
- Must-Know [LATEST] Apache NiFi Interview Questions and Answers
- [SCENARIO-BASED ] Mahout Interview Questions and Answers
- 40+ [REAL-TIME] Apache Ambari Interview Questions and Answers
- [50+] Big Data Greenplum DBA Interview Questions and Answers
- 40+ [REAL-TIME] Informatica Analyst Interview Questions and Answers
- Must-Know [LATEST] FileNet Interview Questions and Answers
- 20+ Must-Know SAS Grid Administration Interview Questions
- [SCENARIO-BASED ] Apache Flume Interview Questions and Answers
- Top Storm Interview Questions and Answers [ TO GET HIRED ]
- Cassandra Interview Questions and Answers
- Sqoop Interview Questions and Answers
- kafka Interview Questions and Answers
- Hive Interview Questions and Answers
- Big Data Hadoop Interview Questions and Answers
- Elasticsearch Interview Questions and Answers
- HDFS Interview Questions and Answers
- HBase Interview Questions and Answers
- MapReduce Interview Questions and Answers
- Pyspark Interview Questions and Answers
- Hadoop Interview Questions and Answers
- Apache Spark Interview Questions and Answers
- Must-Know [LATEST] Apache NiFi Interview Questions and Answers
- [SCENARIO-BASED ] Mahout Interview Questions and Answers
- 40+ [REAL-TIME] Apache Ambari Interview Questions and Answers
- [50+] Big Data Greenplum DBA Interview Questions and Answers
- 40+ [REAL-TIME] Informatica Analyst Interview Questions and Answers
- Must-Know [LATEST] FileNet Interview Questions and Answers
- 20+ Must-Know SAS Grid Administration Interview Questions
- [SCENARIO-BASED ] Apache Flume Interview Questions and Answers
- Top Storm Interview Questions and Answers [ TO GET HIRED ]
- Cassandra Interview Questions and Answers
- Sqoop Interview Questions and Answers
- kafka Interview Questions and Answers
- Hive Interview Questions and Answers
- Big Data Hadoop Interview Questions and Answers
- Elasticsearch Interview Questions and Answers
- HDFS Interview Questions and Answers
- HBase Interview Questions and Answers
- MapReduce Interview Questions and Answers
- Pyspark Interview Questions and Answers
- Hadoop Interview Questions and Answers
- Apache Spark Interview Questions and Answers

Elasticsearch Interview Questions and Answers
Last updated on 05th Oct 2020, Big Data, Blog, Interview Question
If you are preparing for an interview, here are the 51 most frequently asked Elasticsearch interview questions and answers for your reference.
We have tried to bring together all the possible questions you may likely encounter during your technical interview to check your competency on Elasticsearch.
Elasticsearch is an open-source, RESTful, scalable, built on Apache Lucene library, document-based search engine. It stores retrieve and manage textual, numerical, geospatial, structured and unstructured data in the form of JSON documents using CRUD REST API or ingestion tools such as Logstash.
You can use Kibana, an open-source visualization tool, with Elasticsearch to visualize your data and build interactive dashboards for Analysis.
Elasticsearch, Apache Lucene search engine is a JSON document, which is indexed for faster searching. Due to indexing, user can search text from JSON documents within 10 seconds.
1.Explain in brief about Elasticsearch?
Ans:
Elasticsearch Apache Lucene search engine is a database that stores, retrieves and manages document-oriented and semi-structured data. It provides real-time search and analytics for structured or unstructured text, numerical or geospatial data.
2.Can you state the stable Elasticsearch version currently available for download?
Ans:
The latest stable version of Elasticsearch is 7.5.0.
3.To install Elasticsearch, what software is required as a prerequisite?
Ans:
Latest JDK 8 or Java version 1.8.0 is recommended as the software required for running Elasticsearch on your device.
4.Can you please give step by step procedures to start an Elasticsearch server?
Ans:
The server can be started from the command line.
Following steps explain the process:
- Click on the Windows Start icon present at the bottom-left part of the desktop screen.
- Type command or cmd in the Windows Start menu and press Enter to open a command prompt.
- Change the directory up to the bin folder of the Elasticsearch folder that got created after it has been installed.
- Type /Elasticsearch.bat and press Enter to start the Elasticsearch server.
This will start Elasticsearch on the command prompt in the background. Further open browser and enter http://localhost:9200 and press enter. This should display the Elasticsearch cluster name and other meta values related to its database.
5.Name 10 companies that have an Elasticsearch as their search engine and database for their application?
