
- Probability Density Function in Statistics Tutorial | Definition, Formula & Examples
- Best Clojure Tutorial | Ultimate Guide to Learn [UPDATED]
- Introduction to RapidMiner Tutorial | Get Started with RapidMiner
- R Tutorial
- Spark SQL Tutorial
- Data Extraction in R Tutorial
- Introduction to RapidMiner Tutorial | Get Started with RapidMiner
- Data Scientist vs Data Analyst vs Data Engineer Tutorial
- Unsupervised Learning with Clustering- Machine Learning Tutorial
- Data Scientist Report 2020 Tutorial
- Tutorial on Statistics and Probability for Data Science | All you need to know [ OverView ]
- Machine Learning-K-Means Clustering Algorithm Tutorial
- Julia Tutorial
- Data Science Tutorial
- Probability Density Function in Statistics Tutorial | Definition, Formula & Examples
- Best Clojure Tutorial | Ultimate Guide to Learn [UPDATED]
- Introduction to RapidMiner Tutorial | Get Started with RapidMiner
- R Tutorial
- Spark SQL Tutorial
- Data Extraction in R Tutorial
- Introduction to RapidMiner Tutorial | Get Started with RapidMiner
- Data Scientist vs Data Analyst vs Data Engineer Tutorial
- Unsupervised Learning with Clustering- Machine Learning Tutorial
- Data Scientist Report 2020 Tutorial
- Tutorial on Statistics and Probability for Data Science | All you need to know [ OverView ]
- Machine Learning-K-Means Clustering Algorithm Tutorial
- Julia Tutorial
- Data Science Tutorial

Tutorial on Statistics and Probability for Data Science | All you need to know [ OverView ]
Last updated on 27th Sep 2020, Blog, Data Science, Tutorials
Introduction to Statistics
To become a successful knowledge person you need to apprehend your basics. mathematics and Stats square measure the building blocks of Machine Learning algorithms. it’s necessary to understand the techniques behind varied Machine Learning algorithms so as to understand however and once to use them. Currently the question arises, what specifically is Statistics?
Moving ahead. Let’s discuss the fundamental terminologies in Statistics.
Terminologies In Statistics – Statistics For knowledge Science
One ought to bear in mind some key applied mathematics terminologies whereas coping with Statistics for knowledge Science. I’ve mentioned these terminologies below:
Population is that the set of sources from that knowledge has got to be collected.
A Sample could be a set of the Population
A Variable is any characteristic, number, or amount which will be measured or counted. A variable may be known as an information item.
Also called an applied mathematics model, an applied mathematics Parameter or population parameter could be an amount that indexes a family of likelihood distributions. for instance, the mean, median, etc of a population.
Before we tend to move from now on and discuss the classes of Statistics, let’s inspect the kinds of research.
Types Of Analysis
An analysis of any event will be exhausted one in all 2 ways:
Quantitative Analysis: Quantitative analysis or applied mathematics Analysis is the science of assembling and decoding knowledge with numbers and graphs to spot patterns and trends.
Qualitative Analysis: Qualitative or Non-Statistical Analysis provides generic data and uses text, thousand and different types of media to try and do so.
For example, if I would like a sale a occasional from Starbucks, it’s obtainable briefly, Tall and Grande. This can be an associate degree example of analysis. However, if a store sells seventy regular coffees per week, it’s qualitative analysis as a result of we’ve got a variety representing the coffees sold per week
Categories In Statistics
There square measure 2 main classes in Statistics, namely:
1.Descriptive Statistics
2.Inferential Statistics
Descriptive Statistics:
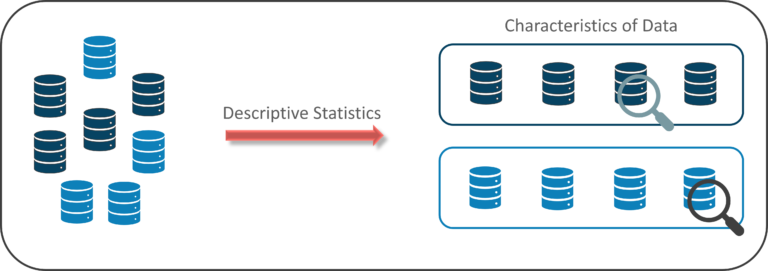
Descriptive Statistics uses the information to supply descriptions of the population, either through numerical calculations or graphs or tables.
Descriptive Statistics helps to organize knowledge and focuses on the characteristics of information providing parameters.
