
- Commvault Tutorial for Beginners | Ultimate Guide to Learn [NEW & UPDATED]
- SAP MM (Material Management) Tutorial | A Complete Guide
- MOST In-DEMAND Snowflake Tutorial [ STEP-IN ] | Learn Now
- SAP MM (Material Management) Tutorial | A Complete Guide
- MOST In-DEMAND Snowflake Tutorial [ STEP-IN ] | Learn Now
- Informatica Master Data Management Concepts (MDM) Tutorial | Quickstart – MUST- READ
- Teradata
- Informatica Tutorial: The Ultimate Guide [STEP-IN] | Learnovita
- ETL Tutorial
- SSIS Cheat Sheet
- Informatica Architecture
- Netezza Tutorial
- Datastage Tutorial
- SSIS Tutorial
- Commvault Tutorial for Beginners | Ultimate Guide to Learn [NEW & UPDATED]
- SAP MM (Material Management) Tutorial | A Complete Guide
- MOST In-DEMAND Snowflake Tutorial [ STEP-IN ] | Learn Now
- SAP MM (Material Management) Tutorial | A Complete Guide
- MOST In-DEMAND Snowflake Tutorial [ STEP-IN ] | Learn Now
- Informatica Master Data Management Concepts (MDM) Tutorial | Quickstart – MUST- READ
- Teradata
- Informatica Tutorial: The Ultimate Guide [STEP-IN] | Learnovita
- ETL Tutorial
- SSIS Cheat Sheet
- Informatica Architecture
- Netezza Tutorial
- Datastage Tutorial
- SSIS Tutorial

Datastage Tutorial
Last updated on 27th Sep 2020, Blog, Datawarehouse, Tutorials
What is DataStage?
Datastage is an ETL tool which extracts data, transform and load data from source to the target. The data sources might include sequential files, indexed files, relational databases, external data sources, archives, enterprise applications, etc. DataStage facilitates business analysis by providing quality data to help in gaining business intelligence.
Datastage is used in a large organization as an interface between different systems. It takes care of extraction, translation, and loading of data from source to the target destination. It was first launched by VMark in mid-90’s. With IBM acquiring DataStage in 2005, it was renamed to IBM WebSphere DataStage and later to IBM InfoSphere.
Various version of Datastage available in the market so far was Enterprise Edition (PX), Server Edition, MVS Edition, DataStage for PeopleSoft and so on. The latest edition is IBM InfoSphere DataStage
IBM Information server includes following products,
- IBM InfoSphere DataStage
- IBM InfoSphere QualityStage
- IBM InfoSphere Information Services Director
- IBM InfoSphere Information Analyzer
- IBM Information Server FastTrack
- IBM InfoSphere Business Glossary
Datastage has following Capabilities.
- 1. It can integrate data from the widest range of enterprise and external data sources
- 2. Implements data validation rules
- 3. It is useful in processing and transforming large amounts of data
- 4. It uses scalable parallel processing approach
- 5. It can handle complex transformations and manage multiple integration processes
- 6. Leverage direct connectivity to enterprise applications as sources or targets
- 7. Leverage metadata for analysis and maintenance
- 8. Operates in batch, real time, or as a Web service
In the following sections, we briefly describe the following aspects of IBM InfoSphere DataStage:
- Data transformation
- Jobs
- Parallel processing
InfoSphere DataStage and QualityStage can access data in enterprise applications and data sources such as:
- 1. Relational databases
- 2. Mainframe databases
- 3. Business and analytic applications
- 4. Enterprise resource planning (ERP) or customer relationship management (CRM) databases
- 5. Online analytical processing (OLAP) or performance management databases
Processing Stage Types
IBM infosphere job consists of individual stages that are linked together. It describes the flow of data from a data source to a data target. Usually, a stage has minimum of one data input and/or one data output. However, some stages can accept more than one data input and output to more than one stage.
In Job design various stages you can use are:
- Transform stage
- Filter stage
- Aggregator stage
- Remove duplicates stage
- Join stage
- Lookup stage
- Copy stage
- Sort stage
- Containers
DataStage Components and Architecture
DataStage has four main components namely,
- 1. Administrator: It is used for administration tasks. This includes setting up DataStage users, setting up purging criteria and creating & moving projects.
- 2. Manager: It is the main interface of the Repository of DataStage. It is used for the storage and management of reusable Metadata. Through DataStage manager, one can view and edit the contents of the Repository.
- 3. Designer: A design interface used to create DataStage applications OR jobs. It specifies the data source, required transformation, and destination of data. Jobs are compiled to create an executable that are scheduled by the Director and run by the Server
- 4. Director: It is used to validate, schedule, execute and monitor DataStage server jobs and parallel jobs.
Subscribe For Free Demo
Error: Contact form not found.
