
- Must-Know [LATEST] Apache NiFi Interview Questions and Answers
- [SCENARIO-BASED ] Mahout Interview Questions and Answers
- 40+ [REAL-TIME] Apache Ambari Interview Questions and Answers
- [50+] Big Data Greenplum DBA Interview Questions and Answers
- 40+ [REAL-TIME] Informatica Analyst Interview Questions and Answers
- Must-Know [LATEST] FileNet Interview Questions and Answers
- 20+ Must-Know SAS Grid Administration Interview Questions
- [SCENARIO-BASED ] Apache Flume Interview Questions and Answers
- Top Storm Interview Questions and Answers [ TO GET HIRED ]
- Cassandra Interview Questions and Answers
- Sqoop Interview Questions and Answers
- kafka Interview Questions and Answers
- Hive Interview Questions and Answers
- Big Data Hadoop Interview Questions and Answers
- Elasticsearch Interview Questions and Answers
- HDFS Interview Questions and Answers
- HBase Interview Questions and Answers
- MapReduce Interview Questions and Answers
- Pyspark Interview Questions and Answers
- Hadoop Interview Questions and Answers
- Apache Spark Interview Questions and Answers
- Must-Know [LATEST] Apache NiFi Interview Questions and Answers
- [SCENARIO-BASED ] Mahout Interview Questions and Answers
- 40+ [REAL-TIME] Apache Ambari Interview Questions and Answers
- [50+] Big Data Greenplum DBA Interview Questions and Answers
- 40+ [REAL-TIME] Informatica Analyst Interview Questions and Answers
- Must-Know [LATEST] FileNet Interview Questions and Answers
- 20+ Must-Know SAS Grid Administration Interview Questions
- [SCENARIO-BASED ] Apache Flume Interview Questions and Answers
- Top Storm Interview Questions and Answers [ TO GET HIRED ]
- Cassandra Interview Questions and Answers
- Sqoop Interview Questions and Answers
- kafka Interview Questions and Answers
- Hive Interview Questions and Answers
- Big Data Hadoop Interview Questions and Answers
- Elasticsearch Interview Questions and Answers
- HDFS Interview Questions and Answers
- HBase Interview Questions and Answers
- MapReduce Interview Questions and Answers
- Pyspark Interview Questions and Answers
- Hadoop Interview Questions and Answers
- Apache Spark Interview Questions and Answers

[SCENARIO-BASED ] Mahout Interview Questions and Answers
Last updated on 26th Sep 2022, Big Data, Blog, Interview Question
1. What’s Apache Mahout?
Ans:
Apache™ driver may be a library of scalable machine-learning algorithms, enforced on prime of Apache Hadoop® and victimizing the MapReduce paradigm. Machine learning may be a discipline of AI centered on sanctioning machines to be told while not being expressly programmed, and it’s ordinarily wont to improve future performance supported previous outcomes.
Once huge knowledge is hold on on the Hadoop Distributed filing system (HDFS), driver provides {the knowledge|the info|the information} science tools to mechanically notice pregnant patterns in those huge data sets. The Apache driver project aims to create it quicker and easier to show huge knowledge into huge data.
2. What will Apache driver do?
Ans:
Mahout supports four main knowledge science use cases:
Clustering: Takes things during a specific category (such as websites or newspaper articles) and organizes them into present teams, such things happiness to constant cluster square measure almost like one another.
Classification: learns from existing categorizations and so assigns unclassified things to the simplest class.
Frequent item-set mining: analyzes things during a cluster (e.g. things during a go-cart or terms during a question session) and so determine that things usually seem along
3. What’s the History of Apache Mahout? Once did it start?
Ans:
The driver project was started by many folks concerned within the Apache Lucene (open supply search) community with a full of life interest in machine learning and a need for sturdy, well-documented, scalable implementations of common machine-learning algorithms for cluster and categorization. The community was at first driven by weight unit et al.’s paper “Map-Reduce for Machine Learning on Multicore” (see Resources) however has since evolved to hide a lot of broader machine-learning approaches. driver additionally aims to:
- Build and support a community of users and contributors such the code outlives any specific contributor’s involvement or any specific company or university’s funding.
