
- DBMS Interview Questions and Answers [ TO GET HIRED ]
- 50+ Best Neo4j Interview Questions and Answers
- PostgreSQL Interview Questions and Answers [ SOLVED ]
- 50+ Best Couchbase Interview Questions
- NoSQL Interview Questions and Answers [BEST & NEW]
- MySQL DBA Interview Questions and Answers
- SQL Query Interview Questions and Answers
- Teradata Interview Questions and Answers
- Hibernate Interview Questions and Answers
- Data Modeling Interview Questions and Answers
- Apache Solr Interview Questions and Answers
- DB2 Interview Questions and Answers
- SQL Interview Questions and Answers
- MongoDB Interview Questions and Answers
- SQL Server DBA Interview Questions and Answers
- DBMS Interview Questions and Answers [ TO GET HIRED ]
- 50+ Best Neo4j Interview Questions and Answers
- PostgreSQL Interview Questions and Answers [ SOLVED ]
- 50+ Best Couchbase Interview Questions
- NoSQL Interview Questions and Answers [BEST & NEW]
- MySQL DBA Interview Questions and Answers
- SQL Query Interview Questions and Answers
- Teradata Interview Questions and Answers
- Hibernate Interview Questions and Answers
- Data Modeling Interview Questions and Answers
- Apache Solr Interview Questions and Answers
- DB2 Interview Questions and Answers
- SQL Interview Questions and Answers
- MongoDB Interview Questions and Answers
- SQL Server DBA Interview Questions and Answers

NoSQL Interview Questions and Answers [BEST & NEW]
Last updated on 03rd Aug 2022, Blog, Database, Interview Question
1. What’s NoSQL?
Ans:
NoSQL encompasses a good kind of completely different info technologies that were developed in response to an increase within the volume of knowledge kept regarding users, objects, and merchandise. The frequency during which this information is accessed, and performance and process desires. relative databases, on the other hand, weren’t designed to address the dimensions and legality challenges that face fashionable applications, nor were they engineered to require advantage of a budget storage and process power on the market nowadays.
2.Comparison Between NoSQL & RDBMS ?
Ans:
NoSQL is completely different from RDBMS within the following manner:
- Criteria NoSQL RDBMS
- Scalability Very Good Average
- Querying Limited as no be a part of Clause Using SQL
- Storage mechanism Key-Value try, document, column storage, etc. information & relationship keep in numerous tables
3. What are the options of NoSQL?
Ans:
When compared to relative databases, NoSQL databases ar additional ascendable and supply superior performance, and their information model addresses many problems that the relative model isn’t designed to handle :
- Large volumes of structured, semi-structured, and unstructured information.
- Agile sprints, fast iteration, and frequent code pushes.
- Object-oriented programming that’s straightforward to use and versatile.
- Efficient, scale-out design rather than expensive , monolithic design.
4.Make a case for the distinction between NoSQL v/s relative database?
Ans:
The history looks to seem like this :
Google desires a storage layer for its inverted search index. They figure a standard RDBMS isn’t planning to cut it. so that they implement a NoSQL information store, BigTable, on prime of their GFS classification system. The key half is that thousands of low-cost artifact hardware machines give speed and redundancy. everybody else realizes what Google simply did. Brewer’s CAP theorem is proved . All RDBMS systems of use are CA systems. individuals begin wiggling with CP and AP systems yet. K/V stores are immensely less complicated, so that they are the first vehicle for the analysis.
Software-as-a-service systems, in general, don’t give associate degree SQL-like stores. Hence, individuals get additionally fascinated by the NoSQL kind stores. I feel a lot of the take-offs are often associated with this history. Scaling Google took some new ideas at Google and everybody else follows suit as a result of this is often the sole resolution they grasp to the scaling downside right away. Hence, you’re willing to transform everything around the distributed info plan of Google as a result of its sole thanks to scale on the far side of a particular size. Get to grasp additional information regarding this NoSQL vs. SQL – what’s Better? that may assist you grow in your career.
5.A way to script NoSQL sound unit configuration?
Ans:
These are as amenable to scripting as the other UNIX operating system commands and can not be mentioned additional here.The interactive commands on the market in java -jar kvstore.jar runadmin, among those accustomed to produce and execute plans, are often written in 2 ways in which. you’ll produce a file containing the sequence of commands that you just need to run, and run them in a very batch mistreatment java -jar kvstore.jar runadmin load -file .For example, a script file named deploy.kvs might contain commands like the subsequent :
- configure – name mystore
- plan deploy- datacenter -name Beantown -rf three -wait
- plan deploy-sn -dcname Beantown -host localhost -port 5000 -wait
- plan deploy-admin -sn sn1 -port 5001 -wait
- You could execute this script by supplying the command
- deploy.kv
6. Will NoSQL information act With Oracle Database?
Ans:
NoSQL information supports retrieving records through the Oracle information External Table functions. This makes it potential to perform some queries from Oracle information and retrieve records from NoSQL information.
7. What’s a prophetess knowledge Model?
Ans:
Cassandra knowledge model consists of 4 main components:
Cluster : created of multiple nodes and keyspaces
Keyspace : A namespace to cluster multiple column families, particularly one per partition
8. What are the benefits and downsides of NoSQL?
Ans:
Advantages of NoSQL :
- Using the new node ideas, the information of NoSQL is enlarged to the set limit. Low trade goods hardware takes now as an extra advantage.
- NoSQL databases are wont to store an enormous volume of knowledge. massive knowledge and recently announced user reviews utilize the thought of NoSQL.
