

Git Architecture Tutorial
Last updated on 13th Oct 2020, Blog, Tutorials, Version Control
Git is a distributed revision control and source code management system with an emphasis on speed. Git was initially designed and developed by Linus Torvalds for Linux kernel development. Git is a free software distributed under the terms of the GNU General Public License version 2. This tutorial explains how to use Git for project version control in a distributed environment while working on web-based and non web-based applications development.
Git- Basic concepts
Version Control System
Version Control System (VCS) is a software that helps software developers to work together and maintain a complete history of their work.
Listed below are the functions of a VCS −
- Allows developers to work simultaneously.
- Does not allow overwriting each other’s changes.
- Maintains a history of every version.
Following are the types of VCS −
- Centralized version control system (CVCS).
- Distributed/Decentralized version control system (DVCS).
Distributed Version Control System
Centralized version control system (CVCS) uses a central server to store all files and enables team collaboration. But the major drawback of CVCS is its single point of failure, i.e., failure of the central server. Unfortunately, if the central server goes down for an hour, then during that hour, no one can collaborate at all. And even in a worst case, if the disk of the central server gets corrupted and proper backup has not been taken, then you will lose the entire history of the project. Here, a distributed version control system (DVCS) comes into picture.
DVCS clients not only check out the latest snapshot of the directory but they also fully mirror the repository. If the server goes down, then the repository from any client can be copied back to the server to restore it. Every checkout is a full backup of the repository. Git does not rely on the central server and that is why you can perform many operations when you are offline. You can commit changes, create branches, view logs, and perform other operations when you are offline. You require network connection only to publish your changes and take the latest changes.
Why Git?
We have discussed many features and benefits of Git that demonstrate the undoubtedly Git as the leading version control system. Now, we will discuss some other points about why we should choose Git.
- Git Integrity
Git is developed to ensure the security and integrity of content being version controlled. It uses checksum during transit or tampering with the file system to confirm that information is not lost. Internally it creates a checksum value from the contents of the file and then verifies it when transmitting or storing data. - Trendy Version Control System
Git is the most widely used version control system. It has maximum projects among all the version control systems. Due to its amazing workflow and features, it is a preferred choice of developers. - Everything is Local
Almost All operations of Git can be performed locally; this is a significant reason for the use of Git. We will not have to ensure internet connectivity. - Collaborate to Public Projects
There are many public projects available on the GitHub. We can collaborate on those projects and show our creativity to the world. Many developers are collaborating on public projects. The collaboration allows us to stand with experienced developers and learn a lot from them; thus, it takes our programming skills to the next level. - Impress Recruiters
We can impress recruiters by mentioning the Git and GitHub on our resume. Send your GitHub profile link to the HR of the organization you want to join. Show your skills and influence them through your work. It increases the chances of getting hired.
Git Terminology
Git is a tool that covers vast terminology and jargon, which can often be difficult for new users, or those who know Git basics but want to become Git masters. So, we need a little explanation of the terminology behind the tools. Let’s have a look at the commonly used terms.
Some commonly used terms are:
Branch
A branch is a version of the repository that diverges from the main working project. It is an essential feature available in most modern version control systems. A Git project can have more than one branch. We can perform many operations on Git branch-like rename, list, delete, etc.
Subscribe For Free Demo
Error: Contact form not found.
Checkout
In Git, the term checkout is used for the act of switching between different versions of a target entity. The git checkout command is used to switch between branches in a repository.
Cherry-Picking
Cherry-picking in Git is meant to apply some commit from one branch into another branch. In case you made a mistake and committed a change into the wrong branch, but do not want to merge the whole branch. You can revert the commit and cherry-pick it on another branch.
Clone
The git clone is a Git command-line utility. It is used to make a copy of the target repository or clone it. If I want a local copy of my repository from GitHub, this tool allows creating a local copy of that repository on your local directory from the repository URL.
Fetch
It is used to fetch branches and tags from one or more other repositories, along with the objects necessary to complete their histories. It updates the remote-tracking branches.
HEAD
HEAD is the representation of the last commit in the current checkout branch. We can think of the head like a current branch. When you switch branches with git checkout, the HEAD revision changes, and points to the new branch.
Index
The Git index is a staging area between the working directory and repository. It is used as the index to build up a set of changes that you want to commit together.
