
- 40+ [REAL-TIME] Data Visualization in R Interview Questions and Answers
- 50+ Best Data Science with R Interview Questions and Answers
- Top NLP Interview Questions and Answers
- STATA Interview Questions And Answers [ FRESHERS ]
- Most Popular Data Mining Interview Questions and Answers
- [50+] SPSS Interview Questions and Answers [ TO GET HIRED ]
- Get Statistics Interview Questions [ TO GET HIRED ]
- Data Science with Python Interview Questions and Answers
- Data Structure Interview Questions and Answers
- Google Data Science Interview Questions and Answers
- SAS Clinical Interview Questions and Answers
- Data Architect Interview Questions and Answers
- Data Analyst Interview Questions and Answers
- R Interview Questions and Answers
- Data Science Interview Questions and Answers
- 40+ [REAL-TIME] Data Visualization in R Interview Questions and Answers
- 50+ Best Data Science with R Interview Questions and Answers
- Top NLP Interview Questions and Answers
- STATA Interview Questions And Answers [ FRESHERS ]
- Most Popular Data Mining Interview Questions and Answers
- [50+] SPSS Interview Questions and Answers [ TO GET HIRED ]
- Get Statistics Interview Questions [ TO GET HIRED ]
- Data Science with Python Interview Questions and Answers
- Data Structure Interview Questions and Answers
- Google Data Science Interview Questions and Answers
- SAS Clinical Interview Questions and Answers
- Data Architect Interview Questions and Answers
- Data Analyst Interview Questions and Answers
- R Interview Questions and Answers
- Data Science Interview Questions and Answers

Top NLP Interview Questions and Answers
Last updated on 26th Sep 2022, Blog, Data Science, Interview Question
1. What does one realize about NLP?
Ans:
NLP stands for language process. It deals with creating a machine to perceive the manner men browse and write in a very language. This task is achieved by planning algorithms which will extract meanings from giant datasets in audio or text format by applying machine learning algorithms.
2. Offer samples of any 2 real-world applications of NLP?
Ans:
Spelling/Grammar Checking Apps: The mobile applications and websites that supply users correct descriptive linguistics mistakes within the entered text accept human language technology algorithms. These days, they will conjointly advocate the subsequent few words that the user would possibly kind, that is additionally attributable to specific human language technology models getting used within the backend.
ChatBots: Many websites currently supply client support through these virtual bots that chat with the user and resolve their issues. It acts as a filter to the problems that don’t need associated interaction with the companies’ client executives.
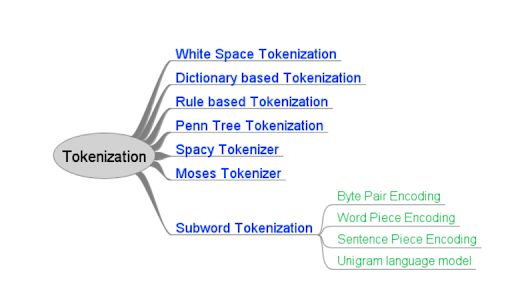
3. What’s tokenization in NLP?
Ans:
Tokenization is the method of cacophonic running text into words and sentences.
4. What’s the distinction between a proper language and a natural language?
Ans:
Formal Language Natural Language:
A formal language may be an assortment of strings, wherever every string contains symbols from a finite set referred to as alphabets. A language may be a language that humans utilize to talk. It’s sometimes totally different from a proper language. These generally contain fragments of words and pause words like uh, um, etc.
5. What’s the distinction between stemming and lemmatization?
Ans:
Both stemming and lemmatization area unit keyword standardization techniques progressing to minimize the morphological variation within the words they encounter in a very sentence. But, they’re totally different from one another within the following manner.
Stemming Lemmatization
This technique involves removing the affixes supplementary to a word and feat USA with the remainder of the word. Lemmatization is the method of changing a word into its lemma from its inflected kind. Example: ‘Caring’→ ’Car’ Example: ‘Caring’→ ’Care’
6. What’s NLU?
Ans:
NLU stands for Language Understanding. It’s a subdomain of human language technology that considers creating a machine to learn the talents of reading comprehension. A couple of applications of NLU embrace computational linguistics (MT), Newsgathering, and Text categorization. It usually goes by the name Language Interpretation (NLI) further.
7. List the variations between human language technology and NLU?
Ans:
Natural Language Processing language Understanding:
NLP may be a branch of AI that deals with planning programs for machines that may permit them to method the language that humans use. The thought is to create machines to imitate the manner humans utilize language for communication. In NLU, the aim is to boost a computer’s ability to know and analyze human language. This aim is achieved by reworking unstructured information into a machine-readable format.
8. What does one realize Latent linguistics compartmentalisation (LSI)?
Ans:
- LSI may be a technique that analyzes a collection of documents to seek out the applied mathematics existence of words that seem along. It provides associate insight into the topics of these documents.
- LSI is additionally called Latent linguistics Analysis.
