
- 40+ [REAL-TIME] Data Visualization in R Interview Questions and Answers
- 50+ Best Data Science with R Interview Questions and Answers
- Top NLP Interview Questions and Answers
- STATA Interview Questions And Answers [ FRESHERS ]
- Most Popular Data Mining Interview Questions and Answers
- [50+] SPSS Interview Questions and Answers [ TO GET HIRED ]
- Get Statistics Interview Questions [ TO GET HIRED ]
- Data Science with Python Interview Questions and Answers
- Data Structure Interview Questions and Answers
- Google Data Science Interview Questions and Answers
- SAS Clinical Interview Questions and Answers
- Data Architect Interview Questions and Answers
- Data Analyst Interview Questions and Answers
- R Interview Questions and Answers
- Data Science Interview Questions and Answers
- 40+ [REAL-TIME] Data Visualization in R Interview Questions and Answers
- 50+ Best Data Science with R Interview Questions and Answers
- Top NLP Interview Questions and Answers
- STATA Interview Questions And Answers [ FRESHERS ]
- Most Popular Data Mining Interview Questions and Answers
- [50+] SPSS Interview Questions and Answers [ TO GET HIRED ]
- Get Statistics Interview Questions [ TO GET HIRED ]
- Data Science with Python Interview Questions and Answers
- Data Structure Interview Questions and Answers
- Google Data Science Interview Questions and Answers
- SAS Clinical Interview Questions and Answers
- Data Architect Interview Questions and Answers
- Data Analyst Interview Questions and Answers
- R Interview Questions and Answers
- Data Science Interview Questions and Answers

Get Statistics Interview Questions [ TO GET HIRED ]
Last updated on 03rd Aug 2022, Blog, Data Science, Interview Question
1.However, is the applied mathematics significance of Associate in Nursing insight assessed?
Ans:
Hypothesis testing is employed to search out the applied mathematics significance of the insight. To elaborate, the null hypothesis and also the alternate hypothesis are explicit , and also the p-value is calculated.
After hard the p-value, the null hypothesis is assumed true, and also the values are determined. To fine-tune the result, the alpha value, that denotes the importance, is tweaked. If the p-value seems to be but the alpha, then the null hypothesis is rejected. This ensures that the result obtained is statistically important.
2.Where are long-tailed distributions used?
Ans:
A long-tailed distribution could be a variety of distributions wherever the tail drops off bit by bit toward the top of the curve.
The economist principle and also the product sales distribution are sensible examples to denote the employment of long-tailed distributions. Also, it’s widely employed in classification and regression issues.
3.What variety of knowledge doesn’t have a log-normal distribution or a Gaussian distribution?
Ans:
Exponential distributions don’t have a log-normal distribution or a normal distribution. Any categorical variety of knowledge won’t have these distributions moreover.
Example: period of a phone automobile, time till successive earthquakes, etc.
4.What is Mean?
Ans:
Mean is the average of a group of values. we will calculate the mean by dividing the total of all observations by the quantity of observations.
5.What is the meaning of ordinary deviation?
Ans:
Standard deviation represents the magnitude of however so much the information points are from the mean. An occasional worth of ordinary deviation is a sign of the information being getting ready to the mean, and a high worth indicates that the information is unfolding to extreme ends, distant from the mean.
6.What’s a bell-curve distribution?
Ans:
A normal distribution may be referred to as a bell-curve distribution. It gets its name from the bell curve form that we tend to get after we visualize the distribution.
7.What are the kinds of choice bias in statistics?
Ans:
There are many varieties of choice bias as shown below:
- Observer choiceM
- AttritionM
- Protopathic biasM
- Time intervalsM
- Sampling biasM
8.What are left-skewed and right-skewed distributions?
Ans:
A left-skewed distribution is one wherever the left tail is longer than that of the proper tail. Here, it’s necessary to notice that the mean < median < mode. Similarly, a right-skewed distribution is one wherever the proper tail is longer than the left one.
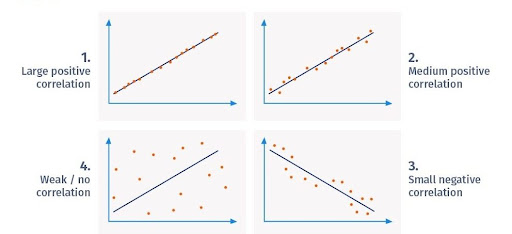
9.What’s the correlation?