Master
Master is a naming convention for Git branches. It’s a default branch of Git. After cloning a project from a remote server, the resulting local repository contains only a single local branch. This branch is called a “master” branch. It means that “master” is a repository’s “default” branch.
Merge
Merging is a process to put a forked history back together. The git merge command facilitates you to take the data created by git branch and integrate them into a single branch.
Origin
In Git, “origin” is a reference to the remote repository from a project that was initially cloned . More precisely, it is used instead of that original repository URL to make referencing much easier.
Pull/Pull Request
The term Pull is used to receive data from GitHub. It fetches and merges changes on the remote server to your working directory. The git pull command is used to make a Git pull.
Pull requests are a process for a developer to notify team members that they have completed a feature. Once their feature branch is ready, the developer files a pull request via their remote server account. Pull request announces all the team members that they need to review the code and merge it into the master branch.
Push
The push term refers to uploading local repository content to a remote repository. Pushing is an act of transfer commits from your local repository to a remote repository. Pushing is capable of overwriting changes; caution should be taken when pushing.
Rebase
In Git, the term rebase is referred to as the process of moving or combining a sequence of commits to a new base commit. Rebasing is very beneficial and visualizes the process in the environment of a feature branching workflow.
From a content perception, rebasing is a technique of changing the base of your branch from one commit to another.
Remote
In Git, the term remote is concerned with the remote repository. It is a shared repository that all team members use to exchange their changes. A remote repository is stored on a code hosting service like an internal server, GitHub, Subversion and more.
In case of a local repository, a remote typically does not provide a file tree of the project’s current state, as an alternative it only consists of the .git versioning data.
Repository
In Git, Repository is like a data structure used by VCS to store metadata for a set of files and directories. It contains the collection of the file as well as the history of changes made to those files. Repositories in Git are considered as your project folder. A repository has all the project-related data. Distinct projects have distinct repositories.
Stashing
Sometimes you want to switch the branches, but you are working on an incomplete part of your current project. You don’t want to commit to half-done work. Git stashing allows you to do so.
The git stash command enables you to switch branches without committing the current branch.
Tag
Tags make a point as a specific point in Git history. It is used to mark a commit stage as important. We can tag a commit for future reference. Primarily, it is used to mark a project’s initial point like v1.1. There are two types of tags.
- 1. Light-weighted tag
- 2. Annotated tag
Upstream And Downstream
The term upstream and downstream is a reference of the repository. Generally, upstream is where you cloned the repository from (the origin) and downstream is any project that integrates your work with other works. However, these terms are not restricted to Git repositories.
Git Revert
In Git, the term revert is used to revert some commit. To revert a commit, git revert command is used. It is an undo type command. However, it is not a traditional undo alternative.
Git Reset
In Git, the term reset stands for undoing changes. The git reset command is used to reset the changes. The git reset command has three core forms of invocation. These forms are as follows.
- Soft
- Mixed
- Hard
Git Ignore
In Git, the term ignore used to specify intentionally untracked files that Git should ignore. It doesn’t affect the Files that are already tracked by Git.
Git Diff
Git diff is a command-line utility. It’s a multi use Git command. When it is executed, it runs a diff function on Git data sources. These data sources can be files, branches, commits, and more. It is used to show changes between commits, commit, and working tree, etc.

Learn Git Training with In-Depth Concepts to Build Your Skills
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Git Cheat Sheet
A Git cheat sheet is a summary of Git quick references. It contains basic Git commands with quick installation. A cheat sheet or crib sheet is a brief set of notes used for quick reference. Cheat sheets are so named because the people may use them without no prior knowledge.
Git Flow
GitFlow is a branching model for Git, developed by Vincent Driessen. It is very well organized to collaborate and scale the development team. Git flow is a collection of Git commands. It accomplishes many repository operations with just single commands.
Git Squash
In Git, the term squash is used to squash previous commits into one. Git squash is an excellent technique to group-specific changes before forwarding them to others. You can merge several commits into a single commit with the powerful interactive rebase command.
Git Rm
In Git, the term rm stands for remove. It is used to remove individual files or a collection of files. The key function of git rm is to remove tracked files from the Git index. Additionally, it can be used to remove files from both the working directory and staging index.
