

Linux Kernel Tutorial
Last updated on 27th Sep 2020, Blog, Operating system, Tutorials
The main purpose of a computer is to run a predefined sequence of instructions, known as a program. A program under execution is often referred to as a process. Now, most special purpose computers are meant to run a single process, but in a sophisticated system such a general purpose computer, are intended to run many processes simultaneously. Any kind of process requires hardware resources such are Memory, Processor time, Storage space, etc.
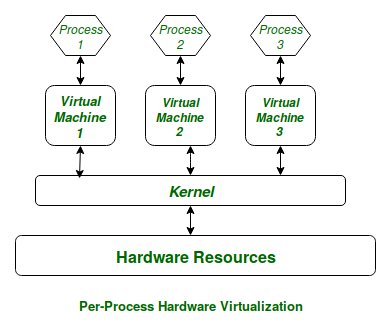
In a General Purpose Computer running many processes simultaneously, we need a middle layer to manage the distribution of the hardware resources of the computer efficiently and fairly among all the various processes running on the computer. This middle layer is referred to as the kernel. Basically the kernel virtualizes the common hardware resources of the computer to provide each process with its own virtual resources. This makes the process seem as it is the sole process running on the machine. The kernel is also responsible for preventing and mitigating conflicts between different processes.
This schematically represented below:
The Core Subsystems of the Linux Kernel are as follows:
- The Process Scheduler
- The Memory Management Unit (MMU)
- The Virtual File System (VFS)
- The Networking Unit
- Inter-Process Communication Unit
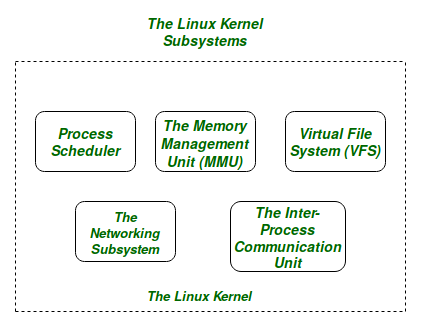
For the purpose of this article we will only be focussing on the 1st three important subsystems of the Linux Kernel.
Subscribe For Free Demo
Error: Contact form not found.
The basic functioning of each of the 1st three subsystems is elaborated below:
- The Process Scheduler:
This kernel subsystem is responsible for fairly distributing the CPU time among all the processes running on the system simulteneously. - The Memory Management Unit:
This kernel sub-unit is responsible for proper distribution of the memory resources among the various processes running on the system. The MMU does more than just simply provide separate virtual address spaces for each of the processes. - The Virtual File System:
This subsystem is responsible for providing a unified interface to access stored data across different filesystems and physical storage media.
What is the Kernel?
A kernel is the lowest level of easily replaceable software that interfaces with the hardware in your computer. It is responsible for interfacing all of your applications that are running in “user mode” down to the physical hardware, and allowing processes, known as servers, to get information from each other using inter-process communication (IPC).
Different Types of Kernels
There are, of course, different ways to build a kernel and architectural considerations when building one from scratch. In general, most kernels fall into one of three types: monolithic, microkernel, and hybrid. Linux is a monolithic kernel while OS X (XNU) and Windows 7 use hybrid kernels. Let’s take a quick tour of the three categories so we can go into more detail later.
Microkernel
A microkernel takes the approach of only managing what it has to: CPU, memory, and IPC. Pretty much everything else in a computer can be seen as an accessory and can be handled in user mode. Microkernels have a advantage of portability because they don’t have to worry if you change your video card or even your operating system so long as the operating system still tries to access the hardware in the same way. Microkernels also have a very small footprint, for both memory and install space, and they tend to be more secure because only specific processes run in user mode which doesn’t have the high permissions as supervisor mode.
Pros
- Portability
- Small install footprint
- Small memory footprint
- Security
Cons
- Hardware is more abstracted through drivers
- Hardware may react slower because drivers are in user mode
- Processes have to wait in a queue to get information
- Processes can’t get access to other processes without waiting
Monolithic Kernel
Monolithic kernels are the opposite of microkernels because they encompass not only the CPU, memory, and IPC, but they also include things like device drivers, file system management, and system server calls. Monolithic kernels tend to be better at accessing hardware and multitasking because if a program needs to get information from memory or another process running it has a more direct line to access it and doesn’t have to wait in a queue to get things done. This however can cause problems because the more things that run in supervisor mode, the more things that can bring down your system if one doesn’t behave properly.