Ans:
Following are the list of some companies that use Elasticsearch along with Logstash and Kibana:
- Uber
- Instacart
- Slack
- Shopify
- Stack Overflow
- DigitalOcean
- Udemy
- 9GAG
- Wikipedia
- Netflix
- Accenture
- Fujitsu
6.Please explain Elasticsearch Cluster?
Ans:
It is a group of one or more node instances connected responsible for the distribution of tasks, searching and indexing across all the nodes.
7.What is a Node in Elasticsearch?
Ans:
A node is an instance of Elasticsearch. Different node types are Data nodes, Master nodes, Client nodes and Ingest nodes.
These are explained as follows:
- Data nodes hold data and perform an operation such as CRUD (Create/Read/Update/Delete., search and aggregations on data)
- Master nodes help in configuration and management to add and remove nodes across the cluster.
- Client nodes send cluster requests to the master node and data-related requests to data nodes,
- Ingest nodes for pre-processing documents before indexing.
8.What is an index in an Elasticsearch cluster?
Ans:
An Elasticsearch cluster can contain multiple indices, which are databases as compared with a relational database, these indices contain multiple types (tables). The types (tables. contain multiple Documents (records/rows) and these documents contain Properties (columns).
9.What is a Type in an Elastic search?
Ans:
Type, here is a table in the relational database. These types (tables) hold multiple Documents (rows), and each document has Properties (columns).

10.Can you please define Mapping in an Elasticsearch?
Ans:
Mapping is the outline of the documents stored in an index. The mapping defines how a document is indexed, how its fields are indexed and stored by Lucene.
Subscribe For Free Demo
Error: Contact form not found.
11.What is a Document with respect to Elasticsearch?
Ans:
A document is a JSON document that is stored in Elasticsearch. It is equivalent to a row in a relational database table.
12.Can you explain SHARDS with regards to Elasticsearch?
Ans:
When the number of documents increases, hard disk capacity, and processing power will not be sufficient, responding to client requests will be delayed. In such a case, the process of dividing indexed data into small chunks is called Shards, which improves the fetching of results during data search.
13.Can you define REPLICA and what is the advantage of creating a replica?
Ans:
A replica is an exact copy of the Shard, used to increase query throughput or achieve high availability during extreme load conditions. These replicas help to efficiently manage requests.
14.Please explain the procedure to add or create an index in Elasticsearch Cluster?
Ans:
To add a new index, create an index API option should be used. The parameters required to create the index is Configuration setting of an index, Fields mapping in the index as well as Index aliases
15.What is the syntax or code to delete an index in Elasticsearch?
Ans:
You can delete an existing index using the following syntax:
- DELETE /<index_name>
- _all or * can be used to remove/delete all the indices
16.What is the syntax or code to list all indexes of a Cluster in Elasticsearch?
Ans:
You can get the list of indices present in the cluster using the following syntax:
- GET /_<index_name>
- GET index_name , in above case, index_name is .kibana
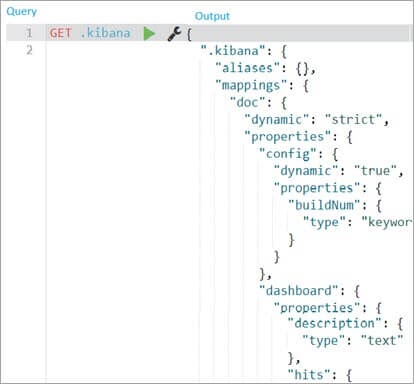
17.Can you tell me the syntax or code to add a Mapping in an Index?
Ans:
You can add a mapping in an index using the following syntax:
POST /_<index_name>/_type/_id
18.What is the syntax or code to retrieve a document by ID in Elasticsearch?
Ans:
GET API retrieves the specified JSON document from an index.
Syntax:
GET <index_name>/_doc/<_id>
19.Please explain relevancy and scoring in Elasticsearch?
Ans:
When you search on the internet about, say, Apple. It could either display the search results about fruit or a company with a name like Apple. You may want to buy fruit online, check the recipe from the fruit or health benefits of eating fruit, apple.
In contrast, you may want to check Apple.com to find the latest product range offered by the company, check Apple Inc.’s stock prices and how a company is performing in NASDAQ in the last 6 months, 1 or 5 years.
Similarly, when we search for a document (a record) from Elasticsearch, you are interested in getting the relevant information that you are looking for. Based on the relevance, the probability of getting the relevant information is calculated by the Lucene scoring algorithm.
The Lucene technology helps to search a particular record i.e. document which is indexed based on the frequency of the term in search appearing in the document, how often its appearance across an index and query which is designed using various parameters.
20.What are the various possible ways in which we can perform a search in Elasticsearch?
