
- 10 Best Data Analytics Tools for Big Data Analysis | Everything You Need to Know
- What is Azure Databricks | A Complete Guide with Best Practices
- Elasticsearch Nested Mapping : The Ultimate Guide with Expert’s Top Picks
- Various Talend Products and their Features | Expert’s Top Picks with REAL-TIME Examples
- What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- Introduction to HBase and Its Architecture | A Complete Guide For Beginners
- What is Azure Data Lake ? : Expert’s Top Picks | Everything You Need to Know
- What is Splunk Rex : Step-By-Step Process with REAL-TIME Examples
- What is Data Pipelining? : Step-By-Step Process with REAL-TIME Examples
- Dedup : Splunk Documentation | Step-By-Step Process | Expert’s Top Picks
- What Is a Hadoop Cluster? : A Complete Guide with REAL-TIME Examples
- Spark vs MapReduce | Differences and Which Should You Learn? [ OverView ]
- Top Big Data Challenges With Solutions : A Complete Guide with Best Practices
- Hive vs Impala | What to learn and Why? : All you need to know
- What is Apache Zookeeper? | Expert’s Top Picks | Free Guide Tutorial
- What is HDFS? Hadoop Distributed File System | A Complete Guide [ OverView ]
- Who Is a Data Architect? How to Become and a Data Architect? : Job Description and Required Skills
- Kafka vs RabbitMQ | Differences and Which Should You Learn?
- What is Apache Hadoop YARN? Expert’s Top Picks
- How to install Apache Spark on Windows? : Step-By-Step Process
- What is Big Data Analytics ? Step-By-Step Process
- Top Big Data Certifications for 2020
- What is Hive?
- Big Data Engineer Salary
- How Facebook is Using Big Data?
- Top Influencers in Big Data and Analytics in 2020
- How to Become a Big Data Hadoop Architect?
- What Are the Skills Needed to Learn Hadoop?
- How to Become a Big Data Analyst?
- How Big Data Can Help You Do Wonders In Your Business
- Essential Concepts of Big Data and Hadoop
- How Big Data is Transforming Retail Industry?
- How big Is Big Data?
- How to Become a Hadoop Developer?
- Hadoop Vs Apache Spark
- PySpark Programming
- 10 Best Data Analytics Tools for Big Data Analysis | Everything You Need to Know
- What is Azure Databricks | A Complete Guide with Best Practices
- Elasticsearch Nested Mapping : The Ultimate Guide with Expert’s Top Picks
- Various Talend Products and their Features | Expert’s Top Picks with REAL-TIME Examples
- What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- Introduction to HBase and Its Architecture | A Complete Guide For Beginners
- What is Azure Data Lake ? : Expert’s Top Picks | Everything You Need to Know
- What is Splunk Rex : Step-By-Step Process with REAL-TIME Examples
- What is Data Pipelining? : Step-By-Step Process with REAL-TIME Examples
- Dedup : Splunk Documentation | Step-By-Step Process | Expert’s Top Picks
- What Is a Hadoop Cluster? : A Complete Guide with REAL-TIME Examples
- Spark vs MapReduce | Differences and Which Should You Learn? [ OverView ]
- Top Big Data Challenges With Solutions : A Complete Guide with Best Practices
- Hive vs Impala | What to learn and Why? : All you need to know
- What is Apache Zookeeper? | Expert’s Top Picks | Free Guide Tutorial
- What is HDFS? Hadoop Distributed File System | A Complete Guide [ OverView ]
- Who Is a Data Architect? How to Become and a Data Architect? : Job Description and Required Skills
- Kafka vs RabbitMQ | Differences and Which Should You Learn?
- What is Apache Hadoop YARN? Expert’s Top Picks
- How to install Apache Spark on Windows? : Step-By-Step Process
- What is Big Data Analytics ? Step-By-Step Process
- Top Big Data Certifications for 2020
- What is Hive?