- Focus on real-world, sensible use cases as hostile bleeding-edge analysis or unproved techniques.
4.What square measures the options of Apache Mahout?
Ans:
Although comparatively young in open supply terms, driver already incorporates a great amount of practicality, particularly in relevance cluster and CF. Mahout’s primary options are:
- Taste CF. style is AN open supply project for CF started by Sean Owen on SourceForge and given to drivers in 2008.
- Several Mapreduce enabled cluster implementations, as well as k-Means, fuzzy k-Means, Canopy, Dirichlet, and Mean-Shift.
- Distributed Naive Thomas {bayes|mathematician} and Complementary Naive mathematician classification implementations.
- Distributed fitness performs capabilities for organic process programming.
- Matrix and vector libraries.
- Examples of all of the higher than algorithms.
5. What’s the Roadmap for Apache driver version one.0?
Ans:
In addition to Java, driver users are going to be able to write jobs victimizing the Scala programming language. Scala makes programming math-intensive applications a lot of easier as compared to Java, thus developers are going to be far more effective. Mahout 0.9 ANd below relied on MapReduce as an execution engine. With driver one.0, users will opt to run jobs either on Spark or liquid, leading to a major performance increase.
6.How is it totally different from doing machine learning in R or SAS?
Ans:
Unless you’re extremely skilled in Java, the commitment to writing itself may be a huge overhead. There’s no means around it, if you don’t realize it already {you square measure|you’re} aiming to learn Java and it’s not a language that flows! For R users WHO are wont to seeing their thoughts completed now, the endless declaration and low-level formatting of objects goes to appear sort of a drag. For that reason, I might suggest protruding with R for any quiet knowledge exploration or prototyping and shift to driver as you catch up with production.
7. Explain some machine learning algorithms exposed by Mahout?
Ans:
Below may be a current list of machine learning algorithms exposed by Mahout:
- Collaborative Filtering
- Item-based cooperative Filtering
- Matrix resolving with Alternating method of least squares
- Matrix resolving with Alternating method of least squares on Implicit Feedback
- Classification
- Naive Bayes
- Complementary Naive mathematician
- Random Forest
- Clustering
- Canopy cluster
- k-Means cluster
- Fuzzy k-Means
8. Which sort of the info is often foreign to HDFS with the assistance of flume?
Ans:
Flume solely ingests unstructured knowledge or semi-structured knowledge into HDFS. whereas Sqoop will also import structured knowledge from RDBMS or Enterprise knowledge warehouses to HDFS or the other way around.
9. Mention some use cases of Apache Mahout?
Ans:
- Commercial Use
- ADOBE CAMPuses Mahout’s cluster algorithms to extend video consumption by higher user targeting.
- Accenture uses driver as a typical example for his or her Hadoop readying Comparison Study
- SOLusi driver for looking recommendations. See slide deck
- BOOZ ALLEN HAMILTONuses Mahout’s cluster algorithms. See slide deck
- Buzzlogic Uses Mahout’s cluster algorithms to boost ad targeting
- tv uses changed driver algorithms for content recommendations
- DATAMINE LABuses Mahout’s recommendation and cluster algorithms to boost our clients’ ad targeting.
- DRUPALusers driver provides open supply content recommendation solutions.
- Evolv uses a driver for its work force prognostic Analytics platform.
- FOURSQUAREuses driver for its recommendation engine.
10. Outline AN Apache driver design overview?
Ans:
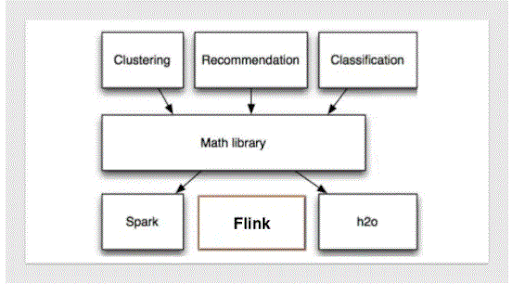
11. Outline tutorial use of the Mahout?
Ans:
- Codeproject uses Mahout’s bunch and classification algorithms on prime of HBase.
