
- Commvault Tutorial for Beginners | Ultimate Guide to Learn [NEW & UPDATED]
- SAP MM (Material Management) Tutorial | A Complete Guide
- MOST In-DEMAND Snowflake Tutorial [ STEP-IN ] | Learn Now
- SAP MM (Material Management) Tutorial | A Complete Guide
- MOST In-DEMAND Snowflake Tutorial [ STEP-IN ] | Learn Now
- Informatica Master Data Management Concepts (MDM) Tutorial | Quickstart – MUST- READ
- Teradata
- Informatica Tutorial: The Ultimate Guide [STEP-IN] | Learnovita
- ETL Tutorial
- SSIS Cheat Sheet
- Informatica Architecture
- Netezza Tutorial
- Datastage Tutorial
- SSIS Tutorial
- Commvault Tutorial for Beginners | Ultimate Guide to Learn [NEW & UPDATED]
- SAP MM (Material Management) Tutorial | A Complete Guide
- MOST In-DEMAND Snowflake Tutorial [ STEP-IN ] | Learn Now
- SAP MM (Material Management) Tutorial | A Complete Guide
- MOST In-DEMAND Snowflake Tutorial [ STEP-IN ] | Learn Now
- Informatica Master Data Management Concepts (MDM) Tutorial | Quickstart – MUST- READ
- Teradata
- Informatica Tutorial: The Ultimate Guide [STEP-IN] | Learnovita
- ETL Tutorial
- SSIS Cheat Sheet
- Informatica Architecture
- Netezza Tutorial
- Datastage Tutorial
- SSIS Tutorial

Teradata
Last updated on 12th Oct 2020, Blog, Datawarehouse, Tutorials
Teradata is a popular Relational Database Management System (RDBMS) suitable for large data warehousing applications. It is capable of handling large volumes of data and is highly scalable. This tutorial provides a good understanding of Teradata Architecture, various SQL commands, Indexing concepts and Utilities to import/export data.
This tutorial is designed for software professionals who are willing to learn Teradata concepts and become a Teradata developer. By the end of this tutorial, you will have gained intermediate level of expertise in Teradata.
Prerequisites
You should have a basic understanding of Relational concepts and basic SQL. It will be good if you have worked with any other RDBMS product.
What is Teradata?
Teradata is one of the popular Relational Database Management System. It is mainly suitable for building large scale data warehousing applications. Teradata achieves this by the concept of parallelism. It is developed by the company called Teradata.
History of Teradata
Following is a quick summary of the history of Teradata, listing major milestones.
- 1979 − Teradata was incorporated.
- 1984 − Release of first database computer DBC/1012.
- 1986 − Fortune magazine names Teradata as ‘Product of the Year’.
- 1999 − Largest database in the world using Teradata with 130 Terabytes.
- 2002 − Teradata V2R5 released with Partition Primary Index and compression.
- 2006 − Launch of Teradata Master Data Management solution.
- 2008 − Teradata 13.0 released with Active Data Warehousing.
- 2011 − Acquires Teradata Aster and enters into Advanced Analytics Space.
- 2012 − Teradata 14.0 introduced.
- 2014 − Teradata 15.0 introduced.
Features of Teradata
- Unlimited Parallelism − Teradata database system is based on Massively Parallel Processing (MPP) Architecture. MPP architecture divides the workload evenly across the entire system. Teradata system splits the task among its processes and runs them in parallel to ensure that the task is completed quickly.
- Shared Nothing Architecture − Teradata’s architecture is called as Shared Nothing Architecture. Teradata Nodes, its Access Module Processors (AMPs) and the disks associated with AMPs work independently. They are not shared with others.
- Linear Scalability − Teradata systems are highly scalable. They can scale up to 2048 Nodes. For example, you can double the capacity of the system by doubling the number of AMPs.
- Connectivity − Teradata can connect to Channel-attached systems such as Mainframe or Network-attached systems.
- Mature Optimizer − Teradata optimizer is one of the matured optimizer in the market. It has been designed to be parallel since its beginning. It has been refined for each release.
- SQL − Teradata supports industry standard SQL to interact with the data stored in tables. In addition to this, it provides its own extension.
- Robust Utilities − Teradata provides robust utilities to import/export data from/to Teradata system such as FastLoad, MultiLoad, FastExport and TPT.