Ans:
Mentioned below are the various possible ways in which we can perform a search in Elasticsearch:
- Applying search API across multiple types and multiple indexes: Search API, we can search an entity across multiple types and indices.
- Search request using a Uniform Resource Identifier: We can search requests using parameters along with URI i.e. Uniform Resource Identifier.
- Search using Query DSL i.e. (Domain Specific Language) within the body: DSL i.e. Domain Specific Language is utilized for JSON request bodies.
21.What are the various types of queries that Elasticsearch supports?
Ans:
Queries are mainly divided into two types: Full Text or Match Queries and Term based Queries.
Text Queries such as basic match, match phrase, multi-match, match phrase prefix, common terms, query-string, simple query string.
Term Queries such as term exists, type, term set, range, prefix, ids, wildcard, regex and fuzzy.
22. Can you compare between Term-based queries and Full-text queries?
Ans:
Domain Specific Language (DSL) Elasticsearch query which is known as Full-text queries utilizes the HTTP request body, offers the advantage of clear and detailed in their intent, over time it is simpler to tune these queries.
Term based queries utilize the inverted index, a hash map-like data structure that helps to locate text or string from the body of email, keyword or numbers or dates, etc. used for analysis purposes.
23. Please explain the working of aggregation in Elasticsearch?
Ans:
Aggregations help in the collection of data from the query used in the search. Different types of aggregations are Metrics, Average, Minimum, Maximum, Sum and stats, based on different purposes.
24. Can you tell me data storage functionality in Elasticsearch?
Ans:
Elasticsearch is a search engine used as storage and searching complex data structures indexed and serialized as a JSON document.
25. What is an Elasticsearch Analyzer?
Ans:
Analyzers are used for Text analysis, it can be either built-in analyzer or custom analyzer. The analyzer consists of zero or more Character filters, at least one Tokenizer and zero or more Token filters.
- Character filters break down the stream of string or numerical into characters by stripping out HTML tags, searching the string for key and replacing them with the related value defined in the mapping char filter as well as replacing the characters based on a specific pattern.
- Tokenizer breaks the stream of string into characters, For example, whitespace tokenizer breaks the stream of string while encountering whitespace between characters.
- Token filters convert these tokens into lower case, remove from string stop words like ‘a’, ‘an’, ‘the’. or replace characters into equivalent synonyms defined by the filter.

Enroll in Best Elasticsearch Training and Get Hired by TOP MNCs
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
26. Can you list various types of analyzers in Elasticsearch?
Ans:
Types of Elasticsearch Analyzer are Built-in and Custom.
Built-in analyzers are further classified as below:
- Standard Analyzer: This type of analyzer is designed with standard tokenizer which breaks the stream of string into tokens based on maximum token length configured, lowercase token filter which converts the token into lower case and stops token filter, which removes stop words such as ‘a’, ‘an’, ‘the’.
- Simple Analyzer: This type of analyzer breaks a stream of string into a token of text whenever it comes across numbers or special characters. A simple analyzer converts all the text tokens into lower case characters.
- Whitespace Analyzer: This type of analyzer breaks the stream of string into a token of text when it comes across white space between these strings or statements. It retains the case of tokens as it was in the input stream.
- Stop Analyzer: This type of analyzer is similar to that of the simple analyzer, but in addition to it removes stop words from the stream of string such as ‘a’, ‘an’, ‘the’. The complete list of stop words in English can be found from the link.
- Keyword Analyzer: This type of analyzer returns the entire stream of string as a single token as it was. This type of analyzer can be converted into a custom analyzer by adding filters to it.
- Pattern Analyzer: This type of analyzer breaks the stream of string into tokens based on the regular expression defined. This regular expression acts on the stream of string and not on the tokens.
- Language Analyzer: This type of analyzer is used for specific language texts analysis. There are plug-ins to support language analyzers. These plug-ins are Stempel, Ukrainian Analysis, Kuromoji for Japanese, Nori for Korean and Phonetic plugins. There are additional plug-ins for Indian as well as non-Indian languages such as Asian languages ( Example, Japanese, Vietnamese, Tibetan. analyzers)
- Fingerprint Analyzer: The fingerprint analyzer converts the stream of string into lower case, removes extended characters, sorts and concatenates into a single token.
27. How can Elasticsearch Tokenizer be used?
Ans:
Tokenizers accept a stream of string, break them into individual tokens and display output as collection/array of these tokens. Tokenizers are mainly grouped into word-oriented, partial word, and structured text tokenizers.
28. How do Filters work in an Elasticsearch?
Ans:
Token filters receive text tokens from tokenizer and can manipulate them to compare the tokens for search conditions. These filters compare tokens with the searched stream, resulting in Boolean value, like true or false.