- The course giant Scale knowledge Analysis and data processing At TU Berlin uses driver to show students concerning the parallelization of information mining issues with Hadoop and Mapreduce
- Mahout is employed at Carnegie philanthropist University, as a comparable platform to GraphLab
- The strong project, co-funded by the ecu Commission, employs drivers within the large-scale analysis of on-line community knowledge.
- Mahout is employed for analysis and processing at urban center Institute of Technology, within the context of a large-scale subject participation platform project, funded by the Ministry of Interior of Japan.
- Several sorts of analysis among Digital Enterprise analysis Institute NUI Ireland use drivers for e.g. topic mining and modeling of enormous corpora. driver is employed within the NoTube EU project.
12. However, will we have a tendency to scale Apache drivers in the Cloud?
Ans:
Mahout to scale effectively isn’t as easy as merely adding a lot of nodes to a Hadoop cluster. Factors like rule selection, variety of nodes, feature choice, and meagerness of information — still because the usual suspects of memory, bandwidth, and processor speed — all play a role in deciding how effectively the driver will scale. To inspire the discussion, I’ll work with an example of running a number of Mahout’s algorithms on a publically obtainable knowledge set of mail archives from the Apache software package Foundation (ASF) mistreatment of Amazon’s EC2 computing infrastructure and Hadoop, wherever applicable.
13. Is “talent crunch” a true downside in massive Data? What has been your personal expertise around it?
Ans:
Yes,the talent-crunch may be a real downside. however finding really expert individuals is usually arduous. individuals over-rate specific qualifications. a number of the most effective programmers and knowledge scientists I even have identified didn’t have specific coaching as programmers or knowledge scientists. Jacques Nadeau leads the MapR effort to contribute to Apache Drill, for example, and he incorporates a degree in philosophy, not computing. One in all the higher knowledge scientists I do know incorporates a degree in literature.
14. Which sort of main knowledge science use cases does one support?
Ans:
Mahout supports four main knowledge science use cases: cooperative filtering: mines user behavior and makes product recommendations (e.g. Amazon recommendations).
15. What’s the distinction between Apache driver and Apache Spark’s MLlib?
Ans:
It is Hadoop MapReduce and within the case of MLib. To be a lot of specific – from the distinction in per job overhead If Your cubic centimeter rule mapped to solely|the one} mister job – the most distinction is going to be only startup overhead, that is dozens of seconds for Hadoop mister, and let say one second for Spark.
16. What drove you to figure out the Apache driver? However, does one compare Mahout with Spark and H2O?
Ans:
Well, some smart friends asked Maine to answer some queries. From there it had been a downhill slope. First, some inquiries to be answered. Then some code to be reviewed. Then some implementations. Suddenly I used to be a committer and was powerfully committed to the project.
17. What area unit the algorithms utilized by Mahout?
Ans:
Mahout uses the Naive Bayes classifier rule.
18. However will Apache driver work?
Ans:
Apache™ driver may be a library of ascendable machine-learning algorithms, enforced on prime of Apache Hadoop® and mistreatment of the MapReduce paradigm. … Once massive knowledge is keep on the Hadoop Distributed filing system (HDFS), driver provides {the knowledge|the info|the information} science tools to mechanically notice substantive patterns in those massive data sets.
19. What’s Mahout?
Ans:
Apache driver may be a powerful, ascendable machine-learning library that runs on prime of Hadoop MapReduce. It’s an associate open supply project that’s primarily used for making ascendable machine learning algorithms. Maintained by. License kind.
20. What’s my recommendation?
Ans:
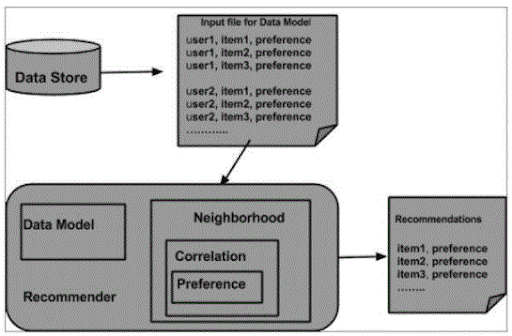
21.What will the Apache driver do?