Git Fork
A fork is a rough copy of a repository. Forking a repository allows you to freely test and debug with changes without affecting the original project.
Great use of using forks to propose changes for bug fixes. To resolve an issue for a bug that you found, you can:
- Fork the repository.
- Make the fix.
- Forward a pull request to the project owner.
Git Flow / Git Branching Model
Git flow is the set of guidelines that developers can follow when using Git. We cannot say these guidelines as rules. These are not the rules; it is a standard for an ideal project. So that a developer would easily understand the things.
It is referred to as the Branching Model by the developers and works as a central repository for a project. Developers work and push their work to different branches of the main repository.
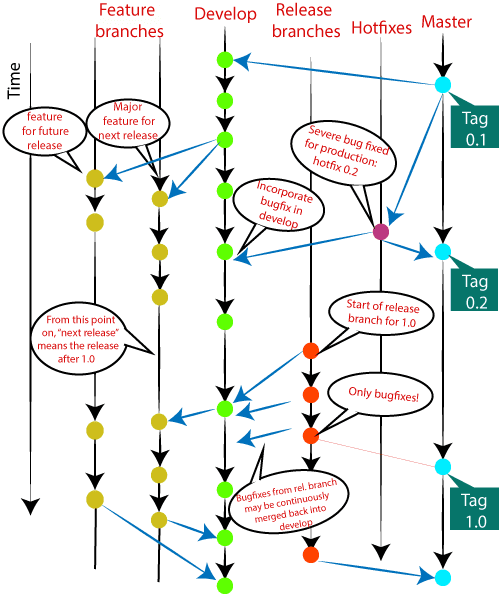
There are different types of branches in a project. According to the standard branching strategy and release management, there can be following types of branches:
- Master
- Develop
- Hotfixes
- Release branches
- Feature branches
Every branch has its meaning and standard. Let’s understand each branch and its usage.
The Main Branches
Two of the branching model’s branches are considered as main branches of the project. These branches are as follows:
- master
- develop
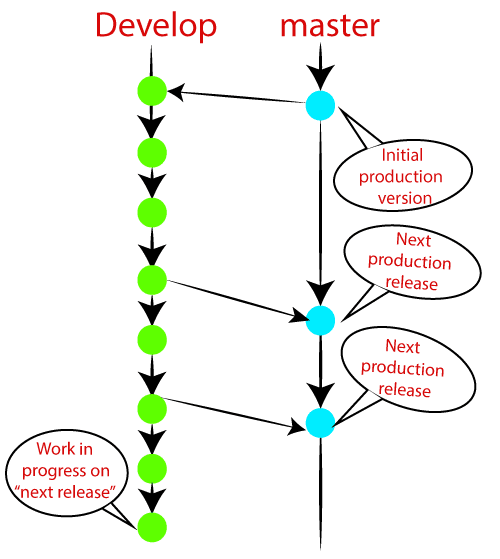
Master Branch
The master branch is the main branch of the project that contains all the history of final changes. Every developer must be used to the master branch. The master branch contains the source code of HEAD that always reflects a final version of the project.
Your local repository has its master branch that is always up to date with the master of a remote repository.
It is suggested not to mess with the master. If you edited the master branch of a group project, your changes would affect everyone else, and very quickly, there will be merge conflicts.
Develop Branch
It is parallel to the master branch. It is also considered as the main branch of the project. This branch contains the latest delivered development changes for the next release. It has the final source code for the release. It is also called an “integration branch.”
When the develop branch reaches a stable point and is ready to release, it should be merged with master and tagged with a release version.
Supportive Branches
The development model needs a variety of supporting branches for the parallel development, tracking of features, assisting in quick fixing and release, and other problems. These branches have a limited lifetime and are removed after the uses.
The different types of supportive branches, we may use are as follows:
- Feature branches
- Release branches
- Hotfix branches
Each of these branches is made for a specific purpose and have some merge targets. These branches are significant for a technical perspective.

Get Hands-on Git Training & Certification Course from Real-Time Experts
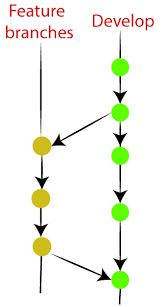
Weekday / Weekend BatchesSee Batch DetailsFeature Branches
Feature branches can be considered as topic branches. It is used to develop a new feature for the next version of the project. The existence of this branch is limited; it is deleted after its feature has been merged with the develop branch.