The comparison can be whether the value for searched condition matches with filtered token texts, OR does not match, OR matches with one of the filtered token text returned OR does not match any of the specified tokens, OR value of the token text is within given range OR is not within a given range, OR the token texts exist in search condition or does not exist in the search condition.
29. How does an ingest node in Elasticsearch function?
Ans:
Ingest node processes the documents before indexing, which takes place with the help of a series of processors which sequentially modifies the document by removing one or more fields followed by another processor that renames the field value. This helps normalize the document and accelerates the indexing, resulting in faster search results.
30. Differentiate between Master node and Master eligible node in Elasticsearch?
Ans:
Master node functionality revolves around actions across the cluster such as the creation of index/indices, deletion of index/indices, monitoring or keeping an account of those nodes that form a cluster. These nodes also decide shards allocation to specific nodes resulting in stable Elasticsearch cluster health.
Whereas, Master – eligible nodes are those nodes that get elected to become Master Node.
31. What are the functionalities of attributes such as enabled, indexed and stored in Elasticsearch?
Ans:
Enabled attribute of Elasticsearch is applied in the case where we need to retain and store a particular field from indexing. This is done by using “enabled”: false syntax into the top-level mapping as well as to object fields.
Index attribute of Elasticsearch will decide three ways in which a stream of string can be indexed.
- ‘analyzed’ in which string will be analyzed before it is subjected to indexing as a full-text field.
- ‘not_analyzed’ indexes the stream of string to make it searchable, without analyzing it.
- ‘no’ – where the string will not be indexed at all, and will not be searchable as well.
Irrespective of setting the attribute ‘store’ to false, Elasticsearch stores the original document on the disk, which searches as quickly as possible.
32. How is a character filter in Elasticsearch Analyzer utilized?
Ans:
Character filter in Elasticsearch analyzer is not mandatory. These filters manipulate the input stream of the string by replacing the token of text with corresponding value mapped to the key.
We can use mapping character filters that use parameters as mappings and mappings_path. The mappings are the files that contain an array of key and corresponding values listed, whereas mappings_path is the path that is registered in the config directory that shows the mappings file present.
33. Please explain about NRT with regards to Elasticsearch?
Ans:
Elasticsearch is the quickest possible search platform, where the latency (delay. is just one second from the time you index the document and the time it becomes searchable, hence Elasticsearch is a Near Real-Time (NRT. search platform.
34. What are the advantages of REST API with regards to Elasticsearch?
Ans:
REST API is communication between systems using hypertext transfer protocol which transfers data requests in XML and JSON format.
The REST protocol is stateless and is separated from the user interface with server and storage data, resulting in enhanced portability of user interface with any type of platform. It also improves scalability allowing to independently implement the components and hence applications become more flexible to work with.
REST API is platform and language independent except that the language used for data exchange will be XML or JSON.
35. While installing Elasticsearch, please explain different packages and their importance?
Ans:
Elasticsearch installation includes the following packages:
- Linux and macOS platform needs tar.gz archives to be installed.
- Windows operating system requires .zip archives to be installed.
- Debian, Ubuntu-based systems deb pack needs to be installed.
- Red Hat, Centos, OpenSuSE, SLES need rpm packages to be installed.
- Windows 64 bits system requires the MSI package to be installed.
- Docker images for running Elasticsearch as Docker containers can be downloaded from Elastic Docker Registry.
- X-Pack API packages are installed along with Elasticsearch that helps to get information on the license, security, migration, and machine learning activities that are involved in Elasticsearch.
36. What are configuration management tools that are supported by Elasticsearch?
Ans:
Ansible, Chef, Puppet and Salt Stack are configuration tools supported by Elasticsearch used by the DevOps team.
37. Can you please explain the functionality and importance of the installation of X-Pack for Elasticsearch?
Ans:
X-Pack is an extension that gets installed along with Elasticsearch. Various functionalities of X-Pack are security (Role-based access, Privileges/Permissions, Roles and User security), monitoring, reporting, alerting and many more.
38. What is Master Node and Master Eligible Node in Elasticsearch?
Ans:
Master Node controls cluster wide operations like creating or deleting an index, tracking which nodes are part of the cluster, and deciding which shards to allocate to which nodes. It is important for cluster health to have a stable master node. Master Node elected based on configuration properties node.master=true (Default).
Master Eligible Node decide based on below configuration
- discovery.zen.minimum_master_node : number (default 1)
- and above number decide based (master_eligible_nodes / 2) + 1
39. What is a Data Node in Elasticsearch?
Ans:
Data nodes hold the shards/replicas that contain the documents that were indexed. Data Nodes perform data related operations such as CRUD, search aggregation etc. Set node.data=true (Default) to make the node as a Data Node.