- Big Data Engineer Salary
- How Facebook is Using Big Data?
- Top Influencers in Big Data and Analytics in 2020
- How to Become a Big Data Hadoop Architect?
- What Are the Skills Needed to Learn Hadoop?
- How to Become a Big Data Analyst?
- How Big Data Can Help You Do Wonders In Your Business
- Essential Concepts of Big Data and Hadoop
- How Big Data is Transforming Retail Industry?
- How big Is Big Data?
- How to Become a Hadoop Developer?
- Hadoop Vs Apache Spark
- PySpark Programming

How to install Apache Spark on Windows? : Step-By-Step Process
Last updated on 27th Oct 2022, Artciles, Big Data, Blog
- In this article you will get
- 1.Introduction of Apache Spark
- 2.Prerequisites
- 3.Install Apache Spark on Windows
- 4.Conclusion
Introduction of Apache Spark
Apache Spark is associate open-supply framework that approaches massive volumes of movement data from a few sources. Spark is used in assigned computing with systems gaining information of applications, data analytics, and graph-parallel processes.
This manual can show you how to deploy Apache Spark on Windows ten and take a glance at the installation.
Prerequisites
- A device walking Windows ten.
- A person account with administrator privileges (required to place in software system, alter record permissions, and alter device PATH) electronic communication or Powershell.
- A device to extract .tar files, together with 7-Zip.
Install Apache Spark on Windows
Installing Apache Spark on Windows ten in addition |may also|may additionally} additionally seem advanced to beginner users, but this straightforward education can have you ever up and running. If you have got already got Java eight and Python 3 put in, you’ll pass the first steps:
- Step 1: Install Java eight. Apache Spark requires Java eight.
- Step 2: Install Python.
- Step 3: transfer Apache Spark.
- Step 4: Verify Spark software system File.
- Step 5: Install Apache Spark.
- Step 6: Add winutils.exe File.
- Step 7: tack setting Variables.
- Step 8: Launch Spark.
Step 1: Install Java eight
Apache Spark requires Java eight. you’ll take a look at to look if Java is connected the employment of the electronic communication.Open the statement with the help of victimization clicking begin > kind cmd > click on electronic communication.Type the following command withinside the command prompt:
If Java is connected, it’ll reply with the following output:
Windows interface output for Java model. Your model will be completely different. The 2nd digit is the Java model – in this case, Java 8.
If you don’t have Java hooked up:
- Click the Java transfer button and store the report back to an area of your alternative.
- Once the download finishes double-click on the report back to place in Java.
Step 2: Install Python
- To set up the Python bundle manager, navigate to https://www.python.org/ to your web browser.
- Mouse over the transfer menu various and click on Python 3.eight.three. three.eight.three is the modern model at the time of writing the article.
- Near rock bottom of the first setup language instrumentation, take a glance at off Add Python 3.eight to PATH. Leave the alternative instrumentation checked.
- Next, click on customize.
- You can get away all containers checked at this step, otherwise you could uncheck the alternatives you are currently not need.
- Click Next.
- Select the instrumentation Install for all customers and get away completely different containers as they’re.
- Under customize came upon location, click on Browse and navigate to the C drive. Add an innovative folder and decide on Python.
- Select that folder and click on OK.
- Click Install, and allow the came upon complete.
- When the came upon completes, click on the Disable direction length prohibits various at rock bottom once that click on shut.
- If you’ve got a command trigger off open, restart it. Verify the came upon through checking the model of Python.
- The output should print Python 3.eight.three.
Step 3: Transfer Apache Spark
Open a browser and navigate to https://spark.apache.org/downloads.html.
Under the transfer Apache Spark heading, there square measure drop-down menus. Use the modern non-preview version.
In our case, opt for a Spark launch computer menu opt for a pair of.4.5 (Feb 05 2020).
In the second drop-down opt for a package deal kind, get away the selection Pre-constructed for Apache Hadoop a pair of.7.