Inferential Statistics:
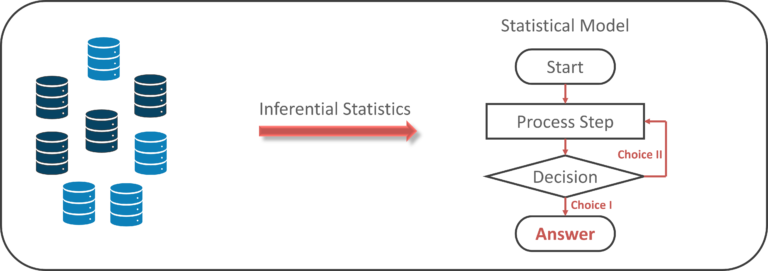
Inferential Statistics makes inferences and predictions a few populations supported a sample of information taken from the population in question.
Inferential statistics generalizes an outsized knowledge set and applies likelihood to reach a conclusion. It permits you to infer parameters of the population supported sample stats and build models thereon.
Understanding Descriptive Analysis
When we attempt to represent knowledge within the type of graphs, like histograms, line plots, etc. the information is delineated and supports some quite central tendency. Central tendency measures like, mean, median, or measures of the unfold, etc square measure used for applied mathematics analysis.
Here could be a sample knowledge set of cars containing the variables:
- Cars
- Mileage per Gallon (mpg)
- Cylinder sort (cyl)
- Displacement (disp)
- Horse Power (hp)
- Real shaft quantitative relation (drat).
- Before we tend to move from now on, let’s outline the most Measures of the middle or Measures of Central tendency.
- Measures Of the middle
- Mean: live of average of all the values in an exceedingly sample is termed Mean.
- Median: live of the central worth of the sample set is termed Median.
- Mode: the most perennial within the sample set is thought as Mode.
- Statistics In R
There square measure n range of reasons why the planet is moving to R. one or two of them square measure noncommissioned below:
R is an ASCII text file and freely obtainable. not like SAS or Matlab, you’ll freely install, use, update, clone, modify, spread and sell R.
R is cross-platform compatible. it’s compatible to run on Windows, raincoat OS X and the UNIX operating system. It may import knowledge from Microsoft surpass, Microsoft Access, MySQL, SQLite, Oracle and different programs.
R could be a powerful scripting language and it will handle giant, advanced knowledge sets.
R is extremely versatile and evolved. Several new developments in statistics initially seem as R packages.
Descriptive Statistics In R
It’s perpetually best to perform sensible implementation to perceive inspiration. during this section, we’ll be corporal punishment atiny low demo that may show you the way to calculate the Mean, Median, Mode, Variance, variance and the way to check the variables by plotting a bar chart. This can be quite an easy demo however it conjointly forms the inspiration that each Machine Learning algorithmic program is constructed upon.
- Step 1: Import knowledge for computation
- Step 2: Calculate Mean for the information
- Step 3: Calculate the Median for the information
- Step 4: Calculate Mode for the information
- Step 5: Calculate Variance & Std Deviation for the information
- Step 6: Plot a bar chart
set.seed(1)
#Generate random numbers and store it in an exceedingly variable known as knowledge
data = runif(20,1,10)
#Calculate Mean
>mean = mean(data)
>print(mean)
[1] 5.996504
#Calculate Median
>median = median(data)
>print(median)
[1] 6.408853
#Create a perform for conniving Mode
>mode uxor ux[which.max(tabulate(match(x, ux)))]
}
>result print(data)
[1] 3.389578 4.349115 6.155680 9.173870 2.815137 9.085507 9.502077 6.947180 6.662026
[10] 1.556076 2.853771 2.589011 7.183206 4.456933 7.928573 5.479293 7.458567 9.927155
[19] 4.420317 7.997007
>cat(“mode= “, result)
mode= 3.389578
#Calculate Variance and std Deviation
>variance = var(data)
>standardDeviation = sqrt(var(data))
>print(standardDeviation)
[1] 2.575061
#Plot bar chart
>hist(data, bins=10, range= c(0,10), edgecolor=’black’)
Understanding Inferential Analysis
Statisticians use hypothesis testing to formally check whether or not the hypothesis is accepted or rejected. Hypothesis testing is associate degree Inferential applied mathematics technique wont to verify whether or not there’s enough proof in an exceedingly knowledge sample to infer that a particular condition holds true for a complete population.
To underneath the characteristics of a general population, we tend to take a random sample and analyze the properties of the sample.
Consider four boys, Nick, John, Bob and Harry UN agency were caught bunking a category. They were asked to remain back in class and clean their room as a penalty.