- There is no expensive administration needed to observe the information of NoSQL.
- NoSQL is put in with a low cost economy rather than pin money on sophisticated systems.
Disadvantages of NoSQL :
- Since NoSQL could be a new technology of information storage, there are several different systems within the market that are already leading within the market.
- The antecedently designed systems have the support offered around the clock, however the NoSQL network is a smaller amount relatively.
- Since NoSQL could be a new technology, it’s not supporting the recent commands that are employed in the system.
9. Enlist variations between SQL and NoSQL databases?
Ans:
Differences between SQL and NoSQL databases :
While NoSQL databases scale horizontally, SQL databases scale vertically. While NoSQL databases are document, key-value, graph, or wide-column stores, SQL databases are table-based. While NoSQL databases are better for unstructured data like documents or JSON, SQL databases are superior for multi-row transactions.
10. What’s the CAP theorem? However, is it applicable to NoSQL systems?
Ans:
The CAP theorem was planned by Eric Brewer in early 2000. In this, 3 system attributes are mentioned inside the distributed databases. That is :
Consistency – during this, all the nodes see identical knowledge at identical times.
Availability – It offers North American nations a guarantee that there’ll be a response for each request created to the system regarding whether or not it absolutely was roaring or not.
Partition tolerance – it’s the standard of the NoSQL management system that states that the system can work even though an area of the system has failed or isn’t operating.
11. What differing types of NoSQL Databases are you aware of?
Ans:
There are four most typical kinds of NoSQL databases as below :
- Key-value databases
- Document databases
- Wide-column or Column-family databases
- Graph databases stores
12. What’s DocumentDB?
Ans:
DocumentDB or Document information could be a fully NoSQL information service that stores the info as schema-free JSON (JavaScript Object Notation) documents.You also would like measurability, low price and quick readying for your knowledge. altogether these situations we have a tendency to think about DocumentDB. There are several DocumentDB services as below.
- Microsoft Azure Cosmos decibel
- Amazon DocumentDB
- MongoDB
13. What are the foremost challenges with ancient RDBMS?
Ans:
Following ar a number of the foremost challenges with RDBMS systems :
Not optimized to scale out : RDBMS systems don’t seem to be optimized for horizontal scaling out.
Not ready to handle unstructured knowledge : RDBMS systems don’t seem to be able to handle schema-less knowledge (semi-structured or unstructured)
Costly : there’s a high licensing price for knowledge analysis with RDBMS systems.
Not able to handle the high speed {of knowledge|of knowledge|of information} bodily process :
- RDBMS systems are designed for steady data retention.
- The NoSQL systems evolved to beat all the on top of challenges.
14.However will NoSQL relate to massive data?
Ans:
NoSQL databases are designed with “Big Data” in mind. Since a hard and fast schema model doesn’t bind them, this makes them appropriate for today’s business wants wherever there’s an oversized volume of non-uniform knowledge (Big Data).
15. What’s Document information in NoSQL?
Ans:
Collection
16. Once ought to I exploit NoSQL info rather than a relative database?
Ans:
Relational databases enforce ACID. So, you may have schema based mostly dealing orientated knowledge stores. It’s established and appropriate for ninety nine of the $64000 world applications. you’ll be able to do much with relative databases.
But, there are unit limitations on speed and scaling once it involves large high accessibility knowledge stores. as an example, Google and Amazon have terabytes {of knowledge|of knowledge|of information} kept in massive data centers. Querying and inserting isn’t performant in these situations thanks to the blocking/schema/transaction nature of the RDBMs. That’s the explanation they need to enforce their own databases (actually, key-value stores) for enormous performance gain and measurability.
If you wish a NoSQL decibel you always realize it, potential reasons are:
- client needs ninety nine.999% accessibility on a high traffic website.
- your knowledge makes no sense in SQL, you discover yourself doing multiple be a part of queries for accessing some piece of knowledge.
- you are breaking the relative model, you have got CLOBs that store denormalized knowledge and you generate external indexes to look at that knowledge.
17. Make a case for distinction between scaling horizontally and vertically for databases?
Ans:
- In a info world horizontal-scaling is commonly supported the partitioning of the info i.e. every node contains solely a part of the info, in vertical-scaling the info resides on one node and scaling is completed through multi-core i.e. spreading the load between the computer hardware and RAM resources of that machine.
- Good samples of horizontal scaling are unit prophetess, MongoDB, Google Cloud hand tool. and a decent example of vertical scaling is MySQL – Amazon RDS (The cloud version of MySQL).
- Horizontal scaling means you scale by adding additional machines into your pool of resources whereas.
- Vertical scaling means you scale by adding additional power (CPU, RAM) to associate existing machines.
18. Once ought to we have a tendency to enter one document among another in MongoDB?
Ans:
You should take into account embedding documents for:
- contains relationships between entities
- One-to-many relationships
- Performance reasons
19. However, do I perform the SQL part equivalent in MongoDB?
Ans:
Mongo isn’t a on-line database, and therefore the devs area unit being careful to advocate specific use cases for $lookup, however a minimum of as of three.2 doing be a part of is currently potential with MongoDB. The new $lookup operator added to the aggregation pipeline is basically similar to a left outer be a part of it.
20. However will column-oriented NoSQL take issue from document-oriented?
Ans:
The main distinction is that document stores (e.g. MongoDB and CouchDB) enable every which way complicated documents, i.e. subdocuments among subdocuments, lists with documents, etc. whereas column stores (e.g. prophetess and HBase) solely enable a hard and fast format, e.g. strict one-level or two-level dictionaries.