Pros
- More direct access to hardware for programs
- Easier for processes to communicate between eachother
- If your device is supported, it should work with no additional installations
- Processes react faster because there isn’t a queue for processor time
Cons
- Large install footprint
- Large memory footprint
- Less secure because everything runs in supervisor mode

Hybrid Kernel
Hybrid kernels have the ability to pick and choose what they want to run in user mode and what they want to run in supervisor mode. Often times things like device drivers and filesystem I/O will be run in user mode while IPC and server calls will be kept in the supervisor mode. This give the best of both worlds but often will require more work of the hardware manufacturer because all of the driver responsibility is up to them. It also can have some of the latency problems that is inherent with microkernels.
Pros
- Developer can pick and choose what runs in user mode and what runs in supervisor mode
- Smaller install footprint than monolithic kernel
- More flexible than other models
Cons
- Can suffer from same process lag as microkernel
- Device drivers need to be managed by user (typically)

UPGRADE Your Career with Linux Kernel Training By Highly Experienced Faculty
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Where Is the Kernel?
If you open a terminal window and issue the command ls /boot, you’ll see a file called vmlinuz-VERSION (Where VERSION is the release name or number). The vmlinuz file is the actual bootable Linux kernel, and the z indicates the kernel is compressed—so instead of vmlinux we have vmlinuz.
Within that /boot directory are other important kernel files, such as initrd.img-VERSION, system.map-VERSION, and config-VERSION (Where VERSION is either a name or release number). These other files serve the following purposes:
- initrd: Used as a small RAMdisk that extracts and executes the actual kernel file.
- system.map: Used for memory management, prior to the kernel loading.
- config: Instructs the kernel on what options and modules to load.
Modules
Without modules, the kernel wouldn’t be much use. Modules effectively turn on the drivers necessary to communicate with hardware without consuming all of your system memory. Modules also add functionality to the kernel, such as communicating with peripherals, managing file systems, security, etc. List, add, and remove modules to the kernel with the following commands:
- lsmod lists all of the currently loaded kernel modules.
- insmod loads a kernel module into the running kernel.
- rmmod unloads a module from the running kernel.
With the help of some simple commands, the Linux kernel can be quite flexible.
The Current Kernel – kernel.org
The Linux kernel updates frequently, but not all Linux distributions will include the latest kernel.
You’re free to download different versions of the Linux kernel from kernel.org and compile it yourself. The compilation of the Linux kernel is a task best left to those who really know what they’re doing. An improperly compiled kernel can render a system unbootable. So, unless you’re ready to dive into the challenging task of compiling code on this level, use the default kernel that ships and updates on your distribution of choice.
Where Are the Linux Kernel Files?

The kernel file, in Ubuntu, is stored in your /boot folder and is called vmlinuz-version. The name vmlinuz comes from the unix world where they used to call their kernels simply “unix” back in the 60’s so Linux started calling their kernel “linux” when it was first developed in the 90’s.
When virtual memory was developed for easier multitasking abilities, “vm” was put at the front of the file to show that the kernel supports virtual memory. For a while the Linux kernel was called vmlinux, but the kernel grew too large to fit in the available boot memory so the kernel image was compressed and the ending x was changed to a z to show it was compressed with zlib compression. This same compression isn’t always used, often replaced with LZMA or BZIP2, and some kernels are simply called zImage.
The version numbering will be in the format A.B.C.D where A.B will probably be 2.6, C will be your version, and D indicates your patches or fixes.

In the /boot folder there will also be other very important files called initrd.img-version, system.map-version, and config-version. The initrd file is used as a small RAM disk that extracts and executes the actual kernel file. The system.map file is used for memory management before the kernel fully loads, and the config file tells the kernel what options and modules to load into the kernel image when the it is being compiled.
Linux Kernel Architecture
Because the Linux kernel is monolithic, it has the largest footprint and the most complexity over the other types of kernels. This was a design feature which was under quite a bit of debate in the early days of Linux and still carries some of the same design flaws that monolithic kernels are inherent to have.
One thing that the Linux kernel developers did to get around these flaws was to make kernel modules that could be loaded and unloaded at runtime, meaning you can add or remove features of your kernel on the fly. This can go beyond just adding hardware functionality to the kernel, by including modules that run server processes, like low level virtualization, but it can also allow the entire kernel to be replaced without needing to reboot your computer in some instances.
