS Snowball, a physical transfer device, to ship large amounts of data from an enterprise data center directly to AWS, which will then upload it to S3.
In addition, users can integrate other AWS services with S3. For example, an analyst can query data directly on S3 either with Amazon Athena for ad hoc queries or with Amazon Redshift Spectrum for more complex analyses.
How Amazon S3 Works
Amazon S3 is an object storage service, which differs from other types of storage such as block and file cloud storage. Each object is stored as a file with its metadata included. The object is also given an ID number. Applications use this ID number to access objects. Unlike file and block cloud storage, where a developer can access an object via a REST API.
The S3 cloud storage service gives a subscriber access to the same systems that Amazon uses to run its own websites. S3 enables customers to upload, store and download practically any file or object that is up to five terabytes (TB) in size — with the largest single upload capped at five gigabytes (GB).
Amazon S3 storage classes
Amazon S3 comes in three storage classes: S3 Standard, S3 Infrequent Access and Amazon Glacier. S3 Standard is suitable for frequently accessed data that needs to be delivered with low latency and high throughput. S3 Standard targets applications, dynamic websites, content distribution and big data workloads.
S3 Infrequent Access offers a lower storage price for data that is needed less often, but that must be quickly accessible. This tier can be used for backups, disaster recovery and long-term data storage.
Amazon Glacier is the least expensive storage option in S3, but it is strictly designed for archival storage because it takes longer to access the data. Glacier offers variable retrieval rates that range from minutes to hours.
A user can also implement lifecycle management policies to curate data and move it to the most appropriate tier over time.
Working with buckets
Amazon does not impose a limit on the number of items that a subscriber can store; however, there are Amazon S3 bucket limitations. An Amazon S3 bucket exists within a particular region of the cloud. An AWS customer can use an Amazon S3 API to upload objects to a particular bucket. Customers can configure and manage S3 buckets.
Protecting your data
User data is stored on redundant servers in multiple data centers. S3 uses a simple web-based interface — the Amazon S3 console — and encryption for user authentication.
S3 buckets are kept private by default, but an admin can choose to make them publicly accessible. A user can also encrypt data prior to storage. Rights may be specified for individual users, who will then need approved AWS credentials to download or access a file in S3.
When a user stores data in S3, Amazon tracks the usage for billing purposes, but it does not otherwise access the data unless required to do so by law.
Getting started with Amazon S3
Amazon Simple Storage Service (Amazon S3) is storage for the internet. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere on the web. You can accomplish these tasks using the AWS Management Console, which is a simple and intuitive web interface.
To get the most out of Amazon S3, you need to understand a few simple concepts. Amazon S3 stores data as objects within buckets. An object consists of a file and optionally any metadata that describes that file. To store an object in Amazon S3, you upload the file you want to store to a bucket. When you upload a file, you can set permissions on the object and any metadata.Buckets are the containers for objects. You can have one or more buckets. For each bucket, you can control access to it (who can create, delete, and list objects in the bucket), view access logs for it and its objects, and choose the geographical region where Amazon S3 will store the bucket and its contents.
Set up and log into your AWS account
To use Amazon S3, you need an AWS account » If you don’t already have one, you’ll be prompted to create one when you sign up for Amazon S3. You will not be charged for Amazon S3 until you use it.
Create a bucket
Every object in Amazon S3 is stored in a bucket. Before you can store data in Amazon S3, you must create an S3 bucket
Start building with AWS
Now that you’ve created a bucket, you’re ready to add an object to it. An object can be any kind of file: a text file, a photo, a video, and so on. Read the Getting Started Guide to learn more and start building.
Most customers start developing brand new applications with the AWS developer tools and SDKs. Alternatively, a web-based interface for accessing and managing Amazon S3 resources is available via the AWS Management Console.
Using the AWS SDK
Developers building applications can choose from a wide variety of AWS SDKs that simplify using Amazon S3 in their use case. AWS SDKs for Amazon S3 include libraries, code samples, and documentation for the following programming languages and platforms.
Using the AWS Mobile SDK
The AWS Mobile SDK helps you build high quality mobile apps quickly and easily. It provides access to services specifically designed for building mobile apps,
mobile-optimized connectors to popular AWS data streaming, storage and database services, and access to a full array of other AWS services.
The AWS Mobile SDK includes libraries, code samples, and documentation for iOS, Android, and Fire OS so you can build apps that deliver great experiences across devices and platforms.
AWS offers free online storage courses to help you learn how to architect and manage highly available storage solutions built on Amazon S3. Progress from the fundamentals to technical deep dives to advance your Amazon S3 expertise and help your organization migrate to the cloud faster.
