
- 10 Best Data Analytics Tools for Big Data Analysis | Everything You Need to Know
- What is Azure Databricks | A Complete Guide with Best Practices
- Elasticsearch Nested Mapping : The Ultimate Guide with Expert’s Top Picks
- Various Talend Products and their Features | Expert’s Top Picks with REAL-TIME Examples
- What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- Introduction to HBase and Its Architecture | A Complete Guide For Beginners
- What is Azure Data Lake ? : Expert’s Top Picks | Everything You Need to Know
- What is Splunk Rex : Step-By-Step Process with REAL-TIME Examples
- What is Data Pipelining? : Step-By-Step Process with REAL-TIME Examples
- Dedup : Splunk Documentation | Step-By-Step Process | Expert’s Top Picks
- What Is a Hadoop Cluster? : A Complete Guide with REAL-TIME Examples
- Spark vs MapReduce | Differences and Which Should You Learn? [ OverView ]
- Top Big Data Challenges With Solutions : A Complete Guide with Best Practices
- Hive vs Impala | What to learn and Why? : All you need to know
- What is Apache Zookeeper? | Expert’s Top Picks | Free Guide Tutorial
- What is HDFS? Hadoop Distributed File System | A Complete Guide [ OverView ]
- Who Is a Data Architect? How to Become and a Data Architect? : Job Description and Required Skills
- Kafka vs RabbitMQ | Differences and Which Should You Learn?
- What is Apache Hadoop YARN? Expert’s Top Picks
- How to install Apache Spark on Windows? : Step-By-Step Process
- What is Big Data Analytics ? Step-By-Step Process
- Top Big Data Certifications for 2020
- What is Hive?
- Big Data Engineer Salary
- How Facebook is Using Big Data?
- Top Influencers in Big Data and Analytics in 2020
- How to Become a Big Data Hadoop Architect?
- What Are the Skills Needed to Learn Hadoop?
- How to Become a Big Data Analyst?
- How Big Data Can Help You Do Wonders In Your Business
- Essential Concepts of Big Data and Hadoop
- How Big Data is Transforming Retail Industry?
- How big Is Big Data?
- How to Become a Hadoop Developer?
- Hadoop Vs Apache Spark
- PySpark Programming
- 10 Best Data Analytics Tools for Big Data Analysis | Everything You Need to Know
- What is Azure Databricks | A Complete Guide with Best Practices
- Elasticsearch Nested Mapping : The Ultimate Guide with Expert’s Top Picks
- Various Talend Products and their Features | Expert’s Top Picks with REAL-TIME Examples
- What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- Introduction to HBase and Its Architecture | A Complete Guide For Beginners
- What is Azure Data Lake ? : Expert’s Top Picks | Everything You Need to Know
- What is Splunk Rex : Step-By-Step Process with REAL-TIME Examples
- What is Data Pipelining? : Step-By-Step Process with REAL-TIME Examples
- Dedup : Splunk Documentation | Step-By-Step Process | Expert’s Top Picks
- What Is a Hadoop Cluster? : A Complete Guide with REAL-TIME Examples
- Spark vs MapReduce | Differences and Which Should You Learn? [ OverView ]
- Top Big Data Challenges With Solutions : A Complete Guide with Best Practices
- Hive vs Impala | What to learn and Why? : All you need to know
- What is Apache Zookeeper? | Expert’s Top Picks | Free Guide Tutorial
- What is HDFS? Hadoop Distributed File System | A Complete Guide [ OverView ]
- Who Is a Data Architect? How to Become and a Data Architect? : Job Description and Required Skills
- Kafka vs RabbitMQ | Differences and Which Should You Learn?
- What is Apache Hadoop YARN? Expert’s Top Picks
- How to install Apache Spark on Windows? : Step-By-Step Process
- What is Big Data Analytics ? Step-By-Step Process
- Top Big Data Certifications for 2020
- What is Hive?
- Big Data Engineer Salary
- How Facebook is Using Big Data?
- Top Influencers in Big Data and Analytics in 2020
- How to Become a Big Data Hadoop Architect?
- What Are the Skills Needed to Learn Hadoop?
- How to Become a Big Data Analyst?
- How Big Data Can Help You Do Wonders In Your Business
- Essential Concepts of Big Data and Hadoop
- How Big Data is Transforming Retail Industry?
- How big Is Big Data?
- How to Become a Hadoop Developer?
- Hadoop Vs Apache Spark
- PySpark Programming

What is Azure Databricks | A Complete Guide with Best Practices
Last updated on 04th Nov 2022, Artciles, Big Data, Blog
- In this article you will get
- 1.Databricks in Azure
- 2.Pros and Cons of Azure Databricks
- 3.Databricks Data Science & Engineering
- 4.Databricks Runtime
- 5.Databricks Machine Learning
- 6.Conclusion
Databricks in Azure
Azure Databricks is data analytics platform optimized for Microsoft Azure cloud services platform. An Azure Databricks provides a three environments:
- Databricks SQL.
- Databricks data science and engineering.
- Databricks machine learning.
Databricks SQL:
Databricks SQL offers a user-friendly platform. This helps to analysts, who work on a SQL queries, to run queries on a Azure Data Lake, create multiple virtualizations, and can build and share dashboards.
