
- Professional Scrum Master Salary | Everything You Need to Know [ OverView ]
- What is Google Cloud Certification Path (GCP)? | Comprehensive Guide [ Explained ]
- Top Career Opportunities | Read this article to know more
- Top Automation Companies| Expert’s Top Picks
- All about SAP Course Know about the fees
- What is White Collar Job?
- Must-Know [LATEST] NLP Interview Questions and Answers
- Types of Influencers | Use to Improve Your Marketing | All you need to know
- Future Work in 2030 – Exciting Career Options
- Top 10 Online Courses in India [ Job & Future ]
- Future Scope of IoT (Internet of Things) in Modern World
- Characteristics Of Complexity Tables, General System and FPA
- The Most In-demand and Highest Paying Jobs in Australia 2020
- Why is Career Exploration important?
- Tips for Women Returning to Work After a Career Gap
- The Importance of Security Awareness
- Incredible Examples of Successful Rebranding
- Top Skills that Boosts Java Developer Salaries
- Why E-Learning?
- Hash in Python
- Professional Scrum Master Salary | Everything You Need to Know [ OverView ]
- What is Google Cloud Certification Path (GCP)? | Comprehensive Guide [ Explained ]
- Top Career Opportunities | Read this article to know more
- Top Automation Companies| Expert’s Top Picks
- All about SAP Course Know about the fees
- What is White Collar Job?
- Must-Know [LATEST] NLP Interview Questions and Answers
- Types of Influencers | Use to Improve Your Marketing | All you need to know
- Future Work in 2030 – Exciting Career Options
- Top 10 Online Courses in India [ Job & Future ]
- Future Scope of IoT (Internet of Things) in Modern World
- Characteristics Of Complexity Tables, General System and FPA
- The Most In-demand and Highest Paying Jobs in Australia 2020
- Why is Career Exploration important?
- Tips for Women Returning to Work After a Career Gap
- The Importance of Security Awareness
- Incredible Examples of Successful Rebranding
- Top Skills that Boosts Java Developer Salaries
- Why E-Learning?
- Hash in Python

Must-Know [LATEST] NLP Interview Questions and Answers
Last updated on 08th Dec 2022, Blog, Interview Question, Trending
1. What is know about NLP?
Ans:
NLP stands for a Natural Language Processing. It deals with the making a machine understand the way human beings read and write in a language. This task is achieved by a designing algorithms that can extract meaning from a large datasets in audio or text format by applying machine learning algorithms.
2. Give examples of a any two real-world applications of NLP?
Ans:
Spelling/Grammar Checking Apps:The mobile applications and websites that provide users correct grammar mistakes in a entered text rely on NLP algorithms. These days, they can also recommend following few words that the user might type, which is also because of particular NLP models being used in a backend.
ChatBots:Many websites now offer a customer support through these virtual bots that chat with user and resolve their problems. It acts as filter to issues that do not require an interaction with companies’ customer executives.
3. What is a tokenization in NLP?
Ans:
Tokenization is a process of splitting running text into a words and sentences.
4. What is difference between the formal language and a natural language?
Ans:
| Formal Language | Natural Language |
|---|---|
| A formal language is the collection of strings, where each string contains a symbols from a finite set called alphabets. | A natural language is the language that humans utilize to speak. It is usually a lot various from a formal language. These typically contain fragments of words and pause the words like uh, um, etc. |
5. What is difference between the stemming and lemmatization?
Ans:
Both stemming and lemmatization are the keyword normalization techniques aiming to minimize a morphological variation in words they encounter in a sentence. But, they are various t from each other in a following way.
| Stemming | Lemmatization |
|---|---|
| This technique involves removing affixes added to the word and leaving us with the rest of word. | Lemmatization is a process of converting a word into lemma from its an inflected form. |
| Example: ‘Caring’→ ’Car’ | Example: ‘Caring’→ ’Care’ |
6. What is a NLU?
Ans:
NLU stands for a Natural Language Understanding. It is subdomain of NLP that concerns making a machine learn skills of reading comprehension. A few applications of NLU include a Machine translation (MT., Newsgathering, and Text categorization. It often goes by a name Natural Language Interpretation (NLI. as well.