Moving data to Amazon S3
AWS provides a portfolio of data transfer services to provide the right solution for any data migration project. The level of connectivity is a major factor in data migration, and AWS has offerings that can address your hybrid cloud storage, offline data transfer, and online data transfer needs.
Hybrid cloud storage
AWS Storage Gateway is a hybrid cloud storage service that lets you seamlessly connect and extend your on-premises applications to AWS Storage. Customers use Storage Gateway for moving backups to the cloud, using on-premises file shares backed by cloud storage, and providing low latency access to data in AWS for on-premises applications. Using AWS Direct Connect, you can establish private connectivity between AWS and your data center, office, or colocation environment, which can reduce your network costs, increase throughput, and provide a more consistent network experience than public internet connections.

Enroll in Instructor-led Amazon S3 Training Course to UPGRADE Your Skills
Weekday / Weekend BatchesSee Batch DetailsOffline data transfer
The AWS Snow Family is comprised of AWS Snowcone, AWS Snowball, and AWS Snowmobile. AWS Snowcone and AWS Snowball are small, rugged, and secure portable storage and edge computing devices for data collection, processing, and migration. These devices are purpose-built for use in edge locations where network capacity is constrained or nonexistent and provide storage and computing capabilities in harsh environments. AWS Snowmobile is an exabyte-scale data transfer service used to move massive volumes of data to the cloud, including video libraries, image repositories, or even a complete data center migration.
Online data transfer
AWS DataSync makes it easy and efficient to transfer hundreds of terabytes and millions of files into Amazon S3, up to 10x faster than open-source tools. DataSync automatically handles or eliminates many manual tasks, including scripting copy jobs, scheduling and monitoring transfers, validating data, and optimizing network utilization. Using Snowcone, you can even transfer data online with AWS DataSync from edge locations.
The AWS Transfer Family provides fully managed, simple, and seamless file transfer to Amazon S3 using SFTP, FTPS, and FTP.
Amazon S3 Transfer Acceleration enables fast transfers of files over long distances between your client and your Amazon S3 bucket. Amazon Kinesis and AWS IoT Core make it simple and secure to capture and load streaming data from IoT devices to Amazon S3.
AWS Quick Start Guide: Back Up Your Files to Amazon Simple Storage Service
1. Create an Amazon S3 Bucket
This quick start guide uses a new version of the AWS Management Console that is currently in preview release and is subject to change.
First, you need to create an Amazon S3 bucket where you will store your objects.
- 1. Sign in to the preview version of the AWS Management Console.
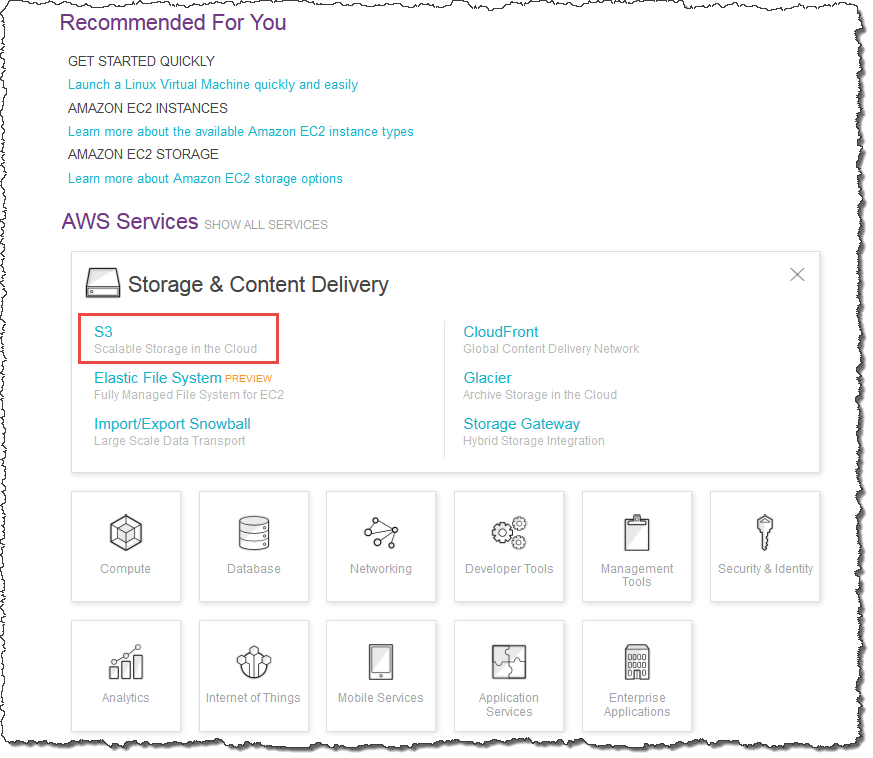
- 2. Under Storage & Content Delivery, choose S3 to open the Amazon S3 console.