Ans:
Correlation is employed to check relationships between quantitative variables and categorical variables. In contrast to variance, correlation tells North American nations however sturdy the link is between 2 variables. The correlation between 2 variables ranges from -1 to +1.
Similarly, +1 means that a direct correlation, and here, a rise in one variable can result in a rise within the difference. Whereas, zero means that there’s no correlation. If 2 variables are powerfully related , then they will damage the applied mathematics model, and one amongst them should be born. Next abreast of this high Statistics Interview queries and Answers web log, allow us to take a glance at the intermediate set of queries.
10.What’s the meaning of the six letters of the alphabet in statistics?
Ans:
Six letters of the alphabet could be a quality assurance methodology used widely in statistics to produce ways to enhance processes and practicality once operating with knowledge.
A method is taken into account as six letters of the alphabet once ninety nine.99966% of the outcomes of the model are thought of to be defect-free.
11.What will the statistical distribution represent?
Ans:
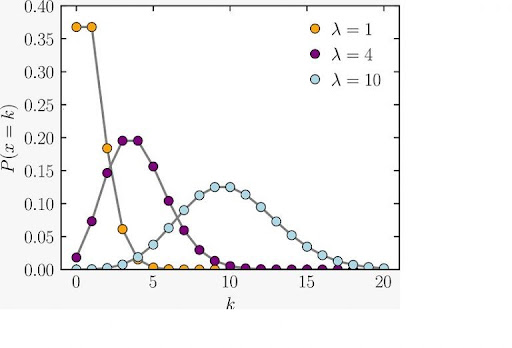
12. What’s DOE?
Ans:
DOE is an associated word form for the planning of Experiments in statistics. it’s thought of because the style of a task that describes the knowledge and therefore the modification of constant supported the changes to the freelance input variables.
13. However, is missing information handled in statistics?
Ans:
There area unit many ways to handle missing information in Statistics:
- Prediction of the missing values
- Assignment of individual (unique) values
- Deletion of rows, that have the missing information
- Mean imputation or median imputation
- Using random forests, that support the missing values
14. What’s the economic expert principle?
Ans:
The economic expert principle is additionally known as the 80/20 rule, which implies that eighty % of the results are unit obtained from twenty % of the causes in the associated experiment.
A simple example of the economic expert principle is the observation that eighty % of peas return from twenty % of pea plants on a farm.
15.What’s beta information analysis?
Ans:
Exploratory information analysis is the method of performing arts investigations on information to know the information higher.
In this, initial investigations are done to work out patterns, spot abnormalities, check hypotheses, and conjointly check if the assumptions are unit right.
16.What’s the meaning of choice bias?
Ans:
- Selection bias could be a development that involves the choice of individual or sorted information during a manner that’s not thought of to be random.
- Randomization plays a key role in performing arts analysis and understanding model practicality higher.
- If correct organization isn’t achieved, then the ensuing sample won’t accurately represent the population.
17.What’s the chance of throwing 2 truthful dice once the total is five and 8?
Ans:
There area unit four ways in which of rolling a five (1+4, 4+1, 2+3, 3+2):
- P(Getting a 5) = 4/36 = 1/9
- P(Getting associate 8) = 7/36 = zero.194
Now, there area unit seven ways in which of rolling associate eight (1+7, 7+1, 2+6, 6+2, 3+5, 5+3, 4+4)
18.What’s the meaning of associate inlier?
Ans:
An inlier could be a datum that lies at constant level because of the remainder of the dataset. Finding associate inlier within the information set is tough compared to associate outlier because it needs external data to try and do thus. Inliers, kind of like outliers scale back model accuracy. Hence, even they’re removed once they’re found within the information. This can be done chiefly to keep up model accuracy in the least times.
19.What area unit the kinds of sampling in Statistics?
Ans:
There area unit four main forms of information sampling as shown below:
- Simple random: Pure random division
- Cluster: Population divided into clusters
- Stratified: information divided into distinctive teams
- Systematical: Picks up each ‘n’ member within the information
20.What’s the meaning of covariance?
Ans:
2-tailed test: crucial region is on either side of the distribution
- H0: x = µ
- H1: x µ
1-tail test: crucial region is on one aspect of the distribution
- H1: x µ
21.What does one perceive by inferential statistics?
Ans:
When we attempt to type a conclusion concerning the population by conducting the experiments on the sample taken from the population.