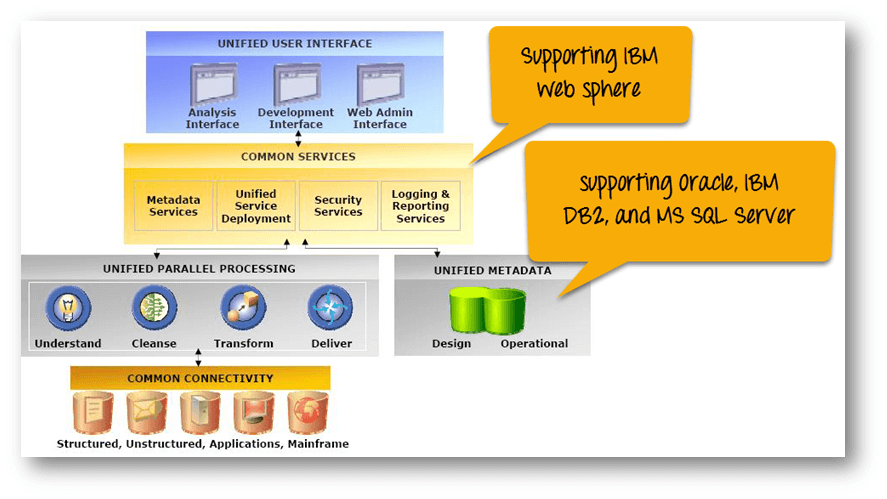
Datastage Architecture Diagram
The above image explains how IBM Infosphere DataStage interacts with other elements of the IBM Information Server platform. DataStage is divided into two section, Shared Components, and Runtime Architecture.
Prerequisite for Datastage tool
For DataStage, you will require the following setup.
- Infosphere
- DataStage Server 9.1.2 or above
- Microsoft Visual Studio .NET 2010 Express Edition C++
- Oracle client (full client, not an instant client) if connecting to an Oracle database
- DB2 client if connecting to a DB2 database
Download and Installation InfoSphere Information Server
To access DataStage, download and install the latest version of IBM InfoSphere Server. The server supports AIX, Linux, and Windows operating system. You can choose as per requirement.
To migrate your data from an older version of infosphere to new version uses the asset interchange tool.
Installation Files
For installing and configuring Infosphere Datastage, you must have following files in your setup.
For Windows,
- 1. EtlDeploymentPackage-windows-oracle.pkg
- 2. EtlDeploymentPackage-windows-db2.pkg
For Linux,
- 1. EtlDeploymentPackage-linux-db2.pkg
- 2. EtlDeploymentPackage-linux-oracle.pkg
Process flow of Change data in a CDC Transaction stage Job.
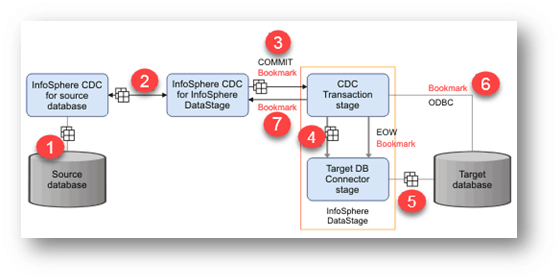
- 1. The ‘InfoSphere CDC’ service for the database monitors and captures the change from a source database
- 2. According to the replication definition “InfoSphere CDC” transfers the change data to “InfoSphere CDC for InfoSphere DataStage.”
- 3. The “InfoSphere CDC for InfoSphere DataStage” server sends data to the “CDC Transaction stage” through a TCP/IP session. The “InfoSphere CDC for InfoSphere DataStage” server also sends a COMMIT message (along with bookmark information) to mark the transaction boundary in the captured log.
- 4. For each COMMIT message sent by the “InfoSphere CDC for InfoSphere DataStage” server, the “CDC Transaction stage” creates end-of-wave (EOW) markers. These markers are sent on all output links to the target database connector stage.
- 5. When the “target database connector stage” receives an end-of-wave marker on all input links, it writes bookmark information to a bookmark table and then commits the transaction to the target database.
- 6. The “InfoSphere CDC for InfoSphere DataStage” server requests bookmark information from a bookmark table on the “target database.”
- 7. The “InfoSphere CDC for InfoSphere DataStage” server receives the Bookmark information.
This information is used to,
- Determine the starting point in the transaction log where changes are read when replication begins.
- To determine if the existing transaction log can be cleaned up
Setting Up SQL Replication
Before you begin with Datastage, you need to setup database. You will create two DB2 databases.
- 1. One to serve as replication source and
- 2. One as the target.
You will also create two tables (Product and Inventory) and populate them with sample data. Then you can test your integration between SQL Replication and Datastage.
Moving forward you will set up SQL replication by creating control tables, subscription sets, registrations and subscription set members. We will learn more about this in details in next section.
Here we will take an example of Retail sales item as our database and create two tables Inventory and Product. These tables will load data from source to target through these sets. (control tables, subscription sets, registrations, and subscription set members.)
Step 1) Create a source database referred to as SALES. Under this database, create two tables product and Inventory.
Step 2) Run the following command to create SALES database.