If you are using the Show All Services view, your screen looks like this with Storage & Content Delivery expanded: - 3. From the Amazon S3 console dashboard, choose Create Bucket.
- 4. In Create a Bucket, type a bucket name in Bucket Name.
The bucket name you choose must be globally unique across all existing bucket names in Amazon S3 (that is, across all AWS customers). For more information, see Bucket Restrictions and Limitations. - 5. In Region, choose Oregon.
- 6. Choose Create.
When Amazon S3 successfully creates your bucket, the console displays your empty bucket in the Buckets pane
2. Upload a File to Your Amazon S3 Bucket
Now that you’ve created a bucket, you’re ready to add an object to it. An object can be any kind of file: a document, a photo, a video, a music file, or other file type.
- 1. In the Amazon S3 console, choose the bucket where you want to upload an object, choose Upload, and then choose Add Files.
- 2. In the file selection dialog box, find the file that you want to upload, choose it, choose Open, and then choose Start Upload.
You can watch the progress of the upload in the Transfer pane.
3. Retrieve a File from Your Amazon S3 Bucket
Now that you’ve added an object to a bucket, you can open and view it in a browser. You can also download the object to your local computer.
- 1. In the Amazon S3 console, choose your S3 bucket, choose the file that you want to open or download, choose Actions, and then choose Open or Download.
- 2. If you are downloading an object, specify where you want to save it.
The procedure for saving the object depends on the browser and operating system that you are using.
4.Delete a File From Your Amazon S3 Bucket
If you no longer need to store the file you’ve uploaded to your Amazon S3 bucket, you can delete it.
- Within your S3 bucket, select the file that you want to delete, choose Actions, and then choose Delete.
In the confirmation message, choose OK.
Amazon S3 Bucket
Step 1: Create an Amazon S3 Bucket
First, you need to create an Amazon S3 bucket where you will store your objects.
- 1. Sign in to the preview version of the AWS Management Console.
- 2. Under Storage & Content Delivery, choose S3 to open the Amazon S3 console.
If you are using the Show All Services view, your screen looks like this:
If you are using the Show Categories view, your screen looks like this with Storage & Content Delivery expanded:
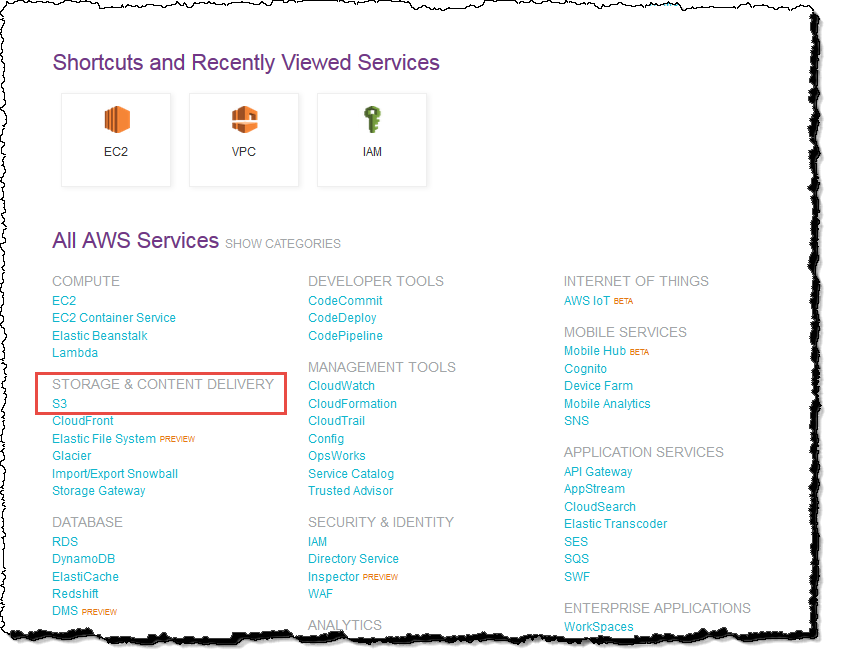
- 3. From the Amazon S3 console dashboard, choose Create Bucket.
- 4. In Create a Bucket, type a bucket name in Bucket Name.
The bucket name you choose must be globally unique across all existing bucket names in Amazon S3 (that is, across all AWS customers). For more information, see Bucket Restrictions and Limitations.