Ans:
Mahout supports four main information processing use cases:
Clustering :Takes things during a} very specific class (such as sites or newspaper articles) and organizes them into gift groups, such that things happiness to an identical cluster unit of measurement rather like each other.
Classification: Learns from existing categorizations therefore assigns unclassified things to the foremost effective category.
22. What’s the History of Apache Mahout? Once did it start?
Ans:
The driver project was started by many people involved among the Apache Lucene (open offer search) community with an active interest in machine learning and a need for sturdy, well-documented, ascendable implementations of common machine-learning algorithms for bunch and categorization.
23. What sq. measures the choices of Apache Mahout?
Ans:
Although relatively young in open offer terms, driver already encompasses a good deal of utility, significantly in connection bunch and CF. Mahout’s primary choices are:
Taste CF. Vogue is an open offer project for CF started by Sean Owen on SourceForge and given to drivers in 2008.
24. What’s good hardware?
Ans:
Commodity Hardware refers to cheap systems that don’t have high handedness or top quality. goods Hardware consists of RAM as a result of there area unit specific services that require to be dead on RAM. Hadoop is often run on any good hardware and doesn’t need any super laptop or high finish hardware configuration to execute jobs.
25. Make a case for concerning the method of entomb cluster knowledge copying?
Ans:
HDFS provides a distributed knowledge repetition facility through the DistCP from supply to destination. If this knowledge repetition is {within|inside|among|at entombvals} the hadoop cluster then it’s named as inter cluster knowledge repetition. DistCP needs each supply and destination to possess a compatible or same version of hadoop.
26. What’s the driver used for?
Ans:
Apache driver could be a powerful, climbable machine-learning library that runs on prime of Hadoop MapReduce. It’s AN open supply project that’s primarily used for making climbable machine learning algorithms.
27. Does the United Nations agency use Mahout?
Ans:
The company’s Apache driver area unit is most frequently found within the U.S. and within the laptop software system trade. Apache driver is most frequently employed by firms with 50-200 workers and 1M-10M greenbacks in revenue.
28. What’s the method to alter the files at impulsive locations in HDFS?
Ans:
HDFS doesn’t support modifications at impulsive offsets within the file or multiple authors however files are area units written by one writer in append solely format i.e. writes to a come in HDFS area unit continuously created at the tip of the file.
29.What is Apache net server?
Ans:
Apache net server protocol could be a hottest, powerful and Open supply to host websites on the net server by serving web files on the networks. It works on protocol as in machine-readable text Transfer protocol, that provides a custom for servers and consumer facet net browsers to speak. It supports SSL, CGI files, Virtual hosting and lots of alternative options.
30. What’s Apache driver and machine learning?
Ans:
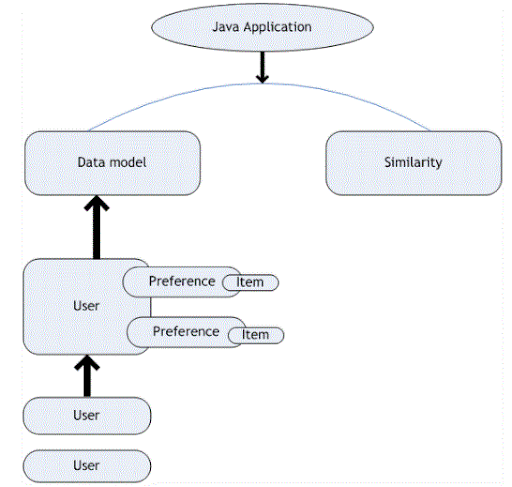
31. What’s the role of the driver within the Hadoop ecosystem?
Ans:
Mahout is an open supply framework for making a climbable machine learning formula and data processing library. Once knowledge is hold on in Hadoop HDFS, driver provides the knowledge science tools to mechanically notice significant patterns in those massive data sets.