Data Node operations are I/O-, memory-, and CPU-intensive. It is important to monitor these resources and to add more data nodes if they are overloaded.The main benefit of having dedicated data nodes is the separation of the master and data roles.
40. What is Ingest Node in Elasticsearch?
Ans:
Ingest nodes can execute pre-processing an ingest pipeline to a document in order to transform and enrich the document before indexing. With a heavy ingest load, it makes sense to use dedicated ingest nodes and to mark the master and data nodes as false and node.ingest=true.
41. What is Tribe Node and Coordinating Node in Elasticsearch?
Ans:
Tribe node, is a special type of node that coordinates to connect to multiple clusters and perform search and other operations across all connected clusters. Tribe Node configured by settings tribe.*.
Coordinating Nodes behave like Smart Load balancers which are able to handle master duties, to hold data, and pre-process documents, then you are left with a coordinating node that can only route requests, handle the search reduce phase, and distribute bulk indexing.
Every node is implicitly a coordinating node. This means that a node that has all three node.master, node.data and node.ingest set to false will only act as a coordinating node, which cannot be disabled. As a result, such a node needs to have enough memory and CPU in order to deal with the gather phase.
42. What are the Benefits of Shards and Replica in Elasticsearch?
Ans:
- Shards split indexes in horizontal partitions for high volumes of data.
- It performs operations parallel to each shard or replica on multiple nodes for index so that increases system performance and throughput.
- Recover easily in case of fail-over of a node because data replicas exist on another node because replicas always store on different nodes where shards exist.
43. What is Document in Elasticsearch?
Ans:
sEach Record store in index is called a document which stores in a JSON object. Document is Similar to row in terms of RDBMS only difference is that each document will have a different number of fields and structure but common fields should have the same data type.
44. What is a Type in Elasticsearch ?
Ans:
Type is logical category/grouping/partition of index whose semantics is completely up to the user and type will always have the same number of columns for each document.
ElasticSearch => Indices => Types => Documents with Fields/Properties
45. What is a Document Type in Elasticsearch?
Ans:
A document type can be seen as the document schema / mapping definition, which has the mapping of all the fields in the document along with its data types.
46.What is indexing in ElasticSearch ?
Ans:
The process of storing data in an index is called indexing in ElasticSearch. Data in ElasticSearch can be divided into write-once and read-many segments. Whenever an update/modification is attempted, a new version of the document is written to the index.
47. What is the inverted index in Elasticsearch ?
Ans:
Inverted Index is the backbone of Elasticsearch which makes full-text search fast. Inverted index consists of a list of all unique words that occur in documents and for each word, maintain a list of document numbers and positions in which it appears.
For Example : There are two documents and having content as :
- 1: FacingIssuesOnIT is for ELK.
- 2: If ELK checks FacingIssuesOnIT.
To make an inverted index each document will split in words (also called as terms or token) and create the below sorted index .
| Term | Doc_1 | Doc_2 |
|---|---|---|
| FacingIssuesOnIT | | X | | X |
| is | | X | | |
| for | | X | | |
| ELK | | X | | X |
| If | | | | X |
| check | | | | X |
Now when we do some full-text search for String will sort documents based on existence and occurrence of matching counts .
Usually in Books we have inverted indexes on the last pages. Based on the word we can thus find the page on which the word exists.
48.What is an Analyzer in ElasticSearch ?
Ans:
While indexing data in ElasticSearch, data is transformed internally by the Analyzer defined for the index, and then indexed. An analyzer is a building block of character filters, tokenizers and token filters. Following types of Built-in Analyzers are available in Elasticsearch 5.6.
| Analyzer | Description |
|---|---|
| Standard Analyzer | Divides text into terms on word boundaries, as defined by the Unicode Text Segmentation algorithm. It removes most punctuation, lower cases terms, and supports removing stop words. |
| Simple Analyzer | Divides text into terms whenever it encounters a character which is not a letter. It lower cases all terms. |
| White space Analyzer | Divides text into terms whenever it encounters any white space character. It does not lowercase terms. |
| Stop Analyzer | It is like the simple analyzer, but also supports removal of stop words. |
| Keyword Analyzer | A “noop” analyzer that accepts whatever text it is given and outputs the exact same text as a single term. |
| Pattern Analyzer | Uses a regular expression to split the text into terms. It supports lower-casing and stop words. |
| Language Analyzer | Elasticsearch provides many language-specific analyzers like English or French. |
| Fingerprint Analyzer | A specialist analyzer which creates a fingerprint which can be used for duplicate detection. |
49.What is a Tokenizer in ElasticSearch ?