Release Branches
The release branch is created for the support of a new version release. Senior developers will create a release branch. The release branch will contain the predetermined amount of the feature branch. The release branch should be deployed to a staging server for testing.
Developers are allowed for minor bug fixing and preparing meta-data for a release on this branch. After all these tasks, it can be merged with the develop branch.
When all the targeted features are created, then it can be merged with the develop branch. Some usual standard of the release branch are as follows:
- Generally, senior developers will create a release branch.
- The release branch will contain the predetermined amount of the feature branch.
- The release branch should be deployed to a staging server for testing.
- Any bugs that need to be improved must be addressed at the release branch.
- The release branch must have to be merged back into developing as well as the master branch.
- After merging, the release branch with the develop branch must be tagged with a version number.
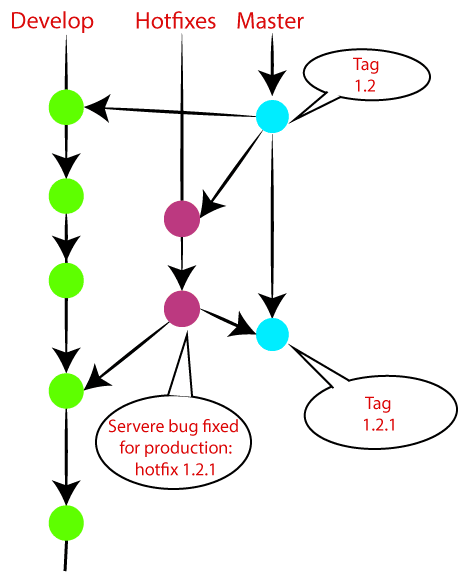
Hotfix Branches
Hotfix branches are similar to Release branches; both are created for a new production release.
The hotfix branches arise due to immediate action on the project. In case of a critical bug in a production version, a hotfix branch may branch off in your project. After fixing the bug, this branch can be merged with the master branch with a tag.
Features of Git
Some remarkable features of Git are as follows:
- Open Source
Git is an open-source tool. It is released under the GPL (General Public License) license. - Scalable
Git is scalable, which means when the number of users increases, the Git can easily handle such situations. - Distributed
One of Git’s great features is that it is distributed. Distributed means that instead of switching the project to another machine, we can create a “clone” of the entire repository. Also, instead of just having one central repository that you send changes to, every user has their own repository that contains the entire commit history of the project. We do not need to connect to the remote repository; the change is just stored on our local repository. If necessary, we can push these changes to a remote repository.
- 1. Security:Git is secure. It uses the SHA1 (Secure Hash Function) to name and identify objects within its repository. Files and commits are checked and retrieved by its checksum at the time of checkout. It stores its history in such a way that the ID of particular commits depends upon the complete development history leading up to that commit. Once it is published, one cannot make changes to its old version.
- 2. Speed:Git is very fast, so it can complete all the tasks in a while. Most of the git operations are done on the local repository, so it provides a huge speed. Also, a centralized version control system continually communicates with a server somewhere.
Performance tests conducted by Mozilla showed that it was extremely fast compared to other VCSs. Fetching version history from a locally stored repository is much faster than fetching it from the remote server. The core part of Git is written in C, which ignores runtime overheads associated with other high-level languages.
Git was developed to work on the Linux kernel; therefore, it is capable enough to handle large repositories effectively. From the beginning, speed and performance have been Git’s primary goals. - 3. Supports non-linear development:Git supports seamless branching and merging, which helps in visualizing and navigating a non-linear development. A branch in Git represents a single commit. We can construct the full branch structure with the help of its parental commit.
- 4. Branching and Merging:Branching and merging are the great features of Git, which makes it different from the other SCM tools. Git allows the creation of multiple branches without affecting each other. We can perform tasks like creation, deletion, and merging on branches, and these tasks take a few seconds only. Below are some features that can be achieved by branching:
- We can create a separate branch for a new module of the project, commit and delete it whenever we want.
- We can have a production branch, which always has what goes into production and can be merged for testing in the test branch.
- We can create a demo branch for the experiment and check if it is working. We can also remove it if needed.
- The core benefit of branching is if we want to push something to a remote repository, we do not have to push all of our branches. We can select a few of our branches, or all of them together.