32.How many algorithms will drive support for clustering?
Ans:
Mahout supports 2 main algorithms for a bunch , namely: cover bunch. K-means bunch.
33. What’s Row Key?
Ans:
Every row in AN HBase table includes a distinctive symbol called RowKey. It’s used for grouping cells logically and it ensures that every one cell that has an equivalent RowKeys area unit co-located on an equivalent server. RowKey is internally thought to be a computer memory unit array.
34. What does DocumentRoot refer to in Apache?
Ans:
It means that the net file location is kept on the server. For Eg: /var/www.
35.What does one mean by the Alias Directive?
Ans:
The alias directive is liable for mapping resources within the classification system.
36. What does one mean by Directory Index?
Ans:
It is the primary file that the apache server appears for once any request comes from a website.
37.What does one mean by the log files of the Apache internet server?
Ans:
The Apache log records events that were handled by the Apache internet server together with requests from alternative computers, responses sent by Apache, and actions internal to the Apache server.
38. Outline Associate in Nursing fast guide for mahout?
Ans:
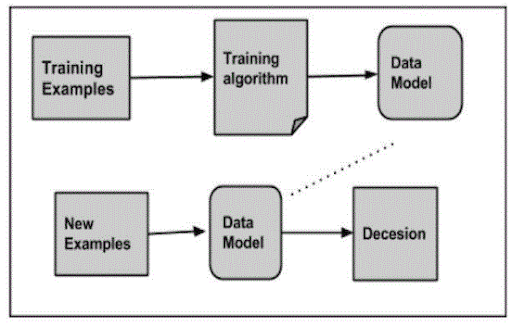
39. What task square measure is performed by the driver package?
Ans:
Mahout offers the engineer a ready-to-use framework for doing data processing tasks on giant volumes of information. driver lets applications investigate giant sets of information effectively and in gait. Includes many MapReduce enabled bunch implementations like k-means, fuzzy k-means, Canopy, Dirichlet, and Mean-Shift.
40. What’s a Hadoop substitution?
Ans:
- Apache Spark.
- Apache Spark is an ASCII text file cluster-computing framework.
- Apache Storm.
- Ceph.
- DataTorrent RTS.
- Disco.
- Google BigQuery.
- High-Performance Computing Cluster (HPCC)
41. That of the subsequent platforms will Apache Hadoop run on?
Ans:
Hadoop has support for cross-platform operational systems.
42. What quiet job may be a mahout?
Ans:
A driver is an elephant rider, trainer, or keeper. Usually, a driver starts as a boy within the family profession once he’s appointed associate elephant early in its life. they continue to be secured to every difference throughout their lives’.
43. What’s the difference between Apache driver and Apache Spark’s MLlib?
Ans:
Clustering – takes things in a {very} very specific class (such as sites or newspaper articles) and organizes them into gift groups, fixed things happiness to an identical cluster unit rather like one anothe.If Your cc formula mapped to the one adult male job – main distinction is simply startup overhead, that’s dozens of seconds for Hadoop adult male, and let say one second for Spark. Therefore, simply just in case of model work it’s not that necessary.
44. Whenever a shopper submits a hadoop job, the United Nations agency receives it?
Ans:
NameNode receives the Hadoop job that then appears for info} requested by the shopper and provides the block information. Hadoop task resource allocation is handled by JobTracker to guarantee prompt completion.
45. Justify regarding the various catalog tables in HBase?
Ans:
The two vital catalog tables in HBase, square measure ROOT and META. ROOT table tracks wherever the META table is and META table stores all the regions within the system.
46. That of the subsequent recommendations employed in Mahout?
Ans:
Mendeley uses a driver to power Mendeley recommend, a search article recommendation service. Myrrix may be a recommender system product engineered on a driver.