- Automatic Distribution − Teradata automatically distributes the data evenly to the disks without any manual intervention.
Teradata Architecture
Post navigation
The main components of Teradata Architecture are PE(Parsing Engine), BYNET, AMP(Access Module Processor), Virtual Disk. Following is the logical view of the architecture:
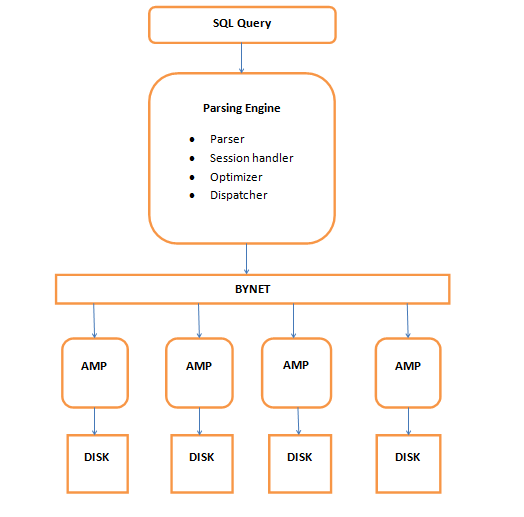
Parsing Engine
When a user fires an SQL query it first gets connected to the PE (Parsing Engine). The processes such as planning and distributing the data to AMPS are done here. It finds out the best optimal plan for query execution. The following are the processes performed by PE:
- Parser: The Parser checks for the syntax, if true forward the query to Session Handler.
- Session Handler: it does all the security checks, such as checking of logging credentials and whether the user has permission to execute the query or not.
- Optimizer: It finds out the best possible and optimized plan to execute the query.
- Dispatcher: The Dispatcher forwards the query to the AMPs.
BYNET
The BYNET acts as a channel between PE and AMPs. It acts as a communicator between the two. There are two BYNETs in Teradata ‘BYNET 0’ and ‘BYNET 1’. But we refer them as single BYNET system. The reason for having 2 BYNETs is:
- If one BYNET fails, the second one can take its place.
- When data is large, both BYNETs can be made functional which improves the communication between PE and AMPs, thus fastening the process.
AMP
Access Module Processor is a virtual processor which is connected to PE via BYNET. Each AMP has its own disk and is allowed to read and write in its OWN disk. This is called as ‘SHARED NOTHING ARCHITECTURE’. When the query is fired , Teradata distributes the rows of table on all the AMPs and when it calls for any data all AMPs work simultaneously to give back the data. This is called PARALLELISM. The AMP executes any SQL requests in three steps
- Lock the table.
- Execute the operation requested.
- End the transaction.
Subscribe For Free Demo
Error: Contact form not found.
Disk
Teradata offers a set of Virtual Disks for each AMP. The storage area of each AMP is called as Virtual Disk or Vdisk. The steps for executing the query are below:
1.The user fires the query which is sent to PE.
2.PE does the security and syntax checks, and finds out the best optimal plan to execute the query.
3.The table rows are distributed on the AMP and the data is retrieved from the disk.
4.The AMP sends back the data through BYNET to PE.
5.PE returns back the data to the user.
Components of Teradata
1. Node − It is the basic unit in Teradata System. Each individual server in a Teradata system is referred as a Node. A node consists of its own operating system, CPU, memory, own copy of Teradata RDBMS software and disk space. A cabinet consists of one or more Nodes.
2.Parsing Engine − Parsing Engine is responsible for receiving queries from the client and preparing an efficient execution plan. The responsibilities of parsing engine are −
- Receive the SQL query from the client
- Parse the SQL query check for syntax errors
- Check if the user has required privilege against the objects used in the SQL query
- Check if the objects used in the SQL actually exists
- Prepare the execution plan to execute the SQL query and pass it to BYNET
- Receives the results from the AMPs and send to the client
3.Message Passing Layer − Message Passing Layer called as BYNET, is the networking layer in Teradata system. It allows the communication between PE and AMP and also between the nodes. It receives the execution plan from Parsing Engine and sends to AMP. Similarly, it receives the results from the AMPs and sends to Parsing Engine.