22.What’s P-value and justify it?
Ans:
When we execute a hypothesis check in statistics, a p-value helps US confirm our results’ significance. These Hypothesis tests area unit nothing however to check the validity of a claim that’s created a few population. A null hypothesis is once the hypothesis and therefore the such population area unit with no important distinction because of sampling or experimental error.
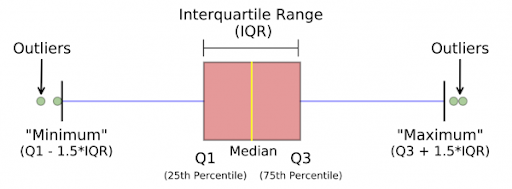
23.What’s the meaning of the five-number outline in Statistics?
Ans:
The five-number outline could be a live of 5 entities that cowl the whole vary of knowledge as shown below:
- Low extreme (Min)
- The first grade (Q1)
- Median
- Upper grade (Q3)
- High extreme (Max)
24.What area unit population and sample in Inferential Statistics, and the way area units are different?
Ans:
A population could be a massive volume of observations (data). The sample could be a little portion of that population. attributable to the massive volume of knowledge within the population, it raises the procedure price. the provision of all information points within the population is additionally a problem.
In short:
- We calculate the statistics of victimization and sample victimization.
- Using these sample statistics, we have a tendency to build conclusions concerning the population.
25.What area unit quantitative information and qualitative data?
Ans:
- Quantitative information is additionally called numeric information.
- Qualitative information is additionally called categorical information.
26. What’s the distinction between Descriptive and Inferential Statistics?
Ans:

27. List the fields wherever a data point will be used?
Ans:
Statistics will be employed in several analysis fields. Below square measure the lists of files during which statistics will be used:
- Science
- Technology
- Business
- Biology
- Computer Science
- Chemistry
- It aids in decision-making.
- Provides comparison
- Explains the action that has taken place
- Predict the long run outcome
28.What’s Bessel’s correction?
Ans:
Bessel’s correction may be an issue that’s accustomed to estimating a populations’ variance from its sample. It causes the quality deviation to be less biased, thereby, providing a lot of correct results.
29.What’s the link between the boldness level and therefore the significance level in statistics?
Ans:
The significance level is that the chance of getting a result that’s extraordinarily totally different from the condition wherever the null hypothesis is true. whereas the boldness level is employed as a variety of comparable values in a very population.
Both significance and confidence level square measure connected by the subsequent formula:
Significance level = one one Confidence level
30. What kinds of variable square measure are used for Pearson’s correlation coefficient?
Ans:
Variables to be used for the Pearson’s parametric statistic should be either AN exceedingly|in a very} magnitude relation or in an interval.
Note that there will exist a condition once one variable may be a magnitude relation, whereas the opposite is Associate in Nursing interval score.
31.Where is inferential statistics used?
Ans:
Inferential statistics is employed for many functions, like analysis, during which we would like to draw conclusions from a couple of population victimization samples. This is often performed in a variety of fields, starting from government operations to internal control and quality assurance groups in international firms.
32.What’s the link between mean and median in a very traditional distribution?
Ans:
In a statistical distribution, the mean is capable of the median. to grasp if the distribution of a dataset is traditional, we are able to simply check the dataset’s mean and median.
33.What square measures the eventualities wherever outliers square measure unbroken within the data?
Ans:
There don’t seem to be several eventualities wherever outliers square measure unbroken within the information, however there square measure some vital things once they square measure unbroken. they’re unbroken within the information for analysis if:
- Results square measure vital
- Outliers add desiring to the info
- The data is very inclined
34.However, are you able to calculate the p-value victimization MS Excel?
Ans:
- Find the info tab on top of
- Click on information Analysis
- Select Descriptive Statistics
- Select the corresponding column
- Input the boldness level
35.Are you able to provide an Associate in Nursing example to denote the operation of the central limit theorem?
Ans:
Let’s contemplate the population of men UN agencies have ordinarily distributed weights, with a mean of sixty kilogram and a customary deviation of ten kilogram, and therefore the chance must be noted.
If one single man is chosen, the burden is larger than sixty five kilogram, however if forty men square measure chosen, then the mean weight is much, quite sixty five kilogram.
The solution to the current will be as shown below:
- Z = (x − µ) / ? = (65 − 60) / ten = zero.5
- For a standard distribution P(Z > zero.5) = 0.409
- Z = (65 − 60) / five = one
- P(Z > 1) = zero.090
36.What’s the connection between variance and normal variance?