47. Is that task performed by the driver package?
Ans:
Mahout offers the engineer a ready-to-use framework for doing data processing tasks on giant volumes of information. driver lets applications analyze giant sets of information effectively and in a very gait. Includes many MapReduce enabled bunch implementations like k-means, fuzzy k-means, Canopy, Dirichlet, and Mean-Shift.
48. What’s Map R on Apache Mahout?
Ans:
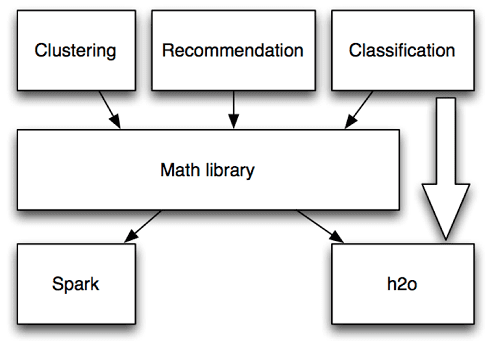
49. What Hadoop is employed for?
Ans:
Apache Hadoop is an open supply framework that wants to efficiently store and method giant datasets in size from gigabytes to petabytes of information. Rather than victimizing one giant laptop to store and method the information, Hadoop permits multiple computers to investigate large datasets in parallel a lot of quickly.
50. Which is better: Spark or Hadoop?
Ans:
Spark has been found to run a hundred times quicker in-memory, and ten times quicker on disk. It’s additionally been wont to type a hundred TB of information three times quicker than Hadoop MapReduce on tenth part of the machines. Spark has notably been found to be quicker on machine learning applications, like Naive Thomas Bayes and k-means.
51. What driver will Mcq?
Ans:
The goal of driver is to make a vivacious, responsive, community to facilitate discussions not solely on the project itself however additionally on potential use cases.
52. What’s Apache driver justify its options and applications?
Ans:
Apache driver may be an extremely climbable machine learning library that permits developers to use optimized algorithms. driver implements well-liked machine learning techniques like recommendation, classification, and bunch. Therefore, it’s prudent to possess a short section on machine learning before we have a tendency to move any.
53. Distinction between Mahout and Graphlab
Ans:
| Mahout | Graphlab |
|---|---|
| Mahout may be a framework for machine learning and a part of the Apache Foundation. | The Graphlab project takes a quite completely different approach to parallel cooperative filtering (more broadly speaking, machine learning), and is primarily utilized by educational establishments. |
| Mahout has inherent Fault-tolerance. | Graphlab doesn’t have inherent Fault tolerance |
| Mahout appears like a lot of polished product, particularly because it depends on Hadoop for quantifiability and distribution. | Graphlab excells since it’s engineered ground up for repetitious algorithms like those employed in cooperative filtering. |
54. Is the driver in the vicinity of Hadoop?
Ans:
Mahout’s design sits atop the Hadoop platform. Hadoop unburdens the applied scientist by separating the task of programming MapReduce jobs from the advanced clerking required to manage similarity across distributed file systems.
55. What number times quicker is MLlib vs Apache Mahout?
Ans:
Spark with MLlib proved to be ninefold quicker than Apache driver in a very Hadoop disk-based atmosphere.
56. Algorithms Supported in Apache driver
Ans:
Apache driver implements serial and parallel machine learning algorithms, which may run on MapReduce, Spark, H2O, and Flink*. This version of driver (0.10.0) focuses on recommendation, clustering, and classification tasks.
57. However putting in Apache driver?
Ans:
Mahout needs Java seven or on top of to be put in, and additionally desires a Hadoop, Spark, H2O, or Flink platform for distributed process (though it may be run in standalone mode for prototyping). driver may be downloaded from http://mahout.apache.org/general/downloads.html and might either be engineered from supply or downloaded in a distribution archive. transfer and untar the distribution, then set the atmosphere variable MAHOUT_HOME to be the directory wherever the distribution is found
58. What’s Apache Spark Apache Mahout?
Ans:
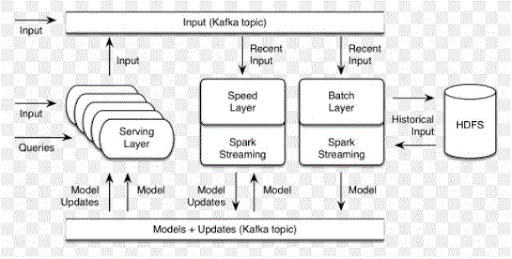
59. What’s Running driver from Java or Scala?
Ans:
In the last example we have a tendency to use the driver from the statement. It’s conjointly doable to integrate drivers together with your Java applications. driver is accessible via hotshot mistreatment the cluster id org.apache.mahout. Add the subsequent dependency to your English person.xml to induce start.