7. List differences between the NLP and NLU?
Ans:
| Natural Language Processing | Natural Language Understanding |
|---|---|
| NLP is branch of AI that deals with designing programs for the machines that will allow them to process language that humans use. The idea is to make a machines imitate way humans utilize language for communication. | In NLU, the aim is to improve the computer’s ability to understand and analyze human language. This aim is achieved by transforming a unstructured data into machine-readable format. |
8. What is know about Latent Semantic Indexing (LSI.?
Ans:
LSI is a technique that analyse a set of documents to find statistical coexistence of words that appear together. It gives an insight into topics of those documents.LSI is also known as a Latent Semantic Analysis.
9. List a few methods for an extracting features from a corpus for NLP.
Ans:
- 1. Bag-of-Words
- 2. Word Embedding
10. What are the stop words?
Ans:
Stop words are words in document that are considered redundant by a NLP engineers and are thus removed from document before processing it.11. What is know about Dependency Parsing?
Ans:
Dependency parsing is the technique that highlights the dependencies among words of a sentence to understand its grammatical structure. It examines how words of a sentence are linguistically linked to the each other. These links are called the dependencies.
12. What is a Text Summarization? Name its two types?
Ans:
- Extraction-based Summarization
- Abstraction-based Summarization
13. What are the false positives and false negatives?
Ans:
- If a machine learning algorithm falsely predicts the negative outcome as positive, then a result is labeled as a false negative.
- And, if machine learning algorithm falsely predicts the positive outcome as negative, then a result is labeled as a false positive.
14. List few methods for a part-of-speech tagging?
Ans:
A Rule-based tagging, HMM-tagging, transformation-based tagging, and a memory-based tagging.
15. What is corpus?
Ans:
Corpus’ is the Latin word that means ‘body.’ Thus, a body of written or spoken text is called corpus.
16. List a few real-world applications of a n-gram model?
Ans:
- Augmentive Communication
- Part-of-speech Tagging
- Natural language generation
- Word Similarity
- Authorship Identification
- Sentiment Extraction
- Predictive Text Input
17. What does a TF*IDF stand for? Explain its significance?
Ans:
TF*IDF stands for a Term-Frequency/Inverse-Document Frequency. It is information-retrieval measure that encapsulates a semantic significance of a word in the particular document N, by degrading words that tend to appear in the variety of different documents in some huge background corpus with a D documents.
Let nw denote a frequency of a word w in a document N, m represents the total number of documents in corpus that contain w. Then, TF*IDF is defined as a.
- TF*IDF(w.=nw×lognm
18. What is a perplexity in NLP?
Ans:
It is the metric that is used to test the performance of a language models. Mathematically, it is explained as a function of the probability that the language model represents test sample. For test sample X = x1, x2, x3,….,xn , a perplexity is given by,
- PP(X.=P(x1,x2,…,xN.-1N
Where N is a total number of word tokens. Higher perplexity, lesser is the information conveyed by a language model.
19.Which algorithm in a NLP supports bidirectional context?
Ans:
Naive Bayes is the classification machine learning algorithm that utilizes Baye’s Theorem for a labeling a class to the input set of features. A vital element of this algorithm is that it assumes that all feature values are be independent.
20. What is a Part-of-Speech tagging?
Ans:
Part-of-speech tagging is a task of assigning a part-of-speech label to each word in the sentence. A variety of part-of-speech algorithms are available that contain a tagsets having several tags between the 40 and 200.
21. What is a bigram model in NLP?
Ans:
A bigram model is the model used in NLP for predicting the probability of word in a sentence using a conditional probability of the previous word. For calculating conditional probability of a previous word, it is crucial that all previous words are known.
22. What is significance of Naive Bayes algorithm in NLP?
Ans:
The Naive Bayes algorithm is widely used in a NLP for different applications. For example: to find the sense of a word, to predict a tag of a given text, etc.
23. What is know about a Masked Language Model?
Ans:
The Masked Language Model is the model that takes a sentence with few hidden (masked. words as input and tries to a sentence by correctly guessing those hidden words.
24. What is a Bag-of-words model in NLP?
Ans:
Bag-of-words refers to the unorganized set of words. The Bag-of-words model is NLP isthe model that assigns a vector to a sentence in a corpus. It first creates the dictionary of words and then produces a vector by assigning the binary variable to each word of the sentence depending on whether it exists in a bag of words or not.