Ans:
Standard deviation is the root of ordinary variance. Basically, variance takes a glance at however the info is unfolded from the mean. On the opposite hand, normal variance is employed to explain what proportion the info varies from the mean of the complete dataset.
37.Once making an applied math model, however can we sight overfitting?
Ans:
Overfitting is detected by cross-validation. In cross-validation, we tend to divide the on the market information into multiple elements and ingeminate on the complete dataset. In every iteration, one half is employed for testing, et al are used for coaching. This way, the complete dataset is going to be used for coaching and testing functions, and that we will see if the info is being overfitted.
38.What area unit a number of the techniques to cut back underfitting and overfitting throughout model training?
Ans:
Underfitting refers to a scenario where information has high bias and low variance, whereas overfitting is the scenario where there is unit high variance and low bias.
Following area unit a number of the techniques to cut back underfitting and overfitting:
For reducing underfitting:
- Increase model complexness
- Increase the quantity of options
- Remove noise from the info
- Increase the quantity of coaching epochs
For reducing overfitting:
- Increase coaching information
- Stop early whereas coaching
- Lasso regularization
- Use random dropouts
39.What’s the employment of Hash tables in statistics?
Ans:
Hash tables area unit the info structures that area unit wont to denote the illustration of key-value pairs in a very structured method. The hashing performed is employed by a hash table to cypher associate index that contains all of the main points relating to the keys that are unit mapped to their associated values.
40.What’s the meaning of TF/IDF vectorization?
Ans:
TF-IDF is an associate form for Term Frequency – Inverse Document Frequency. It’s used as a numerical live to denote the importance of a word in a document. This document is sometimes referred to as the gathering or the corpus.
The TF-IDF price is directly proportional to the quantity of times a word is perennial in a document. TF-IDF is important within the field of language process (NLP) because it is usually employed in the domain of text mining and knowledge retrieval.
41.What will the style of Experiments mean?
Ans:
Design of experiments conjointly referred to as DOE, it’s the planning of any task that aims to {explain} and explain the variation of data beneath conditions that area unit hypothesized to mirror the variable. In essence, the associate experiment aims to predict associate outcomes supported by an amendment in one or a lot of inputs (independent variables).
42.However, does one assess the applied math significance of associate insight?
Ans:
You would perform hypothesis testing to work out applied math significance.
First, you’d state the null hypothesis and different hypotheses.
Second, you’d calculate the p-value, the chance of getting the discovered results of a check assuming that the null hypothesis is true.
Last, you’d set the amount of the importance (alpha) and if the p-value is a smaller amount than the alpha, you’d reject the null — in different words, the results statistically vital.
43.Is mean imputation of missing information acceptable practice? Why or why not?
Ans:
Mean imputation is mostly unhealthy as a result of it doesn’t take into consideration feature correlation. as an example, imagine we’ve got a table showing age associated fitness score and picture that an eighty-year-old encompasses a missing fitness score. If we tend to take the common fitness score from associate age varying from fifteen to eighty, then the eighty-year-old can seem to possess a way higher fitness score that he really ought to.
Second, mean imputation reduces the variance of {the information|the info|the information} and will increase bias in our data. This ends up in a less correct model and a narrower confidence interval because of a smaller variance.
44.What area unit the assumptions needed for linear regression?
Ans:
There area unit four major assumptions:
- 1.There is a linear relationship between the dependent variables and therefore the regressors, which means the model you’re making really fits the info.
- 2.The errors or residuals of the info area unit ordinarily distributed and freelance from one another.
- 3.There is token multiple regression between instructive variables.
- 4.Homoscedasticity. This suggests the variance round the curve is the same for all values of the variable.
45.What’s the distinction between population parameters and sample statistics?
Ans:
Population parameters are:
- Mean = µ
- Standard deviation variance
Sample statistics are:
- Mean = x (bar)
- Standard deviation = s
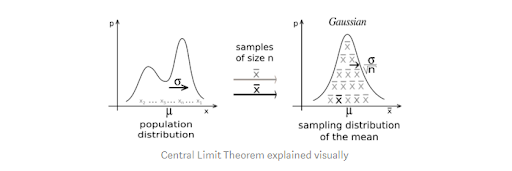
46.What’s the Central Limit Theorem?