Databricks Data Science and Engineering:
Databricks data science and engineering offers an interactive working environment for the data engineers, data scientists, and machine learning engineers. The two ways to send data through a big data pipeline are:
- Ingest into an Azure through Azure Data Factory in the batches.
- A Stream real-time by using the Apache Kafka, Event Hubs, or IoT Hub.
Databricks Machine Learning:
Databricks machine learning is the complete machine learning environment. It helps to manage the services for an experiment tracking, model training, feature development, and management. It also does a model serving.
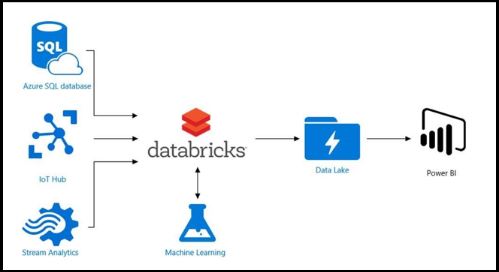
Pros and Cons of an Azure Databricks
Pros:
- It can be process the large amounts of data with the Databricks and since it is part of Azure; the data is a cloud-native.
- The clusters are simple to set up and configure.
- It has Azure Synapse Analytics connector as well as ability to connect to the Azure DB.
- It is integrated with an Active Directory.
- It supports the multiple languages. Scala is a main language, but it also works well with a Python, SQL, and R.
Cons:
- It does not an integrate with a Git or any other versioning tool.
- It, currently, only supports the HDInsight and not Azure Batch or AZTK.
Databricks Data Science & Engineering
Databricks Data Science & Engineering is also called a Workspace. It is an analytics platform that is based on a Apache Spark.
Databricks Data Science & Engineering comprises a complete open-source Apache Spark cluster technologies and also capabilities. Spark in a Databricks Data Science & Engineering includes following components:
Spark SQL and DataFrames: This is a Spark module for working with a structured data. A DataFrame is distributed collection of a data that is organized into a named columns. Streaming: This integrates with a HDFS, Flume, and Kafka. Streaming is a real-time data processing and analysis for the analytical and interactive applications.
MLlib: It is short for a Machine Learning Library consisting of general learning algorithms and utilities including the classification, regression, clustering, collaborative filtering, dimensionality reduction as well as an underlying optimization primitives.
GraphX: Graphs and graph computation for the broad scope of a use cases from cognitive analytics to the data exploration.
Spark Core API: This has support for a R, SQL, Python, Scala, and Java.
Integrating with an Azure Active Directory enables to run a complete Azure-based solutions by using a Databricks SQL. By integrating with Azure databases, Databricks SQL can store a Synapse Analytics, Cosmos DB, Data Lake Store, and a Blob Storage. By integrating with a Power BI, Databricks SQL allows users to a discover and share an insights more easily. BI tools, like Tableau Software, can also be used.
Databricks Runtime
The core components that run on a clusters managed by an Azure Databricks offer several runtimes:
- It includes an Apache Spark but also adds a numerous other features to improve big data analytics.
- Databricks Runtime for the machine learning is built on a Databricks runtime and provides a ready environment for the machine learning and data science.
- Databricks Runtime for genomics is the version of Databricks runtime that is optimized for working with a genomic and biomedical data.
- Databricks Light is an Azure Databricks packaging of an open-source Apache Spark runtime.
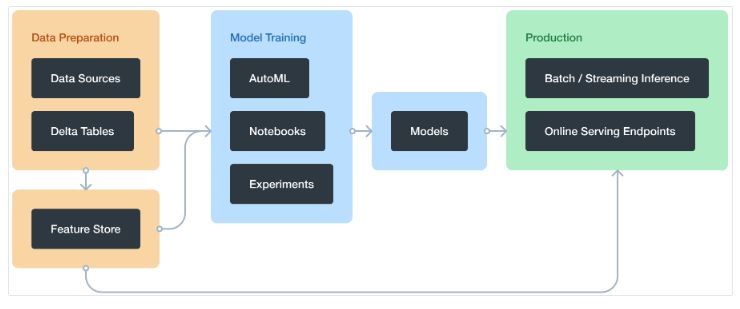
Databricks Machine Learning
Databricks machine learning is the integrated end-to-end machine learning platform incorporating managed services for an experiment tracking, model training, feature development and management, and feature and also model serving. Databricks machine learning automates creation of the cluster that is optimized for machine learning. A Databricks Runtime ML clusters include most famous machine learning libraries like a TensorFlow, PyTorch, Keras, and XGBoost. It also includes the libraries, such as Horovod, that are needed for a distributed training.
With a Databricks machine learning, we can:
- Train models either manually or with an AutoML.
- Track training parameters and models by using the experiments with MLflow tracking.
- Create a feature tables and access them for the model training and inference.
- Share, manage, and serve the models by using a Model Registry.
- Also have access to all of capabilities of the Azure Databricks workspace like notebooks, clusters, jobs, data, Delta tables, security and admin controls, and many more.
Conclusion
Azure Databricks is simple , fast, and collaborative Apache spark-based analytics platform. It accelerates the innovation by bringing together data science, data engineering, and business. This helps to take a collaboration to the another step and makes a process of data analytics more productive, secure, scalable, and an optimized for Azure.