For Example :
A document-oriented info (like MongoDB) inserts whole documents (typically JSON), whereas in prophetess (column-oriented db) you’ll be able to address individual columns or supercolumns, and update these one by one, i.e. they work on a special level of coarseness. every column has its own separate timestamp/version (used to reconcile updates across the distributed cluster).
21. What’s Sharding in MongoDB?
Ans:
Sharding could be a methodology for storing knowledge across multiple machines. MongoDB uses sharding to support deployments with terribly giant knowledge sets and high outturn operations.
22. Once ought to I exploit NoSQL info rather than a relative database?
Ans:
- Relational databases enforce ACID. So, you’ll have schema based mostly dealing homeward-bound knowledge stores. It’s verified and appropriate for ninety nine of the important world applications. you’ll be able to do much with relative databases.
- But, there square measure limitations on speed and scaling once it involves large high convenience knowledge stores. for instance, Google and Amazon have terabytes {of knowledge|of knowledge|of information} hold on in huge data centers. Querying and inserting isn’t performant in these situations thanks to the blocking/schema/transaction nature of the RDBMs.
- If you would like a NoSQL sound unit you always realize it, attainable reasons square measure :
- Clients need ninety nine.999% convenience on a high traffic website.
- Your knowledge makes no sense in SQL, you discover yourself doing multiple be a part of queries for accessing some piece of knowledge.
- You are breaking the relative model, you have got CLOBs that store denormalized knowledge and you generate external indexes to look at that knowledge.
23. What square measures the varied classes On Nosql?
Ans:
The various classes on NOSQL :
- KeyValue Store info
- Column Family info
- Document Store info
- Graph info
- Multivalue info
- Object info
- Triple Store info
- Tuple Store info
- Tabular info
24. The way to script NoSQL sound unit configuration?
Ans:
You may realize that you simply need to make a similar NoSQL sound unit configuration repeatedly for testing functions. The Admin command line interface commands will be written in many ways that.Many uses of the Admin command line interface square measure straightforward commands, like java -jar kvstore.jar makebootconfig to at the start piece a StorageNode, shown on top of.
These square measures are as amenable to scripting as the other UNIX commands and can not be mentioned more here.The interactive commands out there in java -jar kvstore.jar runadmin, among that square measure those wont to produce and execute plans, will be written in 2 ways that.
- configure -name mystore
- plan deploy-datacenter -name Hub of the Universe -rf three -wait
- plan deploy-sn -dcname Hub of the Universe -host localhost -port 5000 -wait
- plan deploy-admin -sn sn1 -port 5001 -wait
- You could execute this script by provision the command
- deploy.kvs
25. List the various varieties of NoSQL knowledge stores?
Ans:
The four varieties of no SQL knowledge storage square measure normally accessible or divided into four classes. they’re as follows :
Key-value store – A key-value store could be a basic knowledge storage key system that uses a key to access numerous values.
Column family store – It’s a distributed system of weights and measures with column family storage. The keys square measure columns and rows.
Graph store – The graph store is employed for managing things that require plenty of relationships.
Document store – document stores square measure wont to store stratified knowledge structures within the info directly.
26. What precisely is that the goal of NoSQL?
Ans:
Non-structured knowledge will be kept in NoSQL databases. The NoSQL info could be novel thanks to storing massive datasets. Once it involves storing matter knowledge, NoSQL could be a viable difference to SQL databases.
27. What area unit The professionals And Cons Of Graph Database?
Ans:
Pros : Graph databases seem to be custom-made for networking applications. The archetypal example could be a social community, during which nodes represent users WHO have numerous sorts of relationships to each alternative. Modeling this kind of fact victimization of any of the opposite patterns is commonly a tricky match, however a graph of information would possibly take delivery of it with savor. they’re conjointly excellent suits for associate item-oriented machines.
Cons : Because of the high certification of interconnection among nodes, graph databases are sometimes not acceptable for community partitioning. Graph databases don’t scale out well.
28. What’s NoSQL information design ?
Ans:
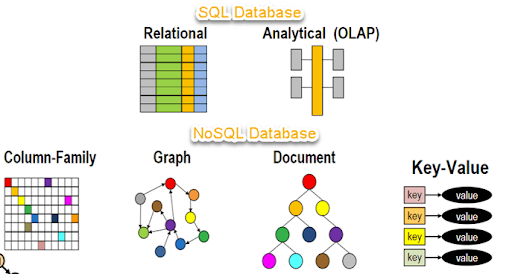
29. Justify however Cassandra Writes?
Ans:
Cassandra writes 1st to a commit go online disk for durability then commits to associate in reminiscence form called a memtable. A write could be a success as long as every commit is complete. Writes are unit batched in memory associated with written to disk in an exceedingly table form remarked as an SSTable (looked when string desk). Memtables and SSTables area unit created in line with column family. With this layout Cassandra has minimum disk I/O and offers excessive pace write performance as a result of the commit log is appendbest and Cassandra doesn’t try to seek out on writes. within the occasion of a fault while writing to the SSTable Cassandra will truly replay the commit log.
30. What’s The Key Distinction Between Replication And Sharding?
Ans:
Replication takes the identical knowledge and copies it over multiple nodes. Sharding puts specific statistics on totally different nodes. Sharding is particularly precious for overall performance because of the actual fact it will enhance every examination and write overall performance. victimization replication, notably with caching, will greatly enhance examine performance but will do very little for packages that have an entire heap of writes.