- 5. In Region, choose Oregon.
- 6. Choose Create.
When Amazon S3 successfully creates your bucket, the console displays your empty bucket in the Buckets pane.
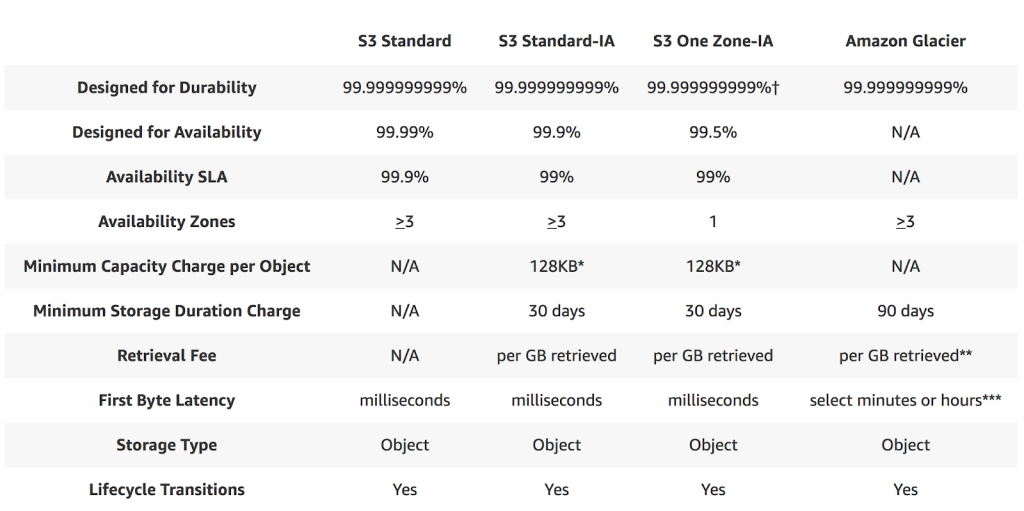
Availability and Durability
When we look for any service to integrate into our application, the major thing we look for is the reliability (and durability) of the service? How frequently the service goes down and what happens to our data if something goes wrong? To keep those things in mind, I am going to list out S3 availability and durability standards first, before we dive into the other features.
- S3 Standard offers 99.99% availability and 99.999999999% durability (Yes, that many 9s)
- S3 IA offers 99.9% availability and 99.99% durability
- S3 One Zoned-IA offers 99.5% availability and 99.999999999% durability, but data will be lost in the event of Availability Zone destruction (data center site failure)
- Glacier offers 99.99% availability and 99.999999999% durability
- S3 RRS is designed to provide 99.99% durability and 99.99% availability
Object Store
Amazon S3 is a simple key, value store designed to store as many objects as you want. You store these objects in one or more buckets. An object consists of the following:
- Key — The name that you assign to an object. You use the object key to retrieve the object.
- Version ID — Within a bucket, a key and version ID uniquely identify an object
- Value — The content that we are storing
- Metadata — A set of name-value pairs with which you can store information regarding the object.
- Subresources — Amazon S3 uses the subresource mechanism to store object-specific additional information.
- Access Control Information — We can control access to the objects in Amazon S3.
Data Bucket
Before we store any data into S3, we first have to create a Bucket. A bucket is similar to how we create a folder on the local system, but with a catch that the bucket name has to be unique across all of the AWS accounts. So for example, if someone has created a S3 bucket, my-backup-files, then no other AWS account can create the S3 bucket with similar name.Inside the bucket, we can have folders or files. There is no limit on how much of data that we can store inside a bucket.Amazon S3 creates buckets in a region we specify. To optimize latency, minimize costs, or address regulatory requirements, we can choose any AWS Region that is geographically close to our requirement. For example, if we reside in Europe, then we should create buckets in the EU (Ireland) or EU (Frankfurt) regions.
By default, you can create up to 100 buckets in each of your AWS accounts. If you need additional buckets, you can increase your bucket limit by submitting a service limit increase.
S3 Bucket is HTTP(s) enabled, so we can access the objects stored inside them with a unique URL. For example, if the object named image/logo.jpg is stored in the appgambit bucket, then it is addressable using the URLhttp://appgambit.s3.amazonaws.com/images/logo.jpg. However, the file is only accessible if it has public-read permission.
Version Control
Versioning allows us to preserve, retrieve, and restore every version of every object stored inside an Amazon S3 bucket. Once you enable Versioning for a bucket, Amazon S3 preserves existing objects anytime you perform a PUT, POST, COPY, or DELETE operation on them.