9. List a couple of strategies for extracting options from a corpus for human language technology?
Ans:
- 1. Bag-of-Words
- 2. Word Embedding
10. What area units stop words?
Ans:
Stop words area unit the words in a very document that area unit thought of redundant by {nlp|natural language process|NLP|human language technology|information science|informatics|information processing|IP} engineers and area units so far away from the document before processing it. Few examples are the unit ‘is’, ‘the’, ‘are’, ‘am’.
11. What does one comprehend Dependency Parsing?
Ans:
Dependency parsing could be a technique that highlights the dependencies among the words of a sentence to know its grammatical structure. It examines however the words of a sentence are unit lingually joined to every alternative. These links are unit referred to as dependencies.
12. What’s Text Summarization? Name its 2 types?
Ans:
- Extraction-based report
- Abstraction-based report
13. What area unit false positives and false negatives?
Ans:
- If a machine learning algorithmic program incorrectly predicts a negative outcome as positive, then the result is labeled as a false negative.
- And, if a machine learning algorithmic program incorrectly predicts a positive outcome as negative, then the result is labeled as a false positive.
14. List a couple of ways for part-of-speech tagging?
Ans:
even “dogs”, that is sometimes thought of as simply a plural noun, may also be a verb: The sailor dogs the hatch. Correct grammatical tagging can mirror that “dogs” is here used as a verb, not because the additional common plural noun.
15. What’s a corpus?
Ans:
Corpus’ could be a Latin word meaning ‘body.’ Thus, a body of the written or spoken text is named a corpus.
16. List a couple of real-world applications of the n-gram model?
Ans:
- Augmentive Communication
- Part-of-speech Tagging
- Natural language generation
- Word Similarity
- Authorship Identification
- Sentiment Extraction
- Predictive Text Input
17. What will TF*What does the IDF stand for? make a case for its significance?
Ans:
- TF*IDF stands for Term-Frequency/Inverse-Document Frequency. it’s Associate in Nursing information-retrieval live that encapsulates the linguistics significance of a word in an exceedingly explicit document N, by degrading words that tend to seem in an exceedingly form of completely different documents in some immense background corpus with D documents.
- Let northwest denote the frequency of a word w within the document N, m represents the entire range of documents within the corpus that contain w. Then, TF*IDF is outlined as
- TF*IDF(w)=nw×logo
18. What’s confusing about NLP?
Ans:
- It is a metric that’s accustomed to taking a look at the performance of language models. Mathematically, it’s outlined as a performance of the likelihood that the language model represents a take a look at a sample. For a take a look at sample X = x1, x2, x3,….,xn , the confusedness is given by,
- PP(X)=P(x1,x2,…,xN)-1N
- where N is the total range of word tokens. Higher the confusion, lesser is the data sent by the language model.
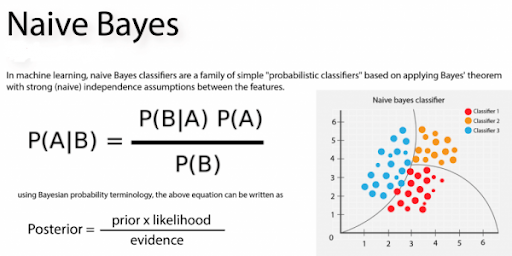
19.Which algorithmic program in natural language processing supports duplex context?
Ans:
Naive mathematician could be a classification machine learning algorithmic program that utilizes Bayes Theorem for labeling a category to the input set of options. An important component of this algorithmic program is that it assumes that each one of the feature values area unit freelance.
20. What’s Part-of-Speech tagging?
Ans:
Part-of-speech tagging is the task of assigning a part-of-speech label to every word in an exceedingly sentence. A range of part-of-speech algorithms are units on the market that contain tagsets having many tags between forty and two hundred.
21. What’s the bigram model in NLP?
Ans:
A bigram model may be a model used in NLP for predicting the probability of a word in a sentence using the conditional probability of the previous word. For calculating the contingent probability of the previous word, it’s crucial that all the previous words are known
22. What role does the Naive Bayes algorithm play in NLP?
Ans:
Numerous NLP applications make use of the Naive Bayes method. For instance: figuring out a word’s meaning, guessing a text’s tag, etc.
23. How well-versed are you in the Masked Language Model?
Ans:
The Masked Language Model is a model that attempts to finish a sentence by accurately guessing a few hidden (masked) words that are included in the input.
24.What does the NLP Bag-of-Words model mean?
Ans:
Unorganized group of words are referred to as a “bag of words.” Using the Bag-of-Words concept, A sentence in a corpus is given a vector by the NLP model. It starts by building a dictionary.
25. Briefly explain NLP’s N-gram model. ?
Ans:
The N-gram model is an NLP model that forecasts the likelihood of a word in a given sentence based on the conditional likelihood of n-1 preceding terms. The fundamental idea behind this algorithm is that we only use a small subset of the prior words to predict the subsequent word.
26. What does the term “word embedding” mean to you?
Ans:
The process of expressing textual data as a real-numbered vector is known as word embedding in NLP. This technique enables representations for words with related meanings to be comparable.
27.What is an embedding matrix, exactly?
Ans:
All of the words in a matrix’s embedding vectors make up a word embedding matrix.