31.Justify regarding Cassandra NoSQL?
Ans:
Cassandra is an open offer scalable and very accessible “NoSQL” distributed direction machine from Apache. Cassandra claims to supply fault-tolerant linear quantifiability and not use one issue of failure. Cassandra sits inside the ColumnFamily NoSQL camp.The Cassandra statistics version is meant for large-scale distributed statistics and trades ACID-compliant records practices for overall performance and accessibility. Cassandra is optimized for very speedy and notably hard writes. Cassandra is written in Java and will run on an intensive array of operating systems and platforms.
32. Justify Cassandra knowledge Model?
Ans:
The Cassandra facts version has the four most significant concepts which might be a cluster, keyspace, column, column family. Clusters embrace several nodes (machines) and will incorporate over one keyspace. A keyspace could be a namespace to establish a few column families, usually one to keep with the appliance. A column includes a decision, fee, and timestamp. A column’s family includes a few columns documented by employing a row key.
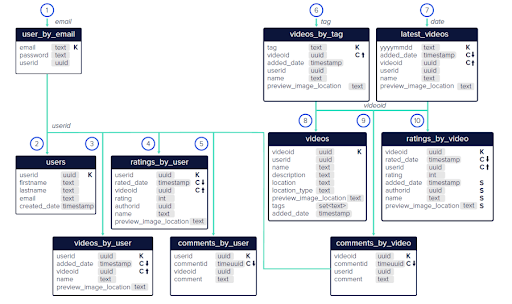
33.Justify however Cassandra Writes?
Ans:
Cassandra writes initially to a commit go online disk for durability then commits to associate degree in reminiscence form referred to as an unforgettable. A write may be a success as shortly as every commit is complete. Writes are batched in memory associate degreed written to disk in an exceedingly table form remarked as an SSTable (looked once string desk). Memtables and SSTables are created in line with the column’s family.With this layout, Cassandra has minimum disk I/O and offers excessive pace write performance as a result of the commit log is appendbest and Cassandra doesn’t attempt to search out on writes. within the occasion of a fault while writing to the SSTable Cassandra will really replay the commit log.
34.Understanding the distinction between Azure Cosmos decibel NoSQL and relational databases?
Ans:
35. What’s Flume?
Ans:
Flume is an associate degree ASCII text file code program developed with the help of the Cloud era that acts as a supplier for aggregating and moving massive quantities of records around a Hadoop cluster as a result of the records being made or shortly thenceforth. Its preferred use case is that the gathering of log documents from all of the machines in an exceedingly cluster to persist them in an exceedingly centralized keep beside HDFS.In Flume, we tend to produce record flows by means of increasing chains of logical nodes and connecting them to resources and sinks. As an example, say we tend to want to maneuver facts from associate degree Apache to get admission to log into HDFS. You produce a supply victimization queue, get admission to log associate degreed use a logical node to course this to an HDFS sink.
36. What’s Bigsql?
Ans:
Big knowledge is the fruit of various studies and development initiatives at IBM. IBM has taken the paintings from those various initiatives associate degreed discharged them as an era preview referred to as massive SQL.IBM claims that massive SQL offers durable SQL assist for the Hadoop atmosphere :
- It has a scalable structure
- It helps SQL and facts types to be had in SQL ’92, and it’s some additional capabilities
- It supports JDBC and ODBC patron drivers
- It has economical handling of “factor queries”
- Big SQL is predicated entirely on a multithreaded design, thus it’s smart for performance and also the quantifiability in an exceedingly massive SQL surroundings primarily depends on the Hadoop cluster itself; this can be its size and programming policies.
37. However massive Sql Works?
Ans:
The Big SQL engine analyzes incoming queries. It separates parts to execute at the server versus the parts to be dispensed by victimization of the cluster. It rewrites queries if essential for progressing overall performance? determines the right garage lookout for data? produces the execution arrangement and executes and coordinates the question.
IBM architected massive SQL with the goal that existing queries have to be compelled to run with no or few modifications which queries ought to be performed as effectively because the chosen storage mechanisms allow. And in preference to constructing a separate question execution infrastructure, they created massive SQL believe a decent deal on Hive, loads of the facts manipulation language, the facts definition language syntax, and also the overall standards of huge SQL ar almost like Hive. and massive SQL shares catalogs with Hive through the Hive metastore. therefore everybody will question each different table.
38. What’s “polyglot Persistence” In Nosql?
Ans:
Neal Ford coined the period polyglot programming, to precise the construct that applications ought to be written in an exceedingly mixture of languages to require advantage of the fact that totally different languages are appropriate for confronting one in all form issues. advanced packages integrate specific sorts of troubles, thus selecting the correct language for every task could also be more effective than seeking to suit all elements into one language.
Similarly, once performing on associate degree etrade business trouble, the usage of a facts store for the buying cart that is exceptionally out there and should scale is crucial, however identical records keep can’t assist you notice product offered by means of the customers’ buddies—which may be a whole exceptional question. We tend to use the period polyglot persistence to outline this hybrid technique to endurance.
39. What’s the trigger?
Ans:
Triggers are held on programs that get mechanically dead once an occurrence like INSERT, DELETE, AND UPDATE(DML) statement happens. Triggers also can be elicited in response to knowledge definition statements(DDL) and info operations, as an example, SERVER ERROR, LOGON.