Ans:
Central Limit Theorem is the cornerstone of statistics. It states that the distribution of a sample from a population comprising an outsized sample size can have its mean ordinarily distributed. In other words, it’ll not have any impact on the first population distribution.
47.what’s the distribution Formula
Ans:
The distribution formula is:
- b(x; n, P) = nCx * post exchange * (1 – P)n – x
Where:
b = binomial chance
x = total variety of “successes” (pass or fail, heads or tails, etc.
P = chance of success on a personal trial
n = variety of trials
48.What’s the distinction between population and sample?
Ans:
| Population | sample |
|---|---|
| Population | Sample |
| Advertisements for IT jobs within the Netherlands. the highest fifty search results for advertisements for IT jobs within the Netherlands on day, 2020. | Songs from the Eurovision Song Contest. |
| Undergraduate students within the Netherlands. three hundred college boy students from 3 Dutch universities United Nations agency volunteer for your science analysis study. | All countries of the planet. Countries with revealed information on the market on birth rates and gross domestic product since 2000. |
49.What’s kurtosis?
Ans:
Kurtosis could be a condition of the degree of the intense values given in one tail of distribution or the peaks of distribution as compared to the others. The quality Gaussian distribution features a kurtosis of three whereas the values of symmetry and kurtosis between -2 and +2 square measure are thought of as traditional and acceptable. The info sets with a high level of kurtosis imply that there’s a presence of outliers. One has to add information or take away outliers to beat this drawback. information sets with low kurtosis levels have light-weight tails and lack outliers.
50. What’s a bell-curve distribution?
Ans:
A bell-curve distribution is diagrammatical by the form of a bell and indicates Gaussian distribution. It happens naturally in several things particularly whereas analyzing monetary information. The highest of the curve shows the mode, mean and median of the info and is dead symmetrical. The key characteristics of a curved shape square measure.
The empirical rule says that around sixty eight of information lies at intervals one variance of the mean in either of the directions.
Around ninety fifth of information falls at intervals 2 normal deviations and Around 99.7% of information falls at intervals 3 normal deviations in either direction.
51. What’s Significance Level?
Ans:
The likelihood of rejecting the null hypothesis once it’s referred to as the importance, the importance , and extremely common selections square measure square measure = zero.05 and α = zero.01.?
52. What to try and do you perceive by right skewness? provide an example.
Ans:
When the info isn’t unremarkably distributed and that we have a tail sort elongated line on the correct aspect, that’s referred to as right asymmetry.
For example:Income distribution.
53.What’s the distinction between information Science and Statistics?
Ans:
Data Science could be a science that’s diode by information. It includes the knowledge domain fields of scientific strategies, algorithms, and even the method for extracting insights from the info. the info will be either structured or unstructured. There square measures several similarities between information science and data processing as each helpful abstract data from the info. Now, information science conjointly includes mathematical statistics and engineering science and its applications.
It is by the mixture of statistics, mental image, and mathematics and engineering science that information science will convert a huge quantity data|of information} into insights and knowledge. Thus, statistics from the most a part of information science it’s a branch of mathematical commerce with the gathering, analysis, interpretation, organization, and presentation of information.
54.What square measures the varied strategies of sampling?
Ans:
Sampling will be exhausted four broad methods:
- Randomly or in a very easy nonetheless random methodology.
- Systematically or taking each kth member of the population.
- Cluster once the population is taken into account in teams or clusters.
- Stratified i.e. once the exclusive teams or strata, a sample from a group) samplings.
55. What does that mean of sensitivity in statistics?
Ans:
Sensitivity, because the name suggests, is employed to see the accuracy of a classifier (logistic, random forest, etc.)
The simple formula to calculate sensitivity is:
- Sensitivity = expected True Events/Total range of Events
56. What square measures the categories of biases that you simply will encounter whereas sampling?
Ans:
There square measure 3 forms of biases:
- Selection bias
- Survivorship bias
- Under coverage bias
57. What’s the good thing about exploitation box plots?
Ans:
Box plots permit the United States to supply a graphical illustration of the 5-number outline and may even be wont to compare teams of histograms.
58. List all the opposite models that employ statistics to research the data?
Ans:
Statistics, beside information Analytics, analyzes the info and facilitates a business to form smart choices. prognosticative ‘Analytics’ and ‘Statistics’ square measure helpful to research current information and historical information to form predictions regarding future events.