Imagine if you could upgrade to a Windows service pack without ever needing to reboot…
Kernel Modules

What if Windows had every driver available already installed and you just had to turn on the drivers you needed? That is essentially what kernel modules do for Linux. Kernel modules, also known as a loadable kernel module (LKM), are essential to keeping the kernel functioning with all of your hardware without consuming all of your available memory.
A module typically adds functionality to the base kernel for things like devices, file systems, and system calls. LKMs have the file extension .ko and are typically stored in the /lib/modules directory. Because of their modular nature you can easily customize your kernel by setting modules to load, or not load, during startup with the menuconfig command or by editing your /boot/config file, or you can load and unload modules on the fly with the modprobe command.
Third party and closed source modules are available in some distributions, like Ubuntu, and may not be installed by default because the source code for the modules is not available. The developer of the software (i.e. nVidia, ATI, among others) do not provide the source code but rather they build their own modules and compile the needed .ko files for distribution. While these modules are free as in beer, they are not free as in speech and thus are not included by some distributions because the maintainers feel it “taints” the kernel by providing non-free software.
A kernel isn’t magic, but it is completely essential to any computer running properly. The Linux kernel is different than OS X and Windows because it includes drivers at the kernel level and makes many things supported “out of the box”. Hopefully you will know a little bit more about how your software and hardware works together and what files you need to boot your computer.

Learn Linux Kernel Courses to Advance Your Skills & Career
Weekday / Weekend BatchesSee Batch DetailsKernel space and Userspace?
In the Linux operating system, the system memory is divided into two different regions: kernel space and userspace. Let’s look into each region of memory and know the functionalities of both.
1. Kernel space
Kernel space is found in an elevated state which provides full access to the hardware devices and protects the memory space. This memory space and user space together called as Kernel-space. In a kernel space environment, core access to the system services and hardware are maintained and provided as a service to the rest of the system.
2. User Space
The userspace or userland is a code which runs outside the operating system kernel environment.
Userspace is defined as various applications or programmes or libraries that an operating system uses to connect with the kernel. Because of the complicated process to access the memory, malicious functions can be restricted only to the user system.
What is Linux ABI?
It is nothing but kernel userspace ABI (application binary user interface). It exists between program modules. ABIs are used to access the codes that are compiled and ready for usage. ABI is an interface between two binary program modules: one of these modules is an operating system facility or library, and the second one is a program run by a user.
The Linux Loadable Kernel Module
If you want to add code to the Linux kernel, the first thing you need to do is to add some source files to the kernel source tree. There may be situations where you are required to add code to the kernels while it is running, this process is called a loadable kernel module.
The benefits of LKMs (Linux Loadable Kernel Module)
- LKM saves time and avoids errors.
- It helps in finding the bugs quickly.
- LKMs save the memory because they are loaded into memory only when required.
- It offers faster maintenance and debugging time.
Linux kernel interfaces:
The Linux Kernel provides different interfaces to the user-space applications that execute different tasks and have different properties. It consists of two separate Application Programming Interfaces (APIs): one is kernel userspace, and the other is kernel internal. Kernel user space is the Linux API userspace and allows the programs in the user space into system services and resources of the kernel.
Major Subsystems of the Linux Kernel
Below mentioned are the some of the subsystems of the Linux kernel. Let’s discuss them one by one in detail.
System call interface:
A system call is a programmatic process in which a program requests a service from the kernel of an operating system. It includes various hardware services such as connecting with hardware devices and creating a communication interface among the integral parts of the Kernel. System call creates an efficient interface between an operating system and a process.
Process management:
The Kernel takes care of creating and destroying the different processes and monitors their connection to the outside world such as input and output. It handles the communication between different methods via signals, interprocess communication primitive, or pipes. In addition to all these, it also has a scheduler which controls the processes in sharing the CPU.
1. Memory management:
Memory is a vital component of an Operating system and kernel takes care of it. Linux manages the available memory and hardware mechanisms for virtual and physical mappings.
Memory management isn’t just managing 4KB buffers, and it is much more than that. Linux also provides abstractions other than 4kb buffers, known as a slab allocator. Slab allocator uses the 4kb buffer as its base but then allocates structures from inside by monitoring things like, which pages are full, empty, and partially used. This allows the scheme to grow dynamically and in supporting the more significant needs of the system.
2. Virtual file system:
Virtual file system (VFS) is an important integral part of the kernel and facilitates common interface abstraction for the file system. The VFS creates a switching layer between the file system supported by the kernel and SCI (System Call Interface).