4.Access Module Processor (AMP) − AMPs, called as Virtual Processors (vprocs) are the one that actually stores and retrieves the data. AMPs receive the data and execution plan from Parsing Engine, performs any data type conversion, aggregation, filter, sorting and stores the data in the disks associated with them. Records from the tables are evenly distributed among the AMPs in the system. Each AMP is associated with a set of disks on which data is stored. Only that AMP can read/write data from the disks.
Storage Architecture
When the client runs queries to insert records, Parsing engine sends the records to BYNET. BYNET retrieves the records and sends the row to the target AMP. AMP stores these records on its disks. Following diagram shows the storage architecture of Teradata.
Retrieval Architecture
When the client runs queries to retrieve records, the Parsing engine sends a request to BYNET. BYNET sends the retrieval request to appropriate AMPs. Then AMPs search their disks in parallel and identify the required records and sends to BYNET. BYNET then sends the records to Parsing Engine which in turn will send to the client. Following is the retrieval architecture of Teradata.
Advantages of Teradata
1) Teradata database is linearly scalable: It can expand the database capacity by adding more nodes to the existing database.
2) Extensive parallel processing: It has parallel processing capacity. It can also handle request from multiple ad-hoc and from many concurrent users.
3) Shared nothing architecture: The architecture of the Teradata database is also not shareable. It can tolerate faults and data protection.
Disadvantages
- It is not suitable for small transaction OLTP databases.
- Development of Teradata and DBA resources are harder to come by and therefore more expensive.
Applications of Teradata
1.Customer Data Management: Helps to create and maintain long-lasting relationships with customers.
2.Master Data Management: It develops an environment where master data can be used and synchronized and can be stored.
3.Finance and Performance Management: It helps to improve speed and quality of financial report of an organization. It reduces finance infrastructure costs.
4.Supply Chain Management: It improves operational chain which helps to improve customer services and reduces the time cycle.
5.Demand Chain Management: It increases customer service sales and levels. It also predicts the demand for store item accurately.
Installation
Teradata provides Teradata express for VMWARE which is a fully operational Teradata virtual machine. It provides up to 1 terabyte of storage. Teradata provides both 40GB and 1TB version of VMware.
Step 1:-You can download Teradata Express and Vmware workstation from Teradata site and Vmware site respectively. Once downloaded, you can unzip Teradata Express into some folder. Suppose you have unzipped it in a folder name “virtual”. You will end up with something like this- ” F:\virtual\TDExpressXX_Sles11_40GB “. Install Vmware workstation.
Step 2:-Open VMware Workstation Welcome page, choose “Open a Virtual Machine” and navigate to Teradata express folder, looking for the ” TDExpress15.00.01_Sles11″ file.
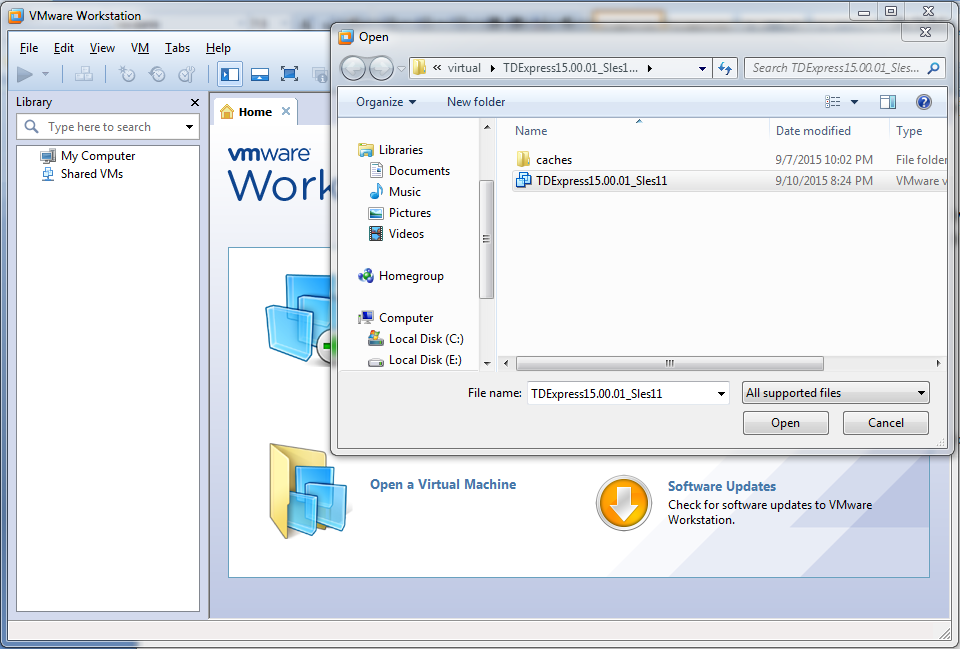
Step 3:-Once you find the image, open it by double clicking. Vmware will now ask you if you want to copy or move this image. Make sure to choose ‘I MOVED IT‘!