25. Briefly describe a N-gram model in NLP?
Ans:
N-gram model is the model in NLP that predicts the probability of word in a given sentence using a conditional probability of n-1 previous words in sentence. The basic intuition behind this algorithm is that instead of using all previous words to predict a next word, use only a few previous words.
26. What understand by a word embedding?
Ans:
In NLP, word embedding is a process of representing textual data through the real-numbered vector. This method allows words having a similar meanings to have similar representation.
27. What is embedding matrix?
Ans:
A word embedding matrix is the matrix that contains embedding vectors of all words in given text.
28. List few popular methods used for a word embedding.
Ans:
- Embedding Layer
- Word2Vec
- Glove
29. How will use a Python’s concordance command in the NLTK for a text that does not belong to a package?
Ans:
- The concordance(. function can simply be accessed for a text that belongs to a NLTK package .
- However, for text that does not belong to a NLTK package, one has to use the code to access that a function.
- Have created a Text object to access a concordance(. function. The function displays a occurrence of the chosen word and context around it.
30. Write a code to count a number of distinct tokens in a text?
Ans:
- len(set(text..
31. What are first few steps that will take before applying an NLP machine-learning algorithm to given corpus?
Ans:
- Removing white spaces
- Removing Punctuations
- Converting Uppercase to Lowercase
- Tokenization
- Removing Stopwords
- Lemmatization
32. For correcting spelling errors in the corpus, which one is a better choice: a giant dictionary or smaller dictionary, and why?
Ans:
Initially, smaller dictionary is a better choice because most a NLP researchers feared that giant dictionary would contain rare words that may be similar to a misspelled words. However, later it was found (Damerau and Mays (1989.. that in a practice, a more extensive dictionary is better at marking a rare words as errors.
33. Do always recommend removing punctuation marks from a corpus you’re dealing with? Why/Why not?
Ans:
No, it is not always good idea to remove punctuation marks from a corpus as they are necessary for a certain NLP applications that require a marks to be counted along with the words.
For example: Part-of-speech tagging, parsing, a speech synthesis.
34. List few libraries that use for a NLP in Python?
Ans:
NLTK, Scikit-learn,GenSim, SpaCy, CoreNLP, TextBlob.
35. Suggest few machine learning/deep learning models that are used in a NLP?
Ans:
Support Vector Machines, Neural Networks, Decision Tree, Bayesian Networks.
36. Which library contains a Word2Vec model in a Python?
Ans:
GenSim
37. What are the homographs, homophones, and homonyms?
Ans:
| Homographs | Homophones | Homonyms |
|---|---|---|
| “Home”=same“graph”=write | “Home”=same“phone”=sound | “Homo”=same,“onym” = name |
| These are words that have a same spelling but may or may not have a same pronunciations. | These are words that sound similar but have various spelling and different meanings. | These are the words that have a same spelling and pronunciation but a different meanings. |
| To live the life, airing a show live | Eye, I | River Bank, Bank Account |
38. Is converting all text in the uppercase to lowercase always a good idea? Explain with help of an example?
Ans:
No, for words like a The, the, THE, it is a good idea as they all will have a same meaning. However, for a word like brown which can be used as a surname for the someone by a name Robert Brown, it won’t be a good idea as a word ‘brown’ has different meanings for both cases. Hence, it is a better to change uppercase letters at beginning of a sentence to lowercase, convert headings and titles to which are all in a capitals to lowercase, and leave a remaining text unchanged.
39. What is the hapax/hapax legomenon?
Ans:
The rare words that only occur once in the sample text or corpus are called hapaxes. Each one of them is called hapax or hapax legomenon (greek for ‘read-only once’.. It is also called the singleton.
40. Is tokenizing a sentence based on a white-space ‘ ‘ character sufficient? If not, give an example where it may not be work.
Ans:
Tokenizing a sentence using a white space character is not always sufficient.
Consider an example,”I appreciate the stuff on Dezyre,” one of the users commented.
Tokenizing purely based on a white space would result in a following words:‘I said, content’.
41. What is the collocation?
Ans:
A collocation is the group of two or more words that possess a relationship and provide the classic alternative of saying something. For example, ‘strong breeze’, ‘the rich and powerful’, ‘weapons of a mass destruction.42. List few types of a linguistic ambiguities.