- org.apache.mahout.classifier.naivebayes (for a Naive Thomas Bayes Classifier)
- org.apache.mahout.classifier.df (for a call Forest)
- org.apache.mahout.classifier.sgd (for supplying regression)
- libraryDependencies ++= Seq(
- [other libraries]
- “org.apache.mahout” nothing “mahout-core” nothing “0.10.0”
- )
60. Outline cycle ?
Ans:
Apache Mahout-Samsara refers to a Scala domain specific language (DSL) that enables users to use R-Like syntax as against ancient Scala-like syntax. This permits users to specific algorithms in short and clearly.
61. What’s Backend Agnostic?
Ans:
Apache Mahout’s code abstracts the domain specific language from the engine wherever the code is run. whereas active development is completed with the Apache Spark engine, users are allowed to implement any engine they choose- binary compound and Apache Flink are enforced within the past and examples exist within the code base.
62. Outline the Applications of Mahout?
Ans:
- Companies like Adobe, Facebook, LinkedIn, Foursquare, Twitter, and Yahoo use drivers internally.
- Foursquare helps you find places, food, and diversion accessible in an exceedingly explicit space. It uses the recommender engine of the driver.
- Twitter uses a driver for user interest modeling.
- Yahoo! uses a driver for pattern mining.
63. What’s the distinction between MapReduce and Hadoop?
Ans:
The Apache Hadoop is an associate system that provides associate surroundings that is reliable, ascendable and prepared for distributed computing. MapReduce could be a submodule of this project that could be a programming model and is employed to method immense datasets that sit on HDFS (Hadoop distributed file system).
64. That of the subsequent will Hadoop produce?
Ans:
Distributed file system”
65. Apache driver Developers?
Ans:
Apache driver is developed by a community. The project is managed by a gaggle known as the “Project Management Committee” (PMC). The present PMC is Andrew Musselman, Andrew Palumbo, actor Farris, Isabel Drost-Fromm, Jake Mannix, Pat Ferrel, Paritosh Ranjan, Trevor Grant, Robin Anil, Sebastian Schelter, Stevo Slavić.
66. Mistreatment Apache driver With Apache Spark for Recommendations
Ans:
In the following example, we are going to use Spark as a part of a system to come up with recommendations for various restaurants. The recommendations for a possible diner ar made from this formula:
- recommendations_for_user = [V’V] * historical_visits_from_user
Here, V is the matrix of building visits for all users and V’ is the transpose of that matrix. [V’V] may be replaced with a co-occurrence matrix calculated with a log-likelihood magnitude relation, that determines the strength of the similarity of rows and columns (and so be able to notice restaurants that alternative similar users have liked).
67. Example of Multi-Class Classification mistreatment Amazon Elastic MapReduce
Ans:
We can use a driver to acknowledge written digits (a multi-class classification problem). In our example, the options (input variables) are pixels of a picture, and also the target value (output) is a numeric digit—0, 1, 2, 3, 4, 5, 6, 7, 8, or 9.
Creating a Cluster mistreatment Amazon Elastic MapReduce (EMR) whereas Amazon Elastic MapReduce isn’t absolute to use, it’ll enable you to line up a Hadoop cluster with nominal effort and expense. To begin, produce associate Amazon net Services account and follow these steps:
- Create a Key try.
- Select the “EC2” tab.
- Select “Key Pairs” within the left sidebar.