In addition to the above things, Linux supports various types of file systems that require different ways of organizing data to store in physical format. For instance, a disk can be formatted with the commonly used FAT file system, or Linux standard ext3 file system, or several others.
3. Device Drivers:
A vast part of the source code of the kernel is stored in the device drivers, and that makes a specific hardware device usable. The Linux provides a driver subdirectory that is further divided into various devices that are supported, such as I2C, Bluetooth, serial, etc.
4. Architecture-dependent code:
Even though much of the Linux runs on its independent architecture, some elements should be considered for the architecture efficiency and normal operation. Linux has many subdirectories, and each architecture subdirectory has many numbers of other subsidiaries. And, these subdirectories focus on the specific tasks of the kernel such as memory management, boot, kernel, etc.
5. Upgrading the Kernel:
As we are aware of the concept called update, we do have that option in the kernel to update it from the older version to a newer one. The retention of old configurations is significant, and to achieve this, one has to back up the configuration file in the kernel source directory. If anything goes wrong while updating the kernel, follow the below steps.
- Download the latest source code from the kernel.org main page.
- Apply variations to the old version tree to make it as a new one.
- Reconfigure the kernel on the basis of the older kernel configuration file that you had backed up.
- Develop the new kernel.
- Now, you can install the latest kernel in your system.
Linux Kernel system (file system)
The files and systems in the Linux kernel system are where most of the users find difficulties, majorly because it is hard to tell which files are in which directories if you don’t have the knowledge. For this reason, we shall try to look at the organization of the file systems. We shall also learn how to create, delete, move, and rename directories. Additionally, we shall learn how to edit files and change permissions.
The file system layout
The UNIX file system can aptly fit into a one-line description; “Everything on a UNIX system that is not a process is a file”. This statement holds true for files that are a little bit more than just files. Therefore, a Linux system does not differentiate between a file and directory mainly because the directory, in essence, is a file containing names of other files, services, texts, images, and programs. Additionally, a Linux system also treats input and output devices as files. The general understanding is that the files are a sort of in a tree structure on the main hard drive; this is for easy management and order. Most of the files on a Linux system are regular files, regardless of the data they hold, be it programs, executable files or normal data.
While we have already said that everything in a Linux system is a file, there is a general understanding that there are some exceptions. For instance:
(a) Directories: A file list of other files
(b) Special files: These are the mechanisms used for input and output. Special files are in /dev.
(c) Links: This is a system to make a file, including directory visible in various parts of the “system tree”.
(d) Domain (sockets): These are special types of files similar to the IP/TCP sockets. These files are protected by the file system access control and they provide inter-process networking.
Named pipes: These types of files are the bridge between processes. They are more or less the same as sockets and enhance communication between processes without the use of networks or sockets semantics.
Remember that I had indicated that most computer users generalize that the file system is more or less like a tree, here is a good example of a Linux file system tree.
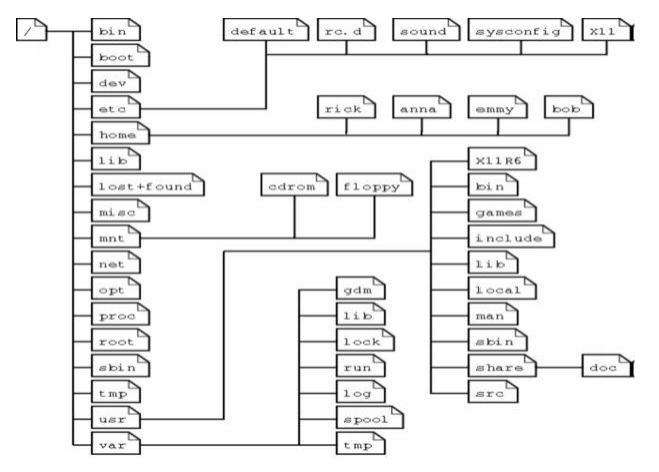
It is important to note that depending on the UNIX system in use, the file system tree may change; some files and directories may change.
The file system tree starts at the slash or the trunk, which, if you look at our table is the (/) forward slash. This is what we call the root directory; it is the underlying directory for all files. Directories are one level below the slash or root directory often have the slash in their proceeding names to indicate their position and to prevent confusion with other files or directories with similar names.