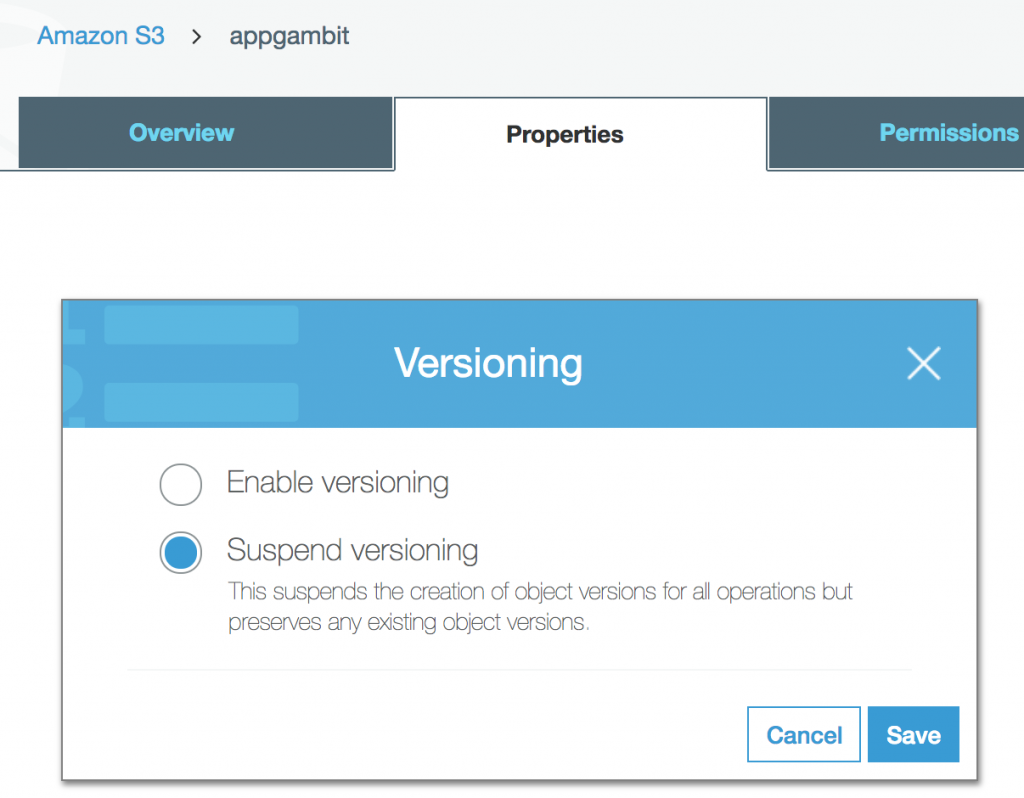
Versioning option for a bucket
By default, GET requests will retrieve the latest written version object. Older versions of an overwritten or deleted object can be retrieved by specifying a version in the request.
Versioning also gives an additional layer of protection to avoid accidental deletion of objects. When a user performs a DELETE operation on an object, subsequent simple (un-versioned) requests will no longer retrieve the object. However, all versions of that object will continue to be preserved in your Amazon S3 bucket and can be retrieved or restored. Only the owner of an Amazon S3 bucket can permanently delete a version.
Once the Versioning is enabled, it can only be suspended but cannot be disabled. S3 considers each version of the object as a separate object for billing, so make sure you are enabling the Versioning for a particular reason.
Static Web Hosting
Static Web Hosting is one of the most powerful features of the AWS S3. Single Page Applications or Pure JavaScript Applications are in trend nowadays and with AWS S3 we can easily deploy an application and start using immediately without setting up any machine anywhere.
This is one of the important building blocks for developing Serverless Web Application.