59. the way to calculate vary and interquartile range?
Ans:
Where, Q3 is that the third score (75 percentile)
Where, Q1 is that the initial score (25 percentile)
60. What am I able to do with outliers?
Ans:
| Remove outlier | Keep outlier |
|---|---|
| When we apprehend the data-point is wrong (negative age of a person). | When we have several information. |
| We should give 2 analyses. One with outliers and another while not outliers. | When there ar heap of outliers (skewed data) |
| When results are vital | When outliers have that means (fraud data) |
61.Way to realize the mean length of all fishes within the sea?
Ans:
- Define the boldness level (most common is 95%)
- Take a sample of fishes from the ocean (to convalesce results the quantity of fishes > 30)
- Calculate the mean length and variance of the lengths
- Calculate t-statistics
- Get the boldness interval during which the mean length of all the fishes ought to be.
62. What’s the distinction between the ninety fifth confidence level and the ninety nine confidence level?
Ans:
The confidence interval will increase as American state move from ninety fifth confidence level to ninety nine confidence level.
63.Justify what Associate in Nursing inlier is and the way you would possibly screen for them and what would you be doing if you found them in your dataset.
Ans:
An inlier could be an information observation that lies among the remainder of the dataset and is uncommon or a slip. Since it lies within the dataset, it’s usually tougher to spot than Associate in Nursing outliers and needs external information to spot them. do you have to establish any inliers, you’ll merely take away them from the dataset to handle them.
64. However, does one handle missing data? What imputation techniques does one recommend?
Ans:
There are many ways in which to handle missing data:
- Delete rows with missing information
- Mean/Median/Mode imputation
- Assigning a novel price
- Predicting the missing values
- Using Associate in Nursing rule that supports missing values, like random forests
65. Are you able to use atomic number 34 for testing Rest API or internet services?
Ans:
Selenium provides Native genus Apis for interacting with the browser exploitation actions and events.The remainder API and therefore the internet services don’t have any UI and thus can’t be machine-driven exploitation atomic number 34.
66. offer an Associate in Nursing example wherever the median could be a higher live than the mean?
Ans:
When there are a variety of outliers that completely or negatively skew the info.
67. Given 2 truthful dice, what’s the likelihood of obtaining scores that total to 4? to 8?
Ans:
There are four combos of rolling a four (1+3, 3+1, 2+2):
P(rolling a 4) = 3/36 = 1/12
There are combos of rolling Associate in Nursing eight (2+6, 6+2, 3+5, 5+3, 4+4):
P(rolling Associate in Nursing 8) = 5/36
68. What’s the Central Limit Theorem? justify it. Why is it important?
Ans:
Statistics a way to provides the most effective definition of CLT, which is:
The central limit theorem is very important as a result of it’s utilized in hypothesis testing and additionally to calculate confidence intervals.
69.A way to establish information is skew or not skew? and what are different types of skewed and the way to spot them?
Ans:
If the numerical information is their mean and median are totally different then this can be the indication of knowledge being skewed. If the information contains Mean = Median = Mode information is generally distributed.
There are 2 different types of skewness:
Positive Skewed:Most of {the information|the info|the information} is gift within the left facet of distribution and tail is downward towards the proper facet then data is positive skew or Mean > Median > Mode this can be additionally called positive skew
Negative skew:Most of {the information|the info|the information} is gift within the right facet of distribution and tail is downward towards the left facet then data is negatively skew or Mean< Median < Mode this can be additionally called Negative Skewed
70. Why is Scaling Required?
Ans:
Most machine learning algorithms take under consideration solely the magnitude of the measurements, not the units of these measurements.
So that is expressed in an exceedingly} very high magnitude (number), which can {affect|have Associate in Nursing effect on} the prediction a great deal over an equally vital feature.
71.Justify Univariate and quantity Graph analysis.
Ans:
Univariate Graph Bivariate Graph.
Univariate Graph analysis used just one variable to induce some analysis. quantity Graph analysis used 2 variables to induce analysis of their relation.
Knowledge uses each Qualitative and Quantitative knowledge Graph use for quantity knowledge is scatter plot, bar graph, etc.
72.What square measures the kinds of modalities?
Ans:
Unimodal:It’s just one peak
Bimodal:It’s 2 peak
Multimodal:It’s several peak
Uniform:All square measure distributed uniformly
73. What makes the distinction between “Long” and “Wide” Format data?
Ans:
In a wide format methodology, once we take a topic, the recurrent responses square measure recorded during a single row, and every recorded response is during a separate column.