Ans:
A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens. Inverted indexes are created and updated using these token values by recording the order or position of each term and the start and end character offsets of the original word which the term represents.
An analyzer must have exactly one Tokenizer.
50.What is Character Filter in Elasticsearch Analyzer?
Ans:
A character filter receives the original text as a stream of characters and can transform the stream by adding, removing, or changing characters. For instance, a character filter could be used to convert Hindu-Arabic numerals (٠١٢٣٤٥٦٧٨٩) into their Arabic-Latin equivalents (0123456789), or to strip HTML elements like from the stream.
An analyzer may have zero or more character filters, which are applied in order.
Enroll in Best Elasticsearch Training and Get Hired by TOP MNCs
- Instructor-led Sessions
- Real-life Case Studies
- Assignments

Get Experts Curated Elasticsearch Certification Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details51.What are Token filters in Elasticsearch Analyzer?
Ans:
A token filter receives the token stream and may add, remove, or change tokens. For example, a lowercase token filter converts all tokens to lowercase, a stop token filter removes common words (stop words) like the from the token stream, and a synonym token filter introduces synonyms into the token stream.
Token filters are not allowed to change the position or character offsets of each token.
An analyzer may have zero or more token filters, which are applied in order.
52.How to check Elasticsearch Cluster Health?
Ans:
To know about cluster health follow below URL over curl or on your browser.
GET /_cat/health?v
53.What is the type of Cluster Health Status?
Ans:
- Green means everything is good (cluster is fully functional).
- Yellow means all data is available but some replicas are not yet allocated (cluster is fully functional)
- Red means some data is not available for whatever reason.
- Note: that even if a cluster is red, it still is partially functional (i.e. it will continue to serve search requests from the available shards) but you will likely need to fix it ASAP since you have missing data
54.How to know Number of Nodes?
Ans:
GET /_cat/nodes?v
Response:
- GET /_cat/nodes?v
Response:
| ip | heap.percent | ram.percent cpu | load_1m | load_5m | load_15m | node.role | master name |
|---|---|---|---|---|---|---|---|
| 127.0.0.1 | 10 | 5 | 5 | 4.46 | mdi | * | PB2SGZY |
Here, we can see our one node named “PB2SGZY”, which is the single node that is currently in our cluster.
55. How to get a list of available Indices in Elasticsearch Cluster?
Ans:
GET /_cat/indices?v
56.How to create Indexes?
Ans:
- PUT /customer?
- prettyGET /_cat/indices?
57.How to delete Index and records?
Ans:
- DELETE /customer?
- pretty GET /_cat/indices?v
and
- PUT /customer
- PUT /customer/external/1
- {
- “name”: “John Doe”
- }
- GET /customer/external/1
- DELETE /customer
If we study the above commands carefully, we can actually see a pattern of how we access data in Elasticsearch. That pattern can be summarized as follows:
<REST Verb> //<Type>/<ID>
This REST access pattern is so pervasive throughout all the API commands that if you can simply remember it, you will have a good head start at mastering Elasticsearch.
58.How to update record and document field values in Index?
Ans:
We’ve previously seen how we can index a single document. Let’s recall that command again:
- PUT /customer/external/1?pretty
- {
- “name”: “John Doe”
- }
Again, the above will index the specified document into the customer index, external type, with the ID of 1. If we then executed the above command again with a different (or same) document, Elasticsearch will replace (i.e. reindex) a new document on top of the existing one with the ID of 1:
<ul class=”rich-text block-editor-rich-text__editable” contenteditable=”true”>
<li>PUT /customer/external/2?pretty</li>
<li>{</li>
<li> “name”: “John Doe”</li>
<li>}</li>
</ul>
The above changes the name of the document with the ID of 1 from “John Doe” to “Jane Doe”. If, on the other hand, we use a different ID, a new document will be indexed and the existing document(s) already in the index remains untouched.
- PUT /customer/external/2?pretty
- {
- “name”: “John Doe”
- }
The above indexes a new document with an ID of 2.
When indexing, the ID part is optional. If not specified, Elasticsearch will generate a random ID and then use it to index the document. The actual ID Elasticsearch generates (or whatever we specified explicitly in the previous examples) is returned as part of the index API call.
This example shows how to index a document without an explicit ID:
- POST /customer/external?pretty
- {
- “name”: “John Doe”
- }
Note that in the above case, we are using the POST verb instead of PUT since we didn’t specify an ID.
59.What is elasticsearch search API?
Ans:
In Elasticsearch search APIs are used to search the content. Either a user can search by sending a get request with a query string as a parameter or a query in the message body of the post request. Mainly all the search APIs are multi-index, multi-type.