Click the spark-2.4.5-bin-hadoop2.7.tgz link.
A web page with an inventory of mirrors plenty whereby you’ll see specific servers to download from. decide any from the listing and keep the document for your Downloads folder.
Step 4: Verify spark software system file
- Verify the integrity of your down load with the help of victimization checking the verification of the report. This guarantees you’re in operation with an unedited, uncorrupted software system.
- Navigate once more to the Spark transfer online page and open the verification link, ideally in a very innovative tab.
- In adventurer, discover the Spark report you downloaded.
- Now, your C:Spark folder contains an innovative folder spark-2.4.5-bin-hadoop2.7 with the necessary documents within.
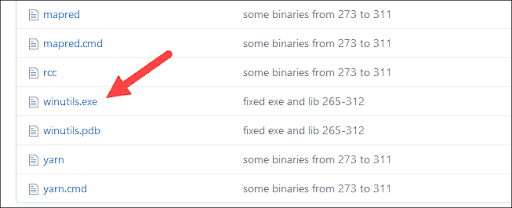
- Navigate to the present URL https://github.com/cdarlint/winutils and among the bin folder, realize winutils.exe, and click on thereon.
- Find the transfer button at the correct side to download the document.
- Now, produce new folders Hadoop and bin on C: the employment of Windows adventurer or the electronic communication.
- Click begin and kind surroundings.
- Select the top result classified Edit the machine surroundings variables.
- A System Properties speech communication field seems. within the lower-proper corner, click on surroundings Variables when that click on New withinside the next window.
- For Variable Name kind SPARK_HOME.
- For Variable price kind C:Sparkspark-2.4.5-bin-hadoop2.7 and click on OK. If you change the folder route, use that one instead.
- In the pinnacle field, click on the trail entry, then click on Edit. use caution with enhancing the machine route.
- On the correct page, click on New.
- The machine highlights the latest line. Enter the route to the Spark folder C:Sparkspark-2.4.5-bin-hadoop2.7 bin. We recommend mistreatment %SPARK_HOME%bin to stay faraway from possible troubles with the route.
- Repeat this methodology for Hadoop and Java.
- For Hadoop, the variable decision is HADOOP_HOME and for that it is worth using the route of the folder you created earlier:
- C:hadoop. Add C:hadoop bin to the trail variable field, but we recommend mistreatment %HADOOP_HOME%bin.
- For Java, the variable decision is JAVA_HOME and for that it is worth using the route in your Java JDK directory (in our case it’s C:Program FilesJavajdk1.8.0_251).
- Click alright to shut all open windows.
- To begin Spark, enter:
- The device got to show varied traces indicating the name of the appliance. you may additionally get a Java pop-up. choose to enable entry to continue.
- Finally, the Spark whole seems, and therefore the set out shows the Scala shell.
- Open a web browser and navigate to http://localhost:4040/.
- You can update localhost with the decision of your device.
- You have to check the associate degree Apache Spark shell internet UI. The instance below indicates the Executors page.
- To go out Spark and close to the Scala shell, press ctrl-d withinside the command-set off window.
Step 5: Install Apache Spark
Installing Apache Spark entails extracting the downloaded report back to the well-liked location.
Create an innovative folder named Spark withinside the basis of your C: drive. From a statement, input the following:
Step 6: Add winutils.exe File
Download the winutils.exe document for the underlying Hadoop model for the Spark created you downloaded:
Step 7: Set up surroundings variables
It permits you to run the Spark shell quickly from a command activate window:
Step 8: Launch Spark
Open a latest command-set off window the usage of the right-click on and Run as administrator:
Conclusion
You need to currently have an in operation created of Apache Spark on Windows ten with all dependencies put in. Get began out cardiopulmonary exercise associate degree example of Spark to your Windows surroundings.Our inspiration is to in addition analyze bigger roughly what Spark DataFrame is, the options, and therefore the thanks to use Spark DataFrame while gathering information.