In wide format, the column square measure is typically divided into teams whereas during a long-form the rows square measure is divided into teams.
74.Justify kind I and sort II errors?
Ans:
The type I error typically happens once the null hypothesis is true, however once rejected. And once we think about the kind II error, it happens once the null hypothesis is fake however mistakenly fails to be rejected.
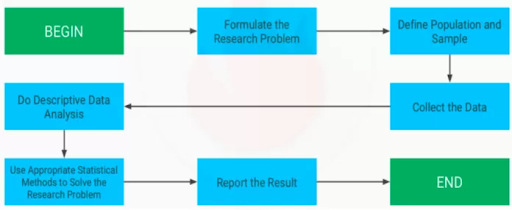
75.Justify the method of information analysis?
Ans:
76. What is: carry, KPI, robustness?
Ans:
Lift:Carry may be a live of the performance of a targeting model measured against a random selection targeting model; in different words, carry tells you the way far better.
KPI:stands for Key Performance Indicator, that may be a measurable metric accustomed to confirming however well an organization is achieving its business objectives. Eg. error rate.
Robustness:Typically lustiness refers to a system’s ability to handle variability and stay effective.
77.Outline quality assurance, six sigma.
Ans:
Quality assurance:Associate activity or set of activities targeted on maintaining a desired level of quality by minimizing mistakes and defects.
Six sigma:selected form of quality assurance methodology composed of a collection of techniques and tools for method improvement. A six alphabetic character method is one during which ninety nine.99966% of all outcomes square measure are freed from defects.
78.Provide samples of knowledge that doesn’t have a Gaussian distribution, nor log-normal?
Ans:
Any form of categorical knowledge won’t have a Gaussian distribution or lognormal distribution.
Exponential distributions — eg. the number of your time that a lead-acid accumulator lasts or the number of your time till associate earthquake happens.
79. What square measures contradictory variables?
Ans:
A contradictory variable, or a confounder, may be a variable that influences each variable quantity and also the variable, inflicting a spurious association, a mathematical relationship during which 2 or additional variables square measure are associated however not causally connected.
80. What’s meant by the applied mathematics power of Sensitivity, and the way will we have a tendency to calculate it?
Ans:
The word Sensitivity is usually utilized in verifying the accuracy of a classifier (SVM, Random Forest, Logistics, etc.).
In applied mathematics analysis, Sensitivity is treated as expected events that square measure true. Truth events square measure nothing however the events that are literally true in nature additionally the} model also expected them as true.
The calculation of seasonality is pretty simple.
- Seasonality = ( True Positives ) / ( Positives in Actual variable quantity )
81.What does that mean of degrees of freedom (DF) in statistics?
Ans:
Degrees of freedom or DF is employed to outline the amount of choices at hand once playing AN analysis. it’s principally used with t-distribution and not with the z-distribution.
82.However are you able to calculate the p-value mistreatment MS Excel?
Ans:
Following steps area unit performed to calculate the p-value easily:
- Find the information tab on top of
- Click on information Analysis
- Select Descriptive Statistics
- Select the corresponding column
- Input the arrogance level
83.In an exceedingly scatter diagram, what’s the road that’s drawn on top of or below the regression curve called?
Ans:
The line that’s drawn on top of or below the regression curve in an exceedingly scatter diagram is termed the residual or conjointly the prediction error.
84.What’s meant by linear regression?
Ans:
Linear regression is often used for conducting prognosticative analysis. It helps the North American nation in examining 2 things. As an example, rectilinear regression is employed to check 2 factors that belong to a selected factor. Let’s say the worth of a house depends on 2 various factors like location and size. to search out the link between these factors, we’d like to conduct a rectilinear regression. Rectilinear regression helps North American nations find the positive or negative effects of those 2 relationships.
85.What is: model fitting, 80/20 rule?
Ans:
Model fitting:Refers to however well a model fits a collection of observations.
80/20 rule:Conjointly referred to as the Pareto principle; states that eightieth of the results return from two hundredth of the causes. Eg. eightieth of sales return from two hundredth of consumers.
86.What style of experiments
Ans:
Design of experiments:Conjointly referred to as DOE, it’s the planning of any task that aims to make a case for} and explain the variation of data underneath conditions that are hypothesized to replicate the variable. [4] In essence, AN experiment aims to predict AN outcome supporting a modification in one or a lot of inputs (independent variables).