60.What is multi-index in Elasticsearch?
Ans:
Elasticsearch allows searching for the documents present in all the indices or in some specific indices.
61.What is multi-type in Elasticsearch?
Ans:
Multi-type means that we can search all the documents in an index across all types or in some specified type.
62. What is aggregations in Elasticsearch?
Ans:
It is a framework that collects all the data which is selected by search query. It consists of many building blocks which help in building complex data.
Basic syntax or structure of aggregation is:
- “aggregations” : {
- “<aggregation_name>” : {
- “<aggregation_type>” : {
- <aggregation_body>
- }
- [,”meta” : { [<meta_data_body>] } ]?
- [,”aggregations” : { [<sub_aggregation>]+ } ]?
- }
- }
63. What are the different types of aggregations?
Ans:
Following are the different types of aggregations:s
- Metrics Aggregations
- Bucket Aggregations
64.What are the different metrics aggregations?
Ans:
Metrics aggregations help in computing matrices either from field value or from scripts. Following are the different types of metrics aggregations:
- Avg Aggregation
- Cardinality Aggregation
- Extended Stats Aggregation
- Max Aggregation
- Min Aggregation
- Sum Aggregation
65. What is Avg Aggregation?
Ans:
Avg Aggregation – It is used to get the average of numeric fields. Example:
Request:- {
- “aggs”:{
- “avg_fees”:{“avg”:{“field”:”fees”}}
- }
- }
Response:
- {
- “took”:44, “timed_out”:false, “_shards”:{“total”:5, “successful”:5, “failed”:0},
- “hits”:{
- “total”:3, “max_score”:1.0, “hits”:[
- {
- “_index”:”schools”, “_type”:”school”, “_id”:”2″, “_score”:1.0,
- “_source”:{
- “name”:”SPaul School”, “description”:”ICSES Affiliation”,
- “street”:”Dwarka”, “city”:”Delhi”, “state”:”Delhi”,
- “zip”:”110075″, “location”:[18.5733056, 57.0122136], “fees”:5000,
- “tags”:[“Good Faculty”, “Great Sports”], “rating”:”4.5″
- }
- },
- {
- “_index”:”schools”, “_type”:”school”, “_id”:”1″, “_score”:1.0,
- “_source”:{
- “name”:”Central School”, “description”:”CBSE Affiliation”,
- “street”:”Sagan”, “city”:”papola”, “state”:”HP”, “zip”:”165715″,
- “location”:[31.8955385, 76.8380405], “fees”:2200,
- “tags”:[“Senior Secondary”, “beautiful campus”], “rating”:”3.3″
- }
- },
- {
- “_index”:”schools”, “_type”:”school”, “_id”:”1″, “_score”:1.0,
- “_source”:{
- “name”:”Central High School”, “description”:”CBSE Affiliation”,
- “street”:”Gagan”, “city”:”papola”, “state”:”HP”, “zip”:”868815″,
- “location”:[41.8955385, 79.8380405], “fees”:2200,
- “tags”:[“Senior Secondary”, “Great infrastructure”], “rating”:”3.9″
- }
- },
- {
- “_index”:”schools”, “_type”:”school”, “_id”:”3″, “_score”:1.0,
- “_source”:{
- “name”:”Crescent School”, “description”:”State Board Affiliation”,
- “street”:”Tonk Road”, “city”:”Jaipur”, “state”:”RJ”,
- “zip”:”176114″, “location”:[25.8535922, 35.8923988], “fees”:2500,
- “tags”:[“Labs”], “rating”:”4.5″
- }
- }
- ]
- }, “aggregations”:{“avg_fees”:{“value”:1133.3333333333335}}
- }
66. What is Cardinality Aggregation?
Ans:
Cardinality Aggregation – It gives count of distinct values. Example:
Request header:
- {
- “aggs”:{
- “distinct_name_count”:{“cardinality”:{“field”:”name”}}
- }
- }
67. What is Extended stats Aggregation?
Ans:
Extended stats Aggregation – It generates the statistics about a specific numerical field. Example:
Request header:
- {
- “aggs” : {
- “fees_stats” : { “extended_stats” : { “field” : “fees” } }
- }
- }
68. What is Max Aggregation?
Ans:
Max Aggregation – It gives the max value. Example:
Request header:
- {
- “aggs” : {
- “max_fees” : { “max” : { “field” : “fees” } }
- }
- }
69. What is Min Aggregation?
Ans:
Min Aggregation – It gives the min value. Example:
Request header:
- {
- “aggs” : {
- “min_fees” : { “min” : { “field” : “fees” } }
- }
- }
70. What is Sum Aggregation?
Ans:
Sum Aggregation – It gives the sum value. Example:
Request header:
- {
- “aggs” : {
- “total_fees” : { “sum” : { “field” : “fees” } }
- }
- }
71. What is the term dictionary in Elasticsearch ?
Ans:
Term dictionary gives information that in which document this term is used
72. What is the term frequency in Elasticsearch ?
Ans:
Term frequency tells number of appearances of a term in a document.If frequency is more than document is more relevant.