- db2 create database SALES
Step 3) Turn on archival logging for the SALES database. Also, back up the database by using the following commands
- db2 update db cfg for SALES using LOGARCHMETH3 LOGRETAIN
- db2 backup db SALES
Step 4) In the same command prompt, change to the setupDB subdirectory in the sqlrepl-datastage-tutorial directory that you extracted from the downloaded compressed file.
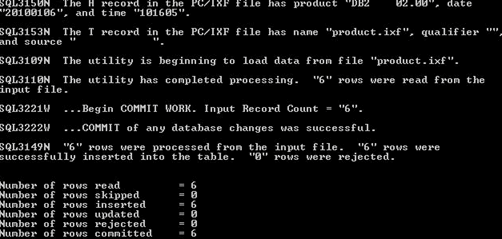
Step 5) Use the following command to create Inventory table and import data into the table by running the following command.
- db2 import from inventory.ixf of ixf create into inventory
Step 6) Create a target table. Name the target database as STAGEDB.
Since now you have created both databases source and target, the next step we will see how to replicate it.
Creating the SQL Replication objects
The image below shows how the flow of change data is delivered from source to target database. You create a source-to-target mapping between tables known as subscription set members and group the members into a subscription.
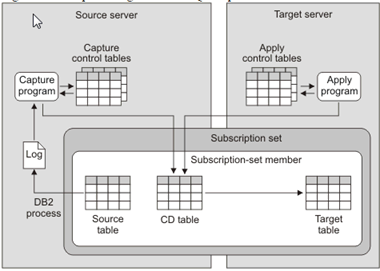
The unit of replication within InfoSphere CDC (Change Data Capture) is referred to as a subscription.
- The changes done in the source is captured in the “Capture control table” which is sent to the CD table and then to target table. While the apply program will have the details about the row from where changes need to be done. It will also join CD table in subscription set.
- A subscription contains mapping details that specify how data in a source data store is applied to a target data store. Note, CDC is now referred as Infosphere data replication.
- When a subscription is executed, InfoSphere CDC captures changes on the source database. InfoSphere CDC delivers the change data to the target, and stores sync point information in a bookmark table in the target database.
- InfoSphere CDC uses the bookmark information to monitor the progress of the InfoSphere DataStage job.
- In the case of failure, the bookmark information is used as restart point. In our example, the ASN.IBMSNAP_FEEDETL table stores DataStage related synchpoint information that is used to track DataStage progress.
Business advantages of using DataStage
- 1. Significant ROI (return of investment) over hand-coding
- 2. Learning curve – quick development and reduced maintenance with GUI tool
- 3. Development Partnerships – easy integration with top market products interfaced with the data warehouse, such as SAP, Cognos, Oracle, Teradata, SAS
- 4. Single vendor solution for bulk data transfer and complex transformations (DataStage versus DataStage TX)
- 5. Transparent and wide range of licensing options
Technical advantages of using DataStage
- Single interface to integrate heterogeneous applications
- Flexible development environment – it enables developers to work in their desired style, reduces training needs and enhances reuse. ETL developers can follow data integrations quickly through a graphical work-as-you-think solution which comes by default with a wide range of extensible objects and functions
- Team communication and documentation of the jobs is supported by data flows and transformations self-documenting engine in HTML format.
- Ability to join data both at the source, and at the integration server and to apply any business rule from within a single interface without having to write any procedural code.
- Common data infrastructure for data movement and data quality (metadata repository, parallel processing framework, development environment)
- With Datastage Enterprise Edition users can use the parallel processing engine which provides unlimited performance and scalability. It helps get most out of hardware investment and resources.
- The datastage server performs very well on both Windows and unix servers.
Major Datastage weaknesses and disadvantages
- 1. Big architectural differences in the Server and Enterprise edition which results in the fact that migration from server to enterprise edition may require vast time and resources effort.
- 2. There is no automated error handling and recovery mechanism – for example no way to automatically time out zombie jobs or kill locking processes. However, on the operator level, these errors can be easily resolved.
- 3. No Unix Datastage client – the Client software available only under Windows and there are different clients for different datastage versions. The good thing is that they still can be installed on the same windows pc and switched with the Multi-Client Manager program.
- 4. Might be expensive as a solution for a small or mid-sized company.
Conclusion
The look and feel of DataStage and QualityStage canvas remains the same but the new functionalities are major enhancements over the previous version. Data Connection Object,Parameter Set, Range Look-up and Slowly Changing Dimension are all designed to simplify design, help cut implementation effort and reduce cost. Advance Find provides a good way to do impact analysis, an important step in project management. Resource Estimation is as important for project planning. Meanwhile, Performance Analysis tool is another useful feature that can be used throughout the lifecycle of a job. By knowing what causes a performance bottleneck, production support groups can better cope with the ever-shrinking batch windows.
While Advance Find will not perform a Replace function and SQL Builder will not let us build complex SQL, all the changes in version 8 have positive impact on job development,production support and project management. Combined with the features offered in Information Server, existing customers who are looking to upgrade or new DataStage clients will benefit from the new enhancements.