40. What are the subsets of SQL?
Ans:
The following are the subsets of SQL :
DDL(Data Definition Language): Includes SQL commands like produce, ALTER, and DELETE.
DML(Data Manipulation Language): Accesses and manipulates information Uses INSERT, UPDATE commands.
DCL(Data management Language): Controls access to the info. Uses commands like GRANT and REVOKE.
41. What’s a Cross Join?
Ans:
In a SQL cross be a part of, a mixture of each row from the 2 tables is enclosed within the result set. this can be conjointly known as vector be a part of. for instance, if table A has 10 rows and table B has twenty rows, the result set can have ten * twenty = two hundred rows provided there’s an obscurity clause within the SQL statement.
42. What are the scalar functions in NoSQL? offer an associate degree example?
Ans:
Scalar Functions are accustomed to come back one worth supporting the input values. Scalar Functions ar as follows :
UCASE(): Converts the required field in capital
LCASE(): Converts the required field in lower-case letter

43. What’s a set-based solution?
Ans:
Cursors operate individual rows, and within the case of a group, it works on a resultant set of information, that may well be a table/view or a be a part of each. The resultant set is associate degree output of a SQL question.
44. What’s denormalization, and once does one opt for it?
Ans:
De-normalization may be a technique typically accustomed to improve performance that the table style permits redundant information to avoid complicated joins. If the application involves significant browser operations, then denormalization is employed at the expense of the write operations performance.
45. What’s a dealings log?
Ans:
A log is an associate degree audit path file wherever the history of actions dead by the software package is held on.
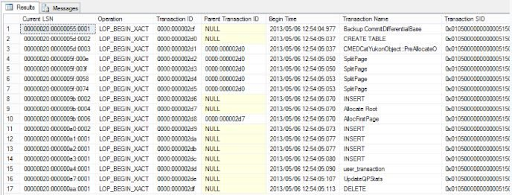
46. What are Object Privileges?
Ans:
An object-level privilege may be a permission granted to an info user account or role to perform some action on an info object. These object privileges embody choose, INSERT, UPDATE, DELETE, ALTER, INDEX on tables, and so on.
The following examples are object privileges that may be granted to users :
- c
- SELECT ON 60 minutes.employees TO myuser
- INSERT ON 60 minutes.employees TO myuser
47. What’s information integrity?
Ans:
Data integrity defines the accuracy, consistency, and responsibleness of information that’s held on within the info.There are four sorts of information integrity :
- Row integrity
- Column integrity
- Referential integrity
- User-defined integrity
48. However is information in a very NoSQL info stored?
Ans:
It depends on the sort of NoSQL info is employed. every info stores the info victimization completely different strategies like some use column store, some graphs, and a few documents, etc. Below is the clarification of every info and the way they store the info.
Graph stores : It stores the info within the sort of graphs.
Key-value stores : during this, every item holds on with an associate degree attribute name at the side of its worth. for instance Riak, Berkeley, etc.
Wide Column stores : information is held within the columns rather than rows. samples of such information stores are prophetess and HBase.
49. NoSQL Developer Skills?
Ans:
Here are some options to observe out for once trying to find associate degree older NoSQL developer :
- Should be able to install, configure, upgrade, and patch info package (MySQL cluster, Cassandra, MySQL, and Couchbase)
- Should be able to handle operations for each production and development databases
- Should be able to troubleshoot NoSQL issues and performance delays
- Should be able to build and put together monitors to line the health of servers and therefore the databases
- Should be able to develop, enforce, manage, and automatise the backup and recovery design as per necessities
50. Make a case for algorithmic hold on procedure?
Ans:
Stored procedure line itself till it reaches some precondition may be an algorithmic hold on procedure. It permits the programmers to use a group of code n variety of times.
51. What’s the hold on procedure?
Ans:
It is an operation consisting of the many SQL statements to access the info system. many SQL statements square measure consolidated into a hold on procedure and square measure dead where and whenever needed.
52. What’s ALIAS command?
Ans:
It will be utilized in wherever clause of a SQL question victimization as keyword.
Example : SELECT S.StudentID, E.Result from student S, examination as E wherever S.StudentID = E.StudentID
53. What square measure STUFF and REPLACE functions?
Ans:
Syntax :
REPLACE : replaces the present characters of all the occurrences.

Syntax :

54. However will dynamic SQL be executed?
Ans:
It will be dead by the subsequent ways in which :
- By capital punishment the question with parameters.
- By victimization EXEC
- By victimization sp_executesql
55. What’s the TRUNCATE command? However, is it totally different from the DELETE command?
Ans:
| DELETE | TRUNCATE |
|---|---|
| DML command DDL command | We can use wherever clause we will not use WHERE clause |
| Deletes a row from the table. Deletes all rows from the table. | We can rollback. we tend to not roll back. |
56. What square measures the various case manipulation functions in SQL?
Ans:
LOWER : Converts all the characters to minuscule.
UPPER : Converts all the characters to capital.
INITCAP : Converts initial character of every word to capital.
57. What square measures the character manipulation functions?
Ans:
Character manipulation functions alter, extract and alter the character string.
58. What square measures the various operators in SQL?
Ans:
- Arithmetic
- Comparison
- Logical
59. What’s the MERGE statement?
Ans:
The statement permits conditional updates or inserts into the table. It updates the row if it exists or inserts the row if it doesn’t exist.
60.Distinguish between BETWEEN and IN conditional operators?