- 5. Data Assurance:The Git data model ensures the cryptographic integrity of every unit of our project. It provides a unique commit ID to every commit through a SHA algorithm. We can retrieve and update the commit by commit ID. Most of the centralized version control systems do not provide such integrity by default.
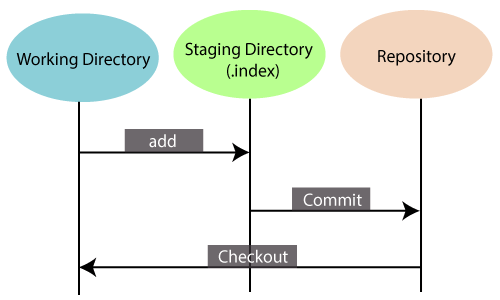
- 6. Staging Area:The Staging area is also a unique functionality of Git. It can be considered as a preview of our next commit, moreover, an intermediate area where commits can be formatted and reviewed before completion. When you make a commit, Git takes changes that are in the staging area and make them as a new commit. We are allowed to add and remove changes from the staging area. The staging area can be considered as a place where Git stores the changes.
Although, Git doesn’t have a dedicated staging directory where it can store some objects representing file changes (blobs). Instead of this, it uses a file called index.
- Another feature of Git that makes it apart from other SCM tools is that it is possible to quickly stage some of our files and commit them without committing other modified files in our working directory.Maintain the clean history
Git facilitates with Git Rebase; It is one of the most helpful features of Git. It fetches the latest commits from the master branch and puts our code on top of that. Thus, it maintains a clean history of the project.
Benefits of Git
A version control application allows us to keep track of all the changes that we make in the files of our project. Every time we make changes in files of an existing project, we can push those changes to a repository. Other developers are allowed to pull your changes from the repository and continue to work with the updates that you added to the project files.
Some significant benefits of using Git are as follows:
- Saves Time
Git is lightning fast technology. Each command takes only a few seconds to execute so we can save a lot of time as compared to login to a GitHub account and find out its features. - Offline Working
One of the most important benefits of Git is that it supports offline working. If we are facing internet connectivity issues, it will not affect our work. In Git, we can do almost everything locally. Comparatively, other CVS like SVN is limited and prefer the connection with the central repository. - Undo Mistakes
One additional benefit of Git is we can Undo mistakes. Sometimes the undo can be a savior option for us. Git provides the undo option for almost everything. - Track the Changes
Git facilitates some exciting features such as Diff, Log, and Status, which allows us to track changes so we can check the status, compare our files or branches.
Advantages of Git
Free and open source
Git is released under GPL’s open source license. It is available freely over the internet. You can use Git to manage property projects without paying a single penny. As it is an open source, you can download its source code and also perform changes according to your requirements.
Fast and small
As most of the operations are performed locally, it gives a huge benefit in terms of speed. Git does not rely on the central server; that is why there is no need to interact with the remote server for every operation. The core part of Git is written in C, which avoids runtime overheads associated with other high-level languages. Though Git mirrors the entire repository, the size of the data on the client side is small. This illustrates the efficiency of Git at compressing and storing data on the client side.
Implicit backup
The chances of losing data are very rare when there are multiple copies of it. Data present on any client side mirrors the repository, hence it can be used in the event of a crash or disk corruption.
Security
Git uses a common cryptographic hash function called secure hash function (SHA1), to name and identify objects within its database. Every file and commit is check-summed and retrieved by its checksum at the time of checkout. It implies that it is impossible to change file, date, and commit message and any other data from the Git database without knowing Git.
No need of powerful hardware
In case of CVCS, the central server needs to be powerful enough to serve requests of the entire team. For smaller teams, it is not an issue, but as the team size grows, the hardware limitations of the server can be a performance bottleneck. In case of DVCS, developers don’t interact with the server unless they need to push or pull changes. All the heavy lifting happens on the client side, so the server hardware can be very simple indeed.
Easier branching
CVCS uses a cheap copy mechanism. If we create a new branch, it will copy all the codes to the new branch, so it is time-consuming and not efficient. Also, deletion and merging of branches in CVCS is complicated and time-consuming. But branch management with Git is very simple. It takes only a few seconds to create, delete, and merge branches.