73. What is horizontal scaling in Elasticsearch ?
Ans:
Adding more nodes in the same cluster is called horizontal scaling because requests are distributed.
74. What is vertical scaling in Elasticsearch ?
Ans:
Adding more resources to a node for example RAM or processor.That always increases performance.
75. How indexing and searching does work in Elasticsearch ?
Ans:
To understand indexing and searching in Elasticsearch, follow link
76. How can documents be indexed in Elasticsearch using cURL?
Ans:
To understand indexing of document in Elasticsearch, follow link
77. How can documents be searched in Elasticsearch using cURL?
Ans:
To understand searching of document in Elasticsearch, follow link
78. What is the significance of the field in Elasticsearch search query results as shown in the above image ?
Ans:
It tells how much time Elasticsearch needed to process the request.
79. What is the significance of the total field in Elasticsearch search query results as shown in the above image ?
Ans:
It tells how many documents match in Elasticsearch. By default Elasticsearch shows 10 matching documents but by total we can know how many documents match the criteria.
80. What is the default operator used by Elasticsearch in searching words ?
Ans:
OR.
81. What is the file name where we specify Elasticsearch options ?
Ans:
- elasticsearch.yml
82. What is the location of the elasticsearch.yml file name in the window ?
Ans:
- \elasticsearch-6.0.0\config
83. How to change cluster name in Elasticsearch ?
Ans:
In elasticsearch.yml add one entry
- cluster.name: your-cluster-name
84. Can we change existing mapping in Elasticsearch for example if a field had type String , can we make it Integer ?
Ans:
No
85. What are the core fields type in Elasticsearch ?
Ans:
- Boolean
- String
- Numeric
- Date
86. How to index a field with multiple values or in easy word Array?
Ans:
- curl -XPUT ‘localhost:9200/preparation for interview/elasticsearch/topic’ -d ‘{ “tags”: [“indexing”, “searching”] }’
87. What are the predefined fields in Elasticsearch ?
Ans:
Predefined fields provide metadata to the document.These fields we don’t need to populate. For example _timestamp which gives information when documents are indexed.Predefined fields always begin with _(underscore).
88. What is _ttl predefined field in Elasticsearch ?
Ans:
ttl means tile to live.It enables Elasticsearch to remove documents after a specified time.
89. What is _source predefined field in Elasticsearch ?
Ans:
source predefined field lets you store original documents in original format.Whenever we search any document ,we get this field by default.
90. How does Elasticsearch identify a document ?
Ans:
Elasticsearch uses combination of type and id in _uid to identify a document uniquely in a same index._uid is used by Elasticsearch to identify document internally because Elasticsearch uses Lucene index and in Lucene there is no concept of type,type abstraction is provided by Elasticsearch. That is the reason in _uid both type and id of document is stored.
91. How can documents be updated in Elasticsearch using cURL?
Ans:
To understand updating of document in Elasticsearch, follow link
92. How does Elasticsearch maintain concurrency control ?
Ans:
By version number for each document.If a document is indexed first time then its version number is 1 and if a second time update happens then version number will be 2.In the meantime anyone updates it then version conflicts and that update is cancelled.
93. What are close indices in Elasticsearch ?
Ans:
A close index does not allow write and read operation and its data is not loaded in memory. We can restore it by opening the index again.
94. What is the query component in a search request ?
Ans:
This component configures the best document to return based on its score.It is configured using query DSL or filter DSL.
95. What is the size component in the search request ?
Ans:
This component configures the amount of documents to return.
96. What is the sort component in search requests ?
Ans:
This component configures in which order documents should be returned by default order is based on _score value in descending order.
97. What is _source component in a search request ?
Ans:
This component configures which fields should be returned in _source fields.By default all fields are returned.
98. What is the component in the search request ?
Ans:
This component configures from which page documents should be returned.This is used for pagination.For example if 40 items are calculated but we want from 20 documents then from will be 20.
99. What is the default size of the page in the response to a search request ?
Ans:
10.
100. What is the difference between query and filter in Elasticsearch ?
Ans:
Query calculates score based on matching so slower compared to filters in Elasticsearch. Filters are cacheable so if filters are used in another search then bitsets are not calculated again as behind the scene Elasticsearch does for filters.