Ans:
Lexical Ambiguity: This type of an ambiguity is observed because of a homonyms and polysemy in a sentence. Syntactic Ambiguity: A syntactic ambiguity is observed when based on a sentence’s syntax, more than one meaning is be possible. Semantic Ambiguity: This ambiguity occurs when a sentence contains an ambiguous words or phrases that have a ambiguous43. Differentiate between the orthographic rules and morphological rules with respect to a singular and plural forms of English words.
Ans:
Orthographiical Rules Morphological Rules These are the rules that contain a information for extracting a plural form of English words that end in ‘y’. Such words are the transformed into their plural form by converting ‘y’ into ‘i’ and adding a letters ‘es’ as suffixes. These rules contain an information for words like a fish; there are null plural forms. And words like goose have their plural generated by change of vowel.44. Calculate Levenshtein distance between the two sequences ‘intention’ and ‘execution’
Ans:
- The first step is a deletion (d. of ‘I.’
- The next step is to be substitute (s. a letter ‘N’ with ‘E.’
- Replace a letter ‘T’ with ‘X.’
- The letter E remains be unchanged, and a letter ‘C’ is inserted (i..
- Substitute ‘U’ for a letter ‘N.’
- Thus, it will take a five editing steps for a transformations, and Levenshtein distance is five.
45. What are full listing hypothesis and minimum redundancy of hypothesis?
Ans:
Full Listing Hypothesis: This hypothesis suggests that all the humans perceive all the words in their memory without any internal morphological structure. So, words like a tire, tiring, tired are all stored separately in a mental lexicon.
Minimum Redundancy Hypothesis: This hypothesis proposes that only a raw form of the words (morphemes. form a part of the mental lexicon. When humans are process a word like tired, they recall both morphemes (tire-d..
46. What is a sequence learning?
Ans:
Sequence learning is the method of learning where both the input and output are sequences.
47. What is a NLTK?
Ans:
NLTK is the Python library, which stands for Natural Language Toolkit. And use a NLTK to process data in human spoken languages. NLTK allows us to apply techniques like parsing, tokenization, lemmatization, stemming, and more to understand a natural languages. It helps in categorizing a text, parsing linguistic structure, analyzing documents, etc.
48. What is a Syntactic Analysis?
Ans:
Syntactic analysis is the technique of analyzing sentences to extract a meaning from it. Using a syntactic analysis, a machine can analyze and understand order of words arranged in the sentence. NLP employs grammar rules of language that helps in a syntactic analysis of the combination and order of words in a documents.
49. What is a Semantic Analysis?
Ans:
Semantic analysis helps to make a machine understand meaning of a text. It uses a various algorithms for an interpretation of words in sentences. It also helps to understand a structure of a sentence.
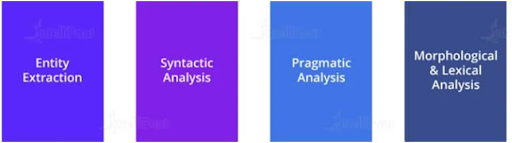
50. List the components of a Natural Language Processing?
Ans:
51. What is a Latent Semantic Indexing (LSI.?
Ans:
Latent semantic indexing is the mathematical technique used to improve a accuracy of the information retrieval process. The design of a LSI algorithms allows machines to detect hidden (latent. correlation between the semantics (words.. To enhance an information understanding, machines generate different concepts that associate with a words of a sentence.
52. What is a Regular Grammar?
Ans:
Regular grammar is used to represent the regular language:
A regular grammar comprises rules a form of A -> a, A -> aB, and many more. The rules help detect and analyze strings by an automated computation.
- ‘N’ is used to represent a non-terminal set.
- ‘∑’ represents a set of terminals.
- ‘P’ stands for a set of productions.
- ‘S € N’ denotes a start of non-terminal.
53. What is Parsing in a context of NLP?
Ans:
Parsing in NLP refers to understanding of a sentence and its grammatical structure by machine. Parsing allows machine to understand the meaning of a word in the sentence and the grouping of words, phrases, nouns, subjects, and objects in sentence. Parsing helps to analyze the text or the document to extract a useful insights from it.
54. Define terminology in NLP?
Ans:
The interpretation of a Natural Language Processing depends on a various factors.