Ans:

61. Why is NoSQL’s document-oriented information model a gorgeous choice?
Ans:
As data-sensitive organizations have moon-faced several data-related issues, therefore a brand new resolution has been introduced and also the answer is NoSQL Document Databases. it’s enticing to the users as a result of it keeps information in documents instead of rows and columns. Some minimum normal format rules should be followed by these documents. The format decisions may well be JSOS, XML, YAML, etc. The priority is usually JSON for NoSQL databases thanks to its higher compatibility and readability.
62. What’s the first key?
Ans:
A primary key constraint unambiguously identifies every row/record in a very information table. Primary keys should contain distinctive values. Null price and duplicate values aren’t allowed to be entered within the primary key column. A table will have just one primary key. It will incorporate single or multiple fields.
63. What square measures the options of MySQL?
Ans:
Here square measure a number of the vital options of MySQL :
- It is reliable and straightforward to use
- It supports normal SQL (Structured question Language)
- MySQL is secure because it consists of {a information|a knowledge|and information} security layer that protects sensitive data from unauthorized users
- MySQL incorporates a versatile structure and supports an oversized range of embedded applications
- It is one in all the in no time information languages
64. Make a case for the various styles of indexes in SQL?
Ans:
There square measure 3 styles of indexes in SQL :
Unique Index – It doesn’t permit a field to possess duplicate values if the column is exclusively indexed.
Clustered Index – This index defines the order during which information is physically kept in a very table. It reorders the physical order of the table and searches supported key values. There is just one clustered index per table.
Non-Clustered Index – It doesn’t type the physical order of the table and maintains a logical order of the information. every table will have quite one non-clustered index.
65. What’s a subquery in SQL? What square measures the various styles of a subquery?
Ans:
A subquery could be a question at intervals another question. Once there’s a question at intervals a question , the outer question is termed the most question, whereas the inner question is termed a subquery. There square measure 2 styles of a subquery :
Correlated subquery : It obtains values from its outer question before it executes. Once the subquery returns, it passes its results to the outer question.
Non-Correlated subquery : It executes several of the outer questions. The subquery executes 1st and so passes its results to the outer question. each inner and outer queries will run severally.
66. What’s collation sensitivity?
Ans:
Collation sensitivity defines the principles to type and compare the strings of character information, supporting correct character sequence, case-sensitivity, character dimension, and accent marks, among others.
67. Are you able to name differing types of MySQL commands?
Ans:
SQL commands square measure divided into the subsequent
- Data Definition Language (DDL)
- Data Manipulation Language (DML)
- Data management Language (DCL)
- Transaction management Language (TCL)
68. What’s info on relationships?
Ans:
An info Relationship is outlined because of the affiliation between 2 electronic database tables. The first table features a foreign key that references the first key of another table. There square measure 3 varieties of info Relationship :
- One-to-one
- One-to-many
- Many-to-many
69. Mention the command wont to revisit the privileges offered by the GRANT command?
Ans:
REVOKE command is employed to urge back the privileges offered by the GRANT command.
70. What square measures the variations between the ‘WHERE’ Clause and therefore the ‘HAVING’ Clause?
Ans:
Below square measure the most important variations between the ‘WHERE’ Clause and therefore the ‘HAVING’ Clause :
| WHERE Clause | HAVING Clause |
|---|---|
| It performs filtration on individual rows supporting the required condition. | HAVING clause performs filtration on teams supporting the required condition. |
| It is often used while not clustered BY Clause. | it’s invariably used with the cluster BY Clause. |
| WHERE Clause is applied in row operations. | HAVING is applied in column operations. |
| We cannot use the wherever clause with combination functions. | This clause works with combination functions. |
| WHERE comes before cluster BY HAVING comes when cluster BY. | HAVING comes when cluster BY. |
| This clause acts as a pre-filter. | The HAVING clause acts as a post-filter. |
| WHERE Clauses are often used with choose, INSERT, UPDATE, and DELETE statements. | This Clause will solely be used with the choose statement. |
71. A way to produce a table in SQL?
Ans:
- CREATE TABLE table_name (
- column1 datatype,
- column2 datatype,
- column3 datatype,
- ….
- );
72. A way to delete a table in SQL?
Ans:
There square measures 2 ways in which to delete a table from sql: DROP and TRUNCATE. The DROP TABLE command is employed to fully delete the table from the info. this can be the command :
DROP TABLE table_name; The higher than command can fully delete all the information gifts within the table together with the table itself.
73. What’s social control in SQL?
Ans:
Normalization is employed to decompose a bigger, complicated table into easy and smaller ones. This helps the US in removing all the redundant information.
Generally, in a table, we are going to have a great deal of redundant info that isn’t needed, therefore it’s better to divide this complicated table into multiple smaller tables that contain solely distinctive info.
74. A way to amend a table name in SQL?
Ans:
We will kick off by giving the keywords ALTER TABLE, then we are going to follow it up by giving the first name of the table, after that, we are going to surrender the keywords RENAME TO and eventually, we are going to offer the new table name.
For example: if we would like to vary the “employee” table to “employee_information”, this may be the command :
- ALTER TABLE worker
- RENAME TO employee_information;
75. A way to notice duplicate records in SQL?
Ans:
There square measures multiple ways in which to seek out duplicate records in SQL. Let’s see however will we discover duplicate records victimization groupby :
- SELECT
- x,
- y,
- COUNT(*) occurrences
- FROM z1
- GROUP BY
- x,
- y
- HAVING
- COUNT(*) > 1;
76. What square measures the advantages of TypeScript?
Ans:
Cursors in SQL square measure accustomed store information tables. There square measure 2 kinds of cursors :
- 1. Implicit pointer
- 2. specific pointer
Implicit pointer : These implicit cursors square measure default cursors that square measure mechanically created. A user cannot produce an associate degree implicit pointer.