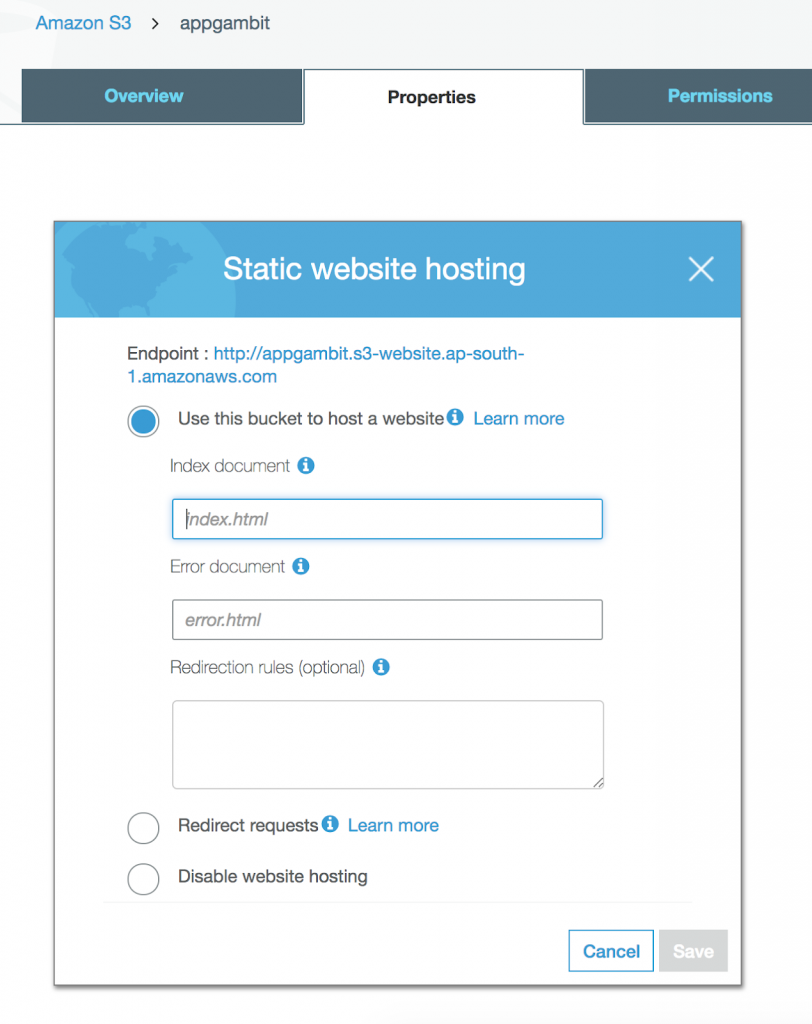
Enable Static Web Hosting for a bucket
Once the Static Web Hosting is enabled, it will generate a URL which we can use to start accessing our application.
Because AWS S3 buckets are placed regionally, by default Web Site will also be serving from the same region. If you are deploying the application for a specific region, then make sure the S3 bucket is created in that region.
If you are deploying the application globally, then you can serve AWS S3 content with AWS CloudFront which works as a CDN to distribute the files on AWS Edge Locations network. This will make sure application is taking minimum latency for loading anywhere in the world.
Backup & Recovery
By default, the AWS S3 provides the same level of durability and availability across all the regions. But then also the things can go wrong, so most organisations when they use Cloud to host their data, would like to have backup and recovery in their plan.
AWS S3 provides a simple mechanism to create a backup for data, Cross Region Replication. Cross-region Replication enables automatic and asynchronous copying of objects across buckets in different AWS regions. This is useful in case we want to fast access our data in different regions or create a general backup of the data.
Cross Region Replication requires Versioning enabled, so this will have an impact on your AWS billing amount as well. The CRR includes Versioning cost as well as the Data Transfer cost.
Security
Amazon takes security very seriously. Being in Cloud and serving to the thousands of organizations using these services means an exceptional level of security is required. AWS provides multiple levels of security, let’s go through them one by one to understand in detail.
Let’s divide the overall security part into two: Data Access Security and Data Storage Security.
Data Access Security
By default when you create a new bucket, only you have access to Amazon S3 resources they create. You can use access control mechanisms such as bucket policies and Access Control Lists (ACLs) to selectively grant permissions to users and groups of users. Customers may use four mechanisms for controlling access to Amazon S3 resources.
Identity and Access Management (IAM) policies
IAM policies are applicable to specific principles like User, Group, and Role. The policy is a JSON document, which mentions what the principle can or can not do.
An example IAM policy will look like this. Any IAM entity (user, role, group) having below policy can access the appgambit-s3access-test bucket and objects inside that.
- {
- “Version”: “2012-10-17”,
- “Statement”:[{
- “Effect”: “Allow”,
- “Action”: “s3:*”,
- “Resource”: [“arn:aws:s3:::appgambit-s3access-test”,
- “arn:aws:s3:::appgambit-s3access-test/*”]
- }
- ]
- }
Bucket policies
Bucket policy uses JSON based access policy language to manage advanced permissions. If you want to make all the objects inside a bucket publicly accessible, then following simple JSON will do that. Bucket policies are only applicable to S3 buckets.
- {
- “Version”: “2012-10-17”,
- “Statement”: [
- {
- “Sid”: “MakeBucketPublic”,
- “Effect”: “Allow”,
- “Principal”: “*”,
- “Action”: “s3:GetObject”,
- “Resource”: “arn:aws:s3:::appgambit-s3access-test/*”
- }
- ]
- }
Bucket policies are very versatile and has lot of configuration options. Let’s say the bucket is service web assets and it should only serve content to request originated from a specific domain.