55. Explain the Dependency Parsing in NLP?
Ans:
Dependency parsing helps assign the syntactic structure to a sentence. Therefore, it is also called a syntactic parsing. Dependency parsing is one of a critical tasks in NLP. It allows analysis of a sentence using parsing algorithms. Also, by using a parse tree in dependency parsing, we can check grammar and analyze a semantic structure of a sentence.
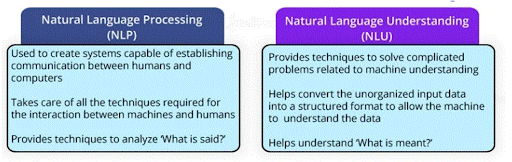
56. What is the difference between the NLP and NLU?
Ans:
57. What is a Pragmatic Analysis?
Ans:
Pragmatic analysis is the important task in NLP for interpreting knowledge that is lying outside the given document. The aim of implementing pragmatic analysis is to focus on be exploring a various aspect of the document or text in a language. This requires the comprehensive knowledge of a real world. The pragmatic analysis allows a software applications for a critical interpretation of the real-world data to know the actual meaning of the sentences and words.
Example:
Consider this is sentence: ‘Do know what time it is?’
LThis sentence can either be asked for a knowing time or for yelling at someone to make them note a time. This depends on a context in which and use the sentence.
58. What are theunigrams, bigrams, trigrams, and n-grams in NLP?
Ans:
When parse a sentence one word at time, then it is called a unigram. The sentence parsed a two words at a time is a bigram.
When a is parsed three words at a time, then it is a trigram. Similarly, n-gram refers to a parsing of n words at a time.
59. What are steps involved in solving an NLP problem?
Ans:
- Gather a text from the available dataset or by a web scraping.
- Apply stemming and lemmatization for a text cleaning.
- Apply feature of engineering techniques.
- Embed using a word2vec.
- Train a built model using a neural networks or other Machine Learning techniques.
- Evaluate a model’s performance.
- Make appropriate changes in a model.
- Deploy a model.
60. What is a Feature Extraction in NLP?
Ans:
Features or characteristics of the word help in text or document analysis. They also help in a sentiment analysis of a text. Feature extraction is one of techniques that are used by a recommendation systems. Reviews such as an ‘excellent,’ ‘good,’ or ‘great’ for a movie are positive reviews, recognized by the recommender system. The recommender system also tries to the identify the features of a text that help in describing the context of a word or sentence. Then, it makes a group or category of words that have some general characteristics. Now, whenever a new word arrives, a system categorizes it as per labels of such groups.
61. What is a precision and recall?
Ans:
The metrics used to test NLP model are precision, recall, and F1. Also and use accuracy for evaluating a model’s performance. The ratio of prediction and desired output yields the accuracy of model.
Precision is a ratio of true positive instances and total number of a positively predicted instances.
62. What is F1 score in a NLP?
Ans:
F1 score evaluates a weighted average of recall and precision. It considers a both false negative and false positive instances while evaluating the model. F1 score is a more accountable than accuracy for an NLP model when there is uneven distribution of class.
63. How to tokenize a sentence using a nltk package?
Ans:
Tokenization is the process used in NLP to split a sentence into a tokens. Sentence tokenization refers to splitting the text or paragraph into sentences.
For tokenizing, and will import sent_tokenize from a nltk package:
- from nltk.tokenize import sent_tokenize
64. Explain how can do parsing?
Ans:
Parsing is a method to identify and understand the syntactic structure of the text. It is done by analyzing an individual elements of the text. The machine parses are text one word at a time, then two at a time, further three, and so on.
- When a machine parses a text one word at a time, then it is a unigram.
- When the text is parsed two words at time, it is bigram.
- The set of words is the trigram when the machine parses three words at time.
65. Explain a Stemming with help of an example?
Ans:
In a Natural Language Processing, stemming is a method to extract the root word by removing the suffixes and prefixes from a word.
- For example can reduce ‘stemming’ to ‘stem’ by removing a ‘m’ and ‘ing.’
- Use a various algorithms for implementing stemming, and one of them is a PorterStemmer.
- Will import a PorterStemmer from a nltk package.
- From a nltk.stem import PorterStemmer.
Creating an object for the PorterStemmer
- pst=PorterStemmer(.
- pst.stem(“running”., pst.stem(“cookies”., pst.stem(“flying”.