28. What preliminary actions will you take before implementing an NLP machine-learning algorithm on a certain corpus?
Ans:
- Getting rid of white space
- Punctuation Elimination
- Lowercase to Uppercase Conversion
- Tokenization
- Getting Stopwords out
- Lemmatization
29. Which dictionary—a large one or a smaller one—is preferable for fixing spelling mistakes in a corpus, and why?
Ans:
A smaller dictionary is initially preferable since the majority of NLP researchers were concerned that a large lexicon would include uncommon terms that would be similar to misspelled words. However, it was later discovered (Damerau and Mays, 1989) that in actuality, a larger vocabulary is better at flagging uncommon terms as errors.
30. Do you consistently advise eliminating punctuation from the corpus you’re working with?
Ans:
No, it is not always a good idea to take punctuation out of the corpus because some NLP applications need the punctuation to be tallied with the words.
Examples: include voice synthesis, parsing, and part-of-speech tagging.
31. Name a few Python libraries you use for NLP?
Ans:
TextBlob, NLTK, Scikit-learn, GenSim, SpaCy, and CoreNLP.
32. To what extent do machine learning and deep neural networks play a role in natural language processing?
Ans:
Decision Trees, Bayesian Networks, Neural Networks, and Support Vector Machines are all useful tools.
33. I have a question about Python’s Word2Vec model; specifically. Which library has it?
Ans:
GenSim
34. What are homographs, homophones, and homonyms?
Ans:
Homographs Homophones Homonyms:
- “Home”=same
- “graph”=write
- “Home”=same
- “phone”=sound
- “Homo”=same,
- “onym” = name
These are the words that have the same spelling but may or may not have the same pronunciations. These are the words that sound similar but have different spelling and different meanings. These are the words that have the same spelling and pronunciation but different meanings.To live a life, airing a show live Eye, I River Bank, Bank Account
35. Is converting all text in uppercase to lowercase always a good idea? Explain with the help of an example?
Ans:
No, for words like The, the, THE, it is a good idea as they all will have the same meaning. However, for a word like brown which can be used as a surname for someone by the name Robert Brown, it won’t be a good idea as the word ‘brown’ has different meanings for both the cases. We, therefore, would want to treat them differently. Hence, it is better to change uppercase letters at the beginning of a sentence to lowercase, convert headings and titles to which are all in capitals to lowercase, and leave the remaining text unchanged.
36. What is a hapax/hapax legomenon?
Ans:
The rare words that only occur once in a sample text or corpus are called hapaxes. Each one of them is called an hapax or hapax legomenon (greek for ‘read-only once’). It is also called a singleton.
37. Is tokenizing a sentence based on white-space ‘ ‘ character sufficient? If not, give an example where it may not work?
Ans:
Tokenizing a sentence using the white space character is not always sufficient.
Consider the example,
- “ One of our users said, ‘I love Dezyre’s content’. ”
- Tokenizing purely based on white space would result in the following words:
- ‘I said, content’.
38. What is a collocation?
Ans:
A collocation is a group of two or more words that possess a relationship and provide a classic alternative of saying something. For example, ‘strong breeze’, ‘the rich and powerful’, ‘weapons of mass destruction.
39. List a few types of linguistic ambiguities?
Ans:
Lexical Ambiguity: This type of ambiguity is observed because of homonyms and polysemy in a sentence.
Syntactic Ambiguity: A syntactic ambiguity is observed when based on the sentence’s syntax, more than one meaning is possible.
Semantic Ambiguity: This ambiguity occurs when a sentence contains ambiguous words or phrases that have ambiguous
40. Differentiate between orthographic rules and morphological rules with respect to singular and plural forms of English words?
Ans:
Orthographic Rules Morphological Rules: These are the rules that contain information for extracting the plural form of English words that end in ‘y’. Such words are transformed into their plural form by converting ‘y’ into ‘i’ and adding the letters ‘es’ as suffixes. These rules contain information for words like fish; there are null plural forms. And words like goose have their plural generated by a change of the vowel.
41. Calculate the Levenshtein distance between two sequences ‘intention’ and ‘execution’?
Ans:

The image above can be used to understand the number of editing steps it will take for the word intention to transform into execution.
- The first step is deletion (d) of ‘I.’
- The next step is to substitute (s) the letter ‘N’ with ‘E.’
- Replace the letter ‘T’ with ‘X.’
- The letter E remains unchanged, and the letter ‘C’ is inserted (i).
- Substitute ‘U’ for the letter ‘N.’
- Thus, it will take five editing steps for transformations, and the Levenshtein distance is five.
42. What are the full listing hypothesis and minimum redundancy hypothesis?
Ans:
Full Listing Hypothesis: This hypothesis suggests that all humans perceive all the words in their memory without any internal morphological structure. So, words like tire, tiring, tired are all stored separately in the mental lexicon.
Minimum Redundancy Hypothesis: This hypothesis proposes that only the raw form of the words (morphemes) form the part of the mental lexicon. When humans process a word like tired, they recall both the morphemes (tired-d).