- {
- “Version”:”2012-10-17″,
- “Id”:”Allow Website Access”,
- “Statement”:[
- {
- “Sid”:”Allow Access to only appgambit.com”,
- “Effect”:”Allow”,
- “Principal”:”*”,
- “Action”:”s3:GetObject”,
- “Resource”:”arn:aws:s3:::appgambit-s3access-test/*”,
- “Condition”:{
- “StringLike”:{
- “aws:Referer”:[
- “https://www.appgambit.com/*”,
- “https://appgambit.com/*”
- ]
- }
- }
- }
- ]
- }
Access Control Lists (ACLs)
ACL is a legacy access policy option to grant basic read/write permissions to other AWS account.
Query String Authentication
Imagine you have private content which you want to share with your authenticated users out of your application, like sending the content link via Email which only that user can access.
AWS S3 allows you to create a specialised URL which contains information to access the object. This method is also known as a Pre-Signed URL.
You can get more detail about generating pre-signed URLs from here.
Uploading from UI
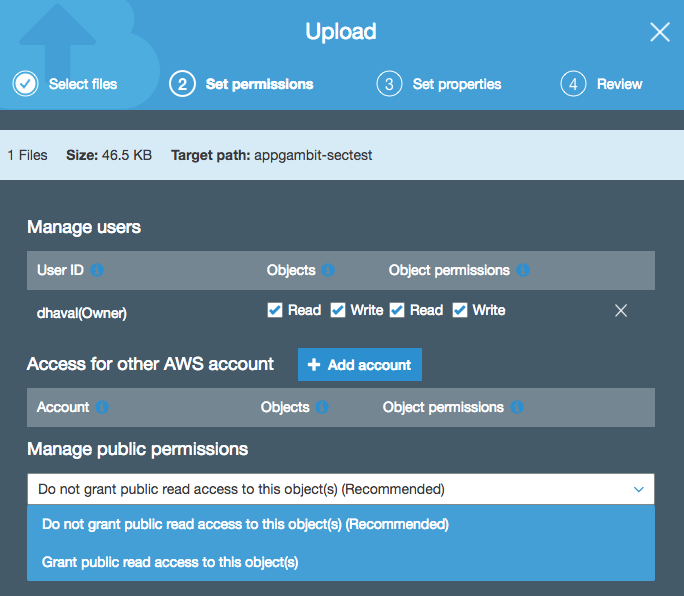
Permissions UI while uploading new object in S3
Each object in the bucket carries their own permission, so if the bucket is set to private, you can still add publicly accessible files inside that bucket.
If you have set the Bucket Policy to make every object publicly accessible, then even the object uploaded with private or no permission, it will still be accessible.
Data Storage Security
Besides Data Access Security, AWS S3 provides Storage level security as well, alternatively known as data-at-rest, while it is stored on disks in Amazon S3 data centers. There are two options for protecting data at rest in AWS S3.
Server-side Encryption
In Server-side encryption, Amazon S3 encrypts your data at the object level as it writes it to disks in its data centers and decrypts it for you when you access it. As long as you authenticate your request and you have access permissions, there is no difference in the way you access encrypted or unencrypted objects.
The entire process is handled by the AWS S3, and the user does not have to do anything with regards to encryption. You can use one of the three available options to encrypt your data.
S3-Managed Keys (SSE-S3)
With S3 managed keys, each object is encrypted with a unique key employing strong multi-factor encryption. As an additional safeguard, it encrypts the key itself with a master key that it regularly rotates. The AES-256 algorithm is used to encrypt all the data.
AWS KMS-Managed Keys (SSE-KMS)
AWS Key Management Service is similar to SSE-S3, but with some additional benefits. It provides centralised access to create and control the encryption keys used to encrypt your data. Most importantly AWS KMS is integrated with AWS CloudTrail to provide encryption key usage logs to help meet your auditing, regulatory and compliance needs.
Here is a comprehensive list of things AWS KMS can manage for you.
Customer-Provided Keys (SSE-C)
With customer provided keys, we can upload our own keys and the S3 will use that for encryption/decryption.
Client-side Encryption
Client-side encryption is the standard way of encrypting data before sending it to Amazon S3. Similar to how we use that in a Non-Cloud environment where we encrypt the data first and then send to storage, and fetch data from storage and then decrypt before we use it.