Step 4:-Now click on “Power on this virtual machine”.
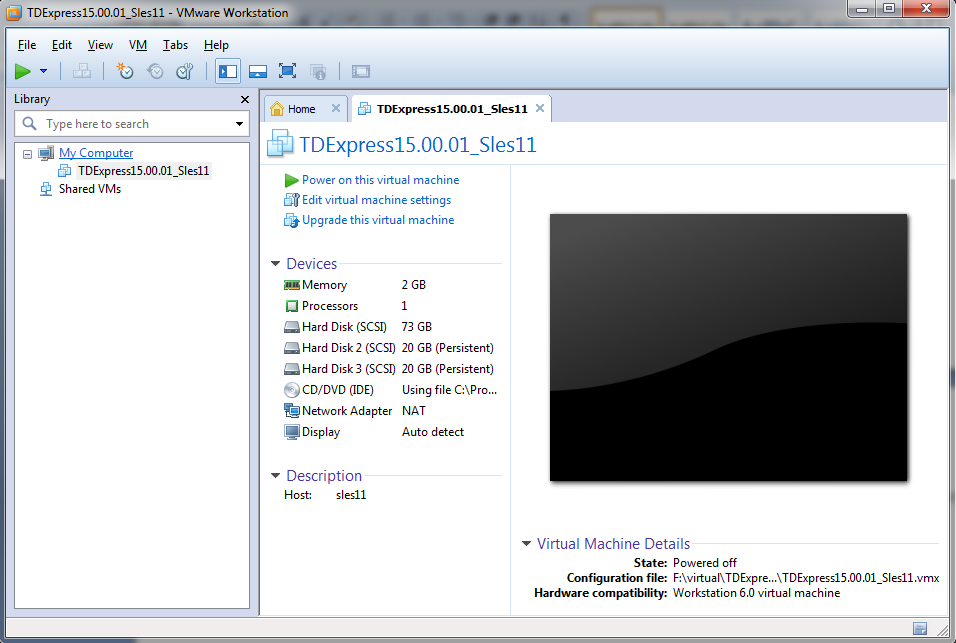
Step 5:-Login into the SLES11 VM with username “root” and password “root”. Wait for sometimes, it will initialize the Teradata.
Step 6:-Once it is ready, open Gnome terminal and you can check the status of Teradata database server using below command-

Best Practical Oriented Teradata Training By Experts Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- TDExpress15.00.01_Sles11:~# pdestate -a
- PDE state is RUN/STARTED.
- DBS state is 4: Logons are enabled – Users are logged on
- TDExpress15.00.01_Sles11:~#
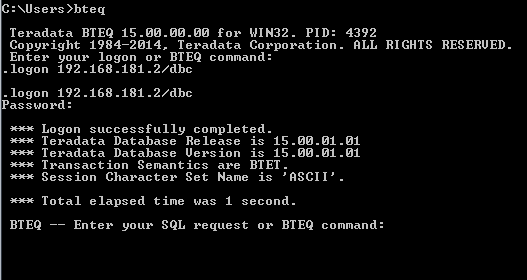
Now you can test the connectivity as well using bteq with username “dbc” and password “dbc”.
You have successfully completed the installation of fully functional Teradata server. If you want to access this Teradata database server from your local PC, few extra steps you may follow:-
Step 7:-Download Microsoft .NET 4 or above and Teradata 15 TTU for windows. You need to install .NET framework prior to install Teradata Tools and Utilities(TTU).
Step 8:-Once installation of TTU is done, set up the IP for VM and SLES11 to access it from your local system using Teradata SQL Assistant or any other utilities.
- Open Virtual Network Editor from the EDIT menu of VM.