43. What is sequence learning?
Ans:
Sequence learning is a method of learning where both input and output are sequences.
44. What is NLTK?
Ans:
NLTK is a Python library, which stands for Natural Language Toolkit. We use NLTK to process data in human spoken languages. NLTK allows us to apply techniques such as parsing, tokenization, lemmatization, stemming, and more to understand natural languages. It helps in categorizing text, parsing linguistic structure, analyzing documents, etc.
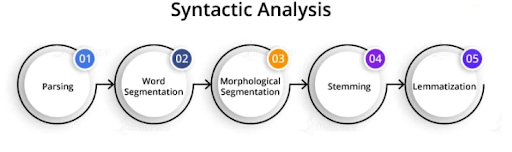
45. What is Syntactic Analysis?
Ans:
Syntactic analysis is a technique of analyzing sentences to extract meaning from it. Using syntactic analysis, a machine can analyze and understand the order of words arranged in a sentence. NLP employs grammar rules of a language that helps in the syntactic analysis of the combination and order of words in documents.
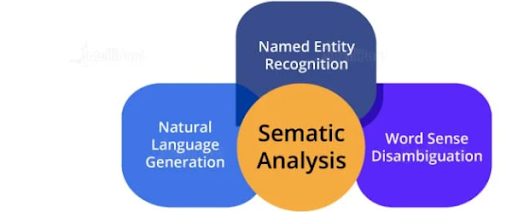
46. What is Semantic Analysis?
Ans:
Semantic analysis helps make a machine understand the meaning of a text. It uses various algorithms for the interpretation of words in sentences. It also helps understand the structure of a sentence.
47. List the components of Natural Language Processing?
Ans:
The major components of NLP are as follows:

48. What’s Latent linguistics compartmentalisation (LSI)?
Ans:
Latent linguistics compartmentalisation could be a mathematical technique wont to improve the accuracy of the data retrieval method. The planning of LSI algorithms permits machines to find the hidden (latent) correlation between linguistics (words). to reinforce data understanding, machines generate varied ideas that come with the words of a sentence.
The technique used for data understanding is termed singular worth decomposition. it’s usually wont to handle static and unstructured knowledge. The matrix obtained for singular worth decomposition contains rows for words and columns for documents. This technique most closely fits to spot parts and cluster them per their varieties.
The main principle behind LSI is that words carry the same meaning once employed in the same context. procedure LSI models are slow as compared to alternative models. However, they’re smart at discourse awareness that helps improve the analysis and understanding of a text or a document.
49. What’s Regular Grammar?
Ans:
Regular synchronic linguistics is employed to represent an everyday language:
A regular synchronic linguistics includes rules within the kind of A -> a, A -> aB, and plenty of additional rules. The foundations facilitate finding and analyzing strings by machine-controlled computation.
Regular synchronic linguistics consists of 4 tuples:
- ‘N’ is employed to represent the non-terminal set.
- ‘∑’ represents the set of terminals.
- ‘P’ stands for the set of productions.
- ‘S € N’ denotes the beginning of non-terminal.
50. What’s Parsing within the context of NLP?
Ans:
Parsing in natural language processing refers to the understanding of a sentence and its grammatical structure by a machine. Parsing permits the machine to know the meaning of a word during a sentence and also the grouping of words, phrases, nouns, subjects, and objects during a sentence. Parsing helps analyze the text or the document to extract helpful insights from it. to know parsing, talk over with the below diagram:
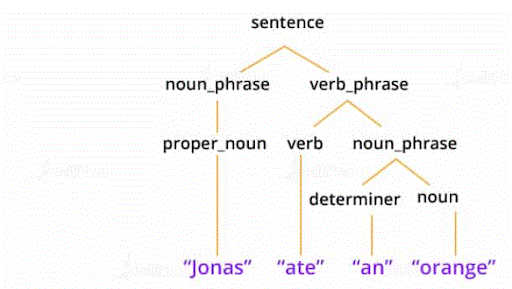
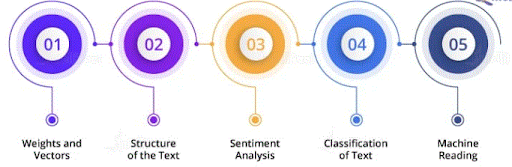
51. Outline the language in NLP?
Ans:
This is one in every of the foremost typically asked natural language processing interview queries.The interpretation of tongue process depends on varied factors, and that they are:
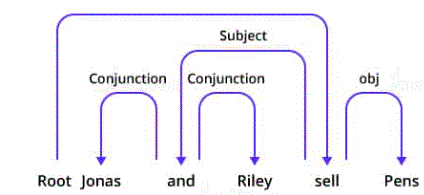
52. Justify Dependency Parsing in NLP?
Ans:
Dependency parsing helps assign a grammar structure to a sentence. Therefore, it’s conjointly referred to as grammar parsing. Dependency parsing is one of the vital tasks in natural language processing. It permits the analysis of sentence victimization parsing algorithms. Also, by victimizing the breakdown tree in dependency parsing, we are able to check the synchronic linguistics and analyze the linguistics structure of a sentence.