Events
Most of the AWS services are designed in a way to integrate with other AWS services and create a flow channel. AWS S3 has Events, imagine you want to run a piece of code when a new file is Added, Updated or Removed. It can be easily done using Events.
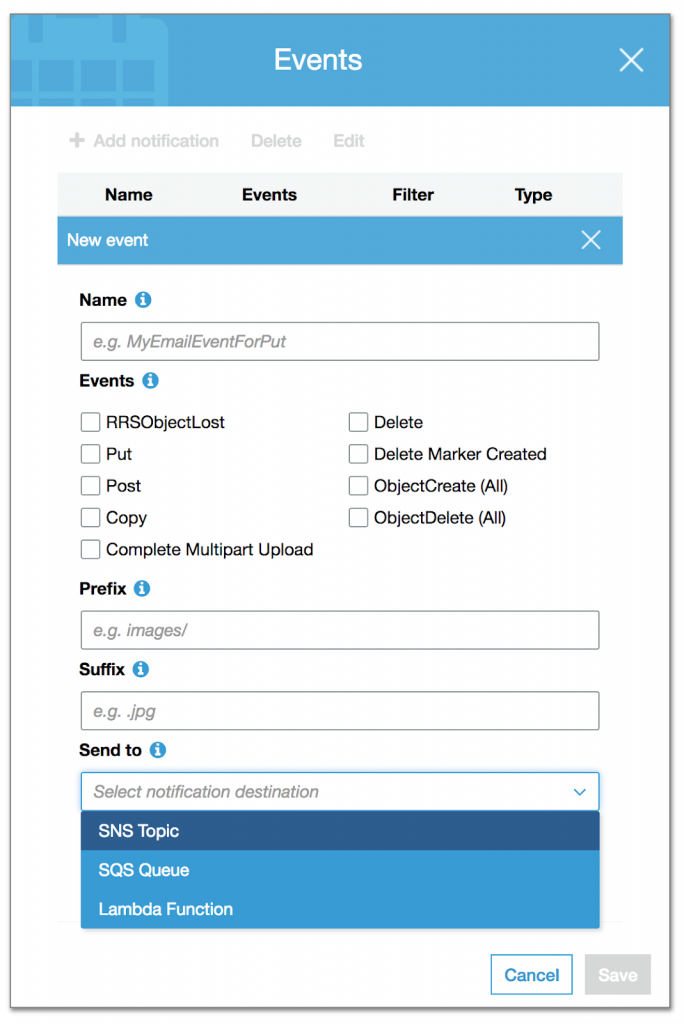
S3 Events Configuration
We can configure things like Events to identify an operation, Prefix/Suffix for object targeting and event target with Send To. As of now, S3 can publish an event to SNS Topic, SQS Queue or invoke a Lambda function.
The common use case for S3 Events is to upload a media file, and does the transformation for different devices like Desktop, Mobile or Tablet to consume or create Thumbnail images.
BitTorrent Support
BitTorrent is an open, peer-to-peer protocol for distributing files. You can use the BitTorrent protocol to retrieve any publicly-accessible object in Amazon S3. Amazon S3 supports the BitTorrent protocol so that developers can save costs when distributing content at high scale.
Every anonymously readable object stored in Amazon S3 is automatically available for download using BitTorrent. To download any file using the BitTorrent protocol, just add ?torrent at the end of the URL request. This either generate the .torrent file for the object or will serve an existing .torrent file.
It is possible to disable the BitTorrent based access by disabling the anonymous access however, we can not prevent the usage of the objects downloaded previously using BitTorrent as they can be served from a peer-to-peer network without the need of the AWS S3.
Pricing
AWS S3 like the other AWS services offers the pay-per-use model. The pricing slightly differs from a region to another region and storage class.
Here is a sample calculation for 1TB of storage with 100K Read and 100K write requests. As you can see on the top right, the usage will cost you around $23.40 / per month.
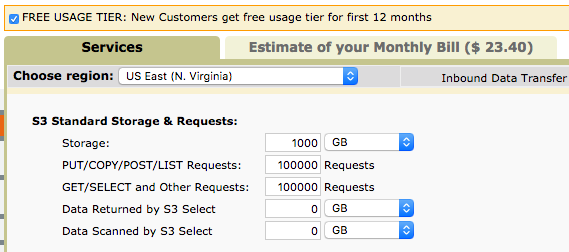
Sample Usage Calculation
You can use the AWS cost calculator from here.
Conclusion
Hence, we studied AWS Marketplace provides pr-build software and deploys it to AWS cloud. This results in the fact that AWS customers can easily use S3 to back up and restore their data. In addition, they can archive the data, backup and restore, and disaster recovery.