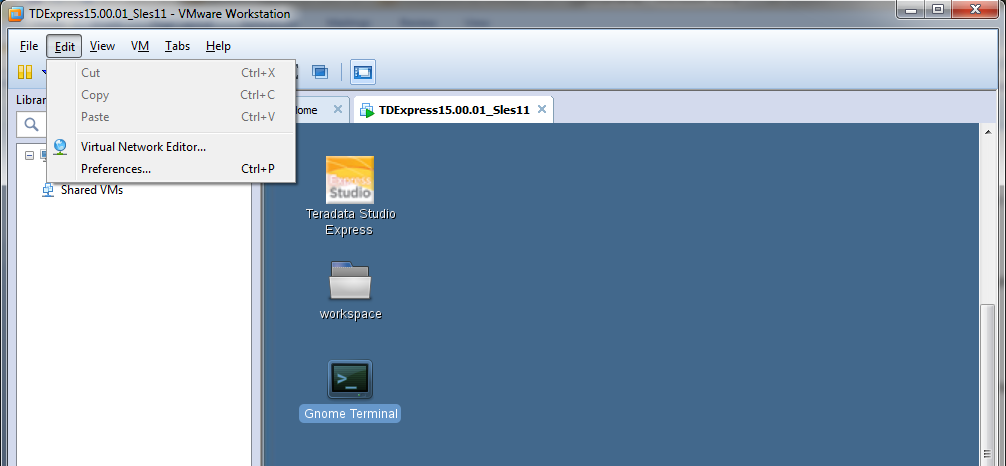
- Select VMnet8 NAT setting and set up Gateway IP.
Suppose your NAT subnet Address is 192.168.181.0, you may provide Gateway IP as 192.168.181.1. Click OK.
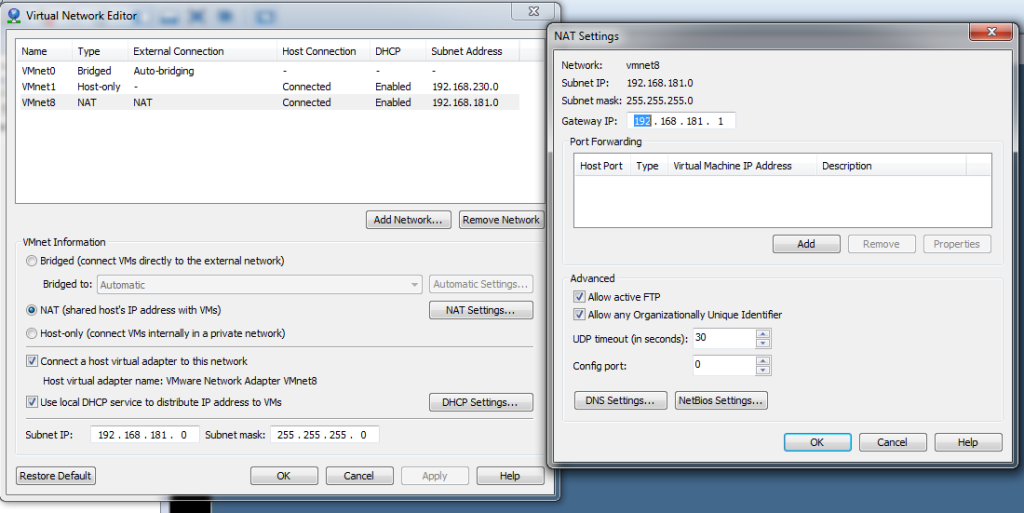
- Now open Network Settings in SLES11 i.e. from the operating system within the Vmware.
Computer -> Control Center -> Network Settings -> Select Ethernet Network Card->Edit. Suppose Gateway IP is 192.168.181.1 in NAT setting, you have to enter 192.168.181.2 here as below-
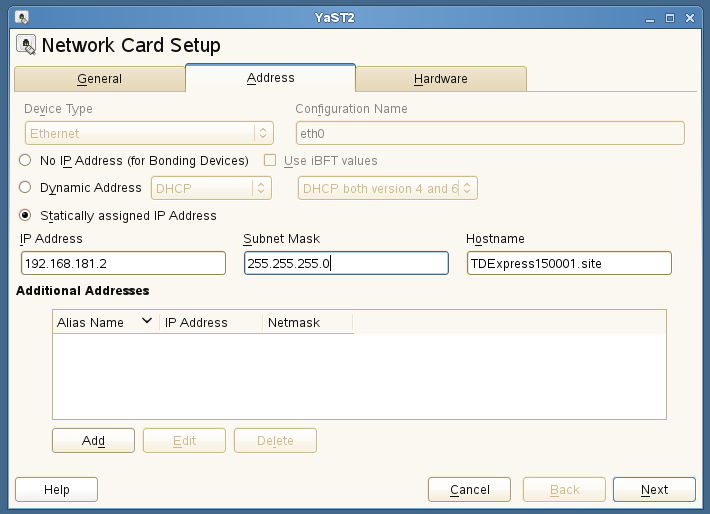
Click Next. Now open command prompt in local system and ping this IP Address.