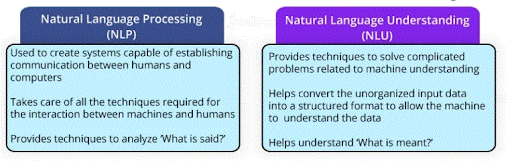
53. What’s the distinction between natural language processing and NLU?
Ans:
The below table shows the distinction between natural language processing and NLU:
54. What’s Pragmatic Analysis?
Ans:
Pragmatic analysis is a crucial task in natural language processing for decoding data that’s lying outside a given document. The aim of implementing pragmatic analysis is to specialize in exploring a unique side of the document or text during a language. This needs comprehensive data of the $64000 world. The pragmatic analysis permits computer code applications for the vital interpretation of the real-world knowledge to understand the particular meanings of sentences and words.
Example:
Consider this sentence: ‘Do you recognize what time it is?’
This sentence will either be asked for knowing the time or for yelling at somebody to create them note the time. This relies on the context within which we tend to use the sentence.
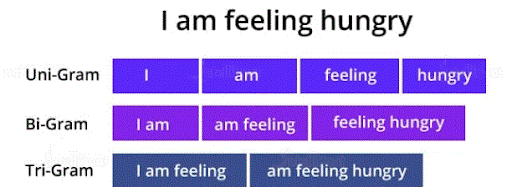
55. What are unigrams, bigrams, trigrams, and n-grams in NLP?
Ans:
When we break down a sentence one word at a time, then it’s referred to as a unigram. The sentence parsed 2 words at a time could be a written word.When the sentence is parsed 3 words at a time, then it’s a written word.
Example: to know unigrams, bigrams, and trigrams, you’ll be able to talk over with the below diagram
Therefore, parsing permits machines to know the individual meaning of a word during a sentence. Also, this sort of parsing helps predict future word and proper writing system errors.
56. What are the steps concerned in finding an Associate in Nursing natural language processing problem?
Ans:
Below are the steps concerned in finding Associate in Nursing natural language processing problem:
- Gather the text from the out there dataset or by internet scraping
- Apply stemming and lemmatization for text cleansing
- Apply feature engineering techniques
- Embed victimization word2vec
- Train the designed model victimization neural networks or alternative Machine Learning techniques
- Evaluate the model’s performance
- Make acceptable changes within the model
- Deploy the model
59. What’s Feature Extraction in NLP?
Ans:
Features or characteristics of a word facilitate text or document analysis. They conjointly facilitate sentiment analysis of a text. Feature extraction is one in every of the techniques that ar employed by recommendation systems. Reviews like ‘excellent,’ ‘good,’ or ‘great’ for a pic are positive reviews, recognized by a recommender system. The recommender system conjointly tries to spot the options of the text that facilitate in describing the context of a word or a sentence. Then, it makes a bunch or class of the words that have some common characteristics. Now, whenever a brand new word arrives, the system categorizes it as per the labels of such teams.
58. What is precision and recall?
Ans:
- The metrics used to test an NLP model are precision, recall, and F1. Also, we use accuracy for evaluating the model’s performance. The ratio of prediction and the desired output yields the accuracy of the model.
- Precision is the ratio of true positive instances and the total number of positively predicted instances.

59. What is F1 score in NLP?
Ans:
F1 score evaluates the weighted average of recall and precision. It considers both false negative and false positive instances while evaluating the model. F1 score is more accountable than accuracy for an NLP model when there is an uneven distribution of class. Let us look at the formula for calculating F1 score:
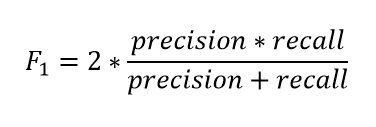
60. How to tokenize a sentence using the nltk package?
Ans:
Tokenization is a process used in NLP to split a sentence into tokens. Sentence tokenization refers to splitting a text or paragraph into sentences.For tokenizing, we will import sent_tokenize from the nltk package:
from nltk.tokenize import sent_tokenize<"">
We will use the below paragraph for sentence tokenization:
- Para = “Hi Guys. Welcome to ACRE. This is a blog on the NLP interview questions and answers.”
- sent_tokenize(Para)Output:
- [ ‘Hi Guys.’ ,
- ‘Welcome to ACRE. ‘,
- ‘This is a blog on the NLP interview questions and answers. ‘ ]
- Tokenizing a word refers to splitting a sentence into words.
- Now, to tokenize a word, we will import word_tokenize from the nltk package.
- from nltk.tokenize import word_tokenize
- Para = “Hi Guys. Welcome to ACRE. This is a blog on the NLP interview questions and answers.”
- word_tokenize(Para)Output:[ ‘Hi’ , ‘Guys’ , ‘ . ‘ , ‘Welcome’ , ‘to’ , ‘ ACTE’ , ‘ . ‘ , ‘This’ , ‘is’ ,
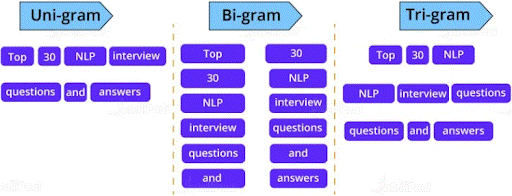
61. Explain how we can do parsing?
Ans:
Parsing is the method to identify and understand the syntactic structure of a text. It is done by analyzing the individual elements of the text. The machine parses the text one word at a time, then two at a time, further three, and so on.