- Output:
- (‘run’, ‘cooki’, ‘fly’ .
66. Explain a Lemmatization ?
Ans:
In lemmatization, rather than a just removing a suffix and the prefix, a process.Tries to find out a root word with its proper meaning.
67.Explain Named an Entity Recognition by implementing it?
Ans:
Named Entity Recognition (NER. is the information retrieval process. NER helps classify named an entities such as a monetary figures, location, things, people, time, and more. It allows software to analyze and understand a meaning of the text. NER is mostly used in a NLP, Artificial Intelligence, and Machine Learning. One of real-life applications of NER is a chatbots used for customer support. Let’s implement NER using a spacy package.
68. How to check a word similarity using the spacy package?
Ans:
To find out a similarity among words, use a word similarity. And evaluate the similarity with help of a number that lies between 0 and 1. We use a spacy library to implement technique of word similarity.
69. List some open-source libraries for a NLP?
Ans:
The popular libraries are the NLTK (Natural Language ToolKit., SciKit Learn, Textblob, CoreNLP, spaCY, Gensim.
70. Explain a masked language model?
Ans:
Masked modeling is an example of an autoencoding language modeling. Here output is predicted from a corrupted input. By this model, can predict a word from other words present in a sentences.
71.What is a bag of words model?
Ans:
The Bagofwords model is used for an information retrieval. Here a text is represented as a multiset, i.e., a bag of a words. don’t consider a grammar and word order, but surely maintain a multiplicity.
72. What are features of a text corpus in NLP?
Ans:
- Word count.
- Vector notation.
- Part of speech tag.
- Boolean feature.
- Dependency grammar.
73. What is named an entity recognition (NER.?
Ans:
Named Entity Recognition is the part of information retrieval, a method to locate and classify a entities present in an unstructured data provided and convert them into a predefined categories.
74.What is NLP pipeline, and what does it consist of?
Ans:
- Gathering a text, whether it’s from web scraping or use of available datasets
- Cleaning text
- Representation of a text
- Word embedding and sentence representation
- Training a model
- Evaluating a model
- Adjusting a model, as needed
- Deploying a model
75. What is “stop” word?
Ans:
Articles such as “the” or “an,” and other filler words that bind a sentences together (e.g., “how,” “why,” and “is”. but don’t offer more additional meaning are often referred to as a “stop” words. In order to get to a root of a search and deliver a most relevant results, search engines routinely filter out stop words.
76. What is a “term frequency-inverse document frequency?
Ans:
Term frequency-inverse a document frequency (TF-IDF. is an indicator of how important a given word is in the document, which helps identify key words and assist with process of feature extraction for the categorization purposes. While “TF” identifies how frequently given word or phrase (“W”. is used, “IDF” measures its importance within a document.
77. What is a perplexity? What is its place in a NLP?
Ans:
Perplexity is a way to express the degree of confusion a model has in predicting. More entropy = more confusion. Perplexity is used to be evaluate language models in a NLP. A good language model assigns the higher probability to a right prediction.
78. What is problem with ReLu?
Ans:
- Exploding a gradient.
- Dying ReLu — No learning if an activation is 0.
- Mean and variance of a activations is not 0 and 1.
79. What is difference between the learning latent features using SVD and getting embedding vectors using deep network?
Ans:
SVD uses a linear combination of inputs while a neural network uses a non-linear combination.
80. What is difference between an hapax and an hapax legomenon?
Ans:
Hapaxes are unusual words that only appear once in sample text or corpus. Each one is referred to as a hapax or hapax legomenon (‘read-only once’ in Greek.. It’s also known as singleton.
81.In NLP, what is a stemming?
Ans:
Stemming is a process of extracting the root word from given term. With efficient and well-generalized principles, all the tokens may be broken down to retrieve a root word or stem. It’s a rule-based system that’s well-known for is ease of use.
82. What are tricks used in ULMFiT?
Ans:
- LM tuning with a task text.
- Weight dropout.
- Discriminative learning rates for layers.
- Gradual unfreezing of layers.
- Slanted triangular learning rate schedule.
83. What are differences between a GPT and BERT?
Ans:
| GPT | BERT |
|---|---|
| GPT is not a bidirectional and has no concept of a masking. | BERT adds next sentence prediction task in a training and so it also has segment embedding. |
84.Define a Dependency Parsing?