87.What does one think about the tail (one tail or 2 tail) if H0 is capable of one price only?
Ans:
It is a two-tail take a look at
88.What’s the crucial price in a one tail or two-tail test?
Ans:
- Critical price in 1-tail = alpha
- Critical price in a pair of-tail = alpha / 2
89.What’s the proportion of confidence intervals which will not contain the population parameter?
Ans:
Alpha is that the portion of confidence interval which will not contain the population parameter
- α = 1 – CL
90.What’s Binary Search?
Ans:
In any binary search, the array must be organized either in ascending or falling order. In each step, the search key price is compared with the key price of the center component of the array by the algorithmic rule. If each of the keys match, an identical component is discovered, and also the index or the position is returned. Else, if the search key falls below the key of the center component, then the algorithmic rule can repeat the action on the sub-array that falls to the left of the center component of the array if the search secret is over the sub-array to the correct.
91.What square measures the results of the dimension of confidence interval?
Ans:
Confidence interval is employed for higher cognitive process.
As the arrogance level will increase the dimension of the confidence interval additionally will increase.
As the dimension of the arrogance interval will increase, we tend to urge useless data additionally.
Useless data – wide CI.
High risk – slender CI.
92. a way to convert distribution to plain traditional distribution?
Ans:
- Standardized distribution has mean = zero and variance = one
- To convert distribution to plain distribution we are able to use the formula
- X (standardized) = (x-µ) / σ
93. What’s the associated Interquartile Range( IQR )?
Ans:
- The main advantage of the IQR is that it’s not tormented by outliers as a result of it doesn’t take into consideration observations below Q1 or on top of Q3.
- It might still be helpful to appear for doable outliers in your study.
- As a rule of thumb, observations may be qualified as outliers once they lie over one.5 IQR below the primary mark or one.5 IQR on top of the third mark. Outliers square measure values that “lie outside” the opposite values.
- Outliers = Q1 – one.5 * IQR OR Outliers = Q3 + one.5 * IQR
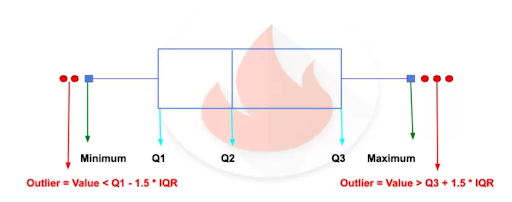
94. What’s the left inclined distribution and right inclined distribution?
Ans:
Left inclined
- Mean < median < mode
Right inclined
he right tail is longer than the correct face
- Mode < median < mean
95. Why do we want a 5-number summary?
Ans:
- Low extreme (minimum)
- Lower mark (Q1)
- Median
- Upper mark (Q3)
- Upper extreme (maximum)
96. What general conditions should be happy for the central limit theorem to hold?
Ans:
The data should follow the randomisation condition which suggests that it should be sampled arbitrarily.
The Independence Assumptions dictate that the sample values should be free of every alternative.
Sample sizes should be massive. they need to be adequate to or bigger than thirty to be able to hold CLT. a massive sample size is needed to carry the accuracy of CLT to be true.
97. a way to notice outliers?
Ans:
The best thanks to notice outliers is thru graphical means that. With the exception of that, outliers also can be detected through the utilization of applied math strategies and victimization tools like surpass, Python, SAS, among others. The foremost well-liked graphical ways to notice outliers embrace box plot and scatter plot.
98. however does one calculate the required sample size?
Ans:
You can use the margin of error (ME) formula to work out the required sample size.
- t/z = t/z score wont to calculate the arrogance interval
- ME = the required margin of error
- S = sample variance
99. A variate X is traditional with mean 1020 and a regular deviation fifty. Calculate P(X>1200)?
Ans:
Using Excel
- p =1-norm.dist(1200, 1020, 50, true)p= 0.000159
100.Difference between Purpose Estimates and Confidence Interval?
Ans:
| Point Estimation | Confidence Interval |
|---|---|
| Point Estimation | Confidence Interval |
| For population parameter specific worth as associate estimate offers North American country purpose estimation. The likelihood that the interval contains the parameter is that of the confidence interval. | Methods like moments and most probability calculator strategies square measure the purpose estimation population parameter. It quantifies the amount of confidence that the parameter lies within the interval. |