- When the machine parses the text one word at a time, then it is a unigram.
- When the text is parsed two words at a time, it is a bigram.
- The set of words is a trigram when the machine parses three words at a time.
62. Explain Stemming with the help of an example?
Ans:
In Natural Language Processing, stemming is the method to extract the root word by removing suffixes and prefixes from a word.For example:
- we can reduce ‘stemming’ to ‘stem’ by removing ‘m’ and ‘ing.’
- We use various algorithms for implementing stemming, and one of them is PorterStemmer.
- First, we will import PorterStemmer from the nltk package.
- from nltk.stem import PorterStemmer
- Creating an object for PorterStemmer
- pst=PorterStemmer()
- pst.stem(“running”), pst.stem(“cookies”), pst.stem(“flying”)
- Output:(‘run’, ‘cookie’, ‘fly’ )
63. Make a case for Lemmatization with the assistance of an associated example?
Ans:
- However, stemming might not provide the particular word, whereas lemmatization generates an important word.
- In lemmatization, instead of simply removing the suffix and therefore the prefix, the method
- tries to search out the foundation word with its correct meaning.
- Let’s implement lemmatization with the assistance of some nltk packages.
- First, we are going to import the specified packages.
- from nltk.stem import wordnet
- from nltk.stem import WordnetLemmatizer
- Creating associate object for WordnetLemmatizer()
- lemma= WordnetLemmatizer()
- list = [“Dogs”, “Corpora”, “Studies”]
- for n in list:
- print(n + “:” + lemma.lemmatize(n))
- Output:
- Dogs: Dog
- Corpora: Corpus
- Studies: Study
64.Explain Named Entity Recognition by implementing it?
Ans:
Named Entity Recognition (NER) is an associated data retrieval method. NER helps classify named entities like financial figures, location, things, people, time, and more. It permits the package to research and perceive the meaning of the text. NER is usually employed in IP, computing, and Machine Learning. One in all the real-life applications of NER is chatbots used for client support. Let’s implement NER exploitation of the spaced-out package. Importing the spaced-out package:
- import spaced-out
- nlp = spaced-out.loud(‘en_core_web_sm’)
- document = nlp(text)for rent in document.ents:
- print(ent.text, ent.start_char, ent.end_char, ent.label_)
- Output:
- Office nine fifteen Place
- Google nineteen twenty five ORG
- California thirty two forty one GPE
65. The way to check word similarity exploitation the spaced-out package?
Ans:
To find out the similarity among words, we have a tendency to use word similarity. we have a tendency to judge the similarity with the assistance of variety that lies between zero and one. we have a tendency to use the spaced-out library to implement the technique of word similarity.
- import spaced-out
- nlp = spaced-out.loud(‘en_core_web_md’)
- print(“Enter the words”)
- input_words = input()
- tokens = nlp(input_words)
- for i in tokens:
- print(i.text, i.has_vector, i.vector_norm, i.is_oov)
- token_1, token_2 = tokens[0], tokens[1]
- print(“Similarity between words:”, token_1.similarity(token_2))
- Output:
- hot True 5.6898586 False
- cold True6.5396233 False
- Similarity: zero.597265
66. List some ASCII text file libraries for NLP?
Ans:

The popular libraries are NLTK (Natural Language ToolKit), SciKit Learn, Textblob, CoreNLP, spaCY, Gensim.
67. Make a case for the disguised language model?
Ans:
Masked modeling is an associated example of autoencoding language modeling. Here the output is foretold from corrupted input. By this model, we are able to predict the word from alternative words given within the sentences.
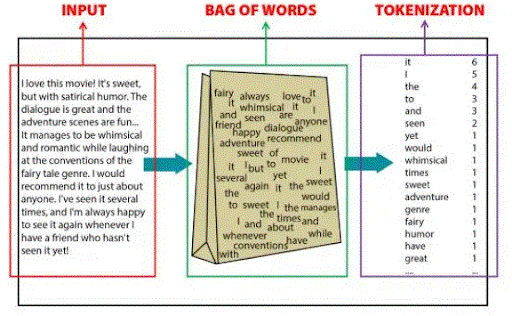
68.What is that bag of words model?
Ans:
The Bag Of Words model is employed for data retrieval. Here the text is described as a multiset, i.e., a bag of words. we have a tendency to don’t contemplate descriptive linguistics and ordering, however we have a tendency to sure as shooting maintain the multiplicity:
69. What area unit the options of the text corpus in NLP?
Ans:
The options of text corpus are:
- Word count
- Vector notation
- Part of speech tag
- Boolean feature
- Dependency descriptive linguistics
70. What’s named entity recognition (NER)?
Ans:
Named Entity Recognition could be a part of info retrieval, a way to find and classify the entity’s gift within the unstructured information provided and convert them into predefined classes.