Ans:
Dependency parsing is the technique for understanding grammatical structure by highlighting a relationships between its components. It investigates how the words of phrase are related linguistically. Dependencies are names given to these connections.
85. What is a Language modeling ?
Ans:
A statistical language model is the probability distribution over sequences of a words. Given such a sequence, say of a length m, it assigns a probability to a whole sequence. The language model provides a context to distinguish between the words and phrases that sound similar.
86. What is a Latent semantic analysis ?
Ans:
Latent semantic analysis is the technique in natural language processing, in a particular distributional semantics, of analyzing relationships between a set of a documents and the terms they contain by producing a set of concepts related to a documents and terms.
87. What is a Fasttext?
Ans:
FastText is the library for learning of word embeddings and a text classification created by Facebook’s AI Research lab. The model allows to create a unsupervised learning or supervised learning a algorithm for obtaining vector representations for a words.
88. What is a POS tagging?
Ans:
POS tagging, or parts of a speech tagging, is basis for identifying individual words in document and classifying them as part of speech based on their context. Because it entails analyzing a grammatical structures and selecting an appropriate component, POS tagging is also known as a grammatical tagging.
89. Define and implement a named entity recognition?
Ans:
For retrieving information and identifying entities present in a data for instance location, time, figures, things, objects, individuals, etc. NER (named entity recognition. is used ina AI, NLP, machine learning, implemented for making software understand what a text means.
90. What is significance of TF-IDF?
Ans:
tf–idf or TFIDF stands for a term frequency–inverse document frequency. In a information retrieval TFIDF is the numerical statistic that is intended to reflect a how important a word is to a document in the collection or in a collection of a set.
91. What is a Named Entity Recognition(NER.?
Ans:
Named entity recognition is the method to divide a sentence into categories. Neil Armstrong of an US had landed on the moon in a 1969 will be categorized as a Neil Armstrong- name; The US – country;1969 – time(temporal token..
The idea behind a NER is to enable the machine to pull out entities like the people, places, things, locations, monetary figures, and more.
92. Explain briefly about a word2vec?
Ans:
Word2Vec embeds words in the lower-dimensional vector space using shallow neural network. The result is a set of a word-vectors where vectors close together ina vector space have same meanings based on context, and word-vectors distant to each other have a differing meanings.
For example, apple and orange would be close together and apple and gravity would be a relatively far. There are the two versions of this model based on a skip-grams (SG. and continuous-bag-of-words (CBOW..
93. What are 5 steps in NLP?
Ans:
The five phases of a NLP involve lexical (structure. analysis, parsing, semantic analysis, discourse integration, and pragmatic analysis. Some well-known application areas of a NLP are Optical Character Recognition (OCR., Speech Recognition, Machine Translation, and Chatbots.
94. What is main challenges of NLP?
Ans:
There are enormous ambiguity exists when processing a natural language. 4. Modern NLP algorithms are based on a machine learning, especially statistical machine learning.
95. Which NLP model gives a best accuracy amongst following?
Ans:
Naive Bayes is a most precise model, with a precision of 88.35%, whereas Decision Trees have precision of 66%.
96. How many components of a NLP are there?
Ans:
Five main Component of Natural Language processing in an AI are: Morphological and Lexical Analysis. Syntactic Analysis. Semantic Analysis.
97. What is a NLP example?
Ans:
Email filters are one of most basic and initial applications of NLP online. It started out with a spam filters, uncovering certain words or phrases that signal spam message. The system recognizes if emails belong in one of a three categories (primary, social, or promotions. based on their contents.
98. Who uses a NLP?
Ans:
Interest in a NLP grew in the late 1970s, after a Bandler and Grinder began marketing the approach as a tool for the people to learn how others achieve success. Today, NLP is used in the wide variety of fields, including counseling, medicine, law, business, a performing arts, sports, the military, and education.
99.Why is a neurolinguistics important?
Ans:
Neurolinguistics is important because it studies a mechanisms in the brain that control the acquisition, comprehension, and production of language.
100. How can data for a NLP projects be obtained?
Ans:
There are several methods for an obtaining data for NLP projects. The following are a few:
- Using publicly accessible datasets: Datasets for a NLP may be found on sites such as a Kaggle and Google Datasets.
- Using data augmentation: This technique produces a new datasets from a current ones.