Explicit pointer : Explicit cursors square measure user-defined cursors. this can be the syntax to make specific pointer :
DECLARE cursor_name pointer FOR choose * FROM table_name
We kick off by giving by keyword DECLARE, then we have a tendency to offer the name of the pointer, at the moment we have a tendency to offer the keywords pointer FOR choose * FROM, finally, we have a tendency to concede the name of the table.
77. A way to modify column data-type in SQL?
Ans:
We can modify the data-type of the column victimization of the alter table. this may be the command :
- ALTER TABLE table_name
- MODIFY COLUMN column_name datatype;
- We kick off by giving the keywords ALTER TABLE, then we are going to concede the name of the table. After that, we are going to concede the keywords MODIFY COLUMN. Going ahead, we are going to concede the name of the column {for that|that} we might need to vary information|the info|the information}type and at last we are going to concede the data kind to which we might need to vary.
78. However will dynamic SQL be executed?
Ans:
- By capital punishment the question with parameters
- By victimization executive department
- By victimization sp_executesql
79. What square measure the most variations between #temp tables and @table variables and that one is most popular ?
Ans:
- 1. SQL server will produce column statistics on #temp tables.
- 2. Indexes will be created on #temp tables
- 3. @table variables square measure keep in memory up to a precise threshold
80. What square measures the cons of a standard RDBMS over NoSQL systems?
Ans:
- The object-relational mapping layer will be complicated.
- Entity-relationship modeling should be completed before testing begins, that slows development.
- RDBMSs don’t scale out once joined square measure is needed.
- Sharding over several servers will be done however, needs application code and can be operationally inefficient.
- Full-text search needs third-party tools.
- function NoReturnType(): void
81.A way to produce a keep procedure in SQL Server?
Ans:
A keep Procedure is nothing however a ofttimes used SQL question. Queries like a pick question, which might usually be accustomed retrieve a collection of data repeatedly inside a information, will be saved as a leep Procedure. The keep Procedure, once referred to as, executes the SQL question save inside the keep Procedure.
Syntax to make a keep Proc :

82.A way to connect SQL Server management studio to the native information?
Ans:
- Launch the SQL Server Management Studio from the beginning menu.
- In the panel shown below, choose the Server sort as information Engine and Server Name because the name of your laptop/ desktop system and click on on the Connect button.
- Select the Authentication as ‘Windows Authentication.
- A secure affiliation would be established, and also the list of the on the market Databases are loaded within the Object person window pane.
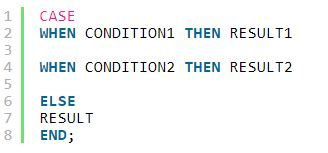
83. What’s the case once in SQL Server?
Ans:
Case once statements in SQL area unit accustomed run through several conditions and to come back a worth once one such condition is met. If none of the conditions is met within the once statements, then the worth mentioned within the Else statement is returned.
Syntax :
84. What’s thirty two bit nuances?
Ans:
There is further memory mapped file activity with journaling. This can further constrain the restricted dB size of thirty two bit builds. Thus, currently journaling by default is disabled on thirty two bit systems.
85. However long will the reproduction set failover take?
Ans:
It may take 10-30 seconds for the first to be declared down by the opposite members and a replacement primary non appointive. throughout this window of your time, the cluster is down for “primary” operations – that’s, writes and powerful consistent reads. However, you will execute eventually consistent queries to secondaries at any time (in slaveOk mode), as well as throughout this window.
86. A way to notice server name in SQL Server?
Ans:
Run the question choose @@version; to seek out the version and name of the SQL Server you’re exploiting.
87.A way to install SQL Server management studio ?
Ans:
Launch Google and within the Search toolbar, sort in SQL Server Management Studio’ transfer. move to the routed web site and click on the link to transfer. Once the transfer is complete, open the .exe file to put in the content of the file. Once the installation is complete, refresh or restart the system, as needed.
Alternatively, once SQL Server is put in and launched, it’ll prompt the user with an associate choice to launch SQL Server Management Studio.
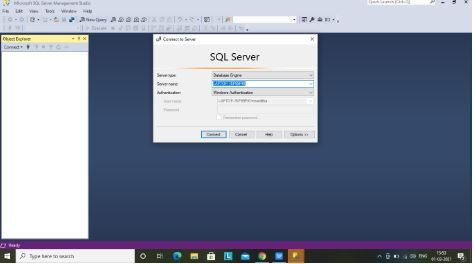
88. A way to connect SQL Server management studio to the native information?
Ans:
- Launch the SQL Server Management Studio from the beginning menu.
- In the panel shown below, choose the Server sort as information Engine and Server Name because the name of your laptop/ desktop system and click on on the Connect button.
- Select the Authentication as ‘Windows Authentication.
- A secure affiliation would be established, and also the list of the on the market Databases are loaded within the Object person window pane.
89. What’s cte in SQL Server?
Ans:
CTEs square measure Common Table Expressions that square measure accustomed produce temporary result tables from that knowledge are often retrieved/ used. the quality syntax for a CTE with a choose statement is :
- WITH RESULT AS
- (SELECT COL1, COL2, COL3
- FROM EMPLOYEE)
- SELECT COL1, COL2 FROM RESULT
- CTEs are often used with Insert, Update or Delete statements furthermore.