71.What is the Associate in Nursing informatics pipeline, and what will it consist of?
Ans:
Generally, informatics issues will be solved by navigating the subsequent steps (referred as a pipeline):
Gathering text, whether or not it’s from net scraping or the utilization of accessible datasets:
- Representation of the text (bag-of-words method)
- Word embedding and sentence illustration (Word2Vec, SkipGram model)
- Evaluating the model
- Adjusting the model, as needed
- Deploying the model
72. What’s a “stop” word?
Ans:
Articles like “the” or “an,” and alternative filler words that bind sentences along (e.g., “how,” “why,” and “is”) however don’t provide abundant extra that means area unit usually remarked as “stop” words. so as to induce the basis of an exploration and deliver the foremost relevant results, search engines habitually filter stop words.
73. What’s “term frequency-inverse document frequency?
Ans:
- Term frequency-inverse document frequency (TF-IDF) is an Associate in Nursing indicator of however necessary a given word is in a document, that helps determine key words and assist with the method of feature extraction for categorization functions. whereas “TF” identifies however ofttimes a given word or phrase (“W”) is employed, “IDF” measures its importance inside the document. The formulas to answer this informatics interview question area unit as follows:
- TF(W) = Frequency of W in a very document / Total variety of terms within the documentIDF(W) = log_e (Total variety of documents / variety of documents having the term W)
- Using these formulas, you’ll be able to confirm simply however necessary a given word or phrase is inside a document.
- Search engines use this to assist them rank sites.
74. What’s perplexity? What’s its place in NLP?
Ans:
Perplexity could be a thanks to categorical a degree of confusion a model has in predicting. additional entropy = additional confusion. disarray is employed to judge language models in informatics. a decent language model assigns a better chance to the correct prediction.
75. What’s the matter with ReLu?
Ans:
- Exploding gradient(Solved by gradient clipping)
- Dying ReLu — No learning if the activation is zero (Solved by constant quantity relu)
- Mean and variance of activations isn’t zero and one.(Partially solved by subtracting around zero.5 from activation. higher explained in fastai videos)
76. What’s the distinction between learning latent options victimization SVD and obtaining embedding vectors victimization deep network?
Ans:
SVD uses linear combination of inputs whereas a neural network uses nonlinear combination.
77. What area unit the various sorts of attention mechanism?
Ans:
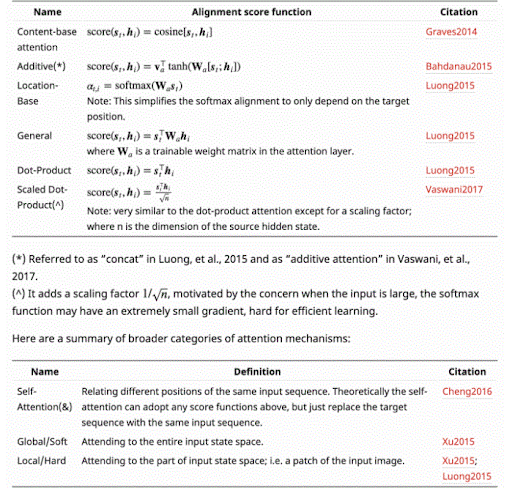
78. Why will the electrical device block have LayerNorm rather than BatchNorm?
Ans:
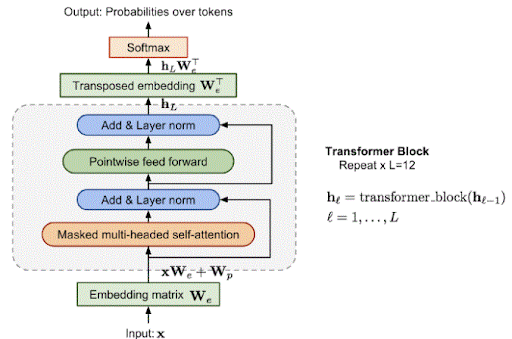
79. What are the tricks utilized in ULMFiT? (Not an excellent queries however checks the awareness?
Ans:
- LM standardization with task text
- Weight dropout
- Discriminative learning rates for layers
- Gradual unfreezing of layers
- Slanted triangular learning rate schedule
80. What are the variations between GPT and BERT?
Ans:
- GPT isn’t bidirectional and has no thought of masking.
- BERT adds next sentence prediction task in coaching then it additionally features a phase embedding.