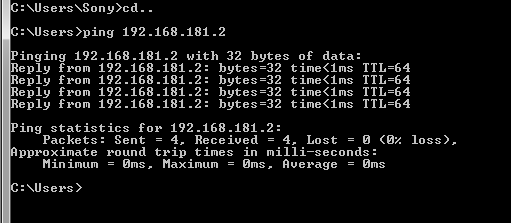
All done. Now you can use this IP Address(192.168.181.2) from your local ODBC driver, Teradata SQL Assistant or BTEQ to access Teradata database server.
Rules
- The number of columns specified in the VALUES list should match with the columns specified in the INSERT INTO clause.
- Values are mandatory for NOT NULL columns.
- If no values are specified, then NULL is inserted for nullable fields.
- The data types of columns specified in the VALUES clause should be compatible with the data types of columns in the INSERT clause.
SET Operators
SET operators combine results from multiple SELECT statement. This may look similar to Joins, but joins combines columns from multiple tables whereas SET operators combines rows from multiple rows.
Rules
- The number of columns from each SELECT statement should be same.
- The data types from each SELECT must be compatible.
- ORDER BY should be included only in the final SELECT statement.
UNION
UNION statement is used to combine results from multiple SELECT statements. It ignores duplicates.
INTERSECT
INTERSECT command is also used to combine results from multiple SELECT statements. It returns the rows from the first SELECT statement that has corresponding match in the second SELECT statements. In other words, it returns the rows that exist in both SELECT statements.
MINUS/EXCEPT
MINUS/EXCEPT commands combine rows from multiple tables and returns the rows which are in first SELECT but not in second SELECT. They both return the same results
Space Concepts
Permanent Space
Permanent space is the maximum amount of space available for the user/database to hold data rows. Permanent tables, journals, fallback tables and secondary index sub-tables use permanent space.
Permanent space is not pre-allocated for the database/user. They are just defined as the maximum amount of space the database/user can use. The amount of permanent space is divided by the number of AMPs. Whenever per AMP limit exceeds, an error message is generated.
Spool Space
Spool space is the unused permanent space which is used by the system to keep the intermediate results of the SQL query. Users without spool space cannot execute any query.
Similar to Permanent space, spool space defines the maximum amount of space the user can use. Spool space is divided by the number of AMPs. Whenever per AMP limit exceeds, the user will get a spool space error.
Temp Space
Temp space is the unused permanent space which is used by Global Temporary tables. Temp space is also divided by the number of AMPs.
Compression
Compression is used to reduce the storage used by the tables. In Teradata, compression can compress up to 255 distinct values including NULL. Since the storage is reduced, Teradata can store more records in a block. This results in improved query response time since any I/O operation can process more rows per block. Compression can be added at table creation using CREATE TABLE or after table creation using ALTER TABLE command.
Multi-Value Compression (MVC)
The following table compresses the field DepatmentNo for values 1, 2 and 3. When compression is applied on a column, the values for this column is not stored with the row. Instead the values are stored in the Table header in each AMP and only presence bits are added to the row to indicate the value.
Conclusion
- Teradata is massively parallel open processing system for developing large-scale data warehousing applications
- Teradata was a division of NCR Corporation. It incorporated in 1979 but parted away from NCR in October 2007
- Teradata offers a full suite of service which focuses on Data Warehousing
- Teradata offers linear scalability when dealing with large volumes of data by adding nodes to increase the performance of the system.
- Three important components of Teradata are 1. Parsing Engine
- 2.MPP 3. Access Module Processors (AMPs
- Teradata offers a complete range of product suite to meet Data warehousing and ETL needs of any organization
- Teradata application mainly used for Supply Chain Management, Master Data Management, Demand Chain Management, etc.