90. Distinction between RDBMS and NoSQL databases?
Ans:
Let’s think about an associate degree example of storing info about a couple of users and their hobbies. We’d like to store a user’s name, last name, cellular phone variety, city, and hobbies.
In a computer database, we’d probably produce 2 tables: one for Users and one for Hobbies.
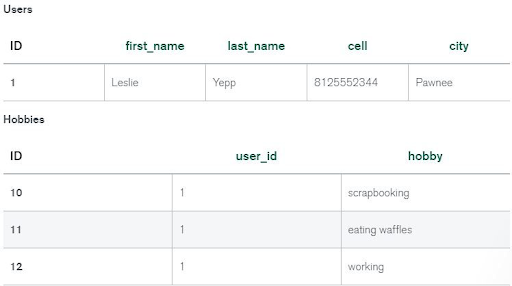
91. Justify NoSQL info misconceptions?
Ans:
Over the years, several misconceptions concerning NoSQL databases have unfolded throughout the developer community. during this section, we’ll discuss 2 of the foremost common misconceptions :
- Relationship knowledge is best fitted to relative databases.
- NoSQL databases don’t support ACID transactions.
92. What’s the ultimate consistency?
Ans:
Eventual consistency may be a property of distributed databases. Ultimate consistency ensures that once an associate degree update is formed to the info, eventually all nodes within the distributed info can replicate that update.
93. What language is employed to question NoSQL?
Ans:
NoSQL databases span a spread of sorts and implementations. As a result, NoSQL databases may be queried employing a type of question languages and arthropod genus. MongoDB, the world’s preferred NoSQL info, may be queried for exploitation of the MongoDB search language (MQL).
94. Will NoSQL have a schema?
Ans:
NoSQL databases usually have versatile schemas. Note that some NoSQL databases like MongoDB even have support for schema validation, thus developers will lock down their schemas the maximum amount or as very little as they’d like once they are prepared.
95. What information model will NoSQL use?
Ans:
NoSQL databases comprise four main classes or sorts. One factor they need in common is that they do not use the rigid tabular row-and-column information model that ancient relative databases (sometimes referred to as SQL databases) use.
Instead, NoSQL databases have an information model that reflects their explicit class. Document databases will store a good deal of data in a very single document and may nest documents. Key-value stores have a straightforward information model, even as their name implies. Wide column stores feature a lot of variation in information sorts and therefore the range of columns in use than row-oriented relative databases. Graph information bases have data models supported graph theory, with information models created from nodes and edges that relate those nodes
96. Is it troublesome to alter tables and relationships?
Ans:
Alteration of the relationships between tables or addition of a replacement table may have an effect on the present relations. This implies dynamically the schema.
Change of the schema would be like eliminating the present one and fashioning a replacement schema.
Addition of a replacement practicality would wish all the weather to support the new structure. modification is inevitable.
Example : every further column wants all the previous rows to own values for that column. Whereas in Cassandra (a NoSQL database), you’ll add a column to specific row partitions.
97. Justify RDBMS ACID properties of the information ?
Ans:
The ACID properties of an information area unit Atomicity, Consistency, Isolation and sturdiness.
Atomicity : associate “all or nothing” approach. If any statement within the dealings fails, the complete dealings is rolled back.
Consistency : The dealings should meet all protocols outlined by the system. No [*fr1] completed transactions.
Isolation : No dealings has access to the other dealings that’s in associate intermediate or unfinished state. Every deal is freelance.
Durability : Ensures that when a dealings commits to the information, it’s preserved through the utilization of backups and dealings logs.
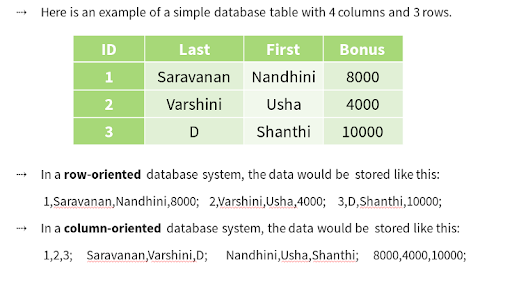
98. However, will columnar information store data?
Ans:
99. Why not use a spreadsheet?
Ans:
- It’s terribly convenient to use stand out for knowledge analysis if you merely ought to handle thousands of rows and tables. however once you get to concerning ten,000 rows, you’ll like an information system to trot out mammoth datasets. (Excel will quickly freeze up.
- If you’re operating for an organization that has tens of thousands of stand out spreadsheets – on completely different computers, say – and therefore the employees and customers ought to see knowledge over a period of time, it’s troublesome to harmonize your knowledge, particularly if many folks are in identical projects.
- Spreadsheets aren’t ideal for operating with multiple datasets in cycle.
100. What’s therefore special concerning NoSQL?
Ans:
- NoSQL databases are a speedier different as a result of, for one, you don’t ought to be a part of tables in NoSQL. Each piece of knowledge is kept in an exceedingly JSON format. and therefore the limitation of relative databases is that every item will solely contain one attribute. for example this time, inspect the higher than Fruit table and spot however every column is devoted to simply one live or attribute. Because of javascript, NoSQL permits you to store knowledge in an exceedingly nested fashion.
- NoSQL is additionally straightforward to use. You don’t have to trot out the “mismatch” between rows and columns. as an example, storing all the reviewer’s info in one document as against having to affix innumerous tables. In this manner, you write less code that, hopefully, means fewer errors.