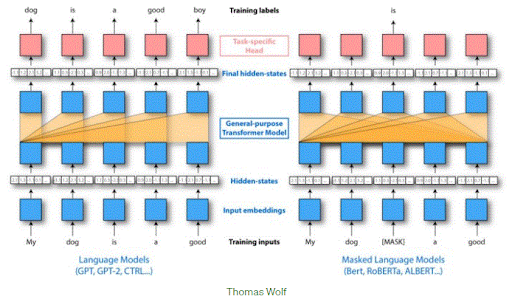
81. Given this chart, can you associate it with an electrical device model or LSTM language model?
Ans:
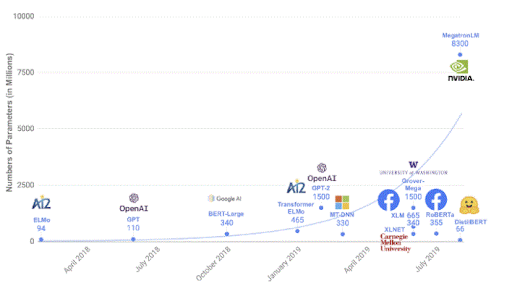
82. What’s Language modeling ?
Ans:
An applied mathematics language model could be a chance distribution over sequences of words. Given such a sequence, say of length m, it assigns a chance to the entire sequence. The language model provides context to differentiate between words and phrases that sound simila.
83. What’s Latent linguistics analysis ?
Ans:
Latent linguistics analysis could be a technique in language process, especially spatial arrangement linguistics, of analyzing relationships between a group of documents and also the terms they contain by manufacturing a group of ideas associated with the documents and terms.
84. What’s Fasttext?
Ans:
FastText could be a library for learning of word embeddings and text classification created by Facebook’s AI work. The model permits to make AN unattended learning or supervised learning formula for getting vector representations for words.
85. Justify components of speech tagging (POS tagging)?
Ans:
Example:
- import nltk
- from nltk.corpus import stopwords
- from nltk.tokenize import word_tokenize, sent_tokenize
- stop_words = set (stopwords.Words(‘english’))
- ## Tokenized via sent_tokenize
- tokenized_text = sent_tokenize (txt)/li>
- impor## exploitation word_tokenizer to spot a string’s words and punctuation then removing stop words
- for n in tokenized_text:
- wordsList = nltk.word_tokenize(i)
- ## exploitation POS tagger
- tagged_words = nltk.pos_tag(wordsList)
- print (tagged_words)
- Output:-
86. Outline and implement named entity recognition?
Ans:
For retrieving data and characteristic entities given within the knowledge as an example location, time, figures, things, objects, people, etc. NER (named entity recognition) is employed in AI, NLP, machine learning, enforced for creating the code that perceives what the text suggests. Chatbots are a real-life example that produces use of NER.
- import spacey
- nlp = spacey.load(‘en_core_web_sm’)
- Text = “The head workplace of Tesla is in California”
- document = nlp(text)
- for rent in document.ents:
- print(ent.text, ent.start_char, ent.end_char, ent.label_)
- output
- Office nine fifteen Place
- Tesla nineteen twenty five ORG
- California thirty two forty one GPE
87. What’s the importance of TF-IDF?
Ans:
In data retrieval TF IDF can be a numerical data point that’s meant to replicate however necessary a word is to a document in a very assortment or within the assortment of a group.
88. What’s Named Entity Recognition(NER)?
Ans:
- Named entity recognition could be a technique to divide a sentence into classes. astronauts of the United States of America who had landed on the moon in 1969 are categorized as Neil Armstrong- name; The United States of America – country;1969 – time(temporal token).
- The idea behind HER is to alter the machine to tug out entities like folks, places, things, locations, financial figures, and more.
89. Make a case for in short concerning word2vec?
Ans:
Word2Vec embeds words during a lower-dimensional vector house employing a shallow neural network. The results of a collection of word-vectors wherever vectors close in the vector house have similar meanings supported by context, and word-vectors distant to every different have different meanings.
For example: apple and orange would be close and apple and gravity would be comparatively so. There are 2 versions of this model supported skip-grams (SG) and continuous-bag-of-words (CBOW).
90. What are the five steps in NLP?
Ans:
The 5 phases of NLP involve lexical (structure) analysis, parsing, linguistics analysis, discourse integration, and pragmatic analysis. Some well-known application areas of NLP are Optical Character Recognition (OCR), Speech Recognition, MT, and Chatbots.
91. What’s the biggest challenges of NLP?
Ans:
There is huge ambiguity once you process language. 4. trendy NLP algorithms support machine learning, particularly applied mathematics machine learning.
92. That NLP model provides the most effective accuracy amongst the following?
Ans:
Naive Thomas Bayes is the most precise model, with an exactness of eighty eight.35%, whereas called Trees have an exactness of sixty six.
93. What number elements of NLP are there?
Ans:
Five main parts of the language process in AI are: Morphological and Lexical Analysis. Syntactical Analysis. Linguistics Analysis.
94. What’s an NLP example?
Ans:
Email filters are one in every of the foremost basic and initial applications of NLP on-line. It comes into being with spam filters, uncovering sure words or phrases that signal a spam message. The system acknowledges if emails belonging to one in every of 3 classes (primary, social, or promotions) supported their contents.
95. UN agencies use NLP?
Ans:
Interest in NLP grew within the late Nineteen Seventies, when Bandler and Grinder began selling the approach as a tool for folks to be told however others attain success. Today, NLP is employed during a wide range of fields, as well as message, medicine, law, business, the humanities, sports, the military, and education.
96. Why is linguistics important?
Ans:
Neurolinguistics is very important as a result of it studies the mechanisms within the brain that manage acquisition, comprehension, and production of language.