68. What’s journal d massive amount of information for mahout?
Ans:
69. What’s the importance and also the role of Apache Hive in Hadoop?
Ans:
Hive permits users to scan, write, and manage petabytes of knowledge mistreatment SQL. Hive is made on the premise of Apache Hadoop, that is to associate ASCII text file framework with efficiency store and method massive datasets. As a result, Hive is closely integrated with Hadoop, and is meant to figure quickly on petabytes of knowledge.
70. However, will Apache Hive add Hadoop functionality?
Ans:
In brief, Apache Hive interprets the service program written within the HiveQL (SQL-like) language to at least one or a lot of Java MapReduce, Tez, or Spark jobs. Apache Hive then organizes the information into tables for the Hadoop Distributed file system HDFS) and runs the roles on a cluster to provide a solution.
71. What quiet name is Mahout?
Ans:
A driver is an elephant rider, trainer, or keeper.
72. What’s higher than Hadoop?
Ans:
Spark has been found to run one hundred times quicker in-memory, and ten times quicker on disk. It’s conjointly been wont to kind one hundred TB of knowledge three times quicker than Hadoop MapReduce on tenth of the machines. Spark has notably been found to be quicker on machine learning applications, like Naive Thomas Bayes and k-means.
73. Why is Spark higher than Hadoop?
Ans:
Spark is quicker as a result of it uses random access memory (RAM) rather than reading and writing intermediate information to disks. Hadoop stores information on multiple sources and processes it in batches via MapReduce. Cost: Hadoop runs at a lower price since it depends on any disk storage kind for processing.
74. What’s Apache in massive data?
Ans:
Apache Hadoop is Associate in Nursing open supply, Java-based software package platform that manages processing and storage for giant information applications. Hadoop works by distributing giant information sets and analytics jobs across nodes in an exceedingly computing cluster, breaking them down into smaller workloads that may be run in parallel.
75. Will Databricks run on Hadoop?
Ans:
Just as information Engineering Integration users use Hadoop to access information on Hive, they’ll use Databricks to access information on Delta Lake. Hadoop customers World Health Organization use NoSQL with HBase on Hadoop will migrate to Azure Cosmos sound unit, or DynamoDB on AWS, and use information Engineering Integration connectors to method the info.
76. What’s the Hadoop ecosystem?
Ans:
A Hadoop system may be a platform or a set that provides numerous services to unravel the massive information issues. It includes Apache comes and numerous business tools and solutions. There square measure four major components of Hadoop i.e. HDFS, MapReduce, YARN, and Hadoop Common. … HDFS: Hadoop Distributed filing system.
77. During which languages are you able to code in Hadoop?
Ans:
Hadoop framework is written in Java language, however it’s entirely attainable for Hadoop programs to be coded in Python or C++ language.
78. What’s Hadoop and driver in information mining?
Ans:
79. What square measure driver libraries?
Ans:
Apache driver may be a powerful, scalable machine-learning library that runs on top of Hadoop MapReduce. It’s an Associate in Nursing open supply project that’s primarily used for making scalable machine learning algorithms. Maintained by. License kind.
80. However do Mahouts manage elephants?
Ans:
Elephants will cause sizable hurt or injury if they’re spooked or get angry. Mahouts mount elephants by holding on to its ears together {with his|along with his} hands and rising up the trunk with his feet. They sit behind the animals neck. Mahouts take naps on high mounts, typically commencing their sarongs and victimizing them as a sheet.
81. What’s the MAP cut back technique?
Ans:
MapReduce may be a programming model or pattern within the Hadoop framework that’s accustomed to accessing massive information within the Hadoop filing system (HDFS).MapReduce facilitates synchronous processes by ripping petabytes of knowledge into smaller chunks, and processing them in parallel on Hadoop artifact servers.
82. What’s flume in massive data?
Ans:
Flume. Apache Flume. Apache Flume is Associate in Nursing ASCII text file, powerful, reliable and versatile system accustomed collect, mixture and move giant amounts of unstructured information from multiple information sources into HDFS/Hbase (for example) in an exceedingly distributed fashion via it’s robust coupling with the Hadoop cluster.