A question that plagues most Linux users is where programs and program files are stored when they are installed on the system. Let us examine this for a minute. Linux uses two partitions: The data partition where the system data, including the root directories and all system resources required to start the system, are located, and the swap partition, which is an expansion of the physical memory on the computer. All files (including programs) are stored in this root directory in accordance with the Linux tree file system we have already looked at.
Manipulating files
To show file names, properties, date of creation, permission, type, size, link files and owners, the Is command is the easiest way.
Creating and deleting files and directories on your system is very important when you want to create new files or delete redundant directories to free up space. Because the graphical interface is much or less that of MS-DOS, creating files is not that difficult. Deleting files, on the other hand, is moderately difficult. There are some popular file managers for the GNU/Linux, with most of them being executable files that are accessible from the desktop manager, home directory icon or the command line using the following commands.
Managing files
Nautilus: This is the default file manager in the Gnome GNU desktop. There are very useful resources on how to use this tool online.
Konqueror: This file manager is typical in KDE desktops.
MC: Code named Midnight Commander is fashioned from the Norton Commander.
For easier file management, the above applications are worth the time of reading through the documentation and the effort. It is also important to note that there are many more file management applications, but these are the most popular and have a moderate difficulty level. Additionally, these tools optimize the UNIX commands in a specific manner.
To keep files and things in one place, you must allocate specific file default locations by creating directories and subdirectories for them. You can do this by using the mkdir command. For instance:
- john:~> cd archive
- john:~/archive> mkdir 1999 2000 2001
- john:~/archive>ls
- 1999/ 2000/ 2001/
- john:~/archive>mkdir 2001/reports/Suppliers-Industrial/
- mkdir: cannot create directory `2001/reports/Suppliers-Industrial/’:
Additionally, you can create subdirectories easily in one-step by using the – p option. For instance:
- john:~> cd archive
- john:~/archive> mkdir 1999 2000 2001
- john:~/archive>ls
- 1999/ 2000/ 2001/
- john:~/archive>mkdir 2001/reports/Suppliers-Industrial/
- mkdir: cannot create directory `2001/reports/Suppliers-Industrial/’:
No such file or directory
- john:~/archive>mkdir -p 2001/reports/Suppliers-Industrial/
- john:~/archive>ls 2001/reports/
- Suppliers-Industrial/:
File permissions
In some instances, you will find that the file needs more or other permission not included in the file creation permission; this is called as an access right.
Access rights are set using the same mkdir command. It is important to note that there are rules on how to name a directory. For instance, in one directory, you cannot have two files with the same name. However, it is important to note that Linux as well as UNIX are case sensitive systems (you can have two file names with you and YOU in the same directory). Additionally, there are no limits to the length of a filename, so naming files should be a breeze. You can also use special characters in the file names as long as those characters do not hold a special meaning to the shell.
Moving files
Moving unclassified files uses the mv command.
- john:~/archive> mv ../report[1-4].doc reports/Suppliers-Industrial/
The same command is also in use when we are renaming files
The command can also come in handy, if you want to rename files:

In the above example, we can see that only the file name changes and all the other properties doesn’t change.
Copying files
The cp command is used to copy directories and files. There is also a very useful option of copying all underlying subdirectories and files (recursive copy) which uses the –R. Here is a look at the general syntax.
1 cp [-R] fromfile tofile
Removing or deleting files
The command rm comes into play when you want to remove single files, while the command rmdir plays its role in removing empty directories. It is important to note that some directories are undeletable (.dot and ..dot) because they are necessary for the proper ranking of a directory in the tree hierarchy. Like UNIX, Linux does not have a garbage can (recycle bin) and once you remove a file, that is it, it is gone and you cannot get it back unless you have a backup. To protect against this, sometimes “mistake delete”, you can activate the interactive behaviour of the cp, mv, and rm commands by using the -i option. When the –i option is active, the system does not execute a command such as delete immediately; instead, it prompts for confirmation, which needs that stroke of a key or an additional click to execute the command fully.
Conclusion
The Linux Kernel plays an important role in resource allocation to different applications. The kernel acts as a centralised place to connect the hardware and software and runs the applications in a system. Linux kernel has got more popularity due to its open-source nature. Users can customize this OS according to their requirements. Therefore, it’s been used by a wide variety of devices.
The modular characteristic of the Linux kernel allows a wide range of modifications without rebooting the system. The Flexibility of the kernel enables its users to perform their level best. Moreover, the monolithic nature of this kernel